当前位置:网站首页>Summary of Wu Enda's course of machine learning (4)
Summary of Wu Enda's course of machine learning (4)
2022-04-21 16:46:00 【zqwlearning】
List of articles
-
- 12. Chapter 12 Support vector machine (Support Vector Machines,SVM)
- 13. clustering (Clustering)
- 14. Chapter 14 Dimension reduction (Dimensionality Reduction)
-
- 14.1 The goal is 1: data compression
- 14.2 The goal is 2: visualization
- 14.3 Principal component analysis problem planning (Principal Component Analysis,PCA)
- 14.4 Principal component analysis algorithm (Principal Component Analysis,PCA)
- 14.5 Main component fraction selection
- 14.6 Compression reproduction
- 14.6 application PCA The advice of
12. Chapter 12 Support vector machine (Support Vector Machines,SVM)
12.1 Optimization objectives (optimization objective)
-
Another view of logistic regression
h θ ( x ) = 1 1 + e − θ T x {h_\theta }(x) = {1 \over {1 + {e^{ - {\theta ^T}x}}}} hθ(x)=1+e−θTx1
- Such as y = 1 y = 1 y=1, We want to h θ ( x ) ≈ 1 {h_\theta }(x) \approx 1 hθ(x)≈1, namely e − θ T x ≫ 0 {e^{ - {\theta ^T}x}} \gg 0 e−θTx≫0
- Such as y = 0 y = 0 y=0, We want to h θ ( x ) ≈ 0 {h_\theta }(x) \approx 0 hθ(x)≈0, namely e − θ T x ≪ 0 {e^{ - {\theta ^T}x}} \ll 0 e−θTx≪0
cos t ( h θ ( x ) , y ) = − ( y log ( h θ ( x ) ) + ( 1 − y ) log ( 1 − h θ ( x ) ) ) = − y log ( 1 1 + e − θ T x ) − ( 1 − y ) log ( 1 − 1 1 + e − θ T x ) \cos t({h_\theta }(x),y) = - ({\rm{y}}\log ({h_\theta }(x)) + (1 - {\rm{y}})\log (1 - {h_\theta }(x))) = - y\log ({1 \over {1 + {e^{ - {\theta ^T}x}}}}) - (1 - y)\log (1 - {1 \over {1 + {e^{ - {\theta ^T}x}}}}) cost(hθ(x),y)=−(ylog(hθ(x))+(1−y)log(1−hθ(x)))=−ylog(1+e−θTx1)−(1−y)log(1−1+e−θTx1)

Use cos t 1 ( z ) , cos t 0 ( z ) \cos {t_1}(z),\cos {t_0}(z) cost1(z),cost0(z) To replace separately − log ( 1 1 + e − θ T x ) , − log ( 1 − 1 1 + e − θ T x ) - \log ({1 \over {1 + {e^{ - {\theta ^T}x}}}}), - \log (1 - {1 \over {1 + {e^{ - {\theta ^T}x}}}}) −log(1+e−θTx1),−log(1−1+e−θTx1)
-
SVM
min θ C ∑ i = 1 m [ y ( i ) cos t 1 ( θ T x ( i ) ) + ( 1 − y ( i ) ) cos t 0 ( θ T x ( i ) ) ] + 1 2 ∑ j = 1 n θ j 2 \mathop {\min }\limits_\theta C\sum\limits_{i = 1}^m {[{y^{(i)}}\cos {t_1}({\theta ^T}{x^{(i)}}) + (1 - {y^{(i)}})\cos {t_0}({\theta ^T}{x^{(i)}})]} + {1 \over 2}\sum\limits_{j = 1}^n { {\theta _j}^2} θminCi=1∑m[y(i)cost1(θTx(i))+(1−y(i))cost0(θTx(i))]+21j=1∑nθj2, C C C Constant
SVM Assume no output probability , Make direct predictions :
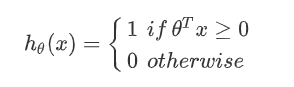
12.2 Large interval visual understanding (Large Margin Intuition)
min θ C ∑ i = 1 m [ y ( i ) cos t 1 ( θ T x ( i ) ) + ( 1 − y ( i ) ) cos t 0 ( θ T x ( i ) ) ] + 1 2 ∑ j = 1 n θ j 2 \mathop {\min }\limits_\theta C\sum\limits_{i = 1}^m {[{y^{(i)}}\cos {t_1}({\theta ^T}{x^{(i)}}) + (1 - {y^{(i)}})\cos {t_0}({\theta ^T}{x^{(i)}})]} + {1 \over 2}\sum\limits_{j = 1}^n { {\theta _j}^2} θminCi=1∑m[y(i)cost1(θTx(i))+(1−y(i))cost0(θTx(i))]+21j=1∑nθj2

