当前位置:网站首页>Interpretation of the paper: Cross-Modality Fusion Transformer for Multispectral Object Detection
Interpretation of the paper: Cross-Modality Fusion Transformer for Multispectral Object Detection
2022-08-11 06:32:00 【pontoon】

(visible and thermal)
The thermal image on the right captures sharper outlines of pedestrians in low-light situations.Additionally, the thermal imagery captured pedestrians obscured by the pillars.In bright daylight, visual images have more detail, such as edges, textures and colors, than thermal images.With these details, we can easily find the driver hidden in the motor tricycle, which is difficult to find in thermal images.
1. Bottleneck problem:
The environment in the real world is constantly changing, such as rainy days, foggy days, sunny days, cloudy days, etc. It is difficult for algorithms to detect dynamic environmental changes using only visible sensor data (such as images captured by cameras).Target.Therefore, multispectral imaging techniques are gradually being adopted because of its ability to provide combined information from multispectral cameras, such as visible light and thermal imaging.And by fusing the complementarity of different modalities, the perceptibility, reliability and robustness of the detection algorithm can be further improved.
However, the introduction of multispectral data will create new problems:
a. How to integrate representations to take advantage of the inherent complementarity between different modalities?
b. And how to design an efficient cross-modal fusion mechanism to achieve maximum performance forming gain?
Extending them to cross-modal fusion or modal interaction using convolutional networks to take full advantage of the inherent complementarity is not trivial.Since the convolution operator has a non-global receptive field, the information is only fused within local regions.
2. Contribution of this article:
(1) Introduces a new powerful dual-stream backbone that augments one modality from another based on the Transformer scheme.
