当前位置:网站首页>Segmentation Learning (loss and Evaluation)
Segmentation Learning (loss and Evaluation)
2022-08-11 09:22:00 【Ferry fifty-six】
Reference
Loss function for semantic segmentation
(cross entropy loss function)
- Pixel-wise cross-entropy
- Also need to consider the problem of sample equalization (some)
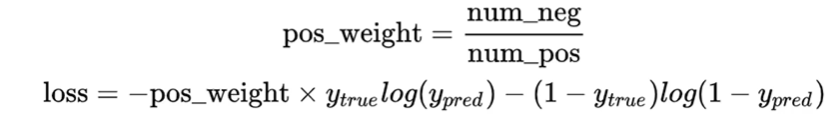
The cross-entropy loss function here adds the pos_weight parameter.The proportions of the foreground and background are different, making the importance of each pixel inconsistent.In general, we set this parameter according to the proportion of positive and negative examples.
Here will explain the next two-category cross-entropy loss function (remove pos_weight):
The smaller the loss function, the better
- log function is as follows
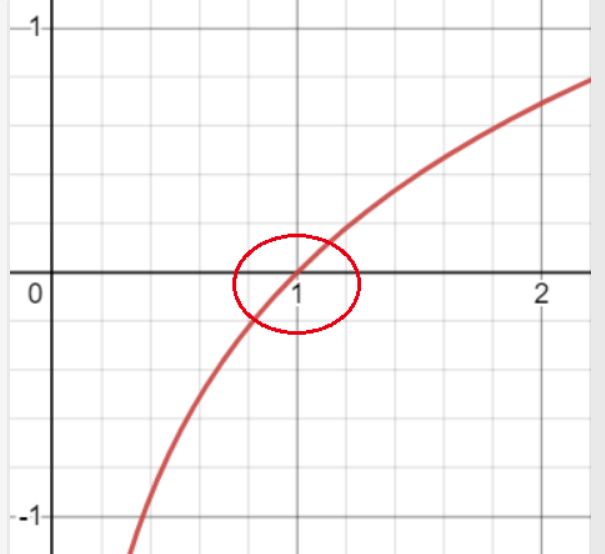
As can be seen from the imageWhen the X value is closer to 1, the absolute value of Y is smaller, and when the X value is closer to 0, the absolute value of Y is larger.
eg:
y_true: true sample label 0, 1
y_pred: sample predicted label 0, 1
| - | y_true=0 | y_true=1 |
|---|---|---|
| y_pred=0 | At this time, the loss function is brought in, loss=0, you can see that when y_true=0, the closer y_pred is to 0, the smaller the absolute value of the loss function is | When y_true=1, the closer y_pred is to 0, the greater the absolute value of the loss function |
| y_pred=1 | When y_true=0, the closer y_pred is to 1, the greater the absolute value of the loss function | When y_true=1, the closer y_pred is to 1, the smaller the absolute value of the loss function is |
It can be seen from this that the closer y_pred is to the true label y_true, the smaller its loss function is, and can distinguish foreground label 1 and background label 0.
We also need to pay attention to the loss of judging the true label as 1 and the predicted label when y_true log(y_pred), think about it, when the true label is 0, this part is directly 0, so the other part is judged trueLoss of label 0
(Focal loss)
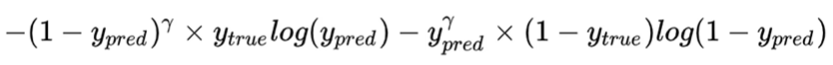
Ideas: Difficulty of pixels: The more difficult the sample, the greater the reward.
Implementation: Based on the cross entropy loss function, increase the difference between the real labels 0 and 1 and the predicted labels 0 and 1 γ \gamma γPower parameter.
Assumptions γ \gamma γ=2
The image of the quadratic square function is as follows: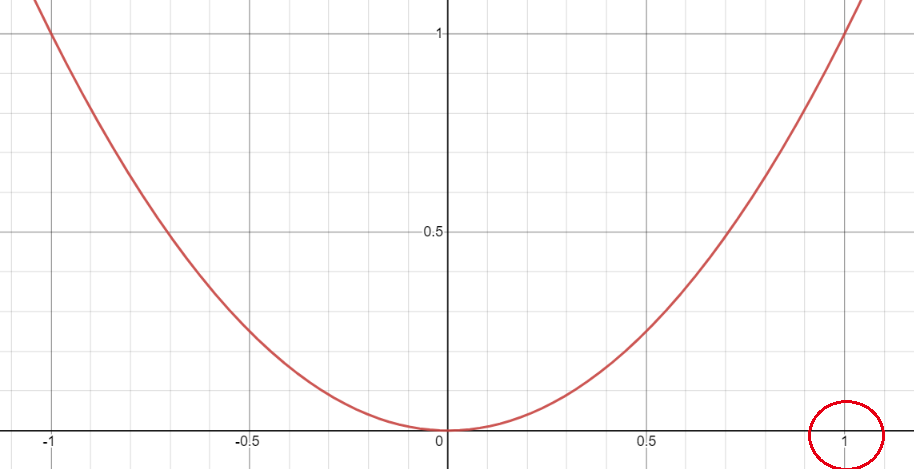
We can see that the function's growth trend between [0, 1]is increasing, so when the difference between the real label y_true and the predicted label y_pred is very large, the difference is close to 1, and the value after the square term is also very large. When the difference is close to 1, the value after the square termIt is also very small, so for the samples that are easy to be divided, the loss incentive is very small, and for the samples that are difficult to be divided, the loss incentive is very large.This makes a distinction between difficult and easy samples (or pixels).
