当前位置:网站首页>部署spark2.2集群(standalone模式)
部署spark2.2集群(standalone模式)
2022-08-08 10:44:00 【51CTO】
欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码): https://github.com/zq2599/blog_demos
- 一起来实战部署spark2.2集群(standalone模式)
版本信息
- 操作系统 CentOS 7.5.1804
- JDK:1.8.0_191
- scala:2.12.8
- spark:2.3.2
机器信息
- 本次实战用到了三台机器,相关信息如下:
| IP 地址 | 主机名 | 身份 |
|---|---|---|
| 192.168.150.130 | master | spark的master节点 |
| 192.168.150.131 | slave1 | spark的一号工作节点 |
| 192.168.150.132 | slave2 | spark的二号工作节点 |
- 接下来开始实战;
关闭防火墙
- 执行以下命令永久关闭防火墙服务:
设置hostname(三台电脑都做)
- 修改/etc/hostname文件,将几台电脑的主机名分别修改为前面设定的master、slave0等;
设置/etc/hosts文件(三台电脑都做)
- 在/etc/hosts文件尾部追加以下三行内容,三台电脑追加的内容一模一样,都是下面这些:
创建用户(三台电脑都做)
- 创建用户和用户组,并指定home目录的位置:
- 设置spark用户的密码:
- 以spark账号的身份登录;
文件下载和解压(三台电脑都做)
- 分别去java、scala的官网下载以下两个文件:
- 上述两个文件下载到目录/home/spark下,依次解压后,/home/spark下的内容如下所示:
- 修改/home/spark文件夹下的.bash_profile文件,在尾部增加以下内容(spark相关的是后面会用到的,这里把配置先写上):
- 执行以下命令,使得.bash_profile的修改生效:
- 分别执行java -version和scala -version命令,检查上述设置是否生效:
spark的设置(只在master机器操作)
- 登录master机器:
- 去spark的官网下载文件spark-2.3.2-bin-hadoop2.7.tgz,下载到目录/home/spark下,在此解压;
- 进入目录/home/spark/spark-2.3.2-bin-hadoop2.7/conf;
- 执行以下命令,将"spark-env.sh.template"更名为"spark-env.sh":
- 打开文件spark-env.sh,在尾部增加以下内容:
- 进入目录/home/spark/spark-2.3.2-bin-hadoop2.7/conf,执行以下命令,将slaves.template更名为slaves:
- 打开文件slaves,将尾部的localhost删除,再增加以下内容:
- 以上就是所有设置,接下来要将spark文件夹同步到其他机器上
