当前位置:网站首页>C# 基础之字典——Dictionary(一)
C# 基础之字典——Dictionary(一)
2022-08-11 05:31:00 【canon_卡农】
前言
字典是C#开发中经常使用的容器之一,面试中经常问到它的底层实现,可见其重要性,今天我们就来看一看Dictionary的源码,研究一下底层到底是怎么设计的。
1.字典如何使用?
static void Main(string[] args)
{
// 1.定义
// Key和Value可以是任意类型
Dictionary<int, string> _testDic = new Dictionary<int, string>();
// 2.添加元素
_testDic.Add(24, "Canon");
// 注意相同相同Key值只能Add一次
_testDic.Add(24, "Jason");// 报错:System.ArgumentException:“已添加了具有相同键的项。”
// 可以使用ContainsKey判断字典中是否已经存在
if (!_testDic.ContainsKey(24)) _testDic.Add(24, "Canon");
// 3.删除元素
// Remove 删除不存在的值不会报错
_testDic.Remove(24);
// 4.取值
// 索引器取值,若字典中没有Key会报错
string str = _testDic[24];
// TryGetValue 取值成功返回true,内部对str赋值,否则返回false
bool isExist = _testDic.TryGetValue(24, out str);
// 5.改值
// 要确保字典中确实存在该值
if (_testDic.ContainsKey(1)) _testDic[1] = "";
// 6.遍历
// Key
foreach (var key in _testDic.Keys) Console.WriteLine("Key = {0}", key);
// Value
foreach (var value in _testDic.Values) Console.WriteLine("value = {0}", value);
// foreach遍历
foreach (var kvp in _testDic) Console.WriteLine("Key = {0}, Value = {1}", kvp.Key, kvp.Value);
// 迭代器遍历
var enumerator = _testDic.GetEnumerator();
while (enumerator.MoveNext())
{
var kvp = enumerator.Current;
Console.WriteLine("Key = {0}", kvp.Key);
Console.WriteLine("Key = {0}", kvp.Value);
}
// 7.清空
_testDic.Clear();
}
2.字典底层实现
链接: C# Dictionary源码
哈希函数
字典的Key——Value映射是利用哈希函数来建立的。
什么是哈希函数呢,
把一个对象转换成唯一且确定值的函数就叫做哈希函数,也叫做散列函数。
这个值就叫做哈希码(hashCode)在C#里一般是一个32位正整数。就好比每一个人都对应一个身份证号码。
哈希桶
从源码中可以看到,字典内部使用数组存储数据。
private struct Entry {
public int hashCode; // Lower 31 bits of hash code, -1 if unused
public int next; // Index of next entry, -1 if last
public TKey key; // Key of entry
public TValue value; // Value of entry
}
private int[] buckets;
private Entry[] entries;
...
由于key的哈希值范围很大,我们不可能声明一个这么大的数组,于是就有了哈希桶。
把hashCode进行分类装到一个个“桶”里面,这样就减少了索引的范围。每次
拿到一个hashCode就去对应的哈希桶里面去找数据。
具体做法是声明一个buckets数组,通过hashCode%BucketSize(取余)获得一个索引值 targetBucket,这样每一个hashCode都对应到一个buckets[targetBucket].
targetBucket永远不会超出数组索引范围。
// & 0x7FFFFFFF(2进制011111..)是为了确保hashCode是一个正整数
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
int targetBucket = hashCode % buckets.Length;
哈希冲突
基于以上做法,不同的hashCode有可能对应到同一个哈希桶,这样就产生了哈希冲突。下图是哈希冲突示意图: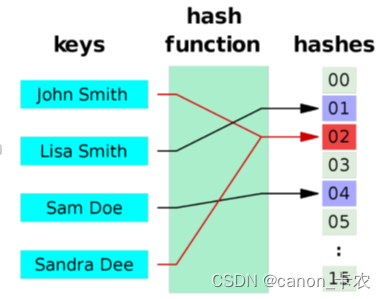
图中红色部分发生了哈希冲突。
C#字典解决哈希冲突的方法是拉链法。
拉链法
将产⽣冲突的元素建⽴⼀个单链表,并将头指针地址存储对应桶的位置。这样定位到Hash桶的位置后可通过遍历单链表的形式来查找元素。
当bucket没有指向任何entry时,它的值为-1。
当我们往字典里插入一个数据时,先获取Key值的hashCode,通过hashCode找到桶的索引 targetBucket,buckets[targetBucket]就是存放数据entry的链表头节点所在。
下面我们看链表构建过程(头插法):
...
entries[index].hashCode = hashCode;
entries[index].next = buckets[targetBucket];
entries[index].key = key;
entries[index].value = value;
buckets[targetBucket] = index;
插入时首先找到entries数组中的空闲位置index,放入entry。
然后将buckets[targetBucket]的值赋值给next字段,显然插入第一个数据时next为-1,即为头节点。
然后更新buckets[targetBucket]的值为index。插入的数据变成新的头节点。
查找时则是通过同样的操作找到链表头节点的位置,如果头结点entry的next字段不为-1,则next指向链表下一个
节点的位置。
通过遍历链表去查找对应的数据。
for (int i = buckets[hashCode % buckets.Length]; i >= 0; i = entries[i].next) {
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) return i;
}
插入细节
在源码中发现插入和删除过程中维护了以下两个字段:
private int freeList;
private int freeCount;
通过这两个字段,插入时可以优先找到上一个释放数据的位置,很是巧妙。
总结
至此,我们对C#的字典底层的实现有了大概的了解。
字典底层将数据储存在数组里面,通过哈希函数建立Key——Value的对应关系,利用拉链法处理哈希冲突。了解这些虽然对写代码来说用处不大,毕竟业务仔会用就行。但至少在面试中可以吹吹水,忽悠面试官还是阔以的。
下一节讲讲 字典的扩容机制 。
个人理解,如有错误,希望大家在评论区指出。
参考链接:
https://www.cnblogs.com/zhaolaosan/p/16244067.html
https://www.cnblogs.com/CoderAyu/p/10360608.html
https://blog.csdn.net/qq_40404477/article/details/120738818
边栏推荐
- Regular expression replacement for batch quick modification code
- PyQt5中调用.ui转换的.py文件代码解释
- C语言预处理
- stack stack
- Compilation exception resolution
- Byte (byte) and bit (bit)
- Jetpack's dataBinding
- JS this关键字
- 第六届蓝帽杯 EscapeShellcode
- Building a data ecology for feature engineering - Embrace the open source ecology, OpenMLDB fully opens up the MLOps ecological tool chain
猜你喜欢
Jetpack use exception problem collection

