当前位置:网站首页>【EagleEye】2020-ECCV-EagleEye: Fast Sub-net Evaluation for Efficient Neural Network Pruning-论文详解
【EagleEye】2020-ECCV-EagleEye: Fast Sub-net Evaluation for Efficient Neural Network Pruning-论文详解
2022-08-08 06:24:00 【唐三.】
【EagleEye】2020-ECCV-EagleEye: Fast Sub-net Evaluation for Efficient Neural Network Pruning-论文详解
文章目录
y = λ x − u σ 2 + ϵ + β {\color{Blue} y=\lambda \frac{x-u}{\sqrt{\sigma ^{2}+\epsilon }}+\beta } y=λσ2+ϵx−u+β σ B 2 = 1 N − 1 ∑ i = 1 N ( X i − σ B ) 2 {\color{Blue} \sigma _{B}^{2}=\frac{1}{N-1}\sum_{i=1}^{N}(Xi-\sigma _{B})^{2}} σB2=N−11i=1∑N(Xi−σB)2 μ t = m μ t − 1 + ( 1 − m ) μ B {\color{Red} \mu _{t}=m\mu _{t-1}+(1-m)\mu _{B}} μt=mμt−1+(1−m)μB σ t 2 = m σ t − 1 2 + ( 1 − m ) σ B 2 {\color{RED} \sigma_{t}^{2}=m\sigma _{t-1}^{2}+(1-m)\sigma _{B}^{2}} σt2=mσt−12+(1−m)σB2
一、Introduction
- 上周讲了一篇Three Dimension Pruning的论文,最近又读了两篇CVPR2020 oral等有时间与大家分享:
这篇论文是去年 ECCV2020oral 的工作,提出了一个对于pruning task的trick,将剪枝后的subnet的BN层中的统计参数做了一个更新,并指出之前的用Full-net的BN层参数inference剪枝后的subnet的做法是不具有有效性的。
- 首先,作者提出我们传统的对模型做pruning流程是:第一步,首先去训练一个参数过度、模型比较大的网络,第二步对它以一定的剪枝率做剪枝。第三步,再进行finetuning,恢复损失的精度。但是作者指出,如果我们每次都对剪枝之后的那么多模型去做finetuning的话,会需要大量的计算资源和训练时间,而且需要比较所有剪枝后模型finetuning的结果才能找到我们最佳的那个剪枝模型,也就是这个流程:
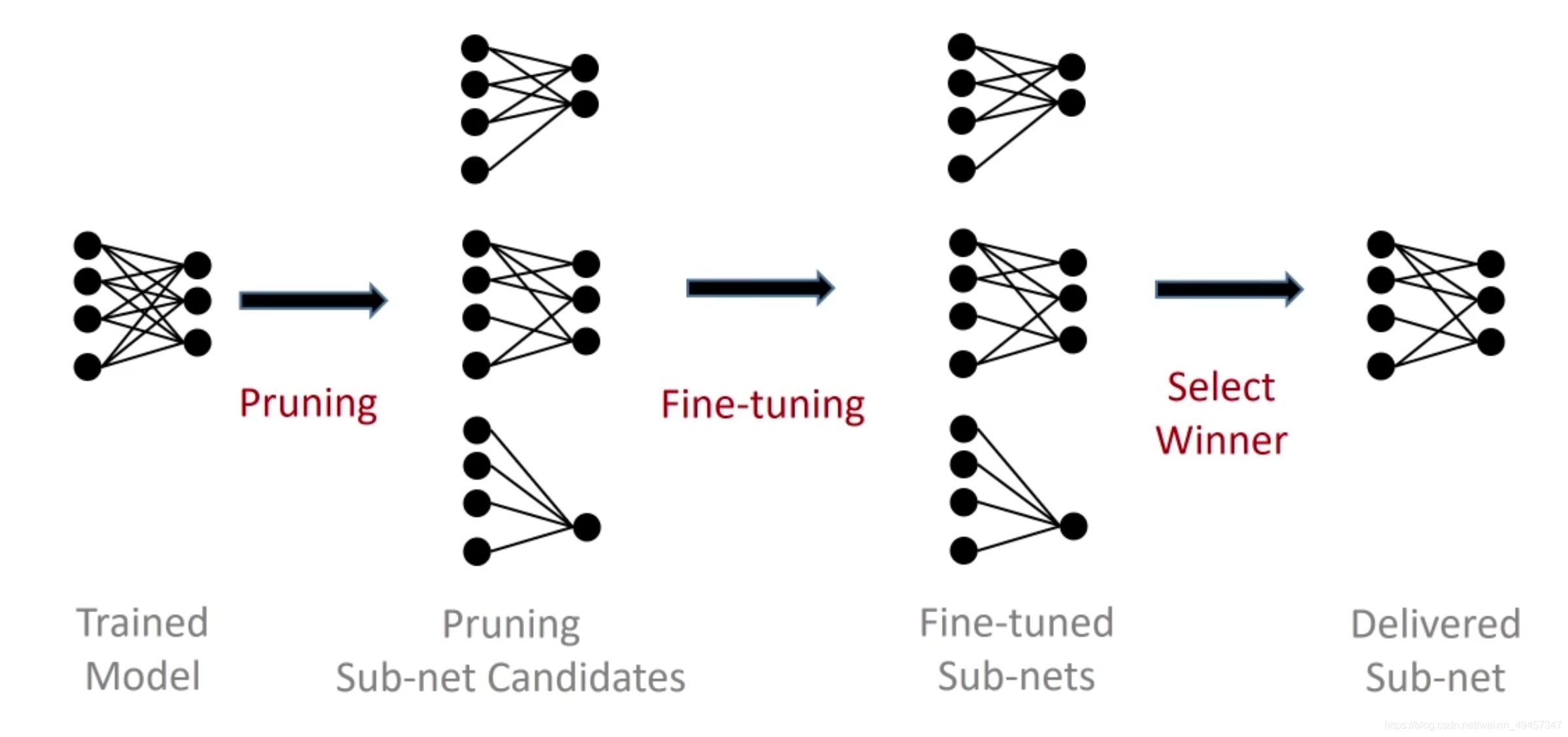
- 理论上我们如果把每一个可能得到的子网络全都进行一个fine-tuning,进行一个额外的epochs的fine-tuning,得到的candidates我们选出一个精度最高的,作为我们最后deliver的剪枝过后的最优子网络。
- 但是这个过程效率是非常低的,因为Fine-tuning这个过程本身就是training,本身就是expensive的一个操作,而我们可能的sub-nets种类又非常多,所以如果针对这种large-scale的subnet的空间,如果都去做这个fine-tuning的话,开销就会非常的大。
后面就出现了很多工作,它将这些模型直接去做一个小范围的推理,得到inference精度最高的作为最好的网络candidate,拿去做finetuning。这样就可以避免finetuning的模型个数,实现高效的剪枝。
也就是:
二、Pipeline

