当前位置:网站首页>Hudi(1.0、2.0)简介
Hudi(1.0、2.0)简介
2022-08-06 19:16:00 【是小先生】
文章目录
Hudi(v1.0)
一、Hudi介绍
1、介绍
Hudi将带来流式处理大数据, 提供新数据集,同时比传统批处理效率高一个数据量级。

2、特性
(1)快速upsert,可插入索引
(2)以原子方式操作数据并具有回滚功能
(3)写入器之间的快照隔离
(4)savepoint用户数据恢复的保存点
(5)管理文件大小,使用统计数据布局
(6)数据行的异步压缩和柱状数据
(7)时间轴数据跟踪血统
二、Hudi快速构建
1、环境准备
Hadoop集群、Hive、Spark2.4.5(2.x)
2、Maven安装
(1)把apache-maven-3.6.1-bin.tar.gz上传到linux的/opt/software目录下
(2)解压apache-maven-3.6.1-bin.tar.gz到/opt/module/目录下面
tar -zxvf apache-maven-3.6.1-bin.tar.gz -C /opt/module/(3)修改apache-maven-3.6.1的名称为maven
mv apache-maven-3.6.1/ maven(4)添加环境变量到/etc/profile中
sudo vim /etc/profile #MAVEN_HOME export MAVEN_HOME=/opt/module/maven export PATH=$PATH:$MAVEN_HOME/bin(5)测试安装结果
source /etc/profile mvn -v(6)修改setting.xml,指定为阿里云
[[email protected] maven]$ cd conf [[email protected] maven]$ vim settings.xml <!-- 添加阿里云镜像--> <mirror> <id>nexus-aliyun</id> <mirrorOf>central</mirrorOf> <name>Nexus aliyun</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url> </mirror>
3、Git安装
[[email protected] software]$ sudo yum install git
[[email protected] software]$ git --version
4、构建Hudi
cd /opt/module/
git clone https://github.com/apache/hudi.git && cd hudi
vim pom.xml
<repository>
<id>nexus-aliyun</id>
<name>nexus-aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
mvn clean package -DskipTests -DskipITs
三、通过Spark-shell快速开始
1、Spark-shell启动
spark-shell启动,需要指定spark-avro模块,因为默认环境里没有,spark-avro模块版本好需要和spark版本对应,这里都是2.4.5。
[[email protected] hudi]# spark-shell --packages org.apache.spark:spark-avro_2.11:2.4.5 --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' --jars /opt/module/hudi/packaging/hudi-spark-bundle/target/hudi-spark-bundle_2.11-0.6.0-SNAPSHOT.jar
2、设置表名
设置表名,基本路径和数据生成器
scala> import org.apache.hudi.QuickstartUtils._
import org.apache.hudi.QuickstartUtils._
scala> import scala.collection.JavaConversions._
import scala.collection.JavaConversions._
scala> import org.apache.spark.sql.SaveMode._
import org.apache.spark.sql.SaveMode._
scala> import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceReadOptions._
scala> import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.DataSourceWriteOptions._
scala> import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.config.HoodieWriteConfig._
scala> val tableName = "hudi_trips_cow"
tableName: String = hudi_trips_cow
scala> val basePath = "file:///tmp/hudi_trips_cow"
basePath: String = file:///tmp/hudi_trips_cow
scala> val dataGen = new DataGenerator
dataGen: org.apache.hudi.QuickstartUtils.DataGenerator = org.apache.hudi.QuickstartUtils$DataGenerator@5cdd5ff9
3、插入数据
新增数据,生成一些数据,将其加载到DataFrame中,然后将DataFrame写入Hudi表
scala> val inserts = convertToStringList(dataGen.generateInserts(10))
scala> val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
scala> df.write.format("hudi").
| options(getQuickstartWriteConfigs).
| option(PRECOMBINE_FIELD_OPT_KEY, "ts").
| option(RECORDKEY_FIELD_OPT_KEY, "uuid").
| option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
| option(TABLE_NAME, tableName).
| mode(Overwrite).
| save(basePath)
Mode(overwrite)将覆盖重新创建表(如果已存在)。可以检查/tmp/hudi_trps_cow 路径下是否有数据生成。
[[email protected] ~]# cd /tmp/hudi_trips_cow/
[[email protected] hudi_trips_cow]# ls
americas asia
4、查询数据
scala> val tripsSnapshotDF = spark.
| read.
| format("hudi").
| load(basePath + "/*/*/*/*")
scala> tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
scala> spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()
+------------------+-------------------+-------------------+---+
| fare| begin_lon| begin_lat| ts|
+------------------+-------------------+-------------------+---+
| 64.27696295884016| 0.4923479652912024| 0.5731835407930634|0.0|
| 33.92216483948643| 0.9694586417848392| 0.1856488085068272|0.0|
| 27.79478688582596| 0.6273212202489661|0.11488393157088261|0.0|
| 93.56018115236618|0.14285051259466197|0.21624150367601136|0.0|
| 43.4923811219014| 0.8779402295427752| 0.6100070562136587|0.0|
| 66.62084366450246|0.03844104444445928| 0.0750588760043035|0.0|
|34.158284716382845|0.46157858450465483| 0.4726905879569653|0.0|
| 41.06290929046368| 0.8192868687714224| 0.651058505660742|0.0|
+------------------+-------------------+-------------------+---+
scala> spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show()
+-------------------+--------------------+----------------------+---------+----------+------------------+
|_hoodie_commit_time| _hoodie_record_key|_hoodie_partition_path| rider| driver| fare|
+-------------------+--------------------+----------------------+---------+----------+------------------+
| 20200701105144|6007a624-d942-4e0...| americas/united_s...|rider-213|driver-213| 64.27696295884016|
| 20200701105144|db7c6361-3f05-48d...| americas/united_s...|rider-213|driver-213| 33.92216483948643|
| 20200701105144|dfd0e7d9-f10c-468...| americas/united_s...|rider-213|driver-213|19.179139106643607|
| 20200701105144|e36365c8-5b3a-415...| americas/united_s...|rider-213|driver-213| 27.79478688582596|
| 20200701105144|fb92c00e-dea2-48e...| americas/united_s...|rider-213|driver-213| 93.56018115236618|
| 20200701105144|98be3080-a058-47d...| americas/brazil/s...|rider-213|driver-213| 43.4923811219014|
| 20200701105144|3dd6ef72-4196-469...| americas/brazil/s...|rider-213|driver-213| 66.62084366450246|
| 20200701105144|20f9463f-1c14-4e6...| americas/brazil/s...|rider-213|driver-213|34.158284716382845|
| 20200701105144|1585ad3a-11c9-43c...| asia/india/chennai|rider-213|driver-213|17.851135255091155|
| 20200701105144|d40daa90-cf1a-4d1...| asia/india/chennai|rider-213|driver-213| 41.06290929046368|
+-------------------+--------------------+----------------------+---------+----------+------------------+
由于测试数据分区是 区域/国家/城市,所以:
load(basePath “/*/*/*/*”)
5、修改数据
类似于插入新数据,使用数据生成器生成新数据对历史数据进行更新。将数据加载到DataFrame中并将DataFrame写入Hudi表中
scala> val updates = convertToStringList(dataGen.generateUpdates(10))
scala> val df = spark.read.json(spark.sparkContext.parallelize(updates, 2))
scala> df.write.format("hudi").
| options(getQuickstartWriteConfigs).
| option(PRECOMBINE_FIELD_OPT_KEY, "ts").
| option(RECORDKEY_FIELD_OPT_KEY, "uuid").
| option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
| option(TABLE_NAME, tableName).
| mode(Append).
| save(basePath)
6、增量查询
Hudi还提供了获取自给定提交时间戳以来以更改记录流的功能。这可以通过使用Hudi的增量查询并提供开始流进行更改的开始时间来实现。
scala> spark.
| read.
| format("hudi").
| load(basePath + "/*/*/*/*").
| createOrReplaceTempView("hudi_trips_snapshot")
scala> val commits = spark.sql("select distinct(_hoodie_commit_time) as commitTime from hudi_trips_snapshot order by commitTime").map(k => k.getString(0)).take(50)
scala> val beginTime = commits(commits.length - 2)
beginTime: String = 20200701105144
scala> val tripsIncrementalDF = spark.read.format("hudi").
| option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
| option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).
