当前位置:网站首页>原文翻译:Structure Aware Single-stage 3D Object Detection from Point Cloud
原文翻译:Structure Aware Single-stage 3D Object Detection from Point Cloud
2022-08-09 02:35:00 【lp_oreo】
0. Abstract
基于点云的3D目标检测在自动驾驶任务中扮演者至关重要的角色。当前单阶段的3D检测器使用全卷积的方式,逐步对3D点云进行下采样提取特征。然而,经过下采样之后的特征不可避免的丢失空间信息,未能充分利用3D点云的结构信息。在本次任务中,我们提出了一种可以利用3D点云的结构信息从而提高定位精度的单阶段检测器。具体而言,我们设计了一个辅助网络,能够将骨干网络提取的卷积特征转换成点云的点级表征。这个辅助网络使用两个点级级别的监督方法对检测网络进行联合优化,使其能够指导骨干网络中的卷积特征感知到物体的结构特征(物体轮廓边界和中心点位置),从而增加定位精度。经过训练之后,这个辅助网络可以去掉,因此在推理阶段并不会增加额外的时间损耗。此外,考虑到单阶段检测器的预测边界框及其类别之间存在不匹配的问题,我们提出了一个高效的part-sensitive warping操作,将预测的边界框及其置信度进行匹配。我们所提出的检测器在KITTI 3D/BEV检测榜上排名第一,并且在推理时还有25个FPS。
从摘要中看出(1)为了解决现有检测器经过下采样之后结构信息丢失的问题,使用一个辅助网络来学习点级结构特征,而且在推理阶段将这个辅助特征去掉,因而并不会增加推理时间损耗。(2)为了能够将置信度和边界框进行匹配,提出了part-sensitive warping操作,防止在NMS的时候丢掉某些定位较好的边界框。
1. Introduction
基于点云的3D目标检测是自动驾驶系统中的核心问题。2D目标检测只需要从图像中预测出二维的边界框,而自动驾驶需要从现实世界中预测出包含更多信息的3D边界框,来实现类似路径规划和碰撞规避等高级任务。这些任务驱动基于卷积神经网络的3D目标检测方法处理来自高端的LiDAR传感器的更具表征性的点云数据。

当前基于点云的3D目标检测方法可以分为两类:一阶段检测方法和二阶段检测方法。一阶段检测方法思想是将稀疏的点云数据转成复杂的数据表征,比如体素栅格特征和鸟瞰图(birds-eye-view, BEV)特征,然后使用全卷积神经网络直接预测边界框,这使得一阶段的检测器简单并且高效。然而,持续地对特征图进行下采样不可避免的会损失点云数据的结构信息,使得一阶段的检测器的检测精度不高。如图1所示,当目标物体所包含点的数量较少时,单阶段检测器就不会获得较高的定位精度。
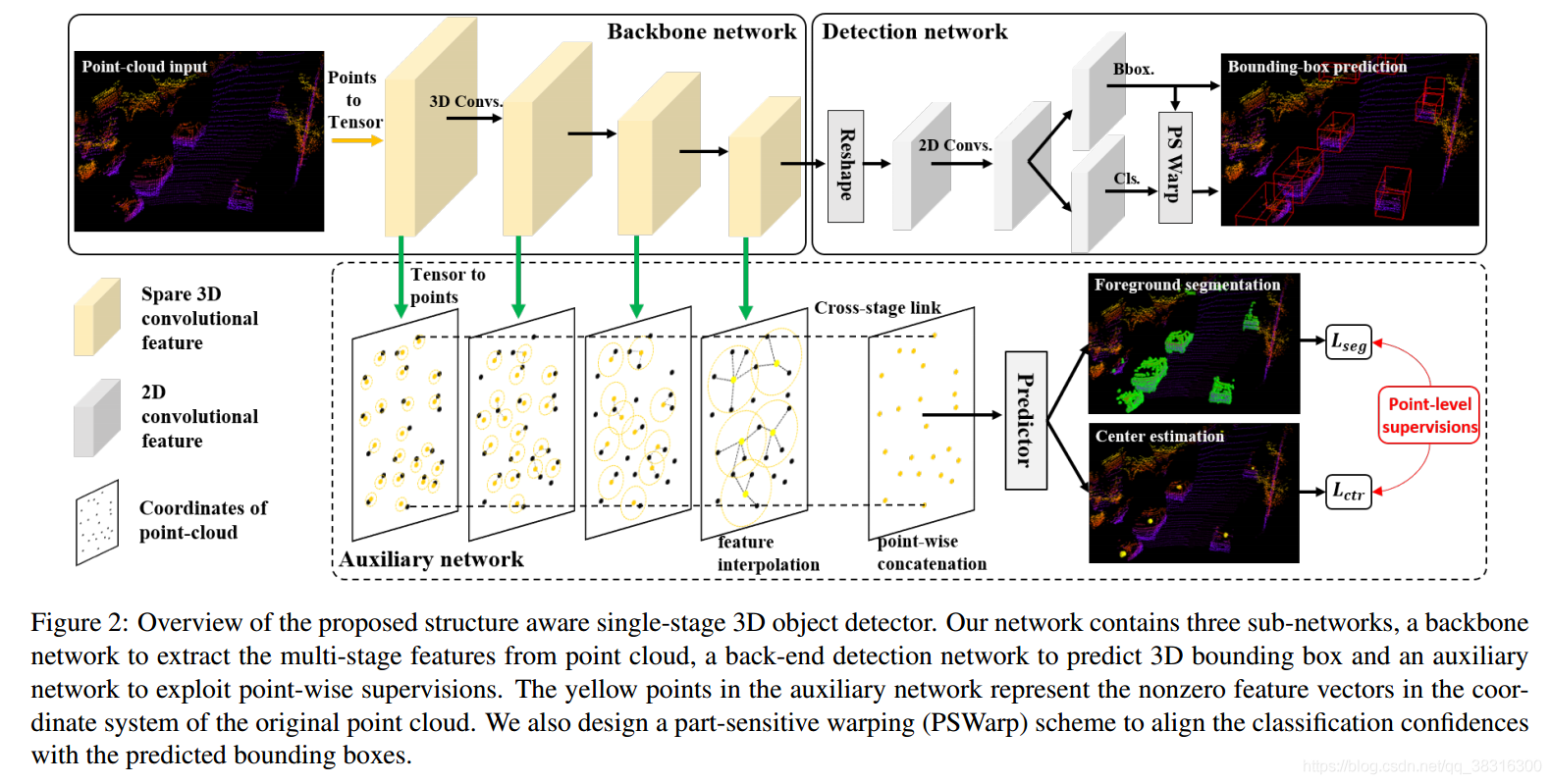
与一阶段检测方法相比,二阶段检测方法在检测的第二阶段可以利用更加精细的空间信息,它可以在第一阶段所预测出的感兴趣区域(regions of interest, RoIs)中再进行有针对性的处理,从而再预测出更加精确的边界框。这揭露了利用点云数据中更加精细的空间特征来实现较高定位精度的重要性。然后对每个点都进行处理并且对每个RoI都需要再次进行特征提取,这显然增加了计算资源损耗,使得二阶段检测方法很难实现实时推理。
