当前位置:网站首页>Regular Expressions for Shell Programming
Regular Expressions for Shell Programming
2022-08-09 08:17:00 【direction of light 79】
目录
1、Counts the number of lines of text that contain a character
3、Write non-blank lines to the file
2.2 Find a single repeating character
2.4 查找ooA line that does not start with an upper or lower case letter precedes it
2.6 Find lines that start with a letter except upper or lower case
4.2 Query for rows that contain multiple strings between two letters
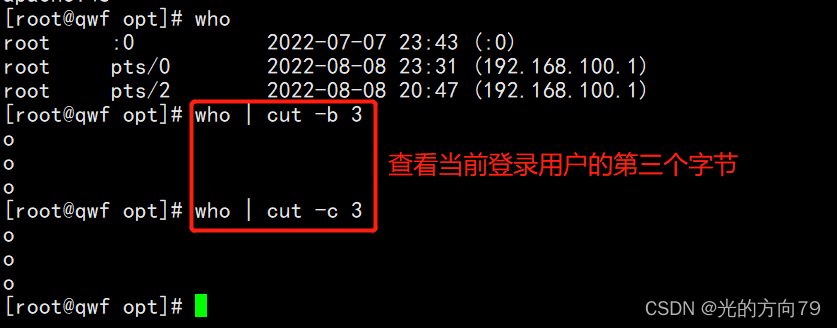
1.2 View the page of the currently logged in user3个字节
1.3 Look at the character positions in the file
2.2 按数字大小排序,separated by colons,给第3列排序
2.4 The output is not output on the screen but to the specified file
4.1 Change all lowercase to uppercase
4.2 Replace letters one by one
4.3 The number of characters on both sides is not equal
4.4 characters are replaced with special characters
引言
在编写处理字符串的程序或网页时,经常会有查找符合某些复杂规则的字符串的需要.正则表达式就是用于描述这些规则的工具.换句话说,正则表达式就是记录文本规则的代码.
一、正则表达式
1、正则表达式概述
- 通常用于判断语句中,用来检查某一字符串是否满足某一格式
- 正则表达式是由普通字符与元字符组成
- 普通字符包括大小写字母、数字、标点符号及一些其他符号
- 元字符是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式
Linux 中常用的有两种正则表达式引擎
- 基础正则表达式:BRE
- 扩展正则表达式:ERE
| 文本处理工具 | 基础正则表达式 | 扩展正则表达式 |
| vi编辑器 | 支持 | \ |
| grep | 支持 | \ |
| egrep | 支持 | 支持 |
| sed | 支持 | \ |
| awk | 支持 | 支持 |
2、基础正则表达式
基础正则表达式是常用的正则表达式部分,常用的元字符及作用如下表所示:
元字符 | 作用 |
^ | 匹配输入字符串的开始位置.除非在方括号表达式中使用,表示不包含该字符集合.要匹配“^” 字符本身,请使用“\^” |
$ | 匹配输入字符串的结尾位置.如果设置了 RegExp 对象的 Multiline 属性,则“$”也匹配‘\n’ 或‘\r’.要匹配“$”字符本身,请使用“\$” | |
. | 匹配除“\r\n”之外的任何单个字符 | |
\ | 将下一个字符标记为特殊字符、原义字符、向后引用、八进制转义符.例如,‘n’匹配字符“n”. ‘\n’匹配换行符.序列‘\\’匹配“\”,而‘\(’则匹配“(” | |
* | 匹配前面的子表达式零次或多次.要匹配“*”字符,请使用“\*” | |
[] | 字符集合.匹配所包含的任意一个字符.例如,“[abc]”可以匹配“plain”中的“a” | |
[^] | 赋值字符集合.匹配未包含的一个任意字符.例如,“[^abc]”可以匹配“plain”中“plin”中的任何一个字母 | |