| load(basePath)
scala> tripsIncrementalDF.createOrReplaceTempView("hudi_trips_incremental")
scala> spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_incremental where fare > 20.0").show()
+-------------------+------------------+--------------------+-------------------+---+
|_hoodie_commit_time| fare| begin_lon| begin_lat| ts|
+-------------------+------------------+--------------------+-------------------+---+
| 20200701110546|49.527694252432056| 0.5142184937933181| 0.7340133901254792|0.0|
| 20200701110546| 90.9053809533154| 0.19949323322922063|0.18294079059016366|0.0|
| 20200701110546| 98.3428192817987| 0.3349917833248327| 0.4777395067707303|0.0|
| 20200701110546| 90.25710109008239| 0.4006983139989222|0.08528650347654165|0.0|
| 20200701110546| 63.72504913279929| 0.888493603696927| 0.6570857443423376|0.0|
| 20200701110546| 29.47661370147079|0.010872312870502165| 0.1593867607188556|0.0|
+-------------------+------------------+--------------------+-------------------+---+
这将提供在beginTime提交后的数据,并且fare>20的数据
7、时间点查询
根据特定时间查询,可以将endTime指向特定时间,beginTime指向000(表示最早提交时间)
scala> val beginTime = "000"
beginTime: String = 000
scala> val endTime = commits(commits.length - 2)
endTime: String = 20200701105144
scala> val tripsPointInTimeDF = spark.read.format("hudi").
| option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
| option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).
| option(END_INSTANTTIME_OPT_KEY, endTime).
| load(basePath)
scala> tripsPointInTimeDF.createOrReplaceTempView("hudi_trips_point_in_time")
scala> spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_point_in_time where fare > 20.0").show()
+-------------------+------------------+-------------------+-------------------+---+
|_hoodie_commit_time| fare| begin_lon| begin_lat| ts|
+-------------------+------------------+-------------------+-------------------+---+
| 20200701105144| 64.27696295884016| 0.4923479652912024| 0.5731835407930634|0.0|
| 20200701105144| 33.92216483948643| 0.9694586417848392| 0.1856488085068272|0.0|
| 20200701105144| 27.79478688582596| 0.6273212202489661|0.11488393157088261|0.0|
| 20200701105144| 93.56018115236618|0.14285051259466197|0.21624150367601136|0.0|
| 20200701105144| 43.4923811219014| 0.8779402295427752| 0.6100070562136587|0.0|
| 20200701105144| 66.62084366450246|0.03844104444445928| 0.0750588760043035|0.0|
| 20200701105144|34.158284716382845|0.46157858450465483| 0.4726905879569653|0.0|
| 20200701105144| 41.06290929046368| 0.8192868687714224| 0.651058505660742|0.0|
+-------------------+------------------+-------------------+-------------------+---+
8、删除数据
scala> spark.sql("select uuid, partitionPath from hudi_trips_snapshot").count()
res12: Long = 10
scala> val ds = spark.sql("select uuid, partitionPath from hudi_trips_snapshot").limit(2)
scala> val deletes = dataGen.generateDeletes(ds.collectAsList())
scala> val df = spark.read.json(spark.sparkContext.parallelize(deletes, 2));
scala> df.write.format("hudi").
| options(getQuickstartWriteConfigs).
| option(OPERATION_OPT_KEY,"delete").
| option(PRECOMBINE_FIELD_OPT_KEY, "ts").
| option(RECORDKEY_FIELD_OPT_KEY, "uuid").
| option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
| option(TABLE_NAME, tableName).
| mode(Append).
| save(basePath)
scala> val roAfterDeleteViewDF = spark.
| read.
| format("hudi").
| load(basePath + "/*/*/*/*")
scala> roAfterDeleteViewDF.registerTempTable("hudi_trips_snapshot")
scala> spark.sql("select uuid, partitionPath from hudi_trips_snapshot").count()
res15: Long = 8
只有append模式,才支持删除功能。
四、基础用例
1、近实时摄取
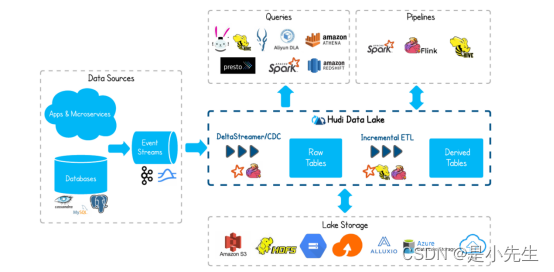
将外部数据(例如事件日志,数据库,外部源)如何摄取到Hadoop Data Lake是一个众所周知的问题。在大多数Hadoop部署中,经常会以零碎的方式,使用多种摄取工具解决,这些数据对整个组织是最具有价值的。
对于RDBMS关系型的摄入,Hudi提供了更快的Upset操作。例如,你可以通过MySql binlog的形式或者Sqoop导入到hdfs上的对应的Hudi表中,这样操作比Sqoop批量合并job(Sqoop merge)和复杂合并工作流更加快速高效。
对于NoSql的数据库,比如Cassandra,Voldemort,Hbase,这种可以存储数十亿行的数据库。采用完全批量加载是根本不可行的,并且如果摄取数据要跟上通常较高的更新量,则需要更有效的方法。
即使对于像Kafka这样不可变数据库源,Hudi也会在HDFS 上强制执行最小文件大小,从而通过整体解决Hadoop领域中小文件过多问题,改善NameNode的运行状况。对于事件流尤为重要,因为事件流通常较大(例如:点击流),并且如果管理不善,可能会严重损害Hadoop集群。
在所有来源中,Hudi都增加了急需的功能,即通过提交概念将新数据原子推送给消费者,避免摄入数据失败。
2、近实时分析
通常,实时数据集市由专门的分析存储(例如Druid或Memsql,OpenTSDB)提供支持,对于较低规模的数据,这绝对是完美的,可实现亚秒级响应查询。但是通常这些数据库最终会因为交互性较低的查询而被滥用,导致利用率不足。
另一方面,Hadoop上交互式的SQL解决方案有Presto和Spark sql。将数据的更新时间缩短至几分钟,Hudi可以提供多种高效的替代方案,并可以对存储在DFS中的多个大小表进行实时分析,此外Hudi没有外部依赖,例如专用实时分析的专用HBase集群,因此可以在不增加操作开销的情况下,进行更快更新鲜的分析。
3、增量处理管道
Hadoop提供的一项基本功能是,通过表示为工作流的DAG来构建彼此衍生的表链。工作流通常取决于多个上游工作流输出的新数据,并且传统上,新数据的可用性由新的DFS文件夹/配置单元分区指示。让我们举一个具体的例子来说明这一点。上游工作流U可以每小时创建一个Hive分区,并在每小时的末尾(processing_time)包含该小时(event_time)的数据,从而提供1小时的有效刷新。然后,下游工作流D在U完成后立即开始,并在接下来的一个小时内进行自己的处理,从而将有效延迟增加到2个小时。
上述范例只是忽略了延迟到达的数据,即,processing_time和event_time分开时。不幸的是,在当今的后移动和物联网前世界中,间歇性连接的移动设备和传感器的最新数据是正常现象,而不是反常现象。在这种情况下,保证正确性的唯一补救方法是每小时一次又一次地重新处理最后几个小时的数据,这会严重损害整个生态系统的效率。例如想象在数百个工作流程中每小时重新处理价值TB的数据。
Hudi通过提供一种以记录粒度(而不是文件夹/分区)消耗上游Hudi表HU的新数据(包括最新数据),应用处理逻辑并有效地更新/协调最新数据的方式再次进行救援。下游护桌HD。在这里,HU和HD可以以更频繁的时间表(例如15分钟)连续进行调度,并在HD上提供30分钟的终端延迟。
为了实现这一目标,Hudi从流处理框架(如Spark Streaming),发布/订阅系统(如Kafka)或数据库复制技术(如Oracle XStream)中采用了类似的概念
4、DFS的数据分散
Hudi可以像Kafka一样,用于数据分散,将每个管道的数据输出到Hudi表中,然后将其递增尾部以获取新数据并写入服务存储中。
五、与其他数据库对比
1、与Kudu对比
Apache Kudu是一个存储系统,其目标与Hudi类似,后者的目标是通过对Upserts的一流支持,对PB级数据进行实时分析。一个关键的区别是Kudu还试图充当OLTP工作负载的数据存储,而Hudi并不希望这样做。因此,Kudu不支持增量拉取(截至2017年初),Hudi这样做是为了启用增量处理用例。
Kudu与分布式文件系统抽象和HDFS完全不同,它自己的一组存储服务器通过RAFT相互通信。另一方面,Hudi旨在与底层Hadoop兼容文件系统(HDFS,S3或Ceph)一起使用,并且没有自己的存储服务器,而是依靠Apache Spark来完成繁重的工作。因此,就像其他Spark作业一样,Hudi可以轻松扩展,而Kudu则需要硬件和操作支持,这对于HBase或Vertica这样的数据存储来说是典型的。
2、与Hbase对比
HBase是OLTP工作负载的关键值存储,但鉴于与Hadoop的相似性,用户通常倾向于将HBase与分析相关联。 鉴于HBase经过严格的写优化,它支持开箱即用的亚秒级更新,Hive-on-HBase允许用户查询该数据。 但是,就分析工作负载的实际性能而言,混合列式存储格式(例如Parquet / ORC)可以轻松击败HBase,因为这些工作负载主要是读取繁重的工作。 Hudi弥补了更快的数据与具有分析性存储格式之间的差距。 从操作的角度来看,与仅管理分析用的大型HBase区域服务器场相比,为用户提供可提供更快数据的库更具可扩展性。 最终,HBase不像Hudi这样的一流公民来支持诸如提交时间,增量拉动之类的增量处理原语。
Hudi拥有更好数据分析能力。
3、与Streaming流式处理对比
Hudi可以与当今的批处理(写时复制表)和流式(读时合并表)作业集成,以将计算结果存储在Hadoop中。对于Spark应用程序,这可以通过将Hudi库与Spark / Spark流式DAG直接集成来实现。在非Spark处理系统(例如Flink,Hive)的情况下,可以在各个系统中进行处理,然后通过Kafka主题/ DFS中间文件将其发送到Hudi表中。从概念上讲,数据处理管道仅由三个部分组成:源,处理,接收器,用户最终针对接收器运行查询以使用管道的结果。 Hudi可以充当将数据存储在DFS上的源或接收器。 Hudi在给定流处理管道上的适用性最终归结为Presto / SparkSQL / Hive对您的查询的适用性。
六、Hudi中的名称概念
Apache Hudi通过Hadoop兼容存储提供以下流处理
(1)Update/Delete Records,更改表记录
(2)Change Streams,获取已更改记录
1、Timeline
Hudi的核心是维护不同时间对表执行的所有操作的事件表,这有助于提供表的即时视图,同时还有效地支持按到达顺序进行数据检索。Hudi包含以下组件:
(1)Instant action:在表上的操作类型
(2)Instant time:操作开始的一个时间戳,该时间戳会按照开始时间顺序单调递增
(3)state:即时状态
Hudi保证在时间轴上执行的操作都是原先性的,所有执行的操作包括:
(1)commits:原子的写入一张表的操作
(2)cleans:后台消除了表中的旧版本数据,即表中不在需要的数据
(3)delta_commit:增量提交,将一批数据原子写入到MergeOnRead表中,并且只记录到增量日志中
(4)compaction:后台协调Hudi中的差异数据
(5)rollback:回滚,删除在写入过程中的数据
(6)savepoint:将某些文件标记“已保存”,以便清理数据时不会删除它们,一般用于表的还原,可以将数据还原到某个时间点
任何操作都可以处于以下状态
(1)Requested:表示已安排操作行为,但是尚未开始
(2)Inflight:表示正在执行当前操作
(3)Completed:表示已完成操作