- Such as y = 1 y = 1 y=1, We want to θ T x ≥ 1 {\theta ^T}x \ge 1 θTx≥1, Not just ≥ 0 \ge 0 ≥0
- Such as y = 0 y = 0 y=0, We want to θ T x ≥ − 1 {\theta ^T}x \ge -1 θTx≥−1, Not just ≤ 0 \le 0 ≤0
SVM Decision boundaries (SVM Decision Boundary): Linearly separable case , Interval of support vector machine , min θ C 0 + 1 2 ∑ j = 1 n θ j 2 \mathop {\min }\limits_\theta C0 + {1 \over 2}\sum\limits_{j = 1}^n { {\theta _j}^2} θminC0+21j=1∑nθj2
- C C C Very big time , Want to classify the samples in each training set correctly , Sensitive to noise
- C C C Not very big , Partial sample classification error is allowed , Insensitive to noise , Even in the case of linear inseparability ,SVM Can also do well .
- C C C amount to 1 λ {1 \over \lambda } λ1

12.3 Mathematical principle of large interval classifier
Appointment :

∥ u ∥ = l e n g t h o f v e c t o r u = u 1 2 + u 2 2 ∈ R \parallel u\parallel = length{\kern 1pt} {\kern 1pt} of{\kern 1pt} {\kern 1pt} vector{\kern 1pt} {\kern 1pt} u = \sqrt {u_1^2 + u_2^2} \in R ∥u∥=lengthofvectoru=u12+u22∈R

P P P be equal to v v v stay u u u Mapping on , u T v = P ∙ ∥ u ∥ = u 1 v 1 + u 2 v 2 ∈ R {u^T}v = P \bullet \parallel u\parallel = {u_1}{v_1} + {u_2}{v_2} \in R uTv=P∙∥u∥=u1v1+u2v2∈R.
Decision boundaries : min θ 1 2 ∑ j = 1 n θ j 2 \mathop {\min }\limits_\theta {1 \over 2}\sum\limits_{j = 1}^n { {\theta _j}^2} θmin21j=1∑nθj2, C C C Very big time .
Simplified analysis : θ 0 = 0 , n = 2 {\theta _0} = 0,n = 2 θ0=0,n=2
1 2 ∑ j = 1 n θ j 2 = 1 2 ( θ 1 2 + θ 2 2 ) = 1 2 ( θ 1 2 + θ 2 2 ) 2 = 1 2 ∥ θ ∥ 2 {1 \over 2}\sum\limits_{j = 1}^n { {\theta _j}^2 = } {1 \over 2}(\theta _1^2 + \theta _2^2) = {1 \over 2}{(\sqrt {\theta _1^2 + \theta _2^2} )^2} = {1 \over 2}\parallel \theta {\parallel ^2} 21j=1∑nθj2=21(θ12+θ22)=21(θ12+θ22)2=21∥θ∥2
θ T x ( i ) = P ( i ) + ∥ θ ∥ = θ 1 x 1 ( i ) + θ 2 x 2 ( i ) {\theta ^T}{x^{(i)}} = {P^{(i)}} + \parallel \theta \parallel = {\theta _1}x_1^{(i)} + {\theta _2}x_2^{(i)} θTx(i)=P(i)+∥θ∥=θ1x1(i)+θ2x2(i)
12.4 Kernel function 1(Kernels)
Nonlinear decision boundary :