[n1-n2] | 字符范围.匹配指定范围内的任意一个字符.例如,“[a-z]”可以匹配“a”到“z”范围内的任意一个小写字母字符. 注意:只有连字符(-)在字符组内部,并且出现在两个字符之间时,才能表示字符的范围;如 果出现在字符组的开头,则只能表示连字符本身 | |
{n} | n 是一个非负整数,匹配确定的 n 次.例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个 o | |
{n,} | n 是一个非负整数,至少匹配 n 次.例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有 o.“o{1,}”等价于“o+”.“o{0,}”则等价于“o*” | |
{n,m} | m 和n 均为非负整数,其中 n<=m,最少匹配 n 次且最多匹配 m 次 |
注意 egrep, awk使用{n}、{n,}、{n,m}匹配时“{}"前不用加“\”
egrep -E -n 'wo{2}d' test.txt -E用于显示文件中符合条件的字符
egrep -E -n 'wo{2,3}d' test.txt3、扩展正则表达式
- 扩展正则表达式是对基础正则表达式的扩充和深化
- 支持的工具有 egerp 和 awk
- 扩展正则表达式元字符
元字符 | 作用与示例 |
+ | 作用:重复一个或者一个以上的前一个字符 示例:执行“egrep -n 'wo+d' test.txt”命令,即可查询"wood""woood""woooooood"等字符串 |
? | 作用:零个或者一个的前一个字符 示例:执行“egrep -n 'bes?t' test.txt”命令,即可查询“bet”“best”这两个字符串 |
| | 作用:使用或者(or)的方式找出多个字符 示例:执行“egrep -n 'of|is|on' test.txt”命令即可查询"of"或者"if"或者"on"字符串 |
() | 作用:查找“组”字符串 示例:“egrep -n 't(a|e)st' test.txt”.“tast”与“test”因为这两个单词的“t”与“st”是重复的,所以将“a”与“e”列于“()”符号当中,并以“|”分隔,即可查询"tast"或者"test"字符串 |
()+ | 作用:辨别多个重复的组 示例:“egrep -n 'A(xyz)+C' test.txt”.该命令是查询开头的"A"结尾是"C",中间有一个以上的 "xyz"字符串的意思 |
定位符
- ^ 匹配输入字符串开始的位置
- $匹配输入字符串结尾的位置
非打印字符
- \n匹配一个换行符
- \r匹配一个回车符
- \t匹配一个制表符
二、grep命令
grep命令使用正则表达式来搜索文本,并且把匹配的文本打印出来
格式:
grep [options] pattern [file]
option表示选项,pattern表示匹配的模式.file表示一系列文件名.
- 1
- 2
- 3
常用选项:
-c 只打印匹配的文本行的次数,不显示文本内容.
-i 匹配时忽略字母大小写
-h 当搜索多个文件,不显示匹配文件名前缀.
-l 只列出含义匹配的文本行的文件的文件名,不显示其具体匹配的内容.
-n 列出所有匹配的文本行,并显示行号
-s 不显示关于不存在或无法读取文件的错误信息
-v 只显示不匹配的文本行,反向选择,显示与搜索字符串不相符的行.
-w 匹配整个单词
-x 匹配整个文本行
-r 递归搜索,不仅搜索当前目录,还有各级子目录
-E 开启扩展(extend)的正则表达式
--color=auto 可以将找到的关键词部分加上颜色的显示
1、Counts the number of lines of text that contain a character
-c 只打印匹配的文本行的次数,不显示文本内容.

2、不区分大小写查找the所有的行
-i 匹配时忽略字母大小写

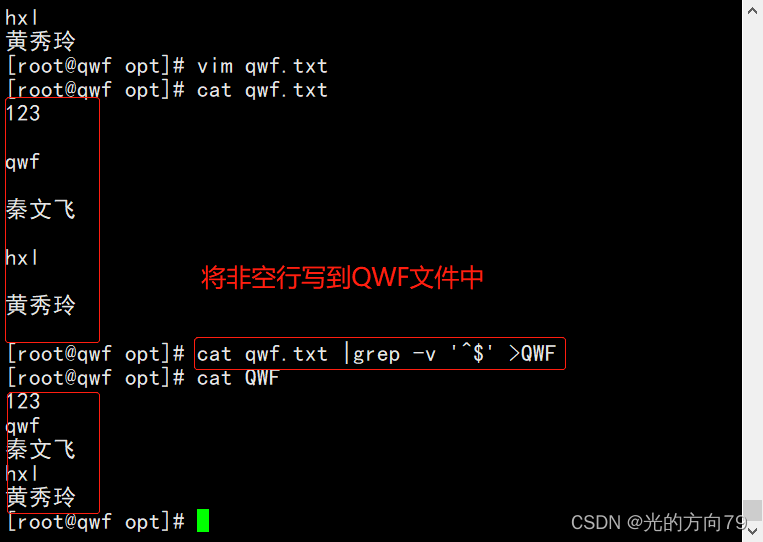
3、Write non-blank lines to the file
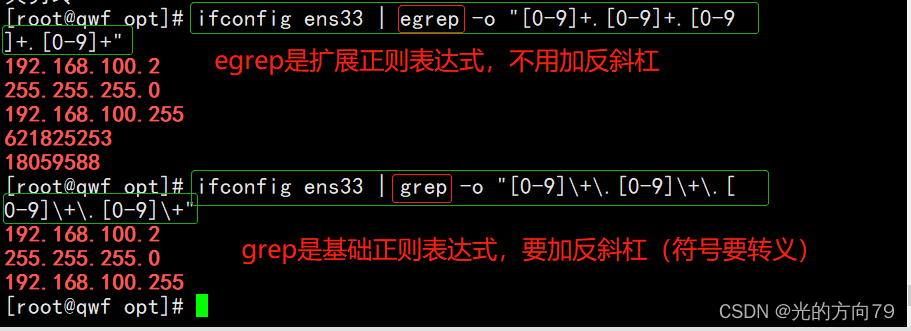
4、过滤出IP地址
三、元字符操作案例
1、查找特定字符
查找出test文件中the的位置,其中“-n”表示显示行号、“-i”表示不区分大小写.命令执行后,符合匹配标准的字符, 字体颜色会变为红色.