上图显示了hudi表上10:00和10:20之间发生的更新插入,每5分钟一次,将提交元数据留以及其他后台清理/压缩操作在hudi时间轴上。观察的关键点是,提交时间表示数据的到达时间,而实际数据组织则反应了实际时间或事件时间,即数据所反映的从07:00开始的每小时时段。在权衡数据延迟和完整性,这是两个关键概念。
如果有延迟到达的数据(事件时间为9:00的数据在10:20达到,延迟>1小时),可以看到upsert将数据生成到更旧的时间段/文件夹中。在时间轴的帮助下,增量查询可以只提取10:00以后成功提交的新数据,并非高效地只消费更改过的文件,且无需扫描更大的文件范围,例如07:00后的所有时间段。
2、File management
Hudi将表组织成DFS上基本路径下的目录结构。表分位几个分区,与hive类似,每个分区均有唯一标示。
在每个分区内,有多个数据组,每个数据组包含几个文件片,其中文件片包含基本文件和日志文件。Hudi采用MVCC设计,其中压缩操作将日志文件和基本数据文件合并成新的文件片,而清楚操作则将未使用的文件片去除。
3、索引
Hudi通过使用索引机制,生成hoodie密钥映射对应文件ID,从而提供高效upsert操作。
4、表类型
(1)Copy on Write:仅使用列式存储,例如parquet。仅更新版本号,通过写入过程中执行同步合并来重写文件
(2)Merge on Read:基于列式存储(parquet)和行式存储(arvo)结合的文件更始进行存储。更新记录到增量文件,压缩同步和异步生成新版本的文件
以下是对比
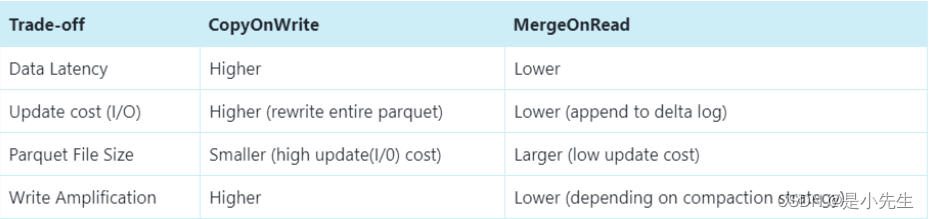
5、查询类型
(1)快照查询(*Snapshot Queries*):查询操作将查询最新快照的表数据。如果是Merge on Read类型的表,它将动态合并最新文件版本的基本数据和增量数据用于显示查询。如果是Copy On Write类型的表,它直接查询parquet表,同时提供upsert/delete操作.
(2)增量查询(*Incremental Queries*):查询只能看到写入表的新数据。这有效的提供了change streams来启用增量数据管道。
(3)优化读查询(*Read Optimized Queries*):查询将查看给定提交/压缩操作表的最新快照

七、Hudi代码测试
1、Hudi操作
1.1、pom.xml
<dependencies>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-client</artifactId>
<version>0.5.3</version>
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-hive</artifactId>
<version>0.5.3</version>
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-spark-bundle_2.11</artifactId>
<version>0.5.3</version>
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-common</artifactId>
<version>0.5.3</version>
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-hadoop-mr-bundle</artifactId>
<version>0.5.3</version>
</dependency>
<!-- Spark的依赖引入 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<!-- <scope>provided</scope>-->
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<!-- <scope>provided</scope>-->
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<!-- <scope>provided</scope>-->
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-avro_2.11</artifactId>
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<!-- <scope>provided</scope>-->
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<!-- <scope>provided</scope>-->
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>org.spark-project.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.1.spark2</version>
</dependency>
</dependencies>
1.2、case class
package com.atguigu.bean
case class DwsMember(
uid: Int,
ad_id: Int,
var fullname: String,
iconurl: String,
dt: String,
dn: String
)
1.3、配置文件
集群配置文件复制到,项目resource源码包下,使本地环境可以访问hadoop集群
1.4、HUdi写入Hdfs
package com.atguigu.hudi.test
import com.atguigu.bean.DwsMember
import com.atguigu.hudi.util.ParseJsonData
import org.apache.spark.SparkConf
import org.apache.spark.sql.{
SaveMode, SparkSession}
object HoodieDataSourceExample {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root")
val sparkConf = new SparkConf().setAppName("dwd_member_import")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val ssc = sparkSession.sparkContext
ssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://mycluster")
ssc.hadoopConfiguration.set("dfs.nameservices", "mycluster")
// insertData(sparkSession)
queryData(sparkSession)
}
/** * 读取hdfs日志文件通过hudi写入hdfs * * @param sparkSession */
def insertData(sparkSession: SparkSession) = {
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val commitTime = System.currentTimeMillis().toString //生成提交时间
val df = sparkSession.read.text("/user/atguigu/ods/member.log")
.mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = ParseJsonData.getJsonData(item.getString(0))
DwsMember(jsonObject.getIntValue("uid"), jsonObject.getIntValue("ad_id")
, jsonObject.getString("fullname"), jsonObject.getString("iconurl")
, jsonObject.getString("dt"), jsonObject.getString("dn"))
})
})
val result = df.withColumn("ts", lit(commitTime)) //添加ts 时间戳列
.withColumn("uuid", col("uid")) //添加uuid 列 如果数据中uuid相同hudi会进行去重
.withColumn("hudipartition", concat_ws("/", col("dt"), col("dn"))) //增加hudi分区列
result.write.format("org.apache.hudi")
// .options(org.apache.hudi.QuickstartUtils.getQuickstartWriteConfigs)
.option("hoodie.insert.shuffle.parallelism", 12)
.option("hoodie.upsert.shuffle.parallelism", 12)
.option("PRECOMBINE_FIELD_OPT_KEY", "ts") //指定提交时间列
.option("RECORDKEY_FIELD_OPT_KEY", "uuid") //指定uuid唯一标示列
.option("hoodie.table.name", "testTable")
// .option(DataSourceWriteOptions.DEFAULT_PARTITIONPATH_FIELD_OPT_VAL, "dt") // 发现api方式不起作用 分区列
.option("hoodie.datasource.write.partitionpath.field", "hudipartition") //分区列
.mode(SaveMode.Overwrite)
.save("/user/atguigu/hudi")
}
测试发现,Hudi不能指定多分区列,所以代码上分区列采用两列拼接成一列的方式,提交操作时必须指定ts和uuid。写入成功后查看hadoop路径上的文件