When θ 0 + θ 1 x 1 + θ 2 x 2 + θ 3 x 1 x 2 + θ 4 x 1 2 + θ 5 x 2 2 + . . . ≥ 0 {\theta _0} + {\theta _1}{x_1} + {\theta _2}{x_2} + {\theta _3}{x_1}{x_2} + {\theta _4}{x_1}^2 + {\theta _5}{x_2}^2 + ... \ge 0 θ0+θ1x1+θ2x2+θ3x1x2+θ4x12+θ5x22+...≥0, forecast y = 1 y = 1 y=1.
Define new features : f 1 = x 1 , f 2 = x 2 , f 3 = x 1 x 2 , . . . {f_1} = {x_1},{f_2} = {x_2},{f_3} = {x_1}{x_2},... f1=x1,f2=x2,f3=x1x2,..., Is there a better way ?
Given x x x, The calculation of new features depends on the connection with landmarks ( l ( 1 ) , l ( 2 ) , l ( 3 ) {l^{(1)}},{l^{(2)}},{l^{(3)}} l(1),l(2),l(3)) The proximity of .
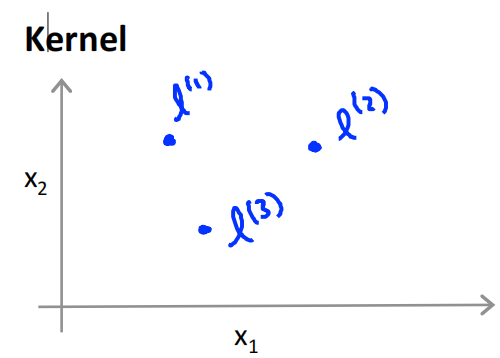
f 1 = s i m i l a r i t y ( x , l ( 1 ) ) = exp ( − ∥ x − l ( 1 ) ∥ 2 2 σ 2 ) {f_1} = similarity(x,{l^{(1)}}) = \exp ( - { {\parallel x - {l^{(1)}}{\parallel ^2}} \over {2{\sigma ^2}}}) f1=similarity(x,l(1))=exp(−2σ2∥x−l(1)∥2), To measure x , l ( 1 ) x,{l^{(1)}} x,l(1) The similarity .
The kernel function is marked as : κ ( x , l ( i ) ) \kappa (x,{l^{(i)}}) κ(x,l(i))
12.5 Kernel function 2
How to get l ( 1 ) , l ( 2 ) , l ( 3 ) , . . . {l^{(1)}},{l^{(2)}},{l^{(3)}},... l(1),l(2),l(3),...?
With kernel function SVM:
- Training set : { ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , . . . , ( x ( m ) , y ( m ) ) } \{ ({x^{(1)}},{y^{(1)}}),({x^{(2)}},{y^{(2)}}),...,({x^{(m)}},{y^{(m)}})\} { (x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))}
- choice l ( 1 ) = x ( 1 ) , l ( 2 ) = x ( 2 ) , . . . , l ( m ) = x ( m ) {l^{(1)}} = {x^{(1)}},{l^{(2)}} = {x^{(2)}},...,{l^{(m)}} = {x^{(m)}} l(1)=x(1),l(2)=x(2),...,l(m)=x(m)
- Calculation f f f: f 1 = s i m i l a r i t y ( x , l ( 1 ) ) {f_1} = similarity(x,{l^{(1)}}) f1=similarity(x,l(1)),…, f m = s i m i l a r i t y ( x , l ( m ) ) {f_m} = similarity(x,{l^{(m)}}) fm=similarity(x,l(m)), f f f As a feature of training
- min θ C ∑ i = 1 m [ y ( i ) cos t 1 ( θ T f ( i ) ) + ( 1 − y ( i ) ) cos t 0 ( θ T f ( i ) ) ] + 1 2 ∑ j = 1 n θ j 2 \mathop {\min }\limits_\theta C\sum\limits_{i = 1}^m {[{y^{(i)}}\cos {t_1}({\theta ^T}{f^{(i)}}) + (1 - {y^{(i)}})\cos {t_0}({\theta ^T}{f^{(i)}})]} + {1 \over 2}\sum\limits_{j = 1}^n { {\theta _j}^2} θminCi=1∑m[y(i)cost1(θTf(i))+(1−y(i))cost0(θTf(i))]+21j=1∑nθj2
Why not apply the kernel technique to logistic regression , Because when combined with logistic regression, it becomes very slow , Some optimizations are for kernel functions and SVM Of .
SVM Parameters :
- C ( = 1 λ ) C( = {1 \over \lambda }) C(=λ1):
- Big C C C: Low deviation , High variance —— Over fitting
- Small C C C: High deviation , Low variance —— Under fitting
- σ 2 {
{\sigma ^2}} σ2:
- Big σ 2 { {\sigma ^2}} σ2: features f f f Very smooth . High deviation , Low variance —— Under fitting
- Small σ 2 { {\sigma ^2}} σ2: features f f f Very uneven . High deviation , Low deviation , High variance —— Over fitting