这是作者最终的pipeline。
- 其实这个做法还是很普遍的,他将我们的神经网络的full-net在进行静态剪枝之后呢,就直接去做一个Inference,然后将inference最高的子网络摘选出来作为一个winner candidate,去做fine-tuning。
- 其实到这里这个工作还不是本文独创的,本文对这个方法进行了讨论,本文把这个方法叫做vanilla evalution,就是把一些静态的inference accurancy去选择子网络的方法,是有失偏颇的,这个讨论后面会讲到为什么这样的selection是不公平的。
三、Analysis (提出疑问)
- 下图是对sub-nets进行推理后的精度直方图:
 Fig. 2. A typical pipeline for neural network training and pruning
Fig. 2. A typical pipeline for neural network training and pruning
我们注意到,如果直接将静态剪枝后的子网络进行推理,精度会很差。暗红色的部分是我们进行一个随机pruning之后的sub-nets,进行推理后的精度直方图,精度在0.1以下,将sub-net全部进行fine-tuning呢,精度就会全部提升到60%以上这个范围内,从不到10%精度的子网络,就一下跨到60%这个范围。这两个结果的精度差距如此之大,我们就可以提出两个疑问:
- 1. 既然我们的剪枝算法是依照某种规则,将我们所谓的不重要unimportance的通道或卷积核给他去掉,那为什么去掉不重要的卷积核之后精度会掉到如此低的区域,这也是说不通的现象。
- 2. 第二个问题自然是,低精度的网络和最终收敛的子网络之间有多大的相关性?如果我们根据performance这么差的subnets去选出performance最优的自网络,这种选择它的可靠性有多大,应不应该去拿这些低精度的子网络去做选择,到底有多大的参考性?
- 其实第一个疑问问的是finetuning的作用,这个问题其实比较根本,从Fig2的右图可以看出,随着finetune的epochs的迭代,我们发现静态的subnets它的weights其实没有一个非常大的变化,其实是一个非常gentle的shift,所以weight在finetune当中的变化可能不是导致这些subnets有这么低精度的原因。
- 对上一句话做一个指正,作者是因为这些subnets的Accuracy非常低才怀疑哪里出了问题,而正常pruning之后只要剪枝率不是特别高,那Accuracy降得并不多的!比如从95.23%降到94.89%。
四、Correlation Measurement (相关性验证)
- 另一个量化的分析这些低精度的子网络跟最后把它们finetune之后的精度去做一个相关性的分析,我们发现其实没有什么关系。