1.5、查询Hdfs上Hudi数据
/** * 查询hdfs上的hudi数据 * * @param sparkSession */
def queryData(sparkSession: SparkSession) = {
val df = sparkSession.read.format("org.apache.hudi")
.load("/user/atguigu/hudi/*/*")
df.show()
}

1.6、修改Hdfs上Hudi数据
def updateData(sparkSession: SparkSession) = {
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val commitTime = System.currentTimeMillis().toString //生成提交时间
val df = sparkSession.read.text("/user/atguigu/ods/member.log")
.mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = ParseJsonData.getJsonData(item.getString(0))
DwsMember(jsonObject.getIntValue("uid"), jsonObject.getIntValue("ad_id")
, jsonObject.getString("fullname"), jsonObject.getString("iconurl")
, jsonObject.getString("dt"), jsonObject.getString("dn"))
})
})
val result = df.withColumn("ts", lit(commitTime)) //添加ts 时间戳列
.withColumn("uuid", col("uid")) //添加uuid 列 如果数据中uuid相同hudi会进行去重
.withColumn("hudipartition", concat_ws("/", col("dt"), col("dn"))) //增加hudi分区列
result.write.format("org.apache.hudi")
// .options(org.apache.hudi.QuickstartUtils.getQuickstartWriteConfigs)
.option("hoodie.insert.shuffle.parallelism", 12)
.option("hoodie.upsert.shuffle.parallelism", 12)
.option("PRECOMBINE_FIELD_OPT_KEY", "ts") //指定提交时间列
.option("RECORDKEY_FIELD_OPT_KEY", "uuid") //指定uuid唯一标示列
.option("hoodie.table.name", "testTable")
// .option(DataSourceWriteOptions.DEFAULT_PARTITIONPATH_FIELD_OPT_VAL, "dt") // 发现api方式不起作用 分区列
.option("hoodie.datasource.write.partitionpath.field", "hudipartition") //分区列
.mode(SaveMode.Append)
.save("/user/atguigu/hudi")
}
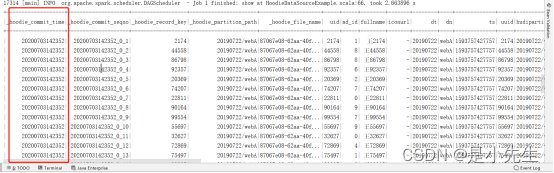
虽然代码操作和新增一样只是修改了插入模式为append,但是hudi会根据uid判断进行更新数据,操作完毕后,生成一份最新的修改后的数据。同时hdfs路径上写入一份数据。

提交时间发生了变化
1.7、增量查询
def incrementalQuery(sparkSession: SparkSession) = {
val beginTime = 20200703130000l
val df = sparkSession.read.format("org.apache.hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL) //指定模式为增量查询
.option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY, beginTime) //设置开始查询的时间戳 不需要设置结束时间戳
.load("/user/atguigu/hudi")
df.show()
println(df.count())
}

根据haoodie_commit_time,时间进行查询,查询增量修改数据,注意参数begintime是和hadoop_commit_time对比而不是跟ts对比。如果beginitime填了比haoodie_commit_time大则会过滤所有数据。


1.8、指定特定时间查询
def updateData(sparkSession: SparkSession) = {
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val commitTime = System.currentTimeMillis().toString //生成提交时间
val df = sparkSession.read.text("/user/atguigu/ods/member.log")
.mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = ParseJsonData.getJsonData(item.getString(0))
DwsMember(jsonObject.getIntValue("uid"), jsonObject.getIntValue("ad_id")
, jsonObject.getString("fullname"), jsonObject.getString("iconurl")
, jsonObject.getString("dt"), jsonObject.getString("dn"))
})
}).limit(100)
val result = df.withColumn("ts", lit(commitTime)) //添加ts 时间戳列
.withColumn("uuid", col("uid")) //添加uuid 列 如果数据中uuid相同hudi会进行去重
.withColumn("hudipartition", concat_ws("/", col("dt"), col("dn"))) //增加hudi分区列
result.write.format("org.apache.hudi")
// .options(org.apache.hudi.QuickstartUtils.getQuickstartWriteConfigs)
.option("hoodie.insert.shuffle.parallelism", 12)
.option("hoodie.upsert.shuffle.parallelism", 12)
.option("PRECOMBINE_FIELD_OPT_KEY", "ts") //指定提交时间列
.option("RECORDKEY_FIELD_OPT_KEY", "uuid") //指定uuid唯一标示列
.option("hoodie.table.name", "testTable")
// .option(DataSourceWriteOptions.DEFAULT_PARTITIONPATH_FIELD_OPT_VAL, "dt") // 发现api方式不起作用 分区列
.option("hoodie.datasource.write.partitionpath.field", "hudipartition") //分区列
.mode(SaveMode.Append)
.save("/user/atguigu/hudi")
}
def pointInTimeQuery(sparkSession: SparkSession) = {
val beginTime = 20200703150000l
val endTime = 20200703160000l
val df = sparkSession.read.format("org.apache.hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL) //指定模式为增量查询
.option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY, beginTime) //设置开始查询的时间戳
.option(DataSourceReadOptions.END_INSTANTTIME_OPT_KEY, endTime)
.load("/user/atguigu/hudi")
df.show()
println(df.count())
}
演示,update时limit只修改100条数据,然后根据时间戳进行查询,只会查询出进行修改的100条符合时间的数据.


2、Hudi集成hive
2.1、将编译好的hudi-hadoop-mr包复制到hive lib下
cp ./packaging/hudi-hadoop-mr-bundle/hudi-hadoop-mr-bundle-0.6.0-SNAPSHOT.jar /opt/module/apache-hive-3.1.2-bin/lib
2.2、建表
hudi会自动创建表,也可以提前手动建表
CREATE EXTERNAL TABLE `member_rt`(
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_partition_path` string,
`_hoodie_file_name` string,
`uid` int,
`ad_id` int,
`fullname` string,
`iconurl` string,
`ts` string,
`hudipartition` string)
PARTITIONED BY (
`dt` string,
`dn` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://mycluster/user/atguigu/hudi/hivetest'
2.3、测试类
package com.atguigu.hudi.test
import com.atguigu.bean.DwsMember
import com.atguigu.hudi.util.ParseJsonData
import org.apache.hudi.DataSourceWriteOptions
import org.apache.hudi.config.HoodieIndexConfig
import org.apache.hudi.hive.MultiPartKeysValueExtractor
import org.apache.hudi.index.HoodieIndex
import org.apache.spark.SparkConf
import org.apache.spark.sql.{
SaveMode, SparkSession}
object HudiTestHive {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root")
val sparkConf = new SparkConf().setAppName("dwd_member_import")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
val ssc = sparkSession.sparkContext
ssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://mycluster")
ssc.hadoopConfiguration.set("dfs.nameservices", "mycluster")
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val commitTime = System.currentTimeMillis().toString //生成提交时间
val df = sparkSession.read.text("/user/atguigu/ods/member.log")
.mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = ParseJsonData.getJsonData(item.getString(0))
DwsMember(jsonObject.getIntValue("uid"), jsonObject.getIntValue("ad_id")
, jsonObject.getString("fullname"), jsonObject.getString("iconurl")
, jsonObject.getString("dt"), jsonObject.getString("dn"))
})
}).withColumn("ts", lit(commitTime))
.withColumn("hudipartition", concat_ws("/", col("dt"), col("dn")))
Class.forName("org.apache.hive.jdbc.HiveDriver");
df.write.format("org.apache.hudi")
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY, DataSourceWriteOptions.MOR_TABLE_TYPE_OPT_VAL) //选择表的类型 到底是MERGE_ON_READ 还是 COPY_ON_WRITE
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "uid") //设置主键
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "ts") //数据更新时间戳的
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "hudipartition") //hudi分区列
.option("hoodie.table.name", "member") //hudi表名
.option(DataSourceWriteOptions.HIVE_URL_OPT_KEY, "jdbc:hive2://hadoop101:10000") //hiveserver2地址
.option(DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY, "default") //设置hudi与hive同步的数据库
.option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY, "member") //设置hudi与hive同步的表名
.option(DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY, "dt,dn") //hive表同步的分区列
.option(DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY, classOf[MultiPartKeysValueExtractor].getName) // 分区提取器 按/ 提取分区
.option(DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY, "true") //设置数据集注册并同步到hive
.option(HoodieIndexConfig.BLOOM_INDEX_UPDATE_PARTITION_PATH, "true") //设置当分区变更时,当前数据的分区目录是否变更
.option(HoodieIndexConfig.INDEX_TYPE_PROP, HoodieIndex.IndexType.GLOBAL_BLOOM.name()) //设置索引类型目前有HBASE,INMEMORY,BLOOM,GLOBAL_BLOOM 四种索引 为了保证分区变更后能找到必须设置全局GLOBAL_BLOOM
.option("hoodie.insert.shuffle.parallelism", "12")
.option("hoodie.upsert.shuffle.parallelism", "12")
.mode(SaveMode.Append)
.save("/user/atguigu/hudi/hivetest")
}
}
跑完任务之后,去查询hive表,通过hive-shell查询