12.6 Use SVM
Use SVM The software package solves the parameter θ \theta θ Calculation problem .
Pay attention to two points :
- Parameters C C C The choice of
- The choice of kernel function
-
Kernel free function ( Linear kernel function ), Get a linear classifier . When n n n It's big , m m m Very feasible . however , In a very high dimensional feature space , Try fitting very complex functions , If the training set is small , Maybe over fitting .
-
Gaussian kernel (Gaussian kernel):
f i = exp ( − ∥ x − l ( 1 ) ∥ 2 2 σ 2 ) {f_i} = \exp ( - { {\parallel x - {l^{(1)}}{\parallel ^2}} \over {2{\sigma ^2}}}) fi=exp(−2σ2∥x−l(1)∥2)
Need to choose σ 2 { {\sigma ^2}} σ2
When n n n Very small , m m m When it is very large, it can fit the nonlinear .
Kernel function note : If the value range of the original feature is very different , Probably f f f It is largely determined by only some characteristics .
Other kernel functions :String kernel,chiIsquare’kernel, histogram intersec2on’kernel,…
Be careful : Not all similarity functions s i m i l a r i t y ( x , l ) similarity(x,l) similarity(x,l) Are valid cores .( Need to meet the requirements named " Mercer's Theorem " Technical conditions of , In order to ensure that SVM Package optimization works correctly , And don't disagree ).
Many classification :
many SVM The learning package has built-in multi classification methods , Use one to many for multi classification .
Logical regression VS SVM:
n n n Represents the number of features , m m m Indicates the number of training samples
- If n n n relative m m m It's big ( Such as : n = 10000 , m = 10 ∼ 1000 n = 10000,m = 10 \sim 1000 n=10000,m=10∼1000), Using logistic regression or linear kernel function SVM
- If n n n smaller m m m secondary ( Such as : n = 1 ∼ 1000 , m = 10 ∼ 10000 n = 1 \sim 1000,m = 10 \sim 10000 n=1∼1000,m=10∼10000), Using Gaussian kernel function SVM
- If n n n smaller m m m It's big ( Such as : n = 1 ∼ 1000 , m = 50000 + n = 1 \sim 1000,m = 50000 + n=1∼1000,m=50000+), Using logistic regression or linear kernel function SVM
Neural networks may perform well in most cases , But training may be slower .
13. clustering (Clustering)
13.1 Unsupervised learning (Unsupervised Learning Introduction)
Training set : { x ( 1 ) , x ( 2 ) , . . . , x ( m ) } \{ {x^{(1)}},{x^{(2)}},...,{x^{(m)}}\} { x(1),x(2),...,x(m)}

