当前位置:网站首页>Two minutes recording can pass by second language!The volcano how to practice and become voice tone reproduction technology?
Two minutes recording can pass by second language!The volcano how to practice and become voice tone reproduction technology?
2022-08-09 13:02:00 【QbitAl】
Let's enjoy an audio and video first, maybe you will have a surprise discovery?
Yes, that's how the voice-over imitator of Anime Sponge looks.
The difference is that the protagonist of the American comedy animation, who is about to run for four years, is now changing the single language and fixed style of the past under the interpretation of the imitator, and he says it all at once.There are translation accents, TVB accents, Cantonese and even Shanghai dialects.
More importantly, all styles and languages are based on a two-minute pure Chinese audio training.
How much can a two-minute audio file contain?
According to the estimation of professionals in voice direction, it is basically equivalent to the content of 20 sentences spoken at a normal speech rate.
In this way, the "magic voice" can not only retain the sound of the deity, but also realize the seamless switching of multi-style and multi-language. It is also thanks to the "sound" developed by the volcano voice"Black Technology", that is, the sound reproduction technology.
For a long time, Volcano Voice has provided global high-quality voice AI technology capabilities and excellent full-stack voice product solutions for ByteDance's internal business lines and Volcano Engine ToB industries and innovative scenarios.Program.
The "timbre reproduction technology" launched this time can be simply understood as "timbre clone", which is a fully automatic, efficient and lightweight sound customization solution.
Less data, low cost, convenient and efficient
Different from the high threshold requirements for data in the model training process of traditional speech synthesis technology, Volcano Voice timbre reproduction technology requires only a large amount of data0.3% of the traditional method, and the requirements for timbre acquisition are also simpler——
There is no need for a professional announcer to record in a recording studio for a long time. Ordinary people can record in a relatively quiet open environment for more than 2 minutes to achieve the standard of sound space modeling and generate exclusive sound.The AI model is convenient and efficient.
Multi-style, multi-language, stable and high-quality
In addition, the self-developed Imitator model structure of Volcano Voice can also extract speaker-independent hidden layer speech representation (SI Context Feature) from audio, such as moreRhythm and accent information, etc., and use this as the intermediate feature of text and audio for auxiliary model training, so that timbre restoration is more accurate.
It is understood that in the pre-training stage, the team also used a multi-style, multi-language, multi-speaker voice database for average model training, which can be understood as a very small amount of recording data.With the support, transfer learning is used to adaptively create a speech synthesis model with a high degree of timbre restoration, so that the synthesized timbre can be outstanding in pronunciation rhythm and similarity.
There is no need for any audio or text annotations during the sound reproduction process, which not only saves labor costs, but also reduces the system complexity of the practical operation.
In addition, the technology of streaming synthesis can make the delay of the first packet of sound reproduction less than 500ms, which is suitable for most personalized voice scenarios.
On the whole, it not only realizes the decoupling of timbre, style and language, but also reaches the industry-leading level in pronunciation stability and sound quality.
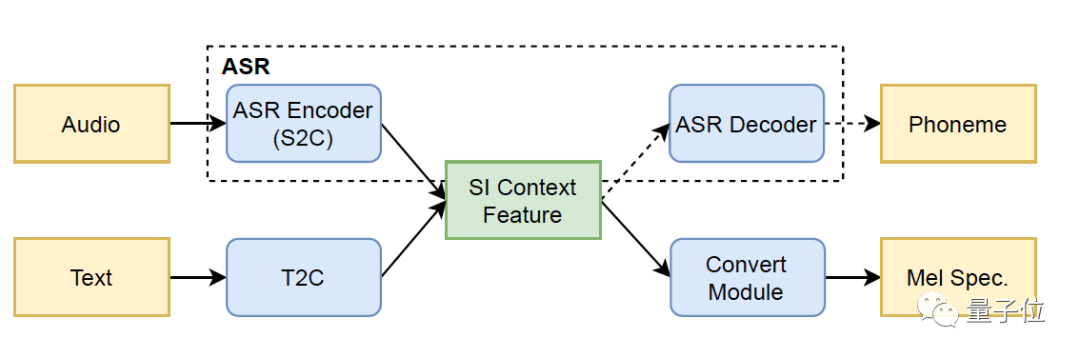
Full-link automation, ready to use
This technical solution will provide external enterprise-level services through Volcano Engine, relying on Volcano Voice's high-quality sound reproduction SDK support, its convenient text reading and recording functions, andThe built-in environment detection and word accuracy detection can maximize the quality of audio input.
At the same time, the back-end has an automated model loading function, and without restarting the service, the corresponding sound can be hot loaded, realizing the whole chain of audio recording to sound experience.Closed-loop, that is to say, only one set of SDK can be used to complete the use of all resources. Currently, the online SDK already supports Chinese Mandarin and English.
The application of this technology strictly follows compliance requirements. The Volcano Voice team said:
We attach great importance to the protection of users' personal information rights and interests. We have obtained full authorization for sound collection and training to ensure the legality of the sound reproduction process and the compliance of sound use., and then applied to enterprise service scenarios.
It is worth mentioning that this technology has core patents.

In short, if you want to make personalized audio, you only need to record 2-10 minutes at a time and train for 10-20 minutes. After entering the text, select the desired style and language, you can quicklyIt is synthesized and applied in multiple enterprise-level service scenarios such as news broadcasts and intelligent customer service.
Now the speech recognition and speech synthesis technology capabilities of Volcano Voice have been successfully applied to many products such as Douyin, Jianying, Tomato Novels, etc., and are open to the outside world through Volcano Engineenterprise.
*This article is published with permission from qubits, and the opinions belong to the author.
— End—
QubitQbitAI
վ'ᴗ' ի Track new developments in AI technology and products
Three clicks of "Share", "Like" and "Watching"
Technology cutting-edge progress will meet every day ~
边栏推荐
猜你喜欢

1小时直播招募令:行业大咖干货分享,企业报名开启丨量子位·视点

又有大厂员工连续加班倒下/ 百度搜狗取消快照/ 马斯克生父不为他骄傲...今日更多新鲜事在此...
Programmer's Exclusive Romance - Use 3D Engine to Realize Fireworks in 5 Minutes
【小程序】低代码+小游戏=小游戏可视化开发

2022 Niu Ke Duo School (6) M. Z-Game on grid

鹅厂机器狗花式穿越10m梅花桩:前空翻、单桩跳、起身作揖...全程不打一个趔趄...
HAproxy:负载均衡
人体解析(Human Parse)开源数据集整理
LeetCode #101. Symmetric Binary Tree
ABP 6.0.0-rc.1的新特性
随机推荐
基于CAP组件实现补偿事务与幂等性保障
GRPC整体学习
Web console control edit box
阿里云新增三大高性能计算解决方案,助力生命科学行业快速发展
WPF implements a MessageBox message prompt box with a mask
程序员的专属浪漫——用3D Engine 5分钟实现烟花绽放效果
标准C语言学习总结14
GET请求和POST请求区别
TIC2000调用API函数Flash擦除片上FLASH失败
HAproxy: load balancing
智驾科技完成C1轮融资,此前2轮已融4.5亿元
API调用,API传参,面向对接开发,你真的会写接口文档吗?
听声辨物,这是AI视觉该干的???|ECCV 2022
《数字经济全景白皮书》银行业智能营销应用专题分析 发布
00后写个暑假作业,被监控成这笔样
Double pointer - the role of char **, int **
Fapi_StatusType Fapi_issueProgrammingCommand使用注意事项
在北京参加UI设计培训到底怎么样?
MySQL查询性能优化七种武器之索引潜水
HAproxy:负载均衡