使用spark-shell,spark on hive方式查询

Hudi集成hive,即Hudi同步数据到hive,供hive查询
3、表类型对比
3.1、生成数据
(1)针对copy_on_write表和merge_on_read表同时生成两份表数据,读取member日志数据各自生成两种类型的表
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root")
val sparkConf = new SparkConf().setAppName("dwd_member_import")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val ssc = sparkSession.sparkContext
ssc.hadoopConfiguration.set("fs.defaultFS", "hdfs://mycluster")
ssc.hadoopConfiguration.set("dfs.nameservices", "mycluster")
generateData(sparkSession)
// queryData(sparkSession)
// updateData(sparkSession)
// queryData(sparkSession)
}
def generateData(sparkSession: SparkSession) = {
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val commitTime = System.currentTimeMillis().toString //生成提交时间
val df = sparkSession.read.text("/user/atguigu/ods/member.log")
.mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = ParseJsonData.getJsonData(item.getString(0))
DwsMember(jsonObject.getIntValue("uid"), jsonObject.getIntValue("ad_id")
, jsonObject.getString("fullname"), jsonObject.getString("iconurl")
, jsonObject.getString("dt"), jsonObject.getString("dn"))
})
}).withColumn("ts", lit(commitTime))
.withColumn("hudipartition", concat_ws("/", col("dt"), col("dn")))
df.write.format("org.apache.hudi")
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY, DataSourceWriteOptions.MOR_TABLE_TYPE_OPT_VAL) //指定表类型为MERGE_ON_READ
.option("hoodie.insert.shuffle.parallelism", 12)
.option("hoodie.upsert.shuffle.parallelism", 12)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "uid") //指定记录键
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "ts") //数据更新时间戳的
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "hudipartition") //hudi分区列
.option("hoodie.table.name", "hudimembertest1") //hudi表名
.option(DataSourceWriteOptions.HIVE_URL_OPT_KEY, "jdbc:hive2://hadoop101:10000") //hiveserver2地址
.option(DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY, "default") //设置hudi与hive同步的数据库
.option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY, "member1") //设置hudi与hive同步的表名
.option(DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY, "dt,dn") //hive表同步的分区列
.option(DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY, classOf[MultiPartKeysValueExtractor].getName) // 分区提取器 按/ 提取分区
.option(DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY, "true") //设置数据集注册并同步到hive
.option(HoodieIndexConfig.BLOOM_INDEX_UPDATE_PARTITION_PATH, "true") //设置当分区变更时,当前数据的分区目录是否变更
.option(HoodieIndexConfig.INDEX_TYPE_PROP, HoodieIndex.IndexType.GLOBAL_BLOOM.name()) //设置索引类型目前有HBASE,INMEMORY,BLOOM,GLOBAL_BLOOM 四种索引 为了保证分区变更后能找到必须设置全局GLOBAL_BLOOM
.option("hoodie.insert.shuffle.parallelism", "12")
.option("hoodie.upsert.shuffle.parallelism", "12")
.mode(SaveMode.Overwrite)
.save("/user/atguigu/hudi/hudimembertest1")
df.write.format("org.apache.hudi")
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY, DataSourceWriteOptions.COW_TABLE_TYPE_OPT_VAL) //指定表类型为COPY_ON_WRITE
.option("hoodie.insert.shuffle.parallelism", 12)
.option("hoodie.upsert.shuffle.parallelism", 12)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "uid") //指定记录键
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "ts") //数据更新时间戳的
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "hudipartition") //hudi分区列
.option("hoodie.table.name", "hudimembertest2") //hudi表名
.option(DataSourceWriteOptions.HIVE_URL_OPT_KEY, "jdbc:hive2://hadoop101:10000") //hiveserver2地址
.option(DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY, "default") //设置hudi与hive同步的数据库
.option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY, "member2") //设置hudi与hive同步的表名
.option(DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY, "dt,dn") //hive表同步的分区列
.option(DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY, classOf[MultiPartKeysValueExtractor].getName) // 分区提取器 按/ 提取分区
.option(DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY, "true") //设置数据集注册并同步到hive
.option(HoodieIndexConfig.BLOOM_INDEX_UPDATE_PARTITION_PATH, "true") //设置当分区变更时,当前数据的分区目录是否变更
.option(HoodieIndexConfig.INDEX_TYPE_PROP, HoodieIndex.IndexType.GLOBAL_BLOOM.name()) //设置索引类型目前有HBASE,INMEMORY,BLOOM,GLOBAL_BLOOM 四种索引 为了保证分区变更后能找到必须设置全局GLOBAL_BLOOM
.option("hoodie.insert.shuffle.parallelism", "12")
.option("hoodie.upsert.shuffle.parallelism", "12")
.mode(SaveMode.Overwrite)
.save("/user/atguigu/hudi/hudimembertest2")
}
生成数据后,查看对应数据块大小,没有太大差别


查看hive,发现自动建好3张表,继续使用命令查看表结构

hive (default)> show create table member1_ro;
OK
createtab_stmt
CREATE EXTERNAL TABLE `member1_ro`(
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_partition_path` string,
`_hoodie_file_name` string,
`uid` int,
`ad_id` int,
`fullname` string,
`iconurl` string,
`ts` string,
`hudipartition` string)
PARTITIONED BY (
`dt` string,
`dn` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://mycluster/user/atguigu/hudi/hudimembertest1'
TBLPROPERTIES (
'bucketing_version'='2',
'last_commit_time_sync'='20200706143356',
'transient_lastDdlTime'='1594017284')
Time taken: 0.097 seconds, Fetched: 27 row(s)
hive (default)> show create table member1_rt;
OK
createtab_stmt
CREATE EXTERNAL TABLE `member1_rt`(
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_partition_path` string,
`_hoodie_file_name` string,
`uid` int,
`ad_id` int,
`fullname` string,
`iconurl` string,
`ts` string,
`hudipartition` string)
PARTITIONED BY (
`dt` string,
`dn` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://mycluster/user/atguigu/hudi/hudimembertest1'
TBLPROPERTIES (
'bucketing_version'='2',
'last_commit_time_sync'='20200706143356',
'transient_lastDdlTime'='1594017286')
Time taken: 0.048 seconds, Fetched: 27 row(s)
hive (default)> show create table member2;
OK
createtab_stmt
CREATE EXTERNAL TABLE `member2`(
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_partition_path` string,
`_hoodie_file_name` string,
`uid` int,
`ad_id` int,
`fullname` string,
`iconurl` string,
`ts` string,
`hudipartition` string)
PARTITIONED BY (
`dt` string,
`dn` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://mycluster/user/atguigu/hudi/hudimembertest2'
TBLPROPERTIES (
'bucketing_version'='2',
'last_commit_time_sync'='20200706143445',
'transient_lastDdlTime'='1594017317')
可以看到格式有两种HoodieParquetInputFormat和HoodieParquetRealtimeInputFormat,两种在hudi中是读优化视图和实时视图
具体来说,就写入过程中传递了两个由table_name命名的Hive表。例如,如果table_name = hudi_tb1,我们得到
- hudi_tb1实现了由HoodieParquetInputFormat支持的数据集读优化视图,从而提供了纯列式数据。
- hudi_tb1_rt实现了由HoodieParquetRealtimeInputFormat支持的数据集的实时视图,从而提供了基础数据和日志数据的合并视图。
Merge_ON_READ建表时会自动创建两种视图,COPY_ON_WRITE建表时只会自动创建读优化视图
查询表,都已同步数据