Application of clustering algorithm : Market segmentation ; Social network analysis ; Server organization ; Astronomical data analysis

13.2 K Mean clustering algorithm (k-means algorithm)
K Mean clustering algorithm :
- Input :K( Number of clusters ); Training set : { x ( 1 ) , x ( 2 ) , . . . , x ( m ) } \{ {x^{(1)}},{x^{(2)}},...,{x^{(m)}}\} { x(1),x(2),...,x(m)}, x ( i ) ∈ R n {x^{(i)}} \in {R^n} x(i)∈Rn Default x 0 = 1 x_0^{} = 1 x0=1
- Random initialization K Class center u 1 , u 2 , . . . , u k ∈ R n {u_1},{u_2},...,{u_k} \in {R^n} u1,u2,...,uk∈Rn
- Cluster allocation (cluster assignment step): Assign each point to the nearest class center point .( New clustering )
- Update cluster center (move centroid): Calculate the mean value of each type of data point as the new class center .( New center )
- Repeat the above steps until convergence , That is, the clustering result remains unchanged
13.3 Optimization objectives (Optimization objective)
c ( i ) {c^{(i)}} c(i) Express x ( i ) {x^{(i)}} x(i) Which category is currently assigned to ; u k {u_k} uk Represents the class center k; u c ( i ) {u_{ {c^{(i)}}}} uc(i) Express x ( i ) {x^{(i)}} x(i) Which class center is currently assigned to .
Optimization objectives : J ( c ( 1 ) , . . . , c ( m ) , . . . , u 1 , . . . , u K ) = 1 m ∑ i = 1 m ∥ x ( i ) − u c ( i ) ∥ 2 J({c^{(1)}},...,{c^{(m)}},...,{u_1},...,{u_K}) = {1 \over m}\sum\limits_{i = 1}^m {\parallel {x^{(i)}} - {u_{ {c^{(i)}}}}{\parallel ^2}} J(c(1),...,c(m),...,u1,...,uK)=m1i=1∑m∥x(i)−uc(i)∥2
min c ( 1 ) , . . . , c ( m ) , . . . , u 1 , . . . , u K J ( c ( 1 ) , . . . , c ( m ) , . . . , u 1 , . . . , u K ) \mathop {\min }\limits_{ {c^{(1)}},...,{c^{(m)}},...,{u_1},...,{u_K}} J({c^{(1)}},...,{c^{(m)}},...,{u_1},...,{u_K}) c(1),...,c(m),...,u1,...,uKminJ(c(1),...,c(m),...,u1,...,uK)
Can prove that :
- First step : Cluster allocation ( New clustering ) Is optimizing c ( 1 ) , . . . , c ( m ) {c^{(1)}},...,{c^{(m)}} c(1),...,c(m), And keep u 1 , . . . , u K {u_1},...,{u_K} u1,...,uK unchanged
- The second step : Update cluster center ( New center ) Is optimizing u 1 , . . . , u K {u_1},...,{u_K} u1,...,uK, And keep c ( 1 ) , . . . , c ( m ) {c^{(1)}},...,{c^{(m)}} c(1),...,c(m) unchanged
- k-means In fact, it is minimized in two steps J ( c ( 1 ) , . . . , c ( m ) , . . . , u 1 , . . . , u K ) = 1 m ∑ i = 1 m ∥ x ( i ) − u c ( i ) ∥ 2 J({c^{(1)}},...,{c^{(m)}},...,{u_1},...,{u_K}) = {1 \over m}\sum\limits_{i = 1}^m {\parallel {x^{(i)}} - {u_{ {c^{(i)}}}}{\parallel ^2}} J(c(1),...,c(m),...,u1,...,uK)=m1i=1∑m∥x(i)−uc(i)∥2, Then iterate repeatedly until convergence
13.4 Random initialization (Random initialization)
The following conditions are met :
- Should have K < m K < m K<m
- Random selection K K K Training samples
- Set up u 1 , . . . , u K {u_1},...,{u_K} u1,...,uK It's equal to this K K K Training samples
Due to different initialization ,K The mean clustering algorithm may fall into the local optimum . To solve the local optimum , especially K = 2 ∼ 10 K = 2 \sim 10 K=2∼10 when , Adopting the following scheme has greatly improved : Run repeatedly 50~1000 Time k-means Take the best .
13.5 Select the number of clusters (Choosing the number of clusters)
- “ Elbow ” Law (Elbow method):