(2) We propose a simple and effective CFT module and conduct a theoretical analysis on it, showing that the CFT module fuses both intra-modal and inter-modal features.
(3) Experimental results achieve state-of-the-art performance on three public datasets, which confirms the effectiveness of the proposed method.
3. Solution:
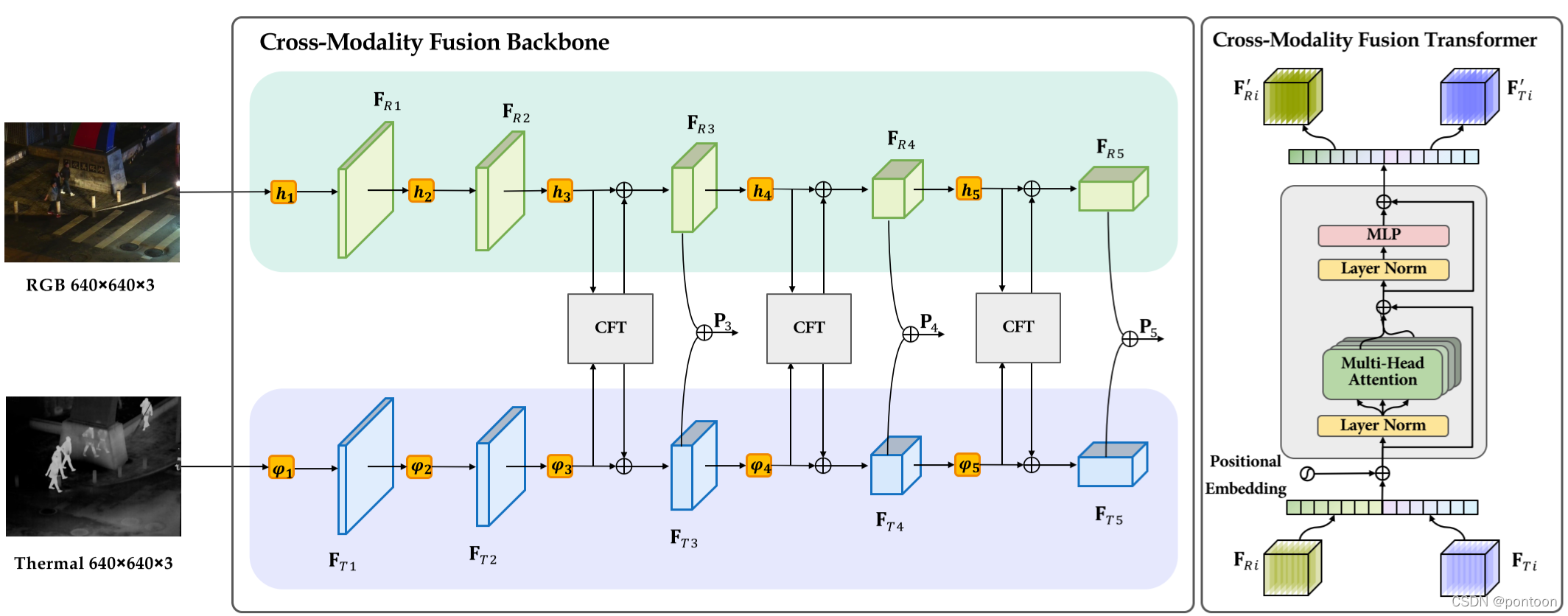
Changes are made under the basic network framework of yolov5
The input is an image pair of different modalities, the backbone is changed to a two-stream network, and CFT (Cross-Modality Fusion Transformer) is embedded in it
Flatten the convolved feature maps of the two modal images and concat them together (denoted as I, (2HW*C)), and add positional coding to form the input of the CFT
Multiply three copies of I and the corresponding W(C*C) to obtain QKV.
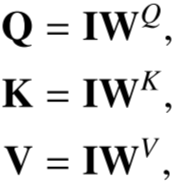
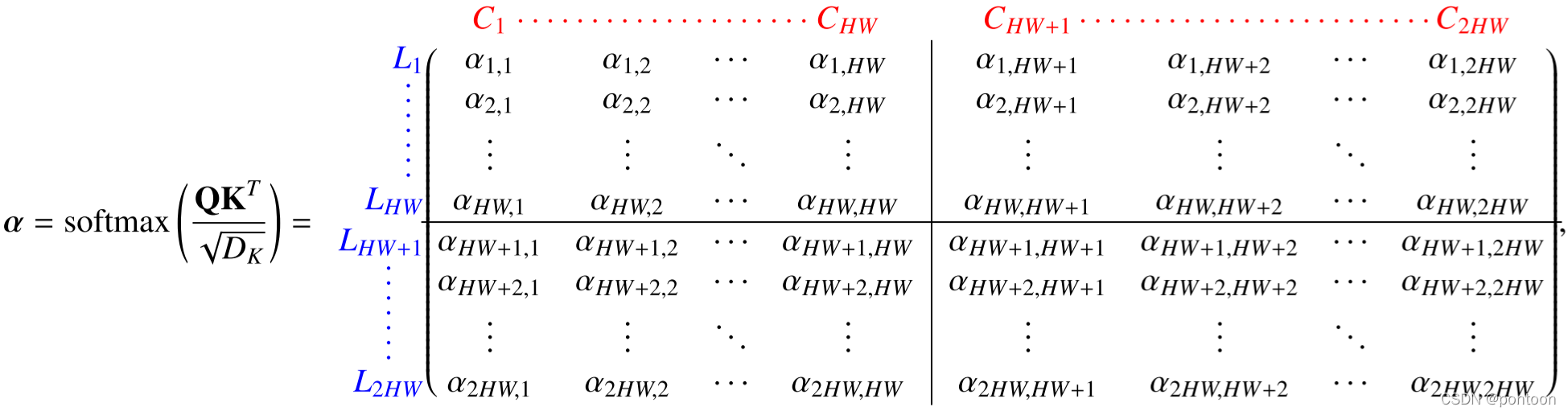
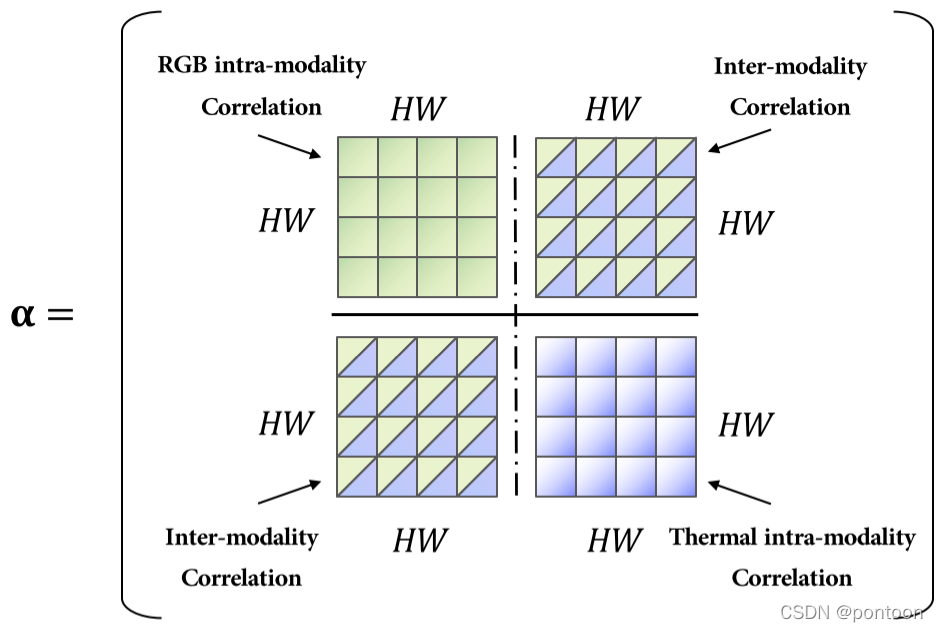
The Transformer mechanism enables features of different modalities to interact.