2、Find a specific set of characters
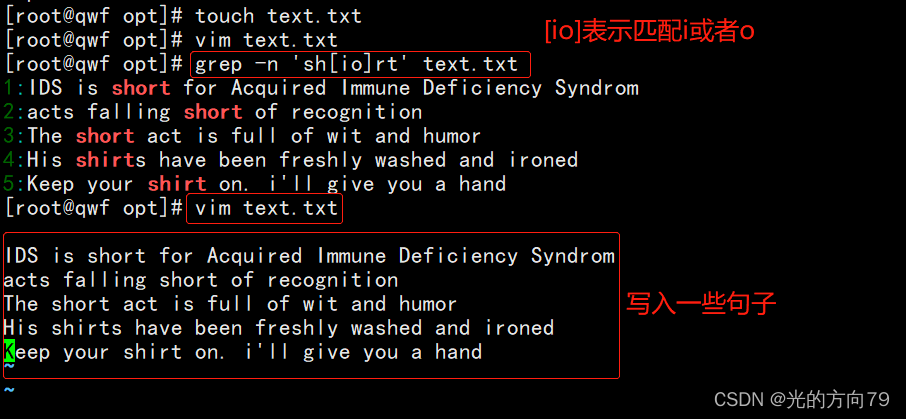
2.1 查找既有i又有o的特殊字符
想要查找“shirt”与“short”这两个字符串时,可以发现这两个字符串均包含“sh”与“rt”.此时执行以下命令即可同时查找到“shirt”与“short”这两个字符串,其中“[]”中无论有几个字符, 都仅代表一个字符,也就是说“[io]”表示匹配“i”或者“o”.
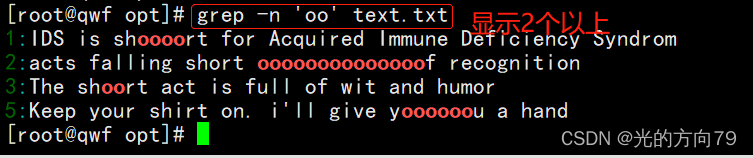
2.2 Find a single repeating character
查找重复字符,例如“oo”时,会显示两个o及两个o以上的行
2.3 查找oo前面不是R开头的行
从后往前看,例如当出现Rooot时,This line will be displayed,Because looking from the back to the frontoo前面还是o,符合条件

2.4 查找ooA line that does not start with an upper or lower case letter precedes it


2.5 查找包含数字的行

2.6 Find lines that start with a letter except upper or lower case

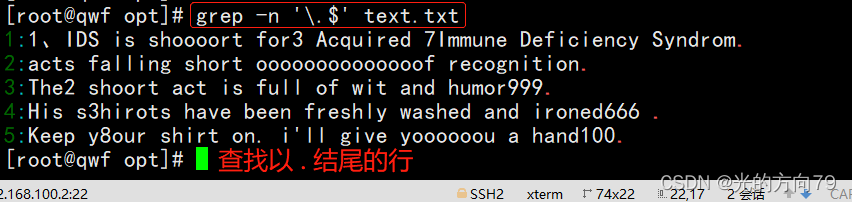
2.7 查找以.结尾的行
3、查找以w开头,以d结尾的行

4、查找连续字符范围“{}”
使用“{}”字符时,需要利用转义字符“\”,将“{}”字符转换成普通字符.
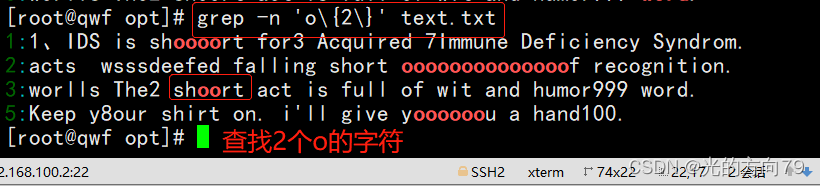
4.1 查询2个o的字符
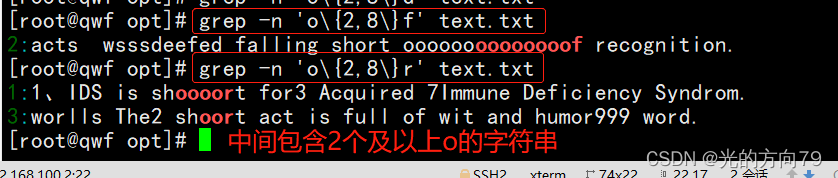
4.2 Query for rows that contain multiple strings between two letters
四、cut、sort、uniq、tr
1、cut-列截取工具
- cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出.