Can solve some problems , But you can't deal with all the problems .
- Sometimes , You are running k-means De clustering , For the next step . This can be based on the performance of the next work , As an option K K K Principle of .
14. Chapter 14 Dimension reduction (Dimensionality Reduction)
14.1 The goal is 1: data compression
Purpose : To reduce the space ; Algorithm acceleration
Reduce the amount of data , Such as : Two dimensions to one dimension , 3D to 2D
The dimension of a matrix is generally the number of values in a vector , Be careful : The vector is vertical by default
14.2 The goal is 2: visualization
High dimensional data is often mapped to 3D or 2D for visualization .
14.3 Principal component analysis problem planning (Principal Component Analysis,PCA)
Problem description : Reduce the quantity n Dimension to k dimension , Search for k Base vectors u ( 1 ) , u ( 2 ) , . . . , u ( k ) {u^{(1)}},{u^{(2)}},...,{u^{(k)}} u(1),u(2),...,u(k) Represents all data , And mapping errors are minimal .
PCA Not linear regression .
14.4 Principal component analysis algorithm (Principal Component Analysis,PCA)
Training set : { x ( 1 ) , x ( 2 ) , . . . , x ( m ) } \{ {x^{(1)}},{x^{(2)}},...,{x^{(m)}}\} { x(1),x(2),...,x(m)}
-
Data preprocessing : Including feature scaling or mean averaging .
Calculation u j = 1 m ∑ i = 1 m x j ( i ) {u_j} = {1 \over m}\sum\limits_{i = 1}^m {x_j^{(i)}} uj=m1i=1∑mxj(i), Then substitute x j − u j s j { { {x_j} - {u_j}} \over { {s_j}}} sjxj−uj On behalf of x j ( i ) {x_j^{(i)}} xj(i).
If the range of different features is different , Feature scaling is very necessary .k Dimensional space is primitive n Low dimensional subspaces of dimensional spaces (dimensional sub-space)
-
Calculate the covariance matrix (convariance matrix)
Σ = 1 m ∑ i = 1 m ( x ( i ) ) ( x ( i ) ) T \Sigma = {1 \over m}\sum\limits_{i = 1}^m {({x^{(i)}}){ {({x^{(i)}})}^T}} Σ=m1i=1∑m(x(i))(x(i))T, among Σ \Sigma Σ yes s i g m a sigma sigma matrix .
-
Calculate singular value decomposition (eigenvectors of sigma)
[ u , s , v ] = s v d ( s i g m a ) [u,s,v] = svd(sigma) [u,s,v]=svd(sigma), among u u u That's what we need
u = [ u ( 1 ) , u ( 2 ) ⏟ k , . . . , u ( m ) ] ∈ R n × n u = \left[ {\underbrace { {u^{(1)}},{u^{(2)}}}_k,...,{u^{(m)}}} \right] \in {R^{n \times n}} u=⎣⎡k u(1),u(2),...,u(m)⎦⎤∈Rn×n, take u u u Before k Just a vector .
-
x ∈ R n ⇒ z ∈ R k x \in {R^n} \Rightarrow z \in {R^k} x∈Rn⇒z∈Rk
KaTeX parse error: Undefined control sequence: \matrix at position 86: …(i)}} = \left[ \̲m̲a̲t̲r̲i̲x̲{ {u^{(1)}} \…
14.5 Main component fraction selection
Square mean of mapping error : 1 m ∑ i = 1 m ∥ x ( i ) − x a p p r o i x ( i ) ∥ 2 {1 \over m}\sum\limits_{i = 1}^m {\parallel {x^{(i)}} - x_{approix}^{(i)}{\parallel ^2}} m1i=1∑m∥x(i)−xapproix(i)∥2; Total data change : 1 m ∑ i = 1 m ∥ x ( i ) ∥ 2 {1 \over m}\sum\limits_{i = 1}^m {\parallel {x^{(i)}}{\parallel ^2}} m1i=1∑m∥x(i)∥2
Try to choose k Minimize the following values , That is to maximize the retention of all differences :