受二阶段检测方法的较高精测精度的启发,在本篇论文中,我们旨在利用细粒度的结构信息来提高定位精度并且能够保持单阶段检测器检测速度的高效性。因此,我们设计了一个结构感知的单阶段3D检测器,其结构框图如图2所示。该检测器除了能够生成进行边界框预测的下采样特征图之外,还包括一个辅助网络,它能够利用点级级别的监督方法指导骨干网络去学习更具有区分性的特征(物体轮廓边界和中心点位置)。具体而言,这个辅助网络先将骨干网络所生成的特征转成点级表征信息,然后该辅助网络分配两个辅助任务:前景分割任务和点中心估计任务。前者让特征对物体的边界更加敏感、后者让特征学习到物体内部之间的关系。在训练阶段,这个辅助网络和骨干网络一起进行优化;在推理阶段会移除辅助网络而仅仅保留骨干网络,使检测网络并不会增加额外的时间损耗。如图1(b)所示,辅助任务预测的边界框的定位精度更高。
此外,我们观察到一阶段检测经常出现预测边界框与其相关的分类置信度不匹配的问题。具体而言,分类的置信度与其所使用的相关特征在整个特征图中的位置有关,然而预测的边界框经常会偏离它们当前的位置(就是说分类特征图与定位特征图会出现对应位置的信息不匹配的现象)。这些不匹配的问题使得非极大值抑制(NMS)等后处理算法的结果并不是最优的。受PSRoIAlign算法的启发,我们提出了一个高效的part-sensitive warping方法(在图2中我们将其记作为PSWarp),在分类特征图上使用空间变换,将物体分类的置信度与其预测的边界框进行匹配,使得我们的模型产生更可靠的置信度。总而言之,我们主要的创新点有两点:
(1)我们提出了一个结构感知的一阶段3D目标检测器,它利用可拆卸的辅助网络来学习结构信息,给骨干网络提供定位精度的同时并不会增加额外的推理损耗。
(2)我们提出了一个高效的特征图变换方法来消除预测的边界框与其相关的分类置信度的不一致性,用近乎可忽略的计算成本来提高检测性能。
在KITTI的3D和BEV目标检测基准进行评估,而我们的检测方法优于之前所有已公布方法的性能,并且还能够得到25FPS的推理速度。
2. Related Work
一阶段检测方法:一阶段检测方法使用可以进行复杂数据表征变换的全卷积神经网络处理点云数据。这一类算法的典型方法是在鸟瞰图和前视图上使用2D卷积神经网络进行特征提取,或者是从体素栅格上使用3D卷积神经网络进行特征提取。VoxelNet对每个体素特征都使用PointNet方法,从而进行特征学习。PointPillars将特征沿着物体高度坐标轴进行堆叠得到“Pillar”从而实现降维。SECOND研究并改进了稀疏卷积,然后使用GPU优化3D卷积的处理速度。我们所提出的算法建立在通用单阶段结构的基础上,并且我们是首次提出使用点级监督的方法来提高卷积特征的表征能力的。
二阶段检测方法:和一阶段检测算法直接预测3D边界框不同,二阶段检测算法旨在在第二阶段复用全分辨率的点云数据来产生更加精确的预测。一些图像驱动的算法首先从图像中得到一系列的3D感兴趣区域,然后再使用PointNet算法来提取感兴趣区域的特征。PointRCNN使用PointNet方法从场景中将前景进行分割,然后再从点云数据中生成感兴趣区域。它的变体工作Fast Point RCNN使用高效的基于体素的卷积神经网络来生成感兴趣区域。STD算法将感兴趣区域分成体素信息,从而能够使用常规的卷积神经网络对感兴趣区域进行特征提取。二阶段检测算法的成功启发我们利用从ground truth编码得到的全分辨率空间信息,指导一阶段检测模型去学习更富有区分性的精细特征。