Therefore, the modal fusion module does not need to be carefully designed.We simply concatenate multi-modal features into a sequence, and Transformer can automatically perform simultaneous intra- and inter-modal information fusion and robustly capture potential interactions between RGB and Ther-.
Experiment:
Experiments on three public datasets (FILP. LLVIP. VEDAI.)
Training parameters:
We use SGD optimizer with an initial learning rate of 1e-2, a momentum of 0.937, and a weight decay of 0.0005. As for data augmentation, we use the Mosaic method which mixes four training images in one image.
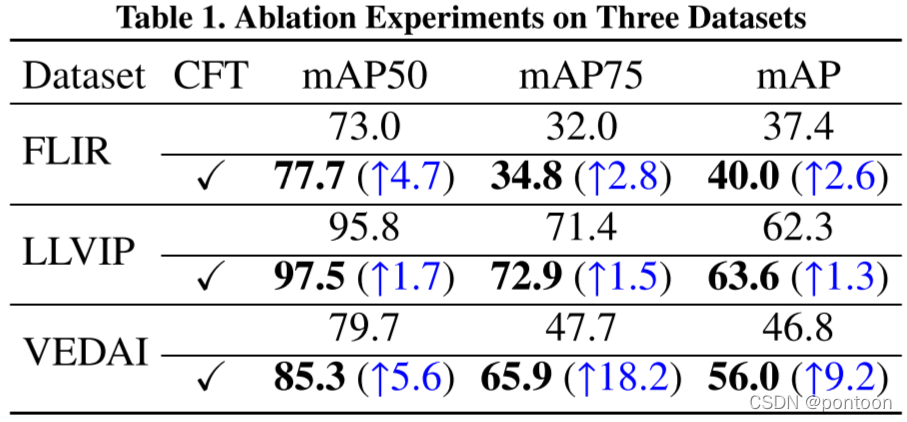
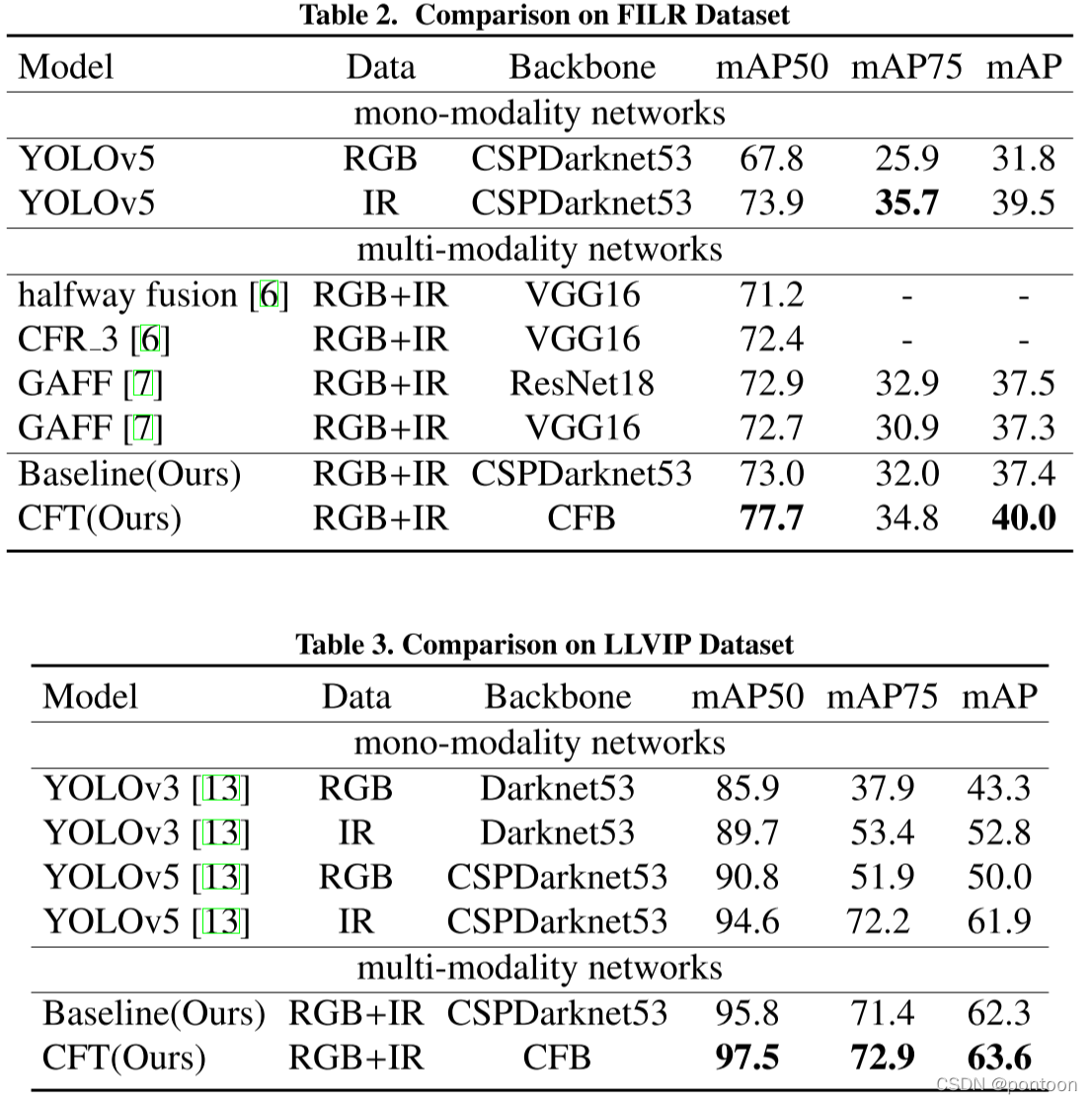
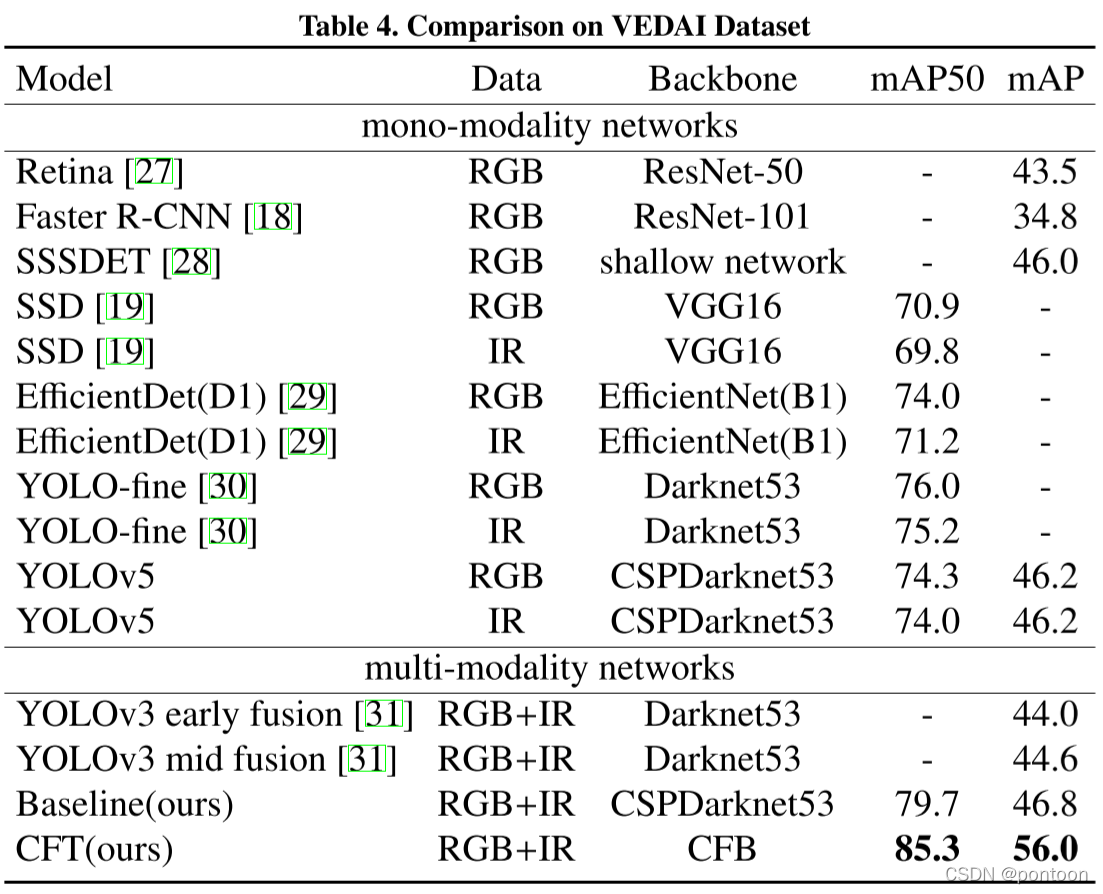
p>Ablation experiment was done on yolov5:
Comparison of experimental results on the FILP. dataset: (red arrows indicate missed detections)
Line 1: true tag
The second line: detection network without CFT
The third line: detection network with CFT

Comparison of experimental results on the LLVIP. dataset: (red arrows indicate missed detections)
Line 1: true tag