1 m ∑ i = 1 m ∥ x ( i ) − x a p p r o i x ( i ) ∥ 2 1 m ∑ i = 1 m ∥ x ( i ) ∥ 2 ≤ 0.01 {
{
{1 \over m}\sum\limits_{i = 1}^m {\parallel {x^{(i)}} - x_{approix}^{(i)}{\parallel ^2}} } \over {
{1 \over m}\sum\limits_{i = 1}^m {\parallel {x^{(i)}}{\parallel ^2}} }} \le 0.01 m1i=1∑m∥x(i)∥2m1i=1∑m∥x(i)−xapproix(i)∥2≤0.01, Equivalent to 99% The variance of is retained
choice k Methods :
Try different k The value of , k = 1 , 2 , . . . k = 1,2,... k=1,2,..., Calculation z ( 1 ) , z ( 2 ) , . . . , z ( m ) , x a p p r o i x ( 1 ) , x a p p r o i x ( 2 ) , . . . , x a p p r o i x ( m ) {z^{(1)}},{z^{(2)}},...,{z^{(m)}},x_{approix}^{(1)},x_{approix}^{(2)},...,x_{approix}^{(m)} z(1),z(2),...,z(m),xapproix(1),xapproix(2),...,xapproix(m), Check to see if 1 m ∑ i = 1 m ∥ x ( i ) − x a p p r o i x ( i ) ∥ 2 1 m ∑ i = 1 m ∥ x ( i ) ∥ 2 ≤ 0.01 { { {1 \over m}\sum\limits_{i = 1}^m {\parallel {x^{(i)}} - x_{approix}^{(i)}{\parallel ^2}} } \over { {1 \over m}\sum\limits_{i = 1}^m {\parallel {x^{(i)}}{\parallel ^2}} }} \le 0.01 m1i=1∑m∥x(i)∥2m1i=1∑m∥x(i)−xapproix(i)∥2≤0.01. But this calculation is too expensive , You can use [ u , s , v ] = s v d ( s i g m a ) [u,s,v] = svd(sigma) [u,s,v]=svd(sigma) Medium s s s Calculation .
1 m ∑ i = 1 m ∥ x ( i ) − x a p p r o i x ( i ) ∥ 2 1 m ∑ i = 1 m ∥ x ( i ) ∥ 2 ≤ 0.01 ⇒ 1 − ∑ i = 1 k s i i ∑ i = 1 n s i i ≤ 0.01 { { {1 \over m}\sum\limits_{i = 1}^m {\parallel {x^{(i)}} - x_{approix}^{(i)}{\parallel ^2}} } \over { {1 \over m}\sum\limits_{i = 1}^m {\parallel {x^{(i)}}{\parallel ^2}} }} \le 0.01 \Rightarrow 1 - { {\sum\limits_{i = 1}^k { {s_{ii}}} } \over {\sum\limits_{i = 1}^n { {s_{ii}}} }} \le 0.01 m1i=1∑m∥x(i)∥2m1i=1∑m∥x(i)−xapproix(i)∥2≤0.01⇒1−i=1∑nsiii=1∑ksii≤0.01,k Traverse from small to large and select the smallest one that satisfies the condition k.
14.6 Compression reproduction
Z = U T X ⇒ X a p p r o i x = U Z ≈ X Z = {U^T}X \Rightarrow {X_{approix}} = UZ \approx X Z=UTX⇒Xapproix=UZ≈X
14.6 application PCA The advice of
Supervised learning accelerates :
Training set : { ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , . . . , ( x ( m ) , y ( m ) ) } \{ ({x^{(1)}},{y^{(1)}}),({x^{(2)}},{y^{(2)}}),...,({x^{(m)}},{y^{(m)}})\} { (x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))}
Perform on the input PCA, { ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , . . . , ( x ( m ) , y ( m ) ) } ⇒ { ( z ( 1 ) , y ( 1 ) ) , ( z ( 2 ) , y ( 2 ) ) , . . . , ( z ( m ) , y ( m ) ) } \{ ({x^{(1)}},{y^{(1)}}),({x^{(2)}},{y^{(2)}}),...,({x^{(m)}},{y^{(m)}})\} \Rightarrow \{ ({z^{(1)}},{y^{(1)}}),({z^{(2)}},{y^{(2)}}),...,({z^{(m)}},{y^{(m)}})\} { (x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))}⇒{ (z(1),y(1)),(z(2),y(2)),...,(z(m),y(m))}.
Be careful : On the training set PCA Mapping calculation , However, the mapping can be applied to validation sets and test sets .
application PCA:
- Compress :
- Reduce memory footprint
- Learning algorithm acceleration
- visualization
- Do not use PCA To solve the fitting problem .
- When is not suitable for use PCA? First, experiment with the original input , If the desired effect is not achieved , Consider adopting PCA.PCA After all, it is dimensionality reduction , There will still be a loss of information ! And it adds extra work .
版权声明
本文为[zqwlearning]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204211639367134.html
边栏推荐
- js 毫秒转天时分秒
- Problems encountered in the project (IV) @ async usage and its idea of batch processing a large amount of data
- 机器学习吴恩达课程总结(四)
- 【观察】紫光云:同构混合云升级为分布式云,让云和智能无处不在
- The elmentui drop-down box realizes all functions
- What are the similarities and differences between LCD and OLED screens
- Go language ⌈ concurrent programming ⌋
- 29. 有 1、2、3、4 个数字,能组成多少个互不相同且无重复数字的三位数
- 2-4. 端口绑定
- 机器学习吴恩达课程总结(一)
猜你喜欢