- 如果不指定 File 参数,cut 命令将读取标准输入.必须指定 -b、-c 或 -f 标志之一
- cut只擅长于处理单个字符为间隔的文本,-b只能分割字母,-c既可以分割字母也可以分割中文
选项
-b:按字节截取
-c:按字符截取,常用于中文
-d:指定以什么为分隔符截取,默认为制表符
-f:通常和-d一起
- 1
- 2
- 3
- 4
- 5
- 6
- 7
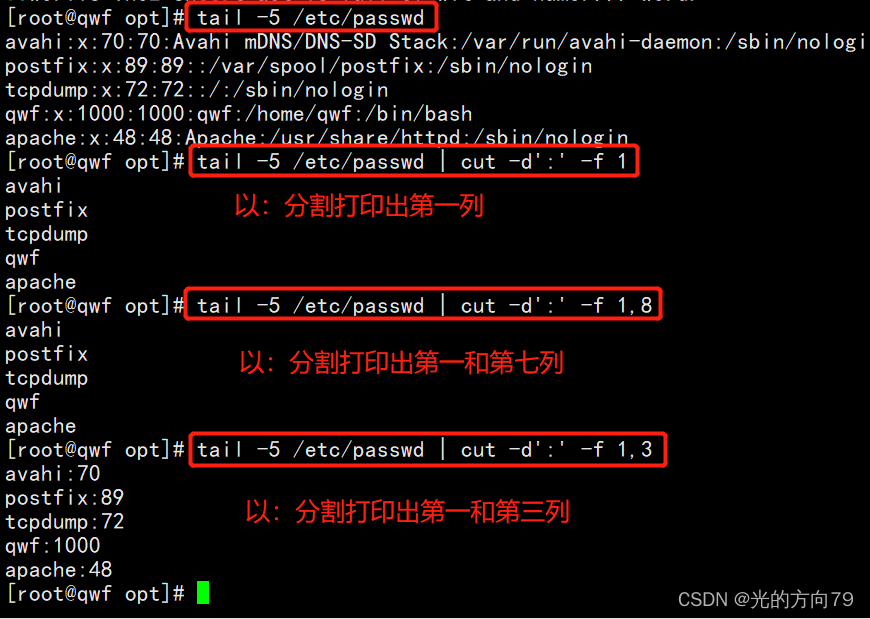
1.1 查看/etc/passwd特定列
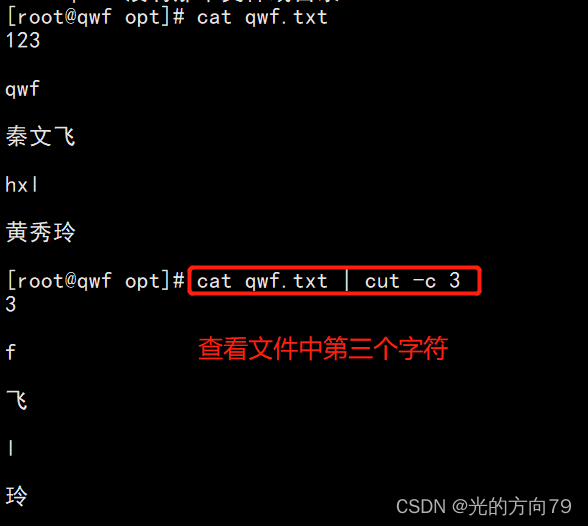
1.2 View the page of the currently logged in user3个字节
cut只擅长于处理单个字符为间隔的文本,-b只能分割字母,-c既可以分割字母也可以分割中文
1.3 Look at the character positions in the file
2、sort-排序工具
sort 是一个以行为单位对文件内容进行排序的工具,也可以根据不同的数据类型来排序.例如数据和字符的排序就不一样.
