当前位置:网站首页>Modèle de Cluster MySQL et scénario d'application
Modèle de Cluster MySQL et scénario d'application
2022-04-23 15:38:00 【Dengk2013】
Assistant provincial:
Mode bibliothèque unique:UnmysqlLa base de données contient toutes les données pertinentes.
Mode de regroupement séparé lecture - écriture:Ajouter une couche intermédiaire sur la base originale,Regroupement séparé de la lecture et de l'écriture avec des ensembles de données d'arrière - plan.Infrastructure globale:Bibliothèque de polices dérivée de la bibliothèque principale originale1,Bibliothèque de caractères2,
UtilisationmysqlMécanisme de synchronisation maître - esclave existant(C'est - à - dire::binlogSynchronisation des journaux),Reproduire les changements de données de la bibliothèque principale à partir de la bibliothèque,Assurer la synchronisation des données.La bibliothèque principale est généralement utilisée pour le traitement des écritures,
Lire à partir de la bibliothèque.Détails:Si vous ne pouvez pas terminer la séparation lecture - écriture en faisant face directement à la bibliothèque principale,Nécessité d'attribuer des intergiciels à puce à l'avant(Ali!mycat,JDShardingSphere),
L'intergiciel passe parcurdDemande,Pour déterminer la bibliothèque à gérer.MHAMiddleware haute disponibilité(C'est - à - dire::Le serveur principal est en panne.,MHAUn Middleware peut promouvoir un serveur primaire à partir d'une table).
Toutes les données du noeud sont synchronisées.Pour lire plus et écrire moins,Des millions d'applications Internet.
Sous - entrepôt sous - Tableau(Fractionnement)Mode Cluster:UnmysqlSi la base de données ne tient pas.Diviser les données de la base de données en différentes bases de données de noeuds(C'est - à - dire::Les données de la base de données des noeuds sont combinées en un corps de données complet).
Nécessite un Middleware pour le routage.(C'est exact.sqlAnalyser,Envoyer la demande à la base de données correspondante,Le processus de distribution des demandes est appelé routage).Pas de disponibilité élevée.
Pourquoi les grandes usines font - elles des tables verticales??
Il y a trop de champs dans une table qui doivent être divisés verticalement.
Qu'est - ce qu'un sous - Tableau horizontal?
Diviser les données en unités de comportement( Méthode du champ d'application ,hashDroit).Caractéristiques: Toutes les tables ont exactement la même structure . Pour résoudre les problèmes de stockage de grandes quantités de données .
Qu'est - ce qu'un sous - Tableau vertical?
Diviser le tableau en colonnes 2 Petite montre au - dessus de la feuille , Obtenir des données par l'Association primaire de clés étrangères .
Pourquoi faire ça??
Besoin de comprendremysqlDeInnoDBMoteur de traitement.
Les données de ligne sont appelées :row
L'Unit é de base des données de gestion est appelée Page :page; Taille par défaut de chaque page :16k
L'Unit é dans laquelle la page est sauvegardée est appelée Zone :Extent.
Relations: La zone se compose de pages consécutives , La page se compose de lignes consécutives .1024/16=64(C'est - à - dire::Un1M La zone de 64Page (s))
InnoDB1.0 Nouvelles caractéristiques après ,Compresser la page.
Compresser la page: Compression de la couche inférieure des données , Rendre la taille réelle inférieure à la taille logique .
Lors de la recherche de données entre les pages , Faible efficacité de compression et de décompression .Au moment de la conception de la table, Stocker autant de données de ligne que possible dans la page , Réduire la recherche de pages croisées , Ajouter une recherche en page .
Analyse:
1Les données de ligne sont:1K,1(En milliers de dollars des États - Unis)16K,C'est - à - dire:1(En milliers de dollars des États - Unis)16Données,1 Des milliards de données sont nécessaires 62510 000 pages
Après la pagination verticale ,1Les données de ligne sont:64Octets(1K=1024Octets),C'est - à - dire:1(En milliers de dollars des États - Unis)256Données,1 Des milliards de données sont nécessaires 4010 000 pages. Les données après la pagination sont basées sur id Extraction rapide de relations égales .
En divisant les champs importants individuellement en petits tableaux , Tenir plus de lignes de données par page , Après réduction de page , Réduire la portée de la numérisation des données ,Atteindre l'objectif d'améliorer l'efficacité de la mise en oeuvre.
Conditions de séparation verticale :
1. Les données d'un seul tableau s'élèvent à 10 millions
2. Champ super 20- Oui.,Et contientvachar,CLOB,BLOBChamp égal
Champ agrandir la base de la petite table :
Petite montre:Recherche de données、 Champs requis lors du tri ; Petits champs accessibles à haute fréquence
Grande montre: Champ d'accès LF ;Grand champ
Les clés primaires auto - incrémentales ne s'appliquent pas dans un environnement distribué.