3.2、修改数据
有了数据之后对表进行更新操作,对两张表分别只更新uid 0-9的10条数据
def updateData(sparkSession: SparkSession) = {
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val commitTime = System.currentTimeMillis().toString //生成提交时间
val df = sparkSession.read.text("/user/atguigu/ods/member.log")
.mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = ParseJsonData.getJsonData(item.getString(0))
DwsMember(jsonObject.getIntValue("uid"), jsonObject.getIntValue("ad_id")
, jsonObject.getString("fullname"), jsonObject.getString("iconurl")
, jsonObject.getString("dt"), jsonObject.getString("dn"))
})
}).where("uid>=0 and uid<=9")
val result = df.map(item => {
item.fullname = "testName"
item
}).withColumn("ts", lit(commitTime))
.withColumn("hudipartition", concat_ws("/", col("dt"), col("dn")))
// result.show()
result.write.format("org.apache.hudi")
.option("hoodie.insert.shuffle.parallelism", 12)
.option("hoodie.upsert.shuffle.parallelism", 12)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "uid") //指定记录键
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "ts") //数据更新时间戳的
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "hudipartition") //hudi分区列
.option("hoodie.table.name", "hudimembertest1") //hudi表名1
.option(DataSourceWriteOptions.HIVE_URL_OPT_KEY, "jdbc:hive2://hadoop101:10000") //hiveserver2地址
.option(DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY, "default") //设置hudi与hive同步的数据库
.option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY, "member1") //设置hudi与hive同步的表名
.option(DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY, "dt,dn") //hive表同步的分区列
.option(DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY, classOf[MultiPartKeysValueExtractor].getName) // 分区提取器 按/ 提取分区
.option(DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY, "true") //设置数据集注册并同步到hive
.option(HoodieIndexConfig.BLOOM_INDEX_UPDATE_PARTITION_PATH, "true") //设置当分区变更时,当前数据的分区目录是否变更
.option(HoodieIndexConfig.INDEX_TYPE_PROP, HoodieIndex.IndexType.GLOBAL_BLOOM.name()) //设置索引
.option("hoodie.insert.shuffle.parallelism", "12")
.option("hoodie.upsert.shuffle.parallelism", "12")
.mode(SaveMode.Append)
.save("/user/atguigu/hudi/hudimembertest1")
result.write.format("org.apache.hudi")
.option("hoodie.insert.shuffle.parallelism", 12)
.option("hoodie.upsert.shuffle.parallelism", 12)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "uid") //指定记录键
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "ts") //数据更新时间戳的
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "hudipartition") //hudi分区列
.option("hoodie.table.name", "hudimembertest2") //hudi表名
.option(DataSourceWriteOptions.HIVE_URL_OPT_KEY, "jdbc:hive2://hadoop101:10000") //hiveserver2地址
.option(DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY, "default") //设置hudi与hive同步的数据库
.option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY, "member2") //设置hudi与hive同步的表名
.option(DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY, "dt,dn") //hive表同步的分区列
.option(DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY, classOf[MultiPartKeysValueExtractor].getName) // 分区提取器 按/ 提取分区
.option(DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY, "true") //设置数据集注册并同步到hive
.option(HoodieIndexConfig.BLOOM_INDEX_UPDATE_PARTITION_PATH, "true") //设置当分区变更时,当前数据的分区目录是否变更
.option(HoodieIndexConfig.INDEX_TYPE_PROP, HoodieIndex.IndexType.GLOBAL_BLOOM.name()) //设置索引
.option("hoodie.insert.shuffle.parallelism", "12")
.option("hoodie.upsert.shuffle.parallelism", "12")
.mode(SaveMode.Append)
.save("/user/atguigu/hudi/hudimembertest2")
}
修改完毕后,查看对应hdfs路径下的文件变化


可以看到对于新增数据,Merger_On_Read(读时合并表)采用增量日志的方式修改数据,而Copy_On_Write(写实时表)采用了全量更新出一份全新文件方式进行修改功能。
两者对比

3.3、查询数据
最后修改完毕之后,查询对应hive表,修改数据操作代码中将fullname字段的值改成了testName

可以发现ro结尾的读优化视图没有发生变化。查询rt表

rt表的数据发生了变化,实时视图是查询基础数据和日志数据的合并视图。最后查询member2的实时视图

3.4、总结
由此可以理解为MERGE_ON_READ的表,是以增量的形式来记录表的数据,修改操作都以日志的形式保存。而COPY_ON_READ的表是以全量覆盖的方式进行保存数据,每次有修改操作那么会和历史数据重新合并生产一份新的数据文件,并且历史数据不会删除。
两种表视图,HoodieParquetInputFormat格式的只支持查询表的原始数据,HoodieParquetRealtimeInputFormat格式支持查询表和日志的合并视图提供最新的数据。
4、问题
跑hive yarn模式会出现以下错误,

cp hudi-hadoop-mr-bundle-0.6.0-SNAPSHOT.jar /opt/module/hadoop-3.1.3/share/hadoop/common/lib/
将hudi mr的jar包放到hadoop下,再次运行,跑rt读实时视图仍会报错

但是读ro读优化视图就可以了

所以建议采用spark on hive方式,通过spark去读hive表
Hudi(v2.0)
一、Hudi介绍
1、介绍
Hudi将流处理引入大数据, 提供新鲜数据,同时比传统批处理效率高一个数据量级。
2、特性
增加一个特性:通过聚类优化数据集
二、概要
1、File management==>File Layout
Hudi会在DFS分布式文件系统上的basepath基本路径下组织成目录结构。每张对应的表都会成多个分区,这些分区是包含该分区的数据文件的文件夹,与hive的目录结构非常相似。
在每个分区内,文件被组织成文件组,文件id为唯一标识。每个文件组包含多个切片,其中每个切片包含在某个提交/压缩即时时间生成的基本列文件(parquet文件),以及自生成基本文件以来对基本文件的插入/更新的一组日志文件(*.log)。Hudi采用MVCC设计,其中压缩操作会将日志和基本文件合并成新的文件片,清理操作会将未使用/较旧的文件片删除来回收DFS上的空间。
MVCC(Multi-Version Concurrency Control):多版本并行发控制机制
Multi-Versioning:产生多版本的数据内容,使得读写可以不互相阻塞
Concurrency Control:并发控制,使得并行执行的内容能保持串行化结果
2、Index
Hudi通过索引机制将映射的给定的hoodie key(record key+partition path)映射到文件id(唯一标示),从而提供高效的upsert操作。记录键和文件组/文件ID之间的这种映射,一旦记录的第一个版本写入文件就永远不会改变。
3、表类型Table Types&Queries
Hudi表类型定义了如何在DFS上对数据进行索引和布局,以及如何在此类组织上实现上述操作和时间轴活动(即如何写入数据)。同样,查询类型定义了底层数据如何暴露给查询(即如何读取数据)。
| Table Type | Supported Query types |
|---|---|
| Copy on Write (写时复制) | 快照查询+增量查询 |
| Merge on Read (读时合并) | 快照查询+增量查询+读取优化查询(近实时) |
Table Types:
(1)Copy on Write:使用列式存储来存储数据(例如:parquet),通过在写入期间执行同步合并来简单地更新和重现文件
(2)Merge on Read:使用列式存储(parquet)+行式文件(arvo)组合存储数据。更新记录到增量文件中,然后进行同步或异步压缩来生成新版本的列式文件。
下面总结了两种表类型之间的权衡
| 权衡 | CopyOnWrite | MergeOnRead |
|---|---|---|
| 数据延迟 | 高 | 低 |
| 查询延迟 | 低 | 高 |
| Update(I/O) 更新成本 | 高(重写整个Parquet文件) | 低(追加到增量日志) |
| Parquet File Size | 低(更新成本I/O高) | 较大(低更新成本) |
| Write Amplification(WA写入放大) | 大 | 低(取决于压缩策略) |
Query Types:
(1)Snapshot Queries:快照查询,在此视图上的查询将看到某个提交和压缩操作的最新快照。对于merge on read的表,它通过即时合并最新文件切片的基本文件和增量文件来展示近乎实时的数据(几分钟)。对于copy on write的表,它提供了对现有parquet表的直接替代,同时提供了upsert/delete和其他写入功能。
(2)Incremental Queries:增量查询,该视图智能看到从某个提交/压缩写入数据集的新数据。该视图有效地提供了chang stream,来支持增量视图
(3)Read Optimized Queries:读优化视图,在此视图上的查询将查看到给定提交或压缩操作中的最新快照。该视图将最新文件切片的列暴露个查询,并保证与非hudi列式数据集相比,具有相同列式查询功能。
下面总结了两种查询的权衡
| 权衡 | Snapshot | Read Optimized |
|---|---|---|
| 数据延迟 | 低 | 高 |
| 查询延迟 | 高(合并列式基础文件+行式增量日志文件) | 低(原始列式数据) |
4、Copy on Write Table
Copy on Write表中的文件切片仅包含基本/列文件,并且每次提交都会生成新版本的基本文件。换句话说,每次提交操作都会被压缩,以便存储列式数据,因此Write Amplification写入放大非常高(即使只有一个字节的数据被提交修改,我们也需要重写整个列数据文件),而读取数据成本则没有增加,所以这种表适合于做分析工作,读取密集型的操作。