辅助任务学习:在自动驾驶应用中,重新研究了从一组辅助任务中学习来提高主要任务性能的工作。HdNet提出通过预测地面高度信息来提高检测器的道路集合感知能力。Liang(Multi-task multi-sensor fusion for 3d object detection)提出从多任务预测中提高多模态输入融合效果。我们的方法和它们的很相似,都是通过利用点级的预测任务来提高3D目标检测性能,但是与他们不同,我们只是将其作为辅助方法,在推理阶段并不使用辅助网络。辅助任务可能和主要任务有所不同,在优化过程中可以提供多重的正则化效果。举例来说,Zhao(Leveraging heterogenrous auxiliary tasks to assist crowd counting)利用人群分割任务辅助人群计数任务,进而来学习更精细的稠密特征图。Mordan(Deep hough voting for 3d object detection in point clouds)利用深度估计任务来学习场景感知特征,提高了其对检测密集物体的鲁棒性。通过利用辅助任务的优势,我们可以在推理阶段保证一阶段检测网络的有效性。
3. Structure-Aware 3D Object Detection via Auxiliary Network Learning
在本节中,我们提出了一个基于点云的高效结构感知的单阶段检测网络。3.1小节介绍了骨干网络和检测模型;3.2小节中介绍了辅助网络,其通过两个特殊的辅助任务来丰富骨干网络的隐层特征;3.3小节介绍了使用part-sensitive warping操作来生成更加精确的置信度特征图;3.4小节介绍了训练阶段的损失函数。
3.1 Backbone and detection networks
Input data representation. 之前的方法通常将点云划分到体素栅格中,从而将其解码成3D稀疏张量(比如VoxelNet就是这样做的),每一个体素都视为输入张量的非零特征(实际上体素中还是存在大量的零特征),但是点云体素化是一个非常耗时的操作。简单起见,通过将点云的坐标量化为张量的索引,我们可以直接将每个点视为输入向量的非零值。设点云的坐标值为 且输入张量的步长
且输入张量的步长![d = \left [ d_{x},d_{y},d_{z} \right ] \in \mathbb{R}^{3}](http://img.inotgo.com/imagesLocal/202208/09/202208090234477948_20.gif) 。因此,张量的索引就可以表示成
。因此,张量的索引就可以表示成 ,其中
,其中 表示floor函数。我们遍历每个点,然后根据相应的索引将每个点分配到输入张量中。如果多个点共享相同的索引,我们就用最新的点来覆盖之前的值。我们发现这个预处理方法非常高效并且当步长
表示floor函数。我们遍历每个点,然后根据相应的索引将每个点分配到输入张量中。如果多个点共享相同的索引,我们就用最新的点来覆盖之前的值。我们发现这个预处理方法非常高效并且当步长 的时候能够获得较好的检测精度(个人理解这个d其实就是采样步长)。
的时候能够获得较好的检测精度(个人理解这个d其实就是采样步长)。