Yunna: is the asset management system of large medical equipment expensive? Main contents of hospital asset management

C语言程序的环境,编译+链接

IvorySQL亮相于PostgresConf SV 2022 硅谷Postgres大会

Start redis process

Historical evolution, application and security requirements of the Internet of things

elmentUI表单中input 和select长度不一致问题

Are you sure you don't want to see it yet? Managing your code base in this way is both convenient and worry free

Mina中的Scan State
如果这题都不会面试官还会继续问我 JVM 嘛:如何判断对象是否可回收

4.25 unlock openharmony technology day! The annual event is about to open!
随机推荐
Project training 2022-4-21 (flame grass)
SIGIR 2022 | 从Prompt的角度考量强化学习推荐系统
程序设计天梯赛L3-29 还原文件(dfs就过了,离离原上谱)
在线词典网站
中国创投,凛冬将至
Which exchange is rapeseed meal futures listed on? How is it safest for a novice to open a futures account?
ES6 how to determine whether an array is repeated
C sliding verification code | puzzle verification | slidecaptcha
4.25 unlock openharmony technology day! The annual event is about to open!
2018-8-10-使用-Resharper-特性
L2-040 哲哲打游戏 (25 分) 模拟
Program design TIANTI race l3-29 restore file (DFS is over, leaving the original spectrum)
从源码角度分析创建线程池究竟有哪些方式
Programmation Multi - noyaux et multi - processeurs - programmation des tâches
Start redis process
巴比特副总裁马千里:元宇宙时代NPC崛起,数字身份协议或成为入口级产品丨2022元宇宙云峰会
Summary of DOM operation elements
WebSocket 协议详解
What are the mobile phone hardware
2-4. Port binding