- 这里横坐标表示vanilla evaluation也就是静态剪枝的这些子网络的精度,纵坐标就是我们把它finetune之后的精度,我们发现其实并没有什么相关性。
换句话说,如果我们从这群静态剪枝之后的subnets中去选择一个精度较高的子网络,并不能代表他经过finetune之后就是一个优质的子网络。
- 我们首先分析原因。
- 发现它主要出在这个BN上:

- 上面这条链路表示我们训练时使用的statistics values(mean,方差等)是通过统计基于Full-net来得到的,但是我们其实进行剪枝之后,这个structure就发生了变化,但是在inference的过程中依然错误地使用了Full-net的这些参数。因此就造成在inference中这些子网络的精度就非常的差。
然后本篇论文的亮点来了,作者做了一个非常简单又值得观察的操作,就是通过几个Inference的过程,将BN的参数进行修正,这个过程是非常快速的,在GPU里只有几秒的延迟。
- 当我们将BN的Mean和variance进行纠正后就发现子网的inference的静态精度就非常高,说明之前第一个问题-------inference的精度掉的那么大的原因就是BN层的参数没有更新,不应该使用Full-net的参数。
五、BN层的工作原理
先解释一下BN层的工作原理,BN层是对每一个batch的数据作归一化: y = λ x − u σ 2 + ϵ + β {\color{Blue} y=\lambda \frac{x-u}{\sqrt{\sigma ^{2}+\epsilon }}+\beta } y=λσ2+ϵx−u+β
- 其中, x − u σ 2 + ϵ {\color{Blue} \frac{x-u}{\sqrt{\sigma ^{2}+\epsilon }}} σ2+ϵx−u将一个batch的 feature map 均值归一化到0,方差归一化到1;
γ \gamma γ, β \beta β分别是缩放系数和偏移系数,是可学习的参数。每个batch的Mean和variance的计算方式如下:
μ B = 1 N ∑ i N X i {\color{Blue}\mu _{B}=\frac{1}{N}\sum_{i}^{N}Xi} μB=N1i∑NXi σ B 2 = 1 N − 1 ∑ i = 1 N ( X i − σ B ) 2 {\color{Blue} \sigma _{B}^{2}=\frac{1}{N-1}\sum_{i=1}^{N}(Xi-\sigma _{B})^{2}} σB2=N−11i=1∑N(Xi−σB)2
- 训练过程中不同 iteration之间BN层使用的均值和方差使用以下 momentum 的方式更新:
μ t = m μ t − 1 + ( 1 − m ) μ B {\color{Red} \mu _{t}=m\mu _{t-1}+(1-m)\mu _{B}} μt=mμt−1+(1−m)μB σ t 2 = m σ t − 1 2 + ( 1 − m ) σ B 2 {\color{RED} \sigma_{t}^{2}=m\sigma _{t-1}^{2}+(1-m)\sigma _{B}^{2}} σt2=mσt−12+(1−m)σB2
- 测试阶段的输入一般是单张图片,没有batch的单位,因此训练结束后的 μ t , σ t 2 {\color{Blue} \mu _{t} , \sigma _{t}^{2}} μt,σt2即作为网络BN层的值,称为"global BN statistics"。
六、Experiments (实验结果)
链接: link.
Adaptive Batch Normalization
- vanilla evaluation 使用"global BN statistics"作为剪枝模型的BN层参数,会导致剪枝模型性能严重下降以及两阶段acc的低相关性。
- 作者提出Adaptive BN的方法来重新计算剪枝后模型BN层的值, μ t , σ t 2 {\color{Blue} \mu _{t} , \sigma _{t}^{2}} μt,σt2具体来说即冻结网络参数使用公式(4)进行几次前向(不进行反向),来更新BN层的值。 vanilla evaluation 与 使用adaptive BN 的相关性如下图:

- 另一方面,我们比较了 global BN statistics,adaptive BN statistics与true statistics之间的距离,如下所示:

Effectiveness 有效性:
- 在CIFAR-10上的结果。左图为Resnet-56,右图为MobilenetV1.
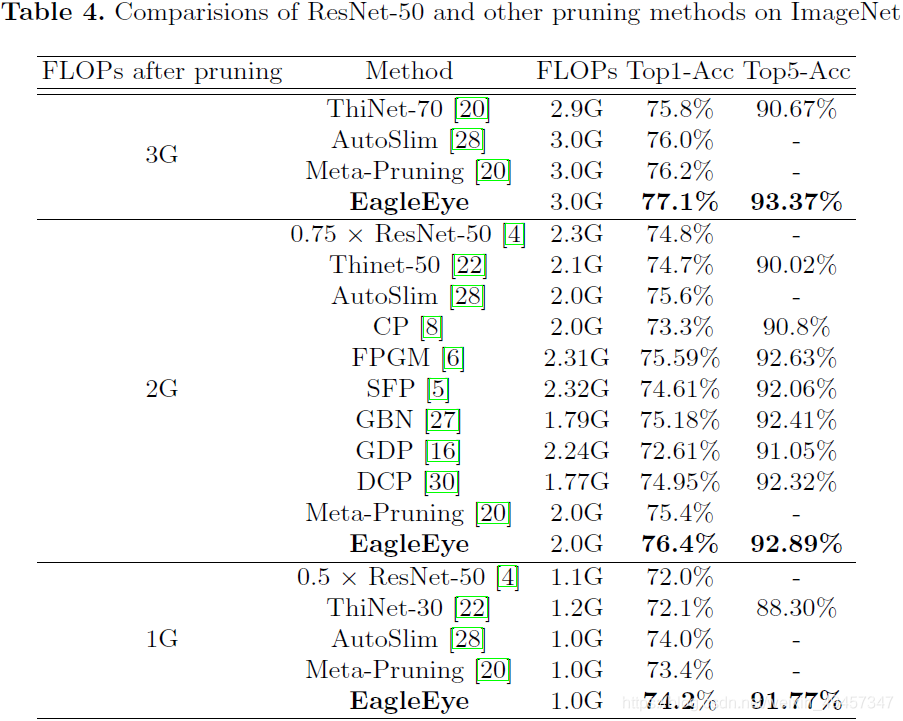