Network architecture. 如图2所示,我们将通用的骨干网络作为我们的特征提取器。这个检测网络包含四个卷积模块,每一个卷积模块都由卷积核为3的子流型卷积构成,而最后的三个卷积模块中都包含一个步长为2的额外的稀疏卷积。每一个卷积后都包含一个BN(Batch Normalization)层和ReLU非线性激活函数。因此,这个骨干网络会生成不同分辨率的多阶段特征图。通过将特征向量沿着深度信息的维度堆叠成一个通道,这个检测网络将骨干网络的输出特征图的形状变成鸟瞰图的表征形状(就是图2中backbone network的特征图与detection network的特征图改变的过程)。然后,使用六个标准的3*3卷积进一步进行特征提取,使用两个1*1卷积用于生成特定任务的像素级别的预测:分类任务和定位定位。
3.2 Detachable auxiliary network
如第一部分所示,我们提出了一个可以进行点级级别监督的可拆卸的辅助网络,它可以帮助骨干网络提取的特征理解三维点云的结构信息。

Motivation. 通常来说,对点云数据进行卷积操作所得到的下采样特征,不可避免的会损失结构特征细节,而这些损失的结构特征对产生一个准确的定位至关重要。图3表示一个从二维点集中进行物体检测的典型案例(绿色点、黑色点和白色边界框分别表示前景图、背景图以及标注的边界框)。如图3(a)所示,该特征图中非零的特征向量的个数较少,并且某些背景点距离目标物体的边界也非常近。这种情况在日常生活中随处可见,比如当目标物体离我们距离较远并且和其他不重要的物体相互遮挡的时候。卷积神经网络持续不断的降低点云的空间分辨率,一些物体也可能会融入到背景点中,导致在低分辨率特征空间中,这些点会被错误地分类,就如图3(b)所示。此时这个模型就会被误导,从而产生低质量的边界框。我们的解决方案就是构建一个点级级别监督的辅助网络来指导骨干网络中不同网络层的特征图去学习点云的高精度结构信息。为了实现这个目标,我们首先需要将由卷积神经网络所提取的特征转成点级表征数据。
Point-wise feature representation. 辅助网络架构如图2所示,根据当前阶段的量化步长,它将骨干网络特征中的非零索引转成现实世界下的坐标,因此每个骨干网络的特征都可以表示成点的形式。我们将其记做为 ,其中f表示特征向量,p表示点的坐标。为了生成全分辨率的点级特征,我们在每个网络层中使用特征传播层(PointNet++中的),以在原始坐标的点云坐标
,其中f表示特征向量,p表示点的坐标。为了生成全分辨率的点级特征,我们在每个网络层中使用特征传播层(PointNet++中的),以在原始坐标的点云坐标 处对骨干网络的特征进行插值。对于插值,我们使用一个领域内所有点的之间距离的倒数作为加权平均值。假设
处对骨干网络的特征进行插值。对于插值,我们使用一个领域内所有点的之间距离的倒数作为加权平均值。假设 是加权特征,每个点的特征向量可以由下面公式计算得到:
是加权特征,每个点的特征向量可以由下面公式计算得到:

 表示一个球形区域,每个网络层中球形的半径分别是0.05m,0.1m,0.2m和0.4m。我们使用夸网络层的连接将这些点级特征进行级联堆叠,然后使用一个浅层的预测器来生成特定任务的输出。这个预测期使用共享的神经元尺寸为(64,64,64)的多层感知机实现,两个特定任务的输出使用逐点的卷积操作得到。
表示一个球形区域,每个网络层中球形的半径分别是0.05m,0.1m,0.2m和0.4m。我们使用夸网络层的连接将这些点级特征进行级联堆叠,然后使用一个浅层的预测器来生成特定任务的输出。这个预测期使用共享的神经元尺寸为(64,64,64)的多层感知机实现,两个特定任务的输出使用逐点的卷积操作得到。