OpenMLDB v0.5.0 released | Performance, cost, flexibility reach new heights
Day 80
微信小程序云开发项目wx-store代码详解
Intelligent risk control China design and fall to the ground
将一个excel文件中多个sheet页“拆分“成多个“独立“excel文件
C语言-6月10日-my_strcat函数的编写
The whole process of Tinker access --- Compilation

父子节点数据格式不一致的树状列表实现
微信小程序_开发工具的安装

随机推荐
stack stack
Day 68
Pinyougou project combat notes
Interpretation of the paper: Cross-Modality Fusion Transformer for Multispectral Object Detection
c语言-数据存储部分
nepctf Nyan Cat 彩虹猫
127.0.0.1 connection refused
【LeetCode-36】有效的数独
JVM tuning and finishing
将一个excel文件中多个sheet页“拆分“成多个“独立“excel文件
【LeetCode-349】两个数组的交集
Goldbach's conjecture and the ring of integers
C语言-7月19日-指针的学习
自己动手写RISC-V的C编译器-01实现加减法
Open Source Machine Learning Database OpenMLDB Contributor Program Fully Launched
Minutes of OpenMLDB Meetup No.2
Promise.race learning (judging the fastest execution of multiple promise objects)
Node 踩坑之80端口被占用
Getting Started with JNI
【LeetCode-202】快乐数