sort [选项] 参数
- 1
常用选项
-t:指定分隔符,默认使用[Tab]键或空格分隔
-k:指定排序区域,哪个区间排序
-n:按照数字进行排序,默认是以文字形式排序
-u:等同于 uniq,表示相同的数据仅显示一行,注意:如果行尾有空格去重就不成功
-r:反向排序,默认是升序,-r就是降序
-o:将排序后的结果转存至指定文件
-f: 忽略大小写,会将小写的字母都转换为大写字母来进行比较
-b: 忽略每行前面的空格
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
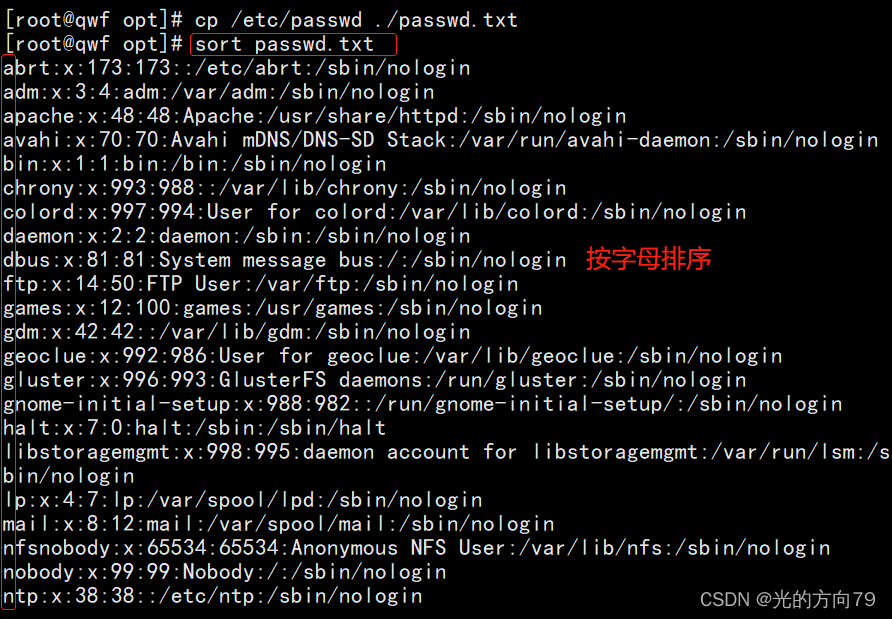
2.1 按字母排序
不加任何选项默认按第一列升序,字母的话就是从a到z由上而下显示
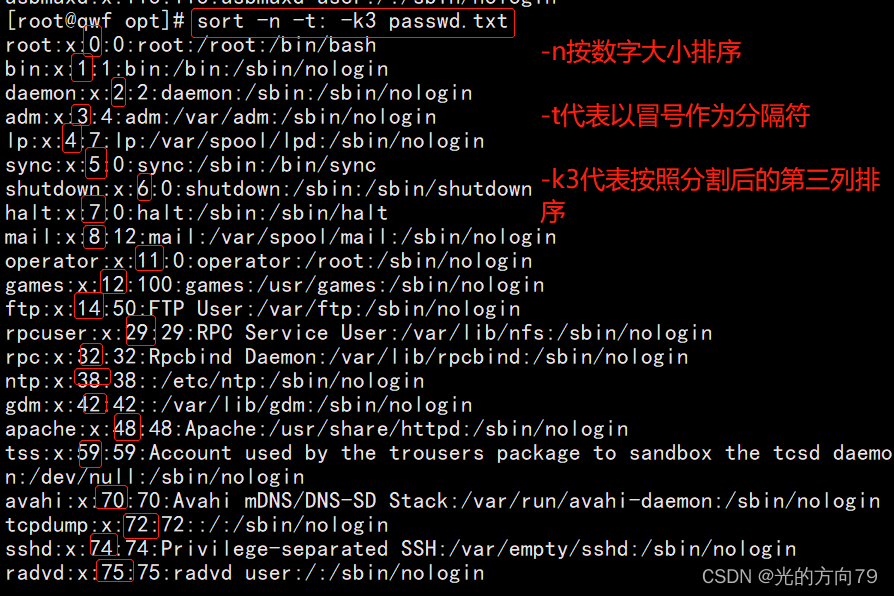
2.2 按数字大小排序,separated by colons,给第3列排序
2.3 反向排序
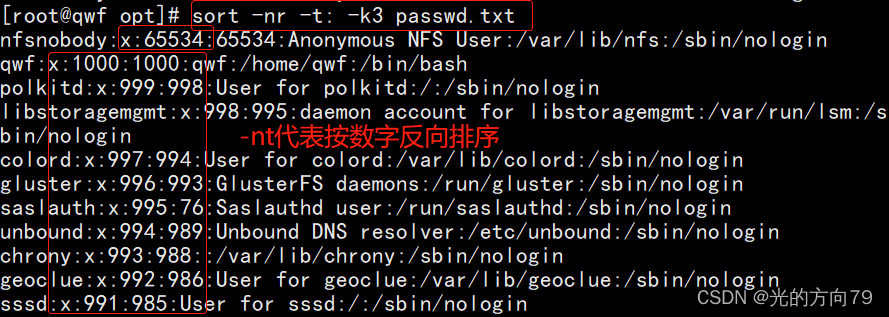