Auxiliary tasks. 我们首先介绍了一个逐点的前景分割任务来指导卷积神经网络的骨干网络学习目标物体边界的差异性特征(也就是前景和背景的边界)。具体而言,我们在分割任务分支中使用一个sigmoid函数来预测每个点是前景还是背景的可能性,记做为 ,是一个二值标签来表示一个点是否落在ground truth的边界框中。这个前景分割任务可以使用focal loss来进行优化:
,是一个二值标签来表示一个点是否落在ground truth的边界框中。这个前景分割任务可以使用focal loss来进行优化:

其中 和
和 都是超参数,我们根据经验值将其设置为和原论文中一样的值,其分别为0.25和2。如图3(c)所示,上面的语义分割任务可以让骨干网络更精确地检测物体的边界框。有个更准确的特征图,这个模型就能够生成更加准确的边界框。然而,尽管前景和背景之间的边界点可以准确地检测出来,但是检测模型仍然不能够准确预测出边界框的缩放尺度和形状,这是因为特征图的点非常的稀疏。为了进一步提高定位误差,我们使用另一个辅助任务来学习每个物体的点相对于物体中心的位置。如图3(d)所示,这些物体内部关系可以帮助检测模型更好地预测缩放尺度和物体形状,从而得到更加准确的定位精度。
都是超参数,我们根据经验值将其设置为和原论文中一样的值,其分别为0.25和2。如图3(c)所示,上面的语义分割任务可以让骨干网络更精确地检测物体的边界框。有个更准确的特征图,这个模型就能够生成更加准确的边界框。然而,尽管前景和背景之间的边界点可以准确地检测出来,但是检测模型仍然不能够准确预测出边界框的缩放尺度和形状,这是因为特征图的点非常的稀疏。为了进一步提高定位误差,我们使用另一个辅助任务来学习每个物体的点相对于物体中心的位置。如图3(d)所示,这些物体内部关系可以帮助检测模型更好地预测缩放尺度和物体形状,从而得到更加准确的定位精度。
设 是预测中心点分支的输出,
是预测中心点分支的输出, 是该物体点相对于其中心店的偏移量。这个中心点预测任务可以使用下面的
是该物体点相对于其中心店的偏移量。这个中心点预测任务可以使用下面的 函数进行优化:
函数进行优化:

其中 表示前景物体点的个数,
表示前景物体点的个数,![1[\cdot ]](http://img.inotgo.com/imagesLocal/202208/09/202208090234477948_2.gif) 表示索引函数。
表示索引函数。
组合使用前景分割任务和中心点预测任务能够使得骨干网络学习结构感知特征。在4.4部分所示,当配置了这两个复制任务之后,可以极大地提高骨干网络的定位精度。此外,这个辅助网络只在训练阶段使用,因此并不会在推理阶段增加额外的计算损耗。
3.3 Part-sensitive warping
为了解决预测的边界框及其相应的置信度特征图出现不匹配的问题,我们提出了part-sensitive warping操作,即PSWarp作为PSRoIAlign算法的变体,通过在特征图上使用空间变换操作来将分类的置信度和预测框进行对齐。

和PSRoIAlign算法类似,我们使用修改最后分类层来生成K个part-sensitive分类特征图,记做为 ,每一个都会对一个确定物体的部分进行编码,举例而言,当K=4的时候,结果为
,每一个都会对一个确定物体的部分进行编码,举例而言,当K=4的时候,结果为 。与此同时,我们将每个特征图位置下的预测边界框分成K个子窗口,然后选择每个子窗口的中心点进行采样。此时,我们可以生成K个采样栅格