Puisque la clé primaire auto - incrémentale doit être continue , Donc, par la méthode de la plage, on fait des tranches ,IDQuantité fixe.Impossible d'étendre dynamiquement.Ça va se produire.“Hotspot arrière”Effets.
Hotspot arrière:C'est - à - dire après le fractionnement selon la méthode de la plage,Données stockées dans les tranches précédentes,La dernière pièce est sous pression..
HashPlus grande efficacité du fractionnement.
UtiliserUUID Remplacer la clé primaire auto - incrémentale ?Je ne peux pas、
Impliquer le mécanisme sous - jacent de la base de données :
1.uuid,Le seul désordre. Le désordre entraîne un réarrangement de l'index .Lorsque la clé primaire est ordonnée,B+Il suffit d'ajouter l'arbre aux données originales.
Comment?? Algorithme de génération de clés primaires distribué et ordonné ?
Algorithme flocon de neige(SnowFlake),Twitter.
Structure:Bits de symbole(1bit)+Horodatage(41bit)+MachinesID(10bit)+Séquence(12bit)
Mode d'emploi:Appel directJARSac
L'algorithme flocon de neige exige une attention particulière à l'impact du rappel temporel .Peut - être.idPossibilité de répétition
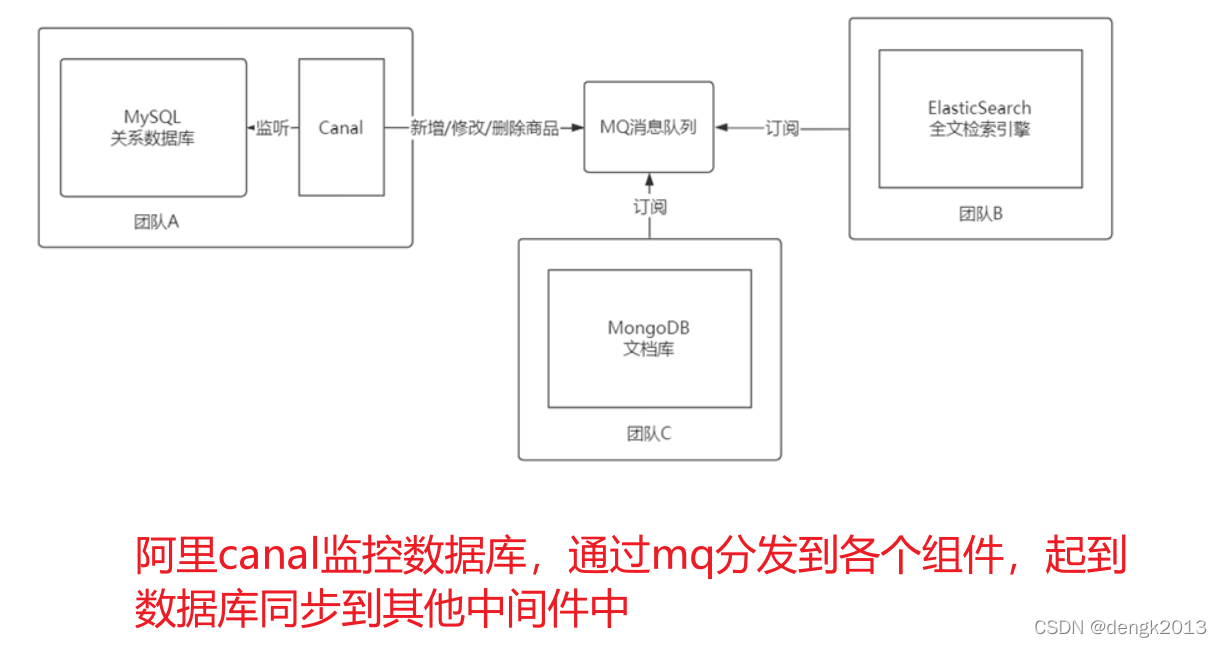
Ali!canal

版权声明
本文为[Dengk2013]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231537380354.html
边栏推荐
猜你喜欢


随机推荐
s16.基于镜像仓库一键安装containerd脚本
Leetcode学习计划之动态规划入门day3(198,213,740)
Upgrade MySQL 5.1 to 5.67
MultiTimer v2 重构版本 | 一款可无限扩展的软件定时器
PHP operators
小程序知识点积累
php类与对象
T2 iCloud日历无法同步
Functions (Part I)
Go并发和通道
怎么看基金是不是reits,通过银行购买基金安全吗
Node. JS ODBC connection PostgreSQL
For examination
Code live collection ▏ software test report template Fan Wen is here
What if the server is poisoned? How does the server prevent virus intrusion?
Explanation of redis database (I)
G007-HWY-CC-ESTOR-03 华为 Dorado V6 存储仿真器搭建
MySQL Basics
Go语言切片,范围,集合
网站某个按钮样式爬取片段