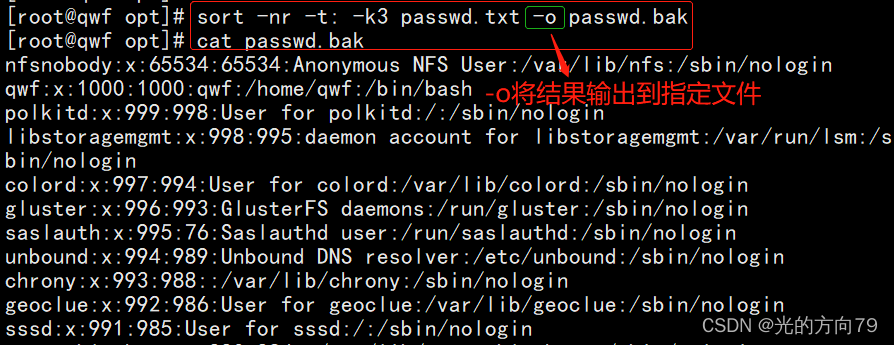
2.4 The output is not output on the screen but to the specified file
2.5 去掉文件中重复的行(-u等同于uniq)
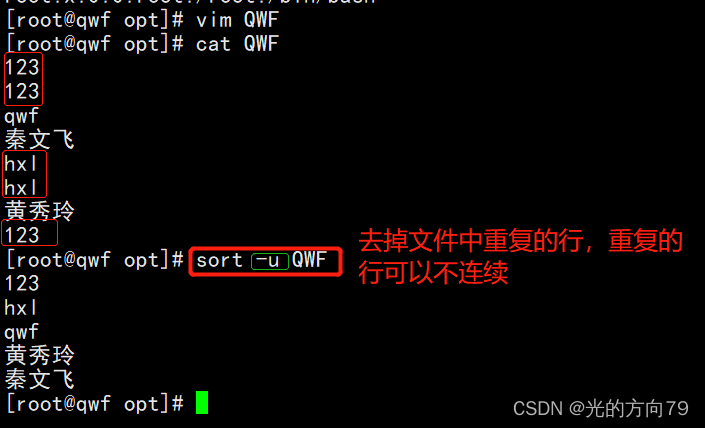
3、uniq-去重工具
主要用于去除连续的重复行
注意:是连续的行,所以通常和sort结合使用先排序使之变成连续的行再执行去重操作,否则不连续的重复行他不能去重
uniq [选项] 参数
-c:对重复的行进行计数;
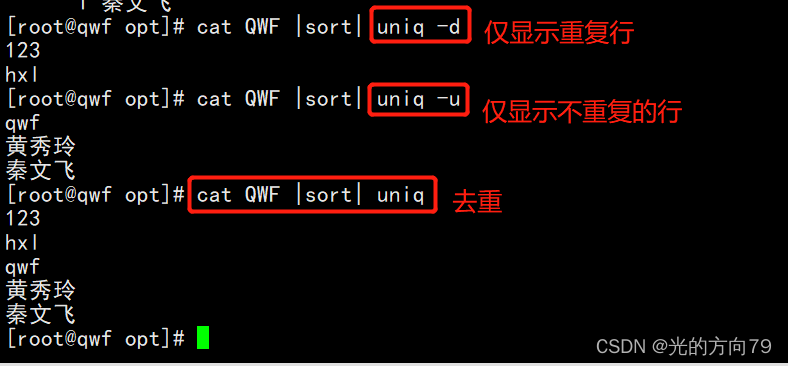
-d:仅显示重复行;
-u:仅显示出现一次的行3.1 统计重复行的次数
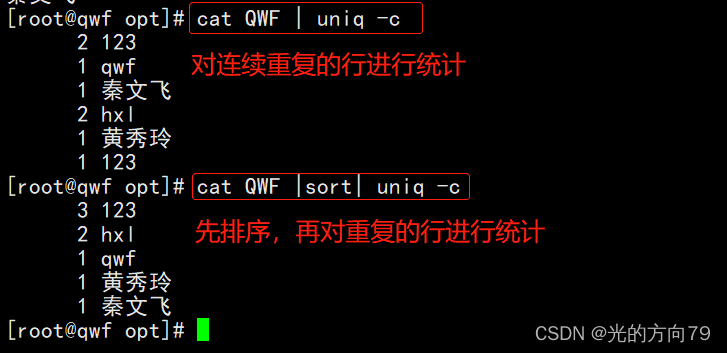
3.2 结合sort去重
4、tr-修改工具
- 它可以用一个字符来替换另一个字符,或者可以完全除去一些字符,也可以用它来除去重复字符
- 从标准输入中替换、缩减和/或删除字符,并将结果写到标准输出.