。与此同时,我们将每个特征图位置下的预测边界框分成K个子窗口,然后选择每个子窗口的中心点进行采样。此时,我们可以生成K个采样栅格 ,并且每一个栅格都有相关的分类特征图。如图4所示,我们的PSWarp操作由特征图采样器组成,该采样器将分类特征图和采样栅格作为输入值,然后将输入值所对应的栅格点的采样值进行输出,最终的置信度特征图C由K个经过采样的分类特征图取平均得到。假设一个预测的边界框p和它相应的采样点
,并且每一个栅格都有相关的分类特征图。如图4所示,我们的PSWarp操作由特征图采样器组成,该采样器将分类特征图和采样栅格作为输入值,然后将输入值所对应的栅格点的采样值进行输出,最终的置信度特征图C由K个经过采样的分类特征图取平均得到。假设一个预测的边界框p和它相应的采样点 ,最终边界框的置信度可以由下面计算得到:
,最终边界框的置信度可以由下面计算得到:
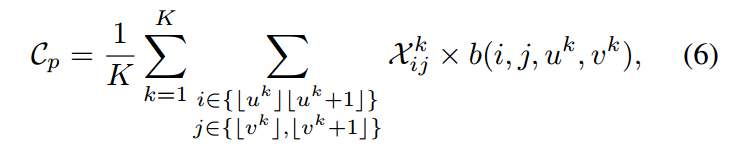
其中b是双边采样核心,它的形式为。和PSRoIAlign和其他基于RoI的方法相比,PSWarp算法那更加高效,因为它并不需要从稠密的特征图中使用非极大值抑制得到感兴趣区域。它只需要考虑每个子窗口的一个像素点,因此该算法和标准的卷积操作的计算复杂度一样。
3.4 Loss functions
我们使用常规的基于锚框设置的参数来优化我们原始的网络。设 和
和 分别为回归分支和分类分支的损失函数。是损失函数,是focal损失函数。我们使用梯度下降方法同时优化检测任务和辅助任务,来最小化下面的损失函数:
分别为回归分支和分类分支的损失函数。是损失函数,是focal损失函数。我们使用梯度下降方法同时优化检测任务和辅助任务,来最小化下面的损失函数:

其中 根据经验值设置为2,
根据经验值设置为2, 和
和 是用来平衡辅助任务和检测任务的超参数。我们将在4.2部分进行实验来选择这两个超参数合适的值。
是用来平衡辅助任务和检测任务的超参数。我们将在4.2部分进行实验来选择这两个超参数合适的值。
4. Experiments
我们在KITTI的3D/BEV目标检测基准上评估结构感知的一阶段检测器(structure-aware single-stage detector, SA-SSD)。该数据集包含7481张训练集图像和7518张测试集图像。我们进一步将训练集图像划分成3712张的训练集图像和3769张的验证集图像。我们在最常用的car类别上进行测试,然后使用阈值为0.7平均精度(Average precision, AP)作为评估矩阵。这个基准基于物体的尺寸、遮挡程度和截断程度分为三种级别:简单,中等和困难。AP使用40个召回率位置点进行计算。开源代码在这:https://github.com/skyhehe123/SA-SSD。
4.1 Implementation details
Training details. 我们分别选择沿着X,Y,Z的(0m, 70.4m),(-40m, 40m),(-3m,1m)范围内的LiDAR点云进行常规设置,然后去掉那些在图像视野中看不到的点。在训练过程中,我们分别设置正样本和负样本锚框的匹配阈值为0.6和0.45。边界框和锚框的匹配交并比由它们在鸟瞰图中最近的水平举行计算得到。检测car类别的锚框的尺寸为:宽度为1.6米,长度为3.9米,高度为1.56米,忽略那些不包含点的锚框。检测网络使用随机梯度下降法训练50个epochs,batch size、学习率和权值