当前位置:网站首页>kakka rebalance解决方案
kakka rebalance解决方案
2022-08-09 17:16:00 【锋火连天】
kakka rebalance解决方案
简介
apache kafka的重平衡(rebalance),一直以来都为人诟病。因为重平衡过程会触发stop-the-world(STW),此时对应topic的资源都会处于不可用的状态。小规模的集群还好,如果是大规模的集群,比如几百个节点的consumer或kafka connect等,那么重平衡就是一场灾难。所以我们要尽可能避免重平衡。
在kafka2.4的时候,社区推出两个新feature来解决重平衡过程中STW的问题。
1. Incremental Rebalance Protocol(以下简称cooperative协议):改进了eager协议(即旧重平衡协议)的问题,避免STW的发生,具体怎么避免,后面介绍
2. static membership:避免重起或暂时离开的消费者触发重平衡
apache kafak2.4 incremental cooperative rebalancing协议
背景
负载均衡,基本是分布式系统中必不可少一个功能,apache kafka也不例外。为了让消费数据这个过程在kafka集群中尽可能地均衡,kafka推出了重平衡的功能,重平衡能够帮助kafka客户端(consumer client,kafkaconnect,kafka stream)尽可能实现负载均衡。
但是在kafka2.3之前,重平衡各种分配策略基本都是基于eager协议的(包括RangeAssignor,RoundRobinAssignor等),也就是我们以前熟知的kafka重平衡
值得一提的是,此前kafka就有推出一个重平衡的新分配策略,`StickyAssignor`粘性分配策略,主要作用是保证客户端,比如consumer消费者在重平衡后能够维持原本的分配方案,可惜的是这个分配策略依旧是在eager协议的框架之下,重平衡仍然需要每个consumer都先放弃当前持有的资源(分区)。
在2.x的时候,社区就意识到需要对现有的rebalance作出改变。所以在kafka2.3版本首先在kafka connect应用cooperative协议,然后在kafka2.4的时候也在consumer client添加了该协议的支持。
incremental cooperative rebalancing协议解析
接下来我们介绍cooperative协议和eager协议的具体区别。一句话介绍,**cooperative协议将一次全局重平衡,改成每次小规模重平衡,直至最终收敛平衡的过程**。
这里我们主要针对一种场景举个例子,来对比两种协议的区别。
假设有这样一种场景,一个topic有三个分区,分别是p1,p2,p3。有两个消费者c1,c2在消费这三个分区,{c1 -> p1, p2},{c2 -> p3}。
当然这样说不平衡的,所以加入一个消费者c3,此时触发重平衡。我们先列出在eager协议的框架下会执行的大致步骤,然后再列出cooperative发生的步骤,以做比对。
eager 协议版本各个名词:
- group coordinator:重平衡协调器,负责处理重平衡生命周期中的各种事件
- hearbeat:consumer和broker的心跳,重平衡时会通过这个心跳通知信息
- join group request:consumer客户端加入组的请求
- sync group request:重平衡后期,group coordinator向consumer客户端发送的分配方案
如果在 eager 版本中,会发生如下事情。
1. 最开始的时候,c1 c2 各自发送hearbeat心跳信息给到group coordinator(负责重平衡的协调器)
2. 这时候group coordinator收到一个join group的request请求,group coordinator知道有新成员加入组了
3. 在下一个心跳中group coordinator 通知 c1 和 c2 ,准备rebalance
4. **c1 和 c2 放弃(revoke)各自的partition**,然后发送joingroup的request给group coordinator
5. group coordinator处理好分配方案(交给leader consumer分配的),发送sync group request给 c1 c2 c3,附带新的分配方案
6. c1 c2 c3接收到分配方案后,重新开始消费
用一张图表示如下:
这里省略了一些细节,不过整体上应该会更方便理解这个过程。接下来再看看cooperative协议会怎么处理。
到了cooperative协议就会变成这样:
cooperative rebalancing protocol
如果在cooperative版本中,会发生如下事情。
1. 最开始的时候c1 c2各自发送hearbeat心跳信息给到group coordinator
2. 这时候group coordinator收到一个join group的request请求,group coordinator知道有新成员加入组了
3. 在下一个心跳中 group coordinator 通知 c1 和 c2 ,准备 rebalance,前面几部分是一样的
4. **c1 和 c2发送joingroup的request给group coordinator,但不需要revoke其所拥有的partition,而是将其拥有的分区编码后一并发送给group coordinator,即 {c1->p1, p2},{c2->p3}**
5. group coordinator 从元数据中获取当前的分区信息(这个称为assigned-partitions),再从c1 c2 的joingroup request中获取分配的分区(这个称为 owned-partitions),通过assigned-partitions和owned-partitions知晓当前分配情况,决定取消c1一个分区p2的消费权,然后发送sync group request({c1->p1},{c2->p3})给c1 c2,让它们继续消费p1 p2
6. c1 c2 接收到分配方案后,重新开始消费,一次 rebalance 完成,**当然这时候p2处于无人消费状态**
7. 再次触发rebalance,重复上述流程,不过这次的目的是把p2分配给c3(通过assigned-partitions和owned-partitions获取分区分配状态)
同样用一张图表示如下: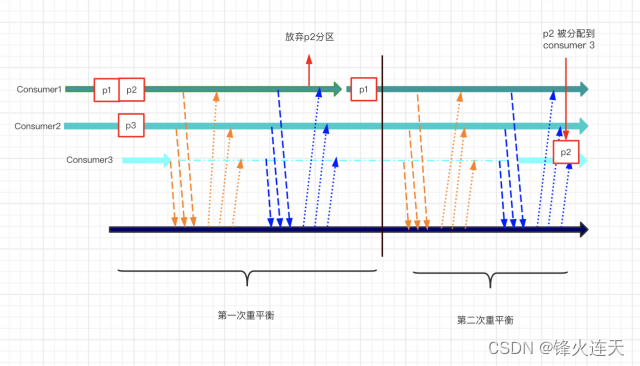
cooperative协议版重平衡的一个核心,是assigned-partitions和owned-partitions,group coordinator通过这两者,可以保存和获取分区的消费状态,以便进行多次重平衡并达到最终的均衡状态。
除了消费者崩溃离场的场景,其他场景也是类似的思路
apache kafka2.4 static membership功能
我们知道,当前重平衡发生的条件有三个:
- 成员数量发生变化,即有新成员加入或现有成员离组(包括主动离组和崩溃被动离组)
- 订阅主题数量发生变化
- 订阅主题分区数量发生变化
其中成员加入或成员离组是最常见的触发重平衡的情况。新成员加入这个场景必然发生重平衡,没办法优化(针对初始化多个消费者的情况有其他优化,即延迟进行重平衡),但消费者崩溃离组却可以优化。因为一个消费者崩溃离组通常不会影响到其他{partition - consumer}的分配情况。
**因此在 kafka 2.3~2.4 推出一项优化,即此次介绍的[Static Membership](https://www.lmlphp.com/r?x=CtQ9ytoWsjbvPE4vPHw7yekGCeT6zihAs_gMsMQVPiKd4Ew9PLQ3zMlVgiI9PLQ3PSbd4ESN4Lh_CerO5tOwp8)功能和一个consumer端的配置参数 `group.instance.id`**。一旦配置了该参数,成员将自动成为静态成员,否则的话和以前一样依然被视为是动态成员。
**静态成员的好处在于,其静态成员ID值是不变的,因此之前分配给该成员的所有分区也是不变的。即假设一个成员挂掉,在没有超时前静态成员重启回来是不会触发 Rebalance 的**(超时时间为`session.timeout.ms`,默认10 sec)。在静态成员挂掉这段时间,broker会一直为该消费者保存状态(offset),直到超时或静态成员重新连接。
如果使用了 static membership 功能后,触发 rebalance 的条件如下:
- 新成员加入组:这个条件依然不变。当有新成员加入时肯定会触发 Rebalance 重新分配分区
- Leader 成员重新加入组:比如主题分配方案发生变更
- 现有成员离组时间超过了 `session.timeout.ms` 超时时间:即使它是静态成员,Coordinator 也不会无限期地等待它。一旦超过了 session 超时时间依然会触发 Rebalance
- Coordinator 接收到 LeaveGroup 请求:成员主动通知 Coordinator 永久离组。
所以使用static membership的两个条件是:
1. consumer客户端添加配置:props.put("group.instance.id", "con1");
2. 设置`session.timeout.ms`为一个合理的时间,这个参数受限于`group.min.session.timeout.ms`(6 sec)和`group.max.session.timeout.ms`(30 min),即大小不能超过这个上下限。但是调的过大也可能造成broker不断等待挂掉的消费者客户端的情况,个人建议根据使用场景,设置合理的参数。
以上~
边栏推荐
- 史上最全架构师知识图谱
- LINE Verda Programming Contest (AtCoder Beginner Contest 263) A~E 题解
- 那些关于DOM的常见Hook封装(二)
- jmeter-录制脚本
- Detailed explanation of JVM memory model and structure (five model diagrams)
- win10 uwp 手动锁Bitlocker
- [极客大挑战 2019]HardSQL
- 最强分布式锁工具:Redisson
- 【工业数字化大讲堂 第二十一期】企业数字化能碳AI管控平台,特邀技术中心总经理 王勇老师分享,8月11日(周四)下午4点
- win10 uwp 设置启动窗口大小 获取窗口大小
猜你喜欢

