当前位置:网站首页>高并发+海量数据下如何实现系统解耦?【下】
高并发+海量数据下如何实现系统解耦?【下】
2022-08-10 01:00:00 【石杉的架构笔记】
一、前情提示
上一篇文章《高并发+海量数据下如何实现系统解耦?【中】》分析了一下如何利用消息中间件对系统进行解耦处理。
同时,我们也提到了使用消息中间件还有利于一份数据被多个系统同时订阅,供多个系统来使用于不同的目的。
目前的一个架构如下图所示。
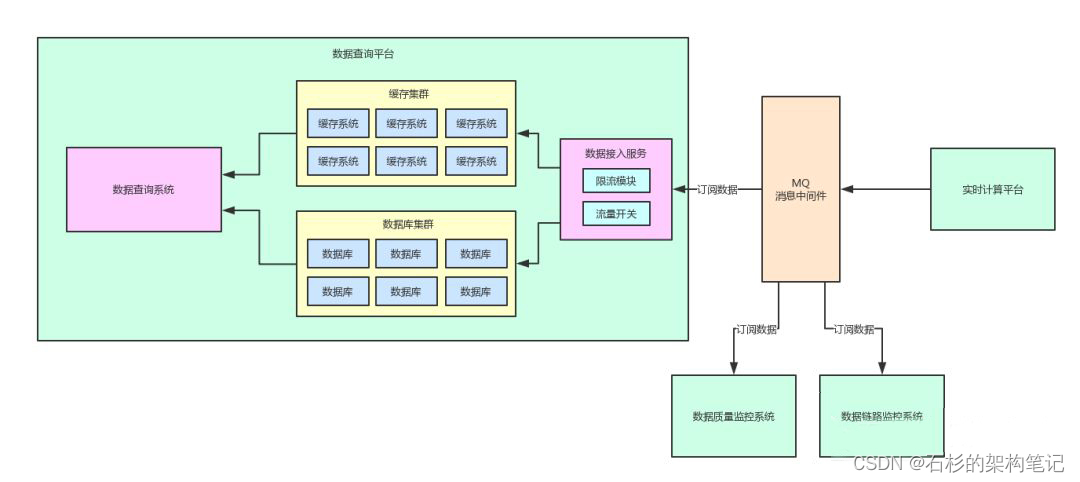
在这个图里,我们可以清晰的看到,实时计算平台发布的一份数据到消息中间件里,接着,会进行如下步骤:
- 数据查询平台会订阅这份数据,并落入自己本地的数据库集群和缓存集群里,接着对外提供数据查询的服务
- 数据质量监控系统会对计算结果按照一定的业务规则进行监控,如果发现有数据计算错误,则会立马进行报警
- 数据链路追踪系统会采集计算结果作为一个链路节点,同时对一条数据的整个完整计算链路都进行采集并组装出来一系列的数据计算链路落地存储,最后如果某个数据计算错误了,就可以立马通过计算链路进行回溯排查问题
因此上述场景中,使用消息中间件一来可以解耦,二来还可以实现消息“Pub/Sub”模型,实现消息的发布与订阅。
这篇文章,咱们就来看看,假如说基于RabbitMQ作为消息中间件,如何实现一份数据被多个系统同时订阅的“Pub/Sub”模型。
二、基于消息中间件的队列消费模型

上面那个图,其实就是采用的RabbitMQ最基本的队列消费模型的支持。
也就是说,你可以理解为RabbitMQ内部有一个队列,生产者不断的发送数据到队列里,消息按照先后顺序进入队列中排队。
接着,假设队列里有4条数据,然后我们有2个消费者一起消费这个队列的数据。
此时每个消费者会均匀的被分配到2条数据,也就是说4条数据会均匀的分配给各个消费者,每个消费者只不过是处理一部分数据罢了,这个就是典型的队列消费模型。
如果有同学对这块基于RabbitMQ如何实现有点不太清楚的话,可以参考之前的一些文章:
- 《RabbitMQ是如何收发消息的?(通俗易懂)》
- 《车祸现场!线上突然宕机,一条订单消息丢失了…》
- 《RabbitMQ宕机后,消息100%不会丢失吗》
之前这几篇文章,基本给出了上述那个最基本的队列消费模型的RabbitMQ代码实现,以及如何保证消费者宕机时数据不丢失,如何让RabbitMQ集群对queue和message都进行持久化。基本上整体代码实现都比较完整,大家可以参考一下。
三、基于消息中间件的“Pub/Sub”模型
但是消息中间件还可以实现一种“Pub/Sub”模型,也就是“发布/订阅”模型,Pub就是Publish,Sub就是Subscribe。
这种模型是可以支持多个系统同时消费一份数据的。也就是说,你发布出去的每条数据,都会广播给每个系统。
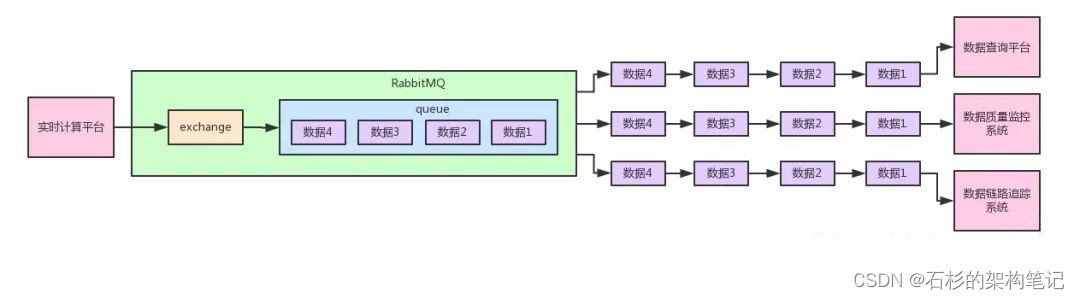
给大家来一张图,一起来感受一下。

