当前位置:网站首页>【C语言进阶】第一篇深度剖析整数数据在内存中的存储(一)
【C语言进阶】第一篇深度剖析整数数据在内存中的存储(一)
2022-08-11 05:16:00 【小吕编程之路】

前言
整数数据介绍
数据类型介绍
| 类型 | |
|---|---|
| char | 字符数据类型 |
| short | 短整型 |
| int | 整形 |
| long | 长整形 |
| long long | 更长的整形 |
| float | 单精度浮点型 |
| double | 双精度浮点型 |
unsigned 和signed
再讲整数数据类型之前我们先来讲一下这两个关键字
unsigned:无符号 signed:有符号
在我们生活中有很多的数据,数据也分正数和负数 ,比如有些数值,有正数,没有负数(身高)
有些数值 ,有正数也有负数(温度)
比如温度-5 和+15,这是我们要用符号要区分数据的大小,需要有正负来描述数据,这时我就要用到unsigned和signed来描述。
整数数据家族
| char | unsigned char ,signed char |
|---|---|
| short | unsigned short, signed short |
| int | unsigned int,signed int |
| long | unsigned long ,signed long |
| long long | unsigned long long ,signed long long |
指针类型
int *pa;
char *pb;
float *pc;
void *pd;
void 表示空类型(无类型)
通常应用于函数的返回类型、函数的参数、指针类型
整数数据在内存中的存储
原码,反码,补码
计算机中的整数有三种2进制表示方法,即原码、反码和补码。
三种表示方法均有符号位和数值位两部分,符号位都是用0表示“正”,用1表示“负”,而数值位
正数的原、反、补码都相同。
负整数的三种表示方法各不相同。
原码 反码 补码转换方法:
原码
直接将数值按照正负数的形式翻译成二进制就可以得到原码。
反码
将原码的符号位不变,其他位依次按位取反就可以得到反码。
补码
反码+1就得到补码。
代码演示:
#include<stdio.h>
int main()
{
int a = 20;//4byte(字节)=32bit
//00000000000000000000000000010100 20原码
//00000000000000000000000000010100 20反码
//00000000000000000000000000010100 20补码
//20是正整数,所以原码,补码,反码相同
int b = -20;
//10000000000000000000000000010100 原码
//11111111111111111111111111101011 反码
//11111111111111111111111111111100 补码
return 0;
}
到这里,我们可看出,对于整形来说:数据存放内存中其实存放的是补码。
下面我们一个代码片段来解释说明