格式
tr [选项]… SET1 [SET2]
- 1
常用选项
-d 删除字符
-s 删除所有重复出现的字符,只保留第一个
- 1
- 2
- 3
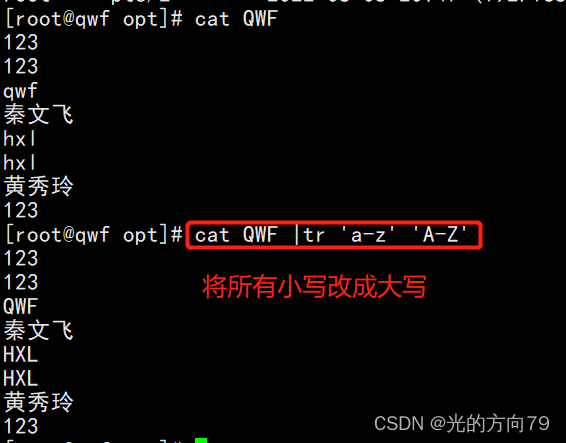
4.1 Change all lowercase to uppercase
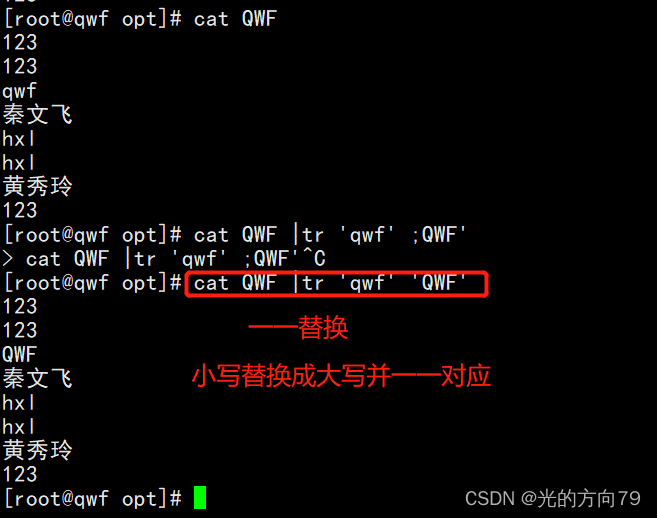
4.2 Replace letters one by one
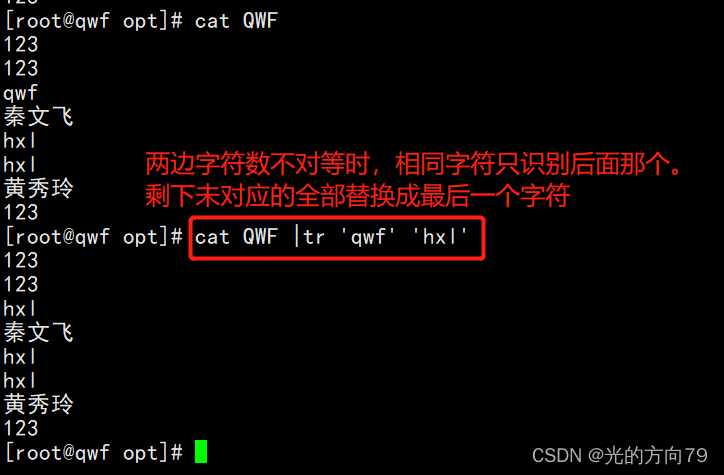
4.3 The number of characters on both sides is not equal
When the number of characters on both sides is not equal,Only the latter one is recognized for the same character,The remaining uncorresponding characters are all the last replacement characters
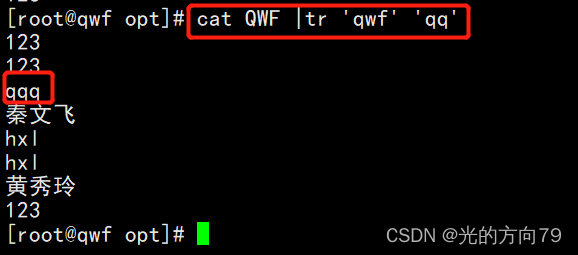
4.4 characters are replaced with special characters
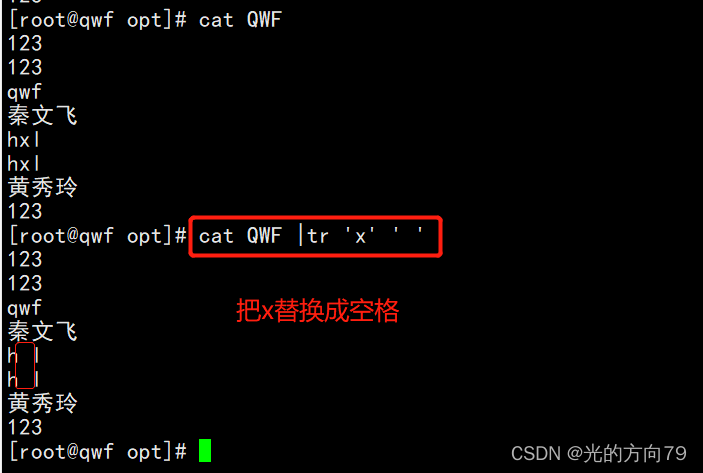
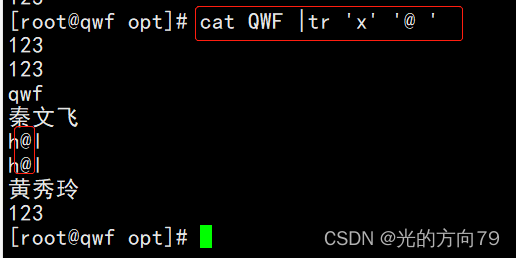
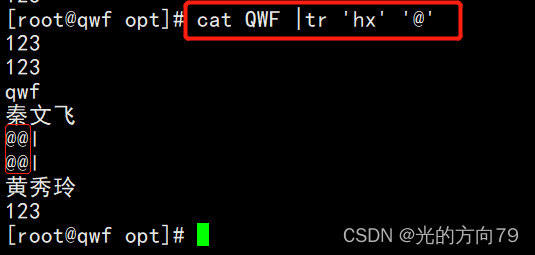
4.5 删除字符
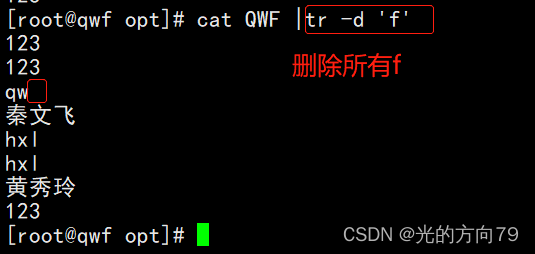
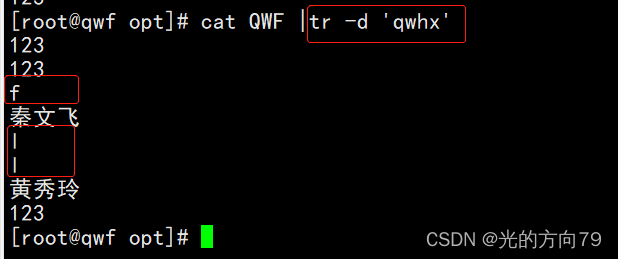
4.6 对字符去重
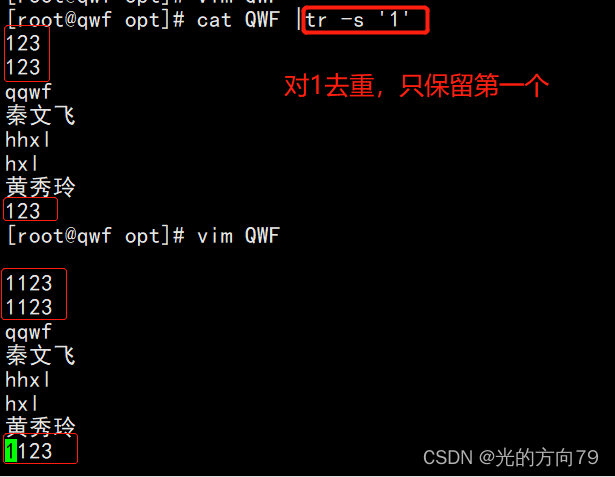
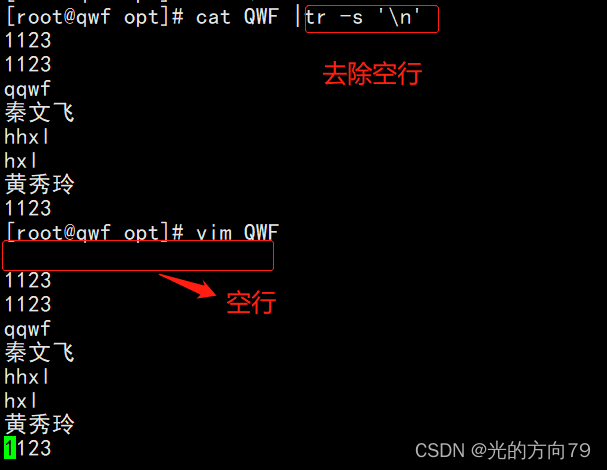
五、总结
This article mainly talks about the usage of basic regular expressions and extended regular expression metacharacters,以及grepCommand usage and four methods commonly used by text processors,Four commonly used methods of text processors includecut列截取工具、sort排序工具、uniqdeduplication tool andtr修改工具.
边栏推荐
猜你喜欢



随机推荐
EMQ X message server learning record - prepare for the subsequent completion
Euclid and the game
LAN Technology - 6MSTP
磁盘管理与挂载
传输层协议介绍
ncnn 推理猫狗识别
三层交换机原理及配置
Process synchronization and mutual exclusion problem
Cookie and Session Details
C语言笔记 学习预处理 学习宏定义
IP地址及子网划分
Notes on OpenHarmony Open Source Meeting (Nanjing Station)
消息中间件(MQ)前置知识介绍(必看)
世界顶尖3D Web端渲染引擎:HOOPS Communicator技术介绍(一)
Solidworks 2022 Inspection新增功能:光学字符识别、可自定义的检查报告
编程洗衣机:字符串输出后的乱码
nyoj58 最少步数(DFS)
继承中的运算符重载:输入输出的传奇
IO byte stream reads text Chinese garbled
3D软件开发工具HOOPS全套产品开发介绍 | HOOPS Exchange、HOOPS Communicator