如上图所示。也就是说,我们想要实现的上图的效果,实时计算平台发布一系列的数据到消息中间件里。
然后数据查询平台、数据质量监控系统、数据链路追踪系统,都会订阅数据,都会消费到同一份完整的数据,每个系统都可以根据自己的需要使用数据。
这,就是所谓的“Pub/Sub”模型,一个系统发布一份数据出去,多个系统订阅和消费到一模一样的一份数据。
那如果要实现上述的效果,基于RabbitMQ应该怎么来处理呢?
四、RabbitMQ中的exchange到底是个什么东西?
实际上来说,在RabbitMQ里面是不允许生产者直接投递消息到某个queue(队列)里的,而是只能让生产者投递消息给RabbitMQ内部的一个特殊组件,叫做“exchange”。
关于这个exchange,大概你可以把这个组件理解为一种消息路由的组件。
也就是说,实时计算平台发送出去的message到RabbitMQ中都是由一个exchange来接收的。
然后这个exchange会根据一定的规则决定要将这个message路由转发到哪个queue里去,这个实际上就是RabbitMQ中的一个核心的消息模型。
大家看下面的图,一起来理解一下。
五、默认的exchange
在之前的文章里,我们投递消息到RabbitMQ的时候,也没有用什么exchange,但是为什么就还是把消息投递到了queue里去呢?
那是因为我们用了默认的exchange,他会直接把消息路由到你指定的那个queue里去,所以如果简单用队列消费模型,不就省去了exchange的概念了吗。

上面这段就是之前我们给大家展示的,让消息持久化的一种投递消息的方式。
大家注意里面的第一个参数,是一个空的字符串,这个空字符串的意思,就是说投递消息到默认的exchange里去,然后他就会路由消息到我们指定的queue里去。
六、将消息投递到fanout exchange
在RabbitMQ里,exchange这种组件有很多种类型,比如说:direct、topic、headers以及fanout。这里咱们就来看看最后一种,fanout这种类型的exchange组件。
这种exchange组件其实非常的简单,你可以创建一个fanout类型的exchange,然后给这个exchange绑定多个queue。
接着只要你投递一条消息到这个exchange,他就会把消息路由给他绑定的所有queue。
使用下面的代码就可以创建一个exchange,比如说在实时计算平台**(生产者)**的代码里,可以加入下面的一段,创建一个fanout类型的exchange。
第一个参数我们叫做“rt_compute_data”,这个就是exchange的名字,rt就是“RealTime”的缩写,意思就是实时计算系统的计算结果数据。
第二个参数就是定义了这个exchange的类型是“fanout”。
channel.exchangeDeclare(
“rt_compute_data”,
“fanout”);
接着我们就采用下面的代码来投递消息到我们创建好的exchange组件里去:

大家会注意到,此时消息就是投递到指定的exchange里去了,但是路由到哪个queue里去呢?此时我们暂时还没确定,要让消费者自己来把自己的queue绑定到这个exchange上去才可以。
七、绑定自己的队列到exchange上去消费
我们对消费者的代码也进行修改,之前我们在这里关闭了autoAck机制,然后每次都是自己手动ack。
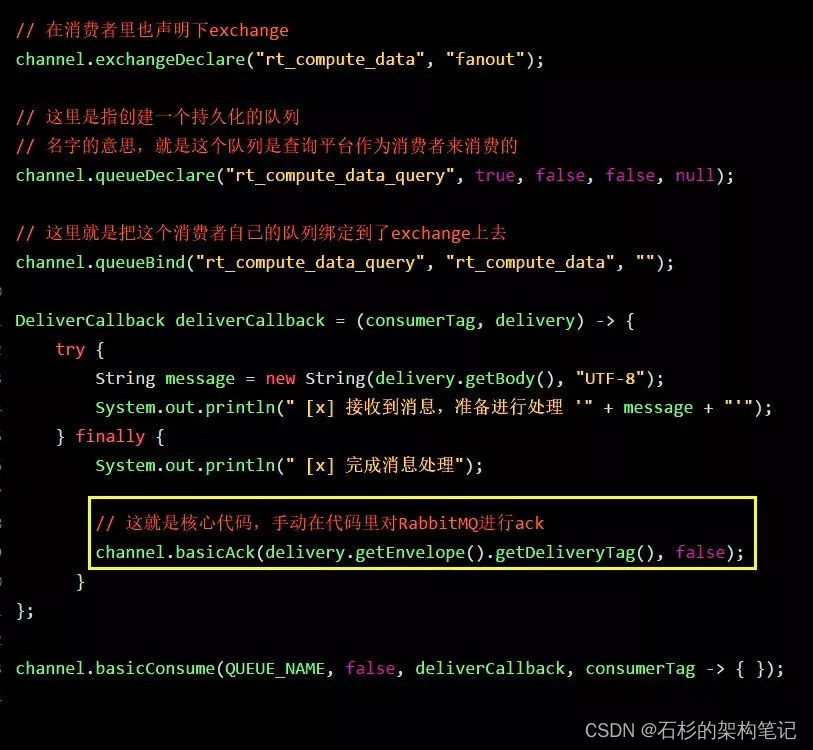
上面的代码里,每个消费者系统,都会有一些不一样,就是每个消费者都需要定义自己的队列,然后绑定到exchange上去。比如:
- 数据查询平台的队列是“rt_compute_data_query”
- 数据质量监控平台的队列是“rt_compute_data_monitor”
- 数据链路追踪系统的队列是“rt_compute_data_link”
这样,每个订阅这份数据的系统其实都有一个属于自己的队列,然后队列里被会被exchange路由进去实时计算平台生产的所有数据。
而且因为是多个队列的模式,每个系统都可以部署消费者集群来进行数据的消费和处理,非常的方便。
八、整体架构图
最后,给大家来一张大图,我们再跟着图,来捋一捋整个流程。

如上图所示,首先,实时计算平台会投递消息到“rt_compute_data”这个“exchange”里去,但是他没指定这个exchange要路由消息到哪个队列,因为这个他本身是不知道的。
接着数据查询平台、数据质量监控系统、数据链路追踪系统,就可以声明自己的队列,都绑定到exchange上去。
因为queue和exchange的绑定,在这里是要由订阅数据的平台自己指定的。而且因为这个exchange是fanout类型的,他只要接收到了数据,就会路由数据到所有绑定到他的队列里去,这样每个队列里都有同样的一份数据,供对应的平台来消费。
而且针对每个平台自己的队列,自己还可以部署消费服务集群来消费自己的一个队列,自己的队列里的数据还是会均匀分发给各个消费服务实例来处理,每个消费服务实例会获取到一部分的数据。
大家思考一下,这样是不是就实现了不同的系统订阅一份数据的“Pub/Sub”的模型?
当然,其实RabbitMQ还支持各种不同类型的exchange,可以实现各种复杂的功能。
后续我们将会给大家通过实际的线上系统架构案例,来阐述消息中间件技术的各种用法。
边栏推荐
- 什么是 PWA
- Research on Ethernet PHY Chip LAN8720A Chip
- CMake 编译运行dpdk项目程序
- Unity reports Unsafe code may only appear if compiling with /unsafe. Enable “Allow ‘unsafe’ code” in Pla
- UI遍历的初步尝试
- 浏览器中的history详解
- Entity FrameWork Core教程,从基础应用到原理实战
- [论文阅读] Diverse Image-to-Image Translation via Disentangled Representations
- 商业模式及其 SubDAO 深入研究
- Problems and solutions related to Chinese character set in file operations in ABAP
猜你喜欢
assert利用蚁剑登录

使用 GoogleTest 框架对 C 代码进行单元测试
Pagoda measurement - building LightPicture open source map bed system
小程序中计算距离信息
卷积神经网络识别验证码
Pyscript,创建一个能执行crud操作的网页应用

已备案域名用国外服务器会不会掉备案?

In the 2022 gold, nine, silver and ten work tide, how can I successfully change jobs and get a high salary?
Unity editor extension interface uses List

unity 报错 Unsafe code may only appear if compiling with /unsafe. Enable “Allow ‘unsafe‘ code“ in Pla
随机推荐
防勒索病毒现状分析
Solidity最强对手:MOVE语言及新公链崛起
什么是 PWA
手把手教你编写性能测试用例
【LeetCode】求根节点到叶节点数字之和
XSS高级 svg 复现一个循环问题以及两个循环问题
你有对象类,我有结构体,Go lang1.18入门精炼教程,由白丁入鸿儒,go lang结构体(struct)的使用EP06
基于FTP协议实现文件上传与下载
20220809-PotPlayer如何设置默认字体色-设置默认字体色的方法
ITK编译remote库
【ROS2原理10】Interface数据的规定
Minimum number of steps to get out of the maze 2
R语言使用coxph函数构建生存分析回归模型,使用forestmodel包的forest_model函数可视化生存回归模型对应的森林图
Not, even the volume of the king to write code in the company are copying and pasting it reasonable?
CMake 编译运行dpdk项目程序
Unity editor extension interface uses List
彩色袜子题
递归 二分查找 冒泡排序 快速排序
Interlay集成至Moonbeam,为网络带来interBTC和INTR
Shader Graph learns various special effects cases