Weights in combined sample size alpha \alpha α (the ratio of positive and negative samples mentioned above pos_weight), it is the complete Focal Loss function.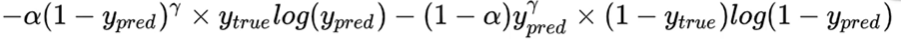
Evaluation Criteria
IoU: Intersection and Union Ratio (the intersection of the yellow parts in the figure/the union of the yellow parts)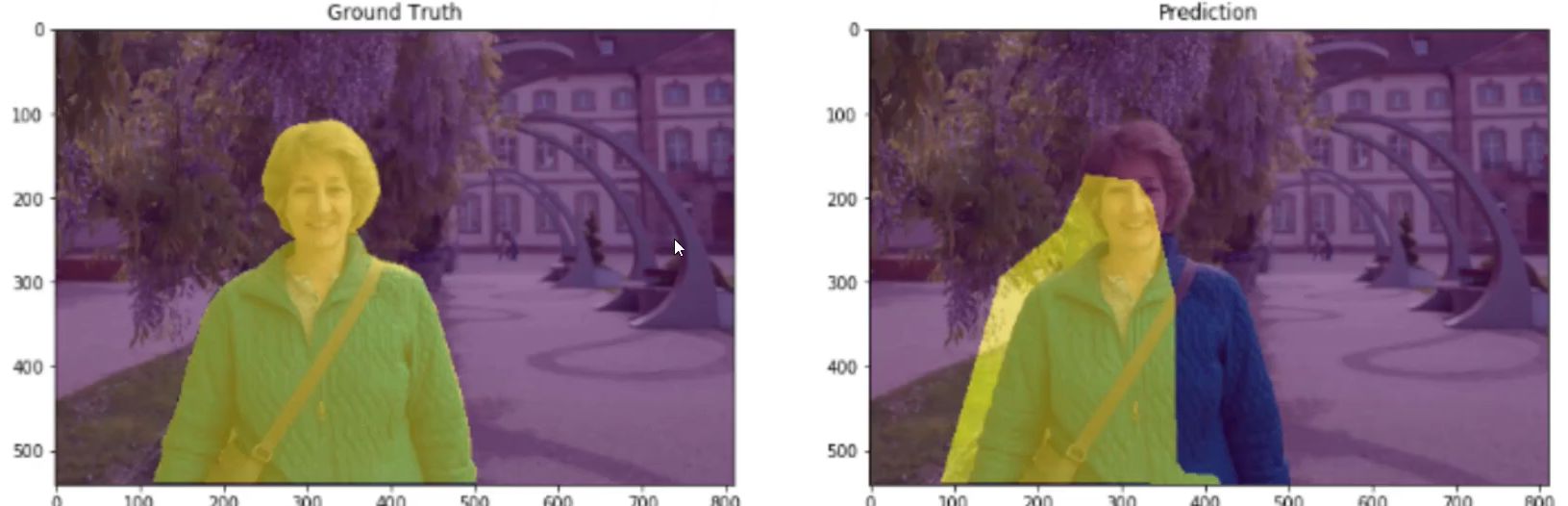
MIoU (calculate the average of all categories, generally used as a segmentation task evaluation index)
边栏推荐
猜你喜欢


随机推荐
当你领导问你“还有其他的么”
WordpressCMS主题开发02-制作顶部header.php和footer.php
MySql事务
刷题错题录2-向上取整、三角形条件、字符串拼接匹配、三数排序思路
基于 VIVADO 的 AM 调制解调(3)仿真验证
表达式必须具有与对应表达式相同的数据类型
深度学习100例 —— 卷积神经网络(CNN)识别眼睛状态
Go 语言的诞生
IPQ4019/IPQ4029 support WiFi6 MiniPCIe Module 2T2R 2×2.4GHz 2x5GHz MT7915 MT7975
安装ES7.x集群
工业检测深度学习方法综述
Lightweight network (1): MobileNet V1, V2, V3 series
SQL语句
Adobe LiveCycle Designer 报表设计器
gRPC系列(四) 框架如何赋能分布式系统
OAuth Client默认配置加载
持续集成/持续部署(2)Jenkins & SonarQube
设置Vagrant创建的虚拟机名称和内存
Primavera Unifier 自定义报表制作及打印分享
四级独创的阅读词汇表