随着数据被写入,对现有文件组的更新会为该文件组生成一个带有提交即时间标记的新切片,而插入分配一个新文件组并写入该文件组第一个切片。这些切片和提交即时时间在上图用同一颜色标识。针对图上右侧sql查询,首先检查时间轴上的最新提交并过滤掉之前的旧数据(根据时间查询最新数据),如上图所示粉色数据在10:10被提交,第一次查询是在10:10之前,所以出现不到粉色数据,第二次查询时间在10:10之后,可以查询到粉色数据(以被提交的数据)。
Copy on Write表从根本上改进表的管理方式
(1)在原有文件上进行自动更新数据,而不是重新刷新整个表/分区
(2)能够只读取修改部分的数据,而不是浪费查询无效数据
(3)严格控制文件大小来保证查询性能(小文件会显著降低查询性能)
5、Merge on Read Table
Merge on Read表是copy on write的超集,它仍然支持通过仅向用户公开最新的文件切片中的基本/列来对表进行查询优化。用户每次对表文件的upsert操作都会以增量日志的形式进行存储,增量日志会对应每个文件最新的ID来帮助用户完成快照查询。因此这种表类型,能够智能平衡读取和写放大(wa),提供近乎实时的数据。这种表最重要的是压缩器,它用来选择将对应增量日志数据压缩到表的基本文件中,来保持查询时的性能(较大的增量日志文件会影响合并时间和查询时间)
下图说明了该表的工作原理,并显示两种查询类型:快照查询和读取优化查询

(1)如上图所示,现在每一分钟提交一次,这种操作是在别的表里(copy on write table)无法做到的
(2)现在有一个增量日志文件,它保存对基本列文件中记录的传入更新(对表的修改),在图中,增量日志文件包含从10:05到10:10的所有数据。基本列文件仍然使用commit来进行版本控制,因此如果只看基本列文件,那么表的表的布局就像copy on write表一样。
(3)定期压缩过程会协调增量日志文件和基本列文件进行合并,并生成新版本的基本列文件,就如图中10:05所发生的情况一样。
(4)查询表的方式有两种,Read Optimized query和Snapshot query,取决于我们选择是要查询性能还是数据新鲜度
(5)如上图所示,Read Optimized query查询不到10:05之后的数据(查询不到增量日志里的数据),而Snapshot query则可以查询到全量数据(基本列数据+行式的增量日志数据)。
(6)压缩触发是解决所有难题的关键,通过实施压缩策略,会快速缩新分区数据,来保证用户使用Read Optimized query可以查询到X分钟内的数据
Merge on Read Table是直接在DFS上启用近实时(near real-time)处理,而不是将数据复制到外部专用系统中。该表还有些次要的好处,例如通过避免数据的同步合并来减少写入放大(WA)
三、基础用例
1、数据删除
Hudi还提供了删除存储在数据中的数据的能力,更重要的是提供了处理大量写入放大(wa)的有效方法,这些通过Merge On Read 表类型基于user_id(任何辅助键)随件删除产生的结果。Hudi可以基于日志提供优雅的并发控制,保证数据的写入和读取可以持续发生,因为后台压缩作业分摊数据的重写和强制删除所需要的成本。
Hudi还解锁了数据聚类等特殊功能,允许用户优化数据布局来进行删除。具体来说,用户可以基于user_id(辅助键)对旧的事件日志数据进行聚类,这样评估数据需要删除的数据就可以快速的定位,对于分区则在时间戳上进行了聚类优化,提高查询性能。
四、并发控制
1、Hudi支持的并发控制
(1)MVCC:Hudi的表操作,如压缩、清理、提交,hudi会利用多版本并发控制来提供多个表操作写入和查询之间的快照隔离。使用MVCC这种模型,Hudi支持并发任意数量的操作作业,并保证不会发生任何冲突。Hudi默认这种模型。
(2)OPTIMISTIC CONCURRENCY:针对写入操作(upsert、insert等)利用乐观并发控制来启用多个写入器将数据写到同一个表中,Hudi支持文件级的乐观一致性,即对于发生在同一个表中的任何2个提交(写入),如果它们没有写入正在更改的重叠文件,则允许两个写入都成功。此功能处于实验阶段,需要用到Zookeeper或HiveMetastore来获取锁。
2、使用并发写
2.1、参数
(1)如果需要开启乐观并发写入,需要设置以下属性
hoodie.write.concurrency.mode=optimistic_concurrency_control hoodie.cleaner.policy.failed.writes=LAZY hoodie.write.lock.provider=<lock-provider-classname>(2)Hudi获取锁的服务提供两种模式使用zookeeper或者HiveMetaStore(选一种即可),相关zookeeper参数
hoodie.write.lock.provider=org.apache.hudi.client.transaction.lock.ZookeeperBasedLockProvider hoodie.write.lock.zookeeper.url hoodie.write.lock.zookeeper.port hoodie.write.lock.zookeeper.lock_key hoodie.write.lock.zookeeper.base_path(3)相关HiveMetastore参数
hoodie.write.lock.provider=org.apache.hudi.hive.HiveMetastoreBasedLockProvider hoodie.write.lock.hivemetastore.database hoodie.write.lock.hivemetastore.table
2.2、使用Spark DataFrame并发写入
(1)编写代码写入数据
package com.atguigu.hudi.test import org.apache.hudi.DataSourceWriteOptions import org.apache.hudi.config.HoodieIndexConfig import org.apache.hudi.hive.MultiPartKeysValueExtractor import org.apache.hudi.index.HoodieIndex import org.apache.spark.SparkConf import org.apache.spark.sql.{ SaveMode, SparkSession} object MultiWriterTest { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setAppName("test_operator").setMaster("local[*]") .set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate() multiWriterTest(sparkSession) } def multiWriterTest(sparkSession: SparkSession) = { import org.apache.spark.sql.functions._ val commitTime = System.currentTimeMillis().toString //生成提交时间 val resultDF = sparkSession.read.json("/user/atguigu/ods/member.log") .withColumn("ts", lit(commitTime)) //添加ts时间戳 .withColumn("hudipartition", concat_ws("/", col("dt"), col("dn"))) //添加分区 两个字段组合分区 Class.forName("org.apache.hive.jdbc.HiveDriver") resultDF.write.format("hudi") .option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY, DataSourceWriteOptions.COW_TABLE_TYPE_OPT_VAL) //选择表的类型 到底是MERGE_ON_READ 还是 COPY_ON_WRITE .option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "uid") //设置主键 .option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "ts") //数据更新时间戳的 .option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "hudipartition") //hudi分区列 .option("hoodie.table.name", "multiwriter_member") //hudi表名 .option(DataSourceWriteOptions.HIVE_URL_OPT_KEY, "jdbc:hive2://hadoop101:10000") //hiveserver2地址 .option(DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY, "default") //设置hudi与hive同步的数据库 .option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY, "multiwriter_member") //设置hudi与hive同步的表名 .option(DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY, "dt,dn") //hive表同步的分区列 .option(DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY, classOf[MultiPartKeysValueExtractor].getName) // 分区提取器 按/ 提取分区 .option(DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY, "true") //设置数据集注册并同步到hive .option(HoodieIndexConfig.BLOOM_INDEX_UPDATE_PARTITION_PATH, "true") //设置当分区变更时,当前数据的分区目录是否变更 .option(HoodieIndexConfig.INDEX_TYPE_PROP, HoodieIndex.IndexType.GLOBAL_BLOOM.name()) //设置索引类型目前有HBASE,INMEMORY,BLOOM,GLOBAL_BLOOM 四种索引 为了保证分区变更后能找到必须设置全局GLOBAL_BLOOM .option("hoodie.insert.shuffle.parallelism", "12") .option("hoodie.upsert.shuffle.parallelism", "12") .option("hoodie.cleaner.policy.failed.writes", "LAZY") .option("hoodie.write.concurrency.mode", "optimistic_concurrency_control") .option("hoodie.write.lock.provider", "org.apache.hudi.client.transaction.lock.ZookeeperBasedLockProvider") .option("hoodie.write.lock.zookeeper.url", "hadoop101,hadoop102,hadoop103") .option("hoodie.write.lock.zookeeper.port", "2181") .option("hoodie.write.lock.zookeeper.lock_key", "test_table") .option("hoodie.write.lock.zookeeper.base_path", "/multiwriter_test") .mode(SaveMode.Append) .save("/user/atguigu/hudi/multiwriter_member") } }(2)用zk客户端,验证是否使用了zk
[[email protected] ~]# /opt/module/apache-zookeeper-3.5.7-bin/bin/zkCli.sh [zk: localhost:2181(CONNECTED) 0] ls /(3)zk下产生了对应的目录,/multiwriter_test下的目录,为代码里指定的lock_key
[zk: localhost:2181(CONNECTED) 4] ls /multiwriter_test
2.3、使用Delta Streamer并发写入
(1)还是拿文档上述的例子,使用Delta Streamer消费kafka种的数据写入到hudi中,这次加上并发写的参数。进入配置文件目录,修改配置文件添加对应参数,提交到Hdfs上
[[email protected] ~]# cd lizunting/ [[email protected] lizunting]# cp kafka-source.properties kafka-multiwriter-source.propertis [[email protected] lizunting]# vim kafka-multiwriter-source.propertis hoodie.cleaner.policy.failed.writes=LAZY hoodie.write.concurrency.mode=optimistic_concurrency_control hoodie.write.lock.provider=org.apache.hudi.client.transaction.lock.ZookeeperBasedLockProvider hoodie.write.lock.zookeeper.url=hadoop101,hadoop102,hadoop103 hoodie.write.lock.zookeeper.port=2181 hoodie.write.lock.zookeeper.lock_key=test_table2 hoodie.write.lock.zookeeper.base_path=/multiwriter_test2 [[email protected] lizunting]# hadoop dfs -put kafka-multiwriter-source.propertis /user/hudi-properties(2)运行Delta Streamer
[[email protected] lizunting]# spark-submit --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer `ls /opt/module/Hudi/packaging/hudi-utilities-bundle/target/hudi-utilities-bundle_2.12-0.8.0.jar` --props hdfs://mycluster/user/hudi-properties/kafka-multiwriter-source.propertis --schemaprovider-class org.apache.hudi.utilities.schema.FilebasedSchemaProvider --source-class org.apache.hudi.utilities.sources.JsonKafkaSource --source-ordering-field userid --target-base-path hdfs://mycluster/user/hudi/multiwriter-test --target-table hudi-multiwriter-test --op INSERT --table-type MERGE_ON_READ(3)查看zk是否产生新的目录
[[email protected] lizunting]# /opt/module/apache-zookeeper-3.5.7-bin/bin/zkCli.sh
五、Flink操作
1、启动flink
(1)hudi(0.8)适用于Flink-11.x版本,scala使用2.12(默认是2.11但上方编译的时候指定了2.12)。Flink官网下载对应版本,并上传进行解压安装客户端。
[[email protected] software]# tar -zxvf flink-1.11.3-bin-scala_2.12.tgz -C /opt/module/
(2)添加hadoop环境变量
[[email protected] module]# cd /opt/module/flink-1.11.3/bin/
[[email protected] bin]# vim config.sh
export HADOOP_COMMON_HOME=/opt/module/hadoop-3.1.3
export HADOOP_HDFS_HOME=/opt/module/hadoop-3.1.3
export HADOOP_YARN_HOME=/opt/module/hadoop-3.1.3
export HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3
export HADOOP_CLASSPATH=`hadoop classpath
(3)启动flink集群
[[email protected] bin]# ./start-cluster.sh
(4)启动flink sql client,并关联编译好的hudi依赖包
[[email protected] bin]# ./sql-client.sh embedded -j /opt/module/Hudi/packaging/hudi-flink-bundle/target/hudi-flink-bundle_2.12-0.8.0.jar
2、Flink Sql Client操作
2.1、插入数据
(1)设置返回结果模式为tableau,让结果直接显示,设置处理模式为批处理
Flink SQL> set execution.result-mode=tableau;
Flink SQL> SET execution.type = batch;
(2)创建一张Merge on Read的表,如果不指定默认为copy on write表
CREATE TABLE t1
( uuid VARCHAR(20),
name VARCHAR(10),
age INT, ts TIMESTAMP(3),
`partition` VARCHAR(20)
)PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://mycluster/flink-hudi/t1',
'table.type' = 'MERGE_ON_READ');
(3)插入数据
INSERT INTO t1 VALUES ('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'), ('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'), ('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'), ('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'), ('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'), ('id6','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'), ('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'), ('id8','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4');
(4)查看flink ui提示成功,查看对应9870页面,hdfs路径下已有数据产生