b的二进制转换为十六进制,是与内存中存储的十六进制是相同的。所以由此可以得出::数据存放内存中其实存放的是补码。
为什么内存存放是补码
使用补码,可以将符号位和数值域统
一处理;同时,加法和减法也可以统一处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。
代码演示
大家可以想想这个代码结果是什么,可能你们会直接会说-1 -1 -1;但结果却有所不同,下面听我解释一番。
#include<stdio.h>
int main()
{
char a = -1;
//10000000000000000000000000000001 原码
//11111111111111111111111111111110 反码
//11111111111111111111111111111111 补码
//上面我们已经说了,内存中存储的是补码,但是char内存中的大小为一个节
//只能存储8个bit位,所以这里会发生截断
//截断后存储在a中
//11111111 -a
//这里是%d形式打印,然而a的类型为char,所以这里会整形提升,所以要高位补位。
//这里a是有符号,用符号位进行补位
//11111111111111111111111111111111 补位后的a
//数据打印出来是原码,所以我们要将部位后的a,转换成原码
//11111111111111111111111111111110 反码
//10000000000000000000000000000001 原码,得出结果为-1,与打印值相同。
signed char b = -1;
//11111111111111111111111111111111 补码
//11111111 -b
//这个也是同理上述方法
unsigned char c = -1;
//11111111111111111111111111111111 补码
//11111111 -c
//这里有略微的改变就是unsigned,unsigned无符号的作用
//截断后存储在c中
//11111111 -c unsigned忽略符号位,高位补0.
//00000000000000000000000011111111 补位后的c
//符号位为0,是正整数
//所以原码,补码,反码相同
//00000000000000000000000011111111 原码
printf("a=%d,b=%d,c=%d", a, b, c);
return 0;
}
打印结果:
图片解读: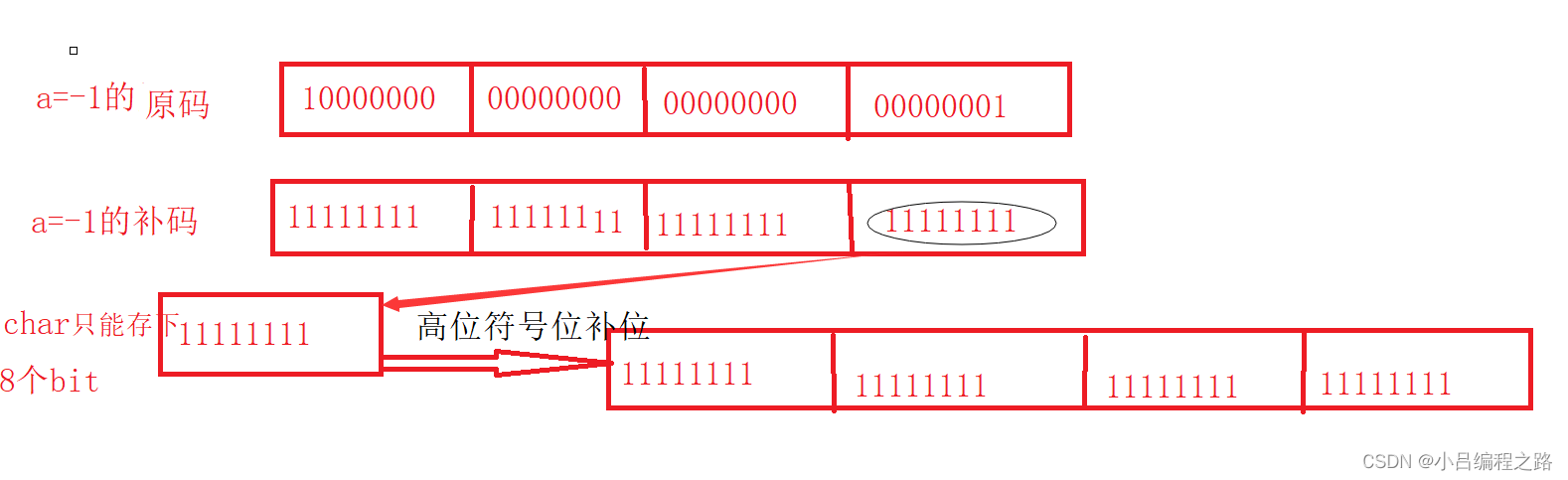
下面我们在再来一个代码对上面知识有一个更好的了解
代码演示:
%u是打印无符号整形,认为内存中存放的补码对应的是一个无符号数
%d是打印有符号整形,认为内存中存放的补码对应的是一个有符号数
#include<stdio.h>
int main()
{
char a = -128;
//10000000000000000000000010000000 原码
//11111111111111111111111101111111 反码
//11111111111111111111111110000000 补码
//10000000 -a 截断后的二进制
//11111111111111111111111110000000 符号位高位补位
//%u打印无符号整形,所以我们认为他的反码 补码 原码相同。
char b = -128;
//10000000000000000000000010000000 原码
//11111111111111111111111101111111 反码
//11111111111111111111111110000000 补码
//10000000 -a 截断后的二进制
//11111111111111111111111110000000 符号位高位补位
//%d打印有符号的整形,所以我们要将补码换成原码。
//11111111111111111111111101111111 反码
//10000000000000000000000010000000 原码
printf("%u\n %d\n", a,b);
return 0;
打印结果:
无符号和有符号范围
图解:
以char型为例
以signed为例,可以发现它的对应范围是成一个圆的循环。
大小端
什么是大小端
大端(存储)模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址
中;
小端(存储)模式,是指数据的低位保存在内存的低地址中,而数据的高位,,保存在内存的高地
址中
图解以字节为单位存储
为什么会有大小端之分呢?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元
都对应着一个字节,一个字节为8 bit。但是在C语言中除了8 bit的char之外,还有16 bit的short型,32 bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式
判断当前机器的字节序(大小端之分)
代码实现
#include<stdio.h>
int main()
{
int a = 1;
char* p = (char*)&a;
if (*p == 1)
printf("小端\n");
else
printf("大端\n");
return 0;
}
图解
分析:
我们从小端中拿出第一个字节01,大端中拿出第一个字节00,这样就能判断
是小端还是大端。 用char的指针来访问第一个字节,charp解引用就访问一个字节,&a拿出的地址强制转换成char型再付给charpa的指针,对pa解引用就可以访问一个字节的内容。
总结
码文不易,给个三连,谢谢

边栏推荐
猜你喜欢

更新啦~人生重开模拟器自制
搭建PX4开发环境

阿里云无法远程连接数据库MySQL错误码10060解决办法_转载

(1) Docker installs Redis in practice (one master, two slaves, three sentinels)

0708作业---商品信息

Flask framework learning: template rendering and Get, Post requests

(二)性能实时监控平台搭建(Grafana+Prometheus+Jmeter)

深入理解线程、进程、多线程、线程池

Solidrun hummingboard制作SD卡

【win10+cuda7.5+cudnn6.0安装caffe③】编译及测试caffe
随机推荐
(3) How Redis performs stress testing
CentOS7静默安装Oracle11g_转载
原生态mongo连接查询代码
【win10+cuda7.5+cudnn6.0安装caffe②】安装Visual Studio 2013和caffe
并发编程之线程基础
pytorch中tensor 生成的函数
【转载】CMake 语法 - 详解 CMakeLists.txt
flaks framework learning: adding variables to the URL
【背包】采药题解
CSDN 社区内容创作规范
信息学奥赛
QtDataVisualization 数据3D可视化
Django--20实现Redis支持、上下文以及上下文和接口的交互
Linux中安装redis
redis集群模式--解决redis单点故障
做款好喝的茶饮~
【分享】一个免费语料库
第4章 复合类型-2(指针)
实战noVNC全过程操作(包含遇到的问题和解决)
简单做份西红柿炒蛋778