将spark文件夹同步到其他机器
- 在master机器执行以下命令,即可将整个spark文件夹同步到slave1:
- 期间会要求输入slave1的密码,输入密码后即可开始同步;
- 在master机器执行以下命令,即可将整个spark文件夹同步到slave2:
- 期间会要求输入slave2的密码,输入密码后即可开始同步;
启动spark
- 以spark账号登录master机器,执行以下命令即可启动spark集群:
- 启动过程中,会要求输入slave1、slave2的密码,输入即可;
- 为了避免每次启动和停止都要输入slave1和slave2的密码,建议将三台机器配置ssh免密码登录,请参考《Docker下,实现多台机器之间相互SSH免密码登录》
- 启动成功后,可以通过浏览器查看启动情况,如下图,地址是: http://192.168.150.130:8080/
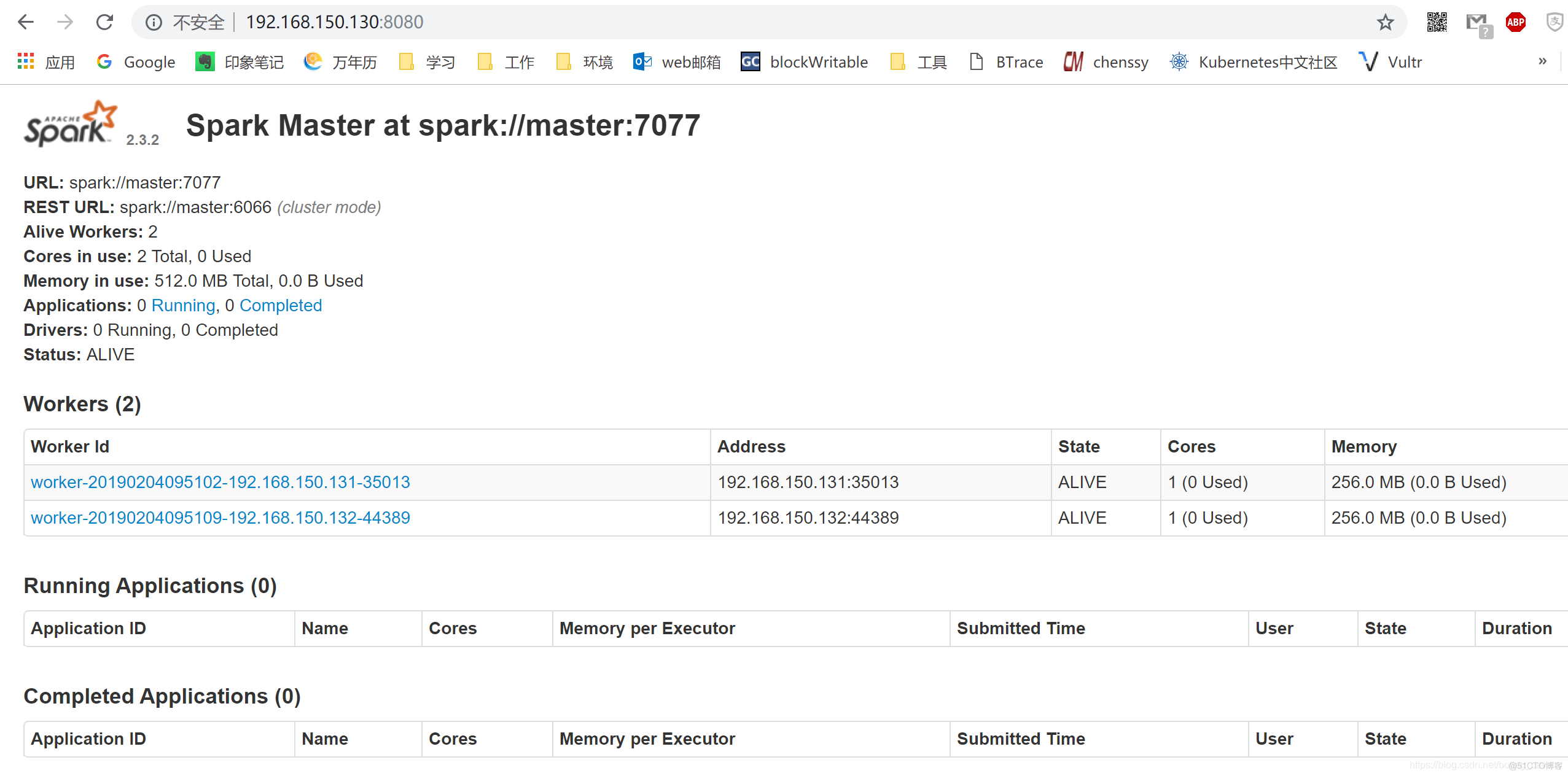
- 至此,spark集群部署成功,接下来的章节,我们会一起进行更多的spark实战;
欢迎关注51CTO博客:程序员欣宸
边栏推荐
- Tensorflow基础概念
- About the Celery service report under win Process 'Worker' exited with 'exitcode 1' [duplicate]
- 详细讲解修改allure报告自定义的logo和名称中文
- 使用ApacheBench来对美多商城的秒杀功能进行高并发压力测试
- Thoroughly understand the differences and application scenarios of session, cookie, sessionStorage, and localStorage (interview orientation)
- dedecms支持Word图文一键导入
- 键值数据库是将什么作为标识符的呢?
- 网盘目录搜索系统源码+搭建教程
- Dubins曲线学习笔记及相关思考
- 关于振弦采集模块及采集仪振弦频率值准确率的问题
猜你喜欢








随机推荐
五、树结构
在mysql中,存储过程中参数为中文 乱码解决方案
idea安装步骤
LeetCode_14_最长公共前缀
一、用户数据仓库
LeetCode_66_加一
使用文档数据库的目的是什么呢?
Optional common method analysis
分布式系统设计策略
Mysql的分布式事务原理理解
Oracle ASM磁盘组使用新存储替换旧存储方案
贵州酒店集团特产券解析
Loadrunner的录制event为0的问题解决方法与思路
一文读懂配置管理(CM)
MySQL源码解析之执行计划
300万招标!青岛市医疗保障局主机数据库中间件运行维护服务项目
关于振弦采集模块及采集仪振弦频率值准确率的问题
About the Celery service report under win Process 'Worker' exited with 'exitcode 1' [duplicate]
新款“廉价”SUV曝光,安全、舒适一个不落
有哪些典型的列存储数据库呢?