(5)查询表数据
Flink SQL> select *from t1;

2.2、修改数据
(1)flink sql操作hudi时很多参数不像spark需要一一设置,但是都有default默认值,比如文档上方建了t1表,插入数据时没有像spark一样指定唯一键,但是不代表flink的表就没有。参照官网参数可以看到flink表中唯一键的默认值为uuid.

(2)所以t1表的主键其实已经指定好为uuid,那么sql语句则可进行修改操作
Flink SQL> insert into t1 values ('id1','Danny',27,TIMESTAMP '1970-01-01 00:00:01','par1');
(3)修改uuid为id1的数据,将原来年龄23岁改为27岁,flink sql除非第一次建表插入数据模式为overwrite,后续操作都是默认为append模式,可以直接触发修改操作。修改完毕后进行查询
Flink SQL> select *from t1;

2.3、流式查询(有bug)
(1)hudi还提供flink sql流式查询,需要定义一个开始时间,那么该时间戳以后数据更改都会进行实时的更新。再建一张t2表指定相应参数,指定开始提交时间为2021年8月9号13点42分整开始,指定表每次检查提交间隔时间为4秒,默认1分钟。
CREATE TABLE t2(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://mycluster/flink-hudi/t2',
'table.type' = 'MERGE_ON_READ',
'read.streaming.enabled' = 'true',
'read.streaming.start-commit' = '20210809134200' ,
'read.streaming.check-interval' = '4'
);
(2)设置执行模式为流,进行查询
Flink SQL> SET execution.type=streaming;
Flink SQL> select *from t2;

(3)发生报错,经过查询发现网上其他人也有这个问题,需要换成flink1.12+master0.9才能解决。
(4)所以此版本(0.8)还是不推荐使用flink操作Hudi
边栏推荐
- Hardcore!The internal manual "MySQL Notes" written by the technical director of Ali is really strong
- What is amazon measurement system, how cross-border sellers by myself have no quickly out of the list?
- 62:第五章:开发admin管理服务:15:开发【新增/修改友情链接,接口】的修改功能;(其实在60篇博客中,已经开发好了)(核心是:理解MongoDB,修改数据的逻辑)
- 文件操作之文件下载读取
- 阿里二面:接口流量突增,如何做好性能调优?
- 【selenium4自动化工具的使用以及Junit5单元测试框架】
- 获取一般椭圆外接矩形
- tensorflow-gpu 2.6.0版本安装教程
- Linear regression and logistic regression (logistic regression and linear regression)
- UniPro升级甘特图 推进项目进度可视化
猜你喜欢

Ali's second side: How to perform performance tuning with sudden increase in interface traffic?
阿里二面:接口流量突增,如何做好性能调优?

63:第五章:开发admin管理服务:16:开发【删除友情链接,接口】;(核心是:理解MongoDB,删除数据的逻辑)

How do Meikeduo and Shopee evaluate self-supporting accounts?

索引的设计原则

为什么Video Speed Manager 和 Video Speed Controller 的chrome插件对有些B站视频不能调速

JDY-16 蓝牙4.2模块串口测试方法

农村孩子高压线。。。

PyTorch framework builds flower image classification model (Resnet network, transfer learning)

Open3D Airborne Point Cloud Powerline Extraction
随机推荐
Ali's second side: How to perform performance tuning with sudden increase in interface traffic?
音视频实时渲染流程操作复杂吗,如何实现?
What is the difference between Apifox and Apipost?That has more advantages (interface tools) postman, jmeter, etc.,,,
Introduction to Mail Services POP3, SMTP and IMAP
PromQL query monitoring data
微信H5页面禁止分享朋友和复制链接
搭建ExtMail邮件服务器
星起航:跨境电商试综区为广大卖家提供更多的市场发展机遇
ceph-ansible5.0部署文档
怎么理解数据网格(Data Mesh)
golang工厂模式极简示例
Uncaught ReferenceError: Cannot access ‘f1‘ before initialization
OS模块中获取当前文件的绝对路径的相关方法
A question that most people get wrong: If I want to store IP addresses, what data type is better?
【Scientific Reports】《多中心影像诊断的联邦学习:心血管疾病的模拟研究》
遵循3GPP标准,爱浦路的卫星仿真平台已实现8大功能!
这个数据太骚!搞得我都激动了。
一分钟看懂TCP粘包拆包
[LeetCode]1403. 非递增顺序的最小子序列
Secrets are stored in etcd without encryption by default