- 在Imagenet上的结果。arch是MobilenetV1。
可见在Imagenet上,EagleEye的剪枝率和SOTA的Meta-Pruning、AMC等剪枝方法结果差不多的情况下,Top1和Top5的精度都是更优一些,但这里没有给出Parameters的PR,感觉作者是不是有一点心虚,毕竟参数量的PR也是很重要的。
七、EagleEye pruning algorithm (剪枝算法)
- 对layers剪枝
生成一个剪枝结构,即一个Layer-wise 剪枝率的vector: ( r 1 , r 2 , r 3 . . . , r L ) {\color{Blue}(r_{1},r_{2},r_{3}...,r_{L})} (r1,r2,r3...,rL) ,这里使用随机采样。 - 对Filters剪枝
根据第一步得到的Layer-wise剪枝率,对full-size模型进行剪枝,这里使用L1-norm重要性分数,剪掉重要性低的filters。 - Adaptive-BN-based candidate 估计模块
对每个剪枝模型重新计算BN statistics,即使用adaptive BN更新BN层,在ImageNet上用来更新BN的dataSet为 1 55 {\color{Blue} \frac{1}{55}} 551 的training set,更新50个iteration。每个剪枝模型在单张2080Ti上完成adaptive BN的更新只需要10+秒。
最后由adaptive BN更新后的剪枝模型性能选出最有潜力的剪枝模型进行fine-tune。
八、Conclusion
本文针对以往直接对静态剪枝后inference精度下降的不足,以及对静态剪枝后的sub-nets和最后finetune最优的网络之间不具有相关性的现象,提出了一个将BN的参数进行修正的trick。
但是只修改BN层中的两个参数就能对finetune后的结果有这么好的提升吗?如果有时间我会复现一下这篇论文。
第二篇CSDN,真不错!
边栏推荐
- 市场调研报告-食品添加剂行业产量为974万吨
- Flutter学习开发资源整理与分享
- Mysql(三)
- Chemical Industry Research: Current Situation and Scale Analysis of Organic Silica Gel Market
- Variational Inference with Normalizing Flows变分推断
- RNN神经网络适用于什么,RNN神经网络基本原理
- bp神经网络预测模型原理,神经网络模型怎么预测
- Market research report - the food additive industry output of 9.74 million tons
- 多神经网络模型联合训练,神经网络模型怎么训练
- Equipment industry research report: laser printer market present situation and development trend in the future
猜你喜欢

Industry Research: Analysis of the Status and Prospects of the Pension Insurance Market in 2022

略解深度学习优化策略
Analysis of the status quo of the chemical industry: the polyolefin market consumption is nearly 200 million tons

2. TF2 FAQ
三.Redis 的发布和订阅

RCNN目标检测原文理解

jupyter notebook添加目录

六.Redis 持久化之 RDB

逻辑回归推导
多神经网络模型联合训练,神经网络模型怎么训练
随机推荐
2022年天然橡胶市场供需与价格走势
神经网络二分类问题范例,神经网络解决分类问题
有限与无限只在于一个变量
六.Redis 持久化之 RDB
四. Redis 事务、锁机制秒杀
神经网络预测结果分析,神经网络怎么预测数据
Mysql 事务
2022年中国儿童食品市场规模与发展趋势
2.Explain详解与索引优化原则
Consumer Goods Industry Report: Research Analysis and Development Prospect Forecast of Cosmetic Container Market Status
Anaconda installation and use
三.Redis 的发布和订阅
电动剃须刀市场现状研究分析与发展前景预测
八.Redis 主从复制
Yii2使用composer安装MongoDB扩展
传统图像特征提取方法:边缘与角点
略解损失函数
在Mysql的 left/right join 添加where条件
Food Industry Report: Research Analysis and Development Prospect Forecast of Chili Market
BiLSTM实现imdb情感分类任务