How to choose a good SaaS knowledge base tool?

Ark: Survival Evolved Open Server Port Mapping Tutorial

十七、一起学习Lua 错误处理

艺术与科技的狂欢,云端XR支撑阿那亚2022砂之盒沉浸艺术季

The principle implementation of handwritten flexible.js, I finally understand the multi-terminal adaptation of the mobile terminal

ceph 创建池和制作块设备基操

Discuz!论坛程序安装+模板配置教程
![[Pycharm easy to use function]](/img/f8/4c131516033286ba8bcb511d395462.png)
[Pycharm easy to use function]

ARM Assembly Basics

学长告诉我,大厂MySQL都是通过SSH连接的
随机推荐
学长告诉我,大厂MySQL都是通过SSH连接的
最新!2022版新员工基础安全知识教育培训PPT,企业拿去直接用
逻辑越权和水平垂直越权支付篡改,验证码绕过,接口
ceph集群部署
LeetCode做题小结
EPIC是什么平台?
mysql如何查看所有复合主键的表名?
The strongest distributed lock tool: Redisson
方舟单机/管理员特殊物品指令代码大全
书单 | “推荐系统” 值得一读的五本书
秋招面试大厂总被刷下来,你这样做保准你事半功倍!
jmeter-录制脚本
win10 uwp 获取指定的文件 AQS
从事软件测试一年,只会基础的功能测试,怎么进一步学习?
Apache Doris Community PMC Yang Zhengguo: How do open source projects strike a balance between their own and the community's needs?
How to play with container local storage through open-local? | Dragon Lizard Technology
Detailed explanation of JVM memory model and structure (five model diagrams)
不是吧,连公司里的卷王写代码都复制粘贴,这合理?
IMX6ULL—汇编LED灯
[极客大挑战 2019]HardSQL