The second line: detection network without CFT
The third line: detection network with CFT

Comparison of experimental results on the VEDAI. dataset: (red arrows are missed detections, blue arrows are over-detected)
Line 1: true tag
The second line: detection network without CFT
The third line: detection network with CFT

Experimental metrics on three different datasets prove that the proposed method is optimal:
边栏推荐
猜你喜欢

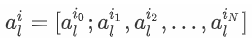

随机推荐
CMT2380F32模块开发7-reset例程
华为IOT设备消息上报和消息下发验证
NUC980-开发环境搭建
栈stack
论文解读:GAN与检测网络多任务/SOD-MTGAN: Small Object Detection via Multi-Task Generative Adversarial Network
mount命令--挂载出现只读,解决方案
Argparse模块 学习
The latest safety helmet wearing recognition system in 2022
华为IOT平台温度过高时自动关闭设备场景试用
Error: Flash Download failed - “Cortex-M4“-STM32F4
Node-1.高性能服务器
Vscode远程连接服务器终端zsh+Oh-my-zsh + Powerlevel10 + Autosuggestions + Autojump + Syntax-highlighting
typescript学习日记,从基础到进阶(第二章)
ActiveReports报表分类之页面报表
实时姿态估计--基于空洞卷积的人体姿态估计网络
使用adb命令管理应用
js常用方法对象及属性
scanf函数在混合接受数据(%d和%c相连接)时候的方式
C语言实现简易扫雷(附带源码)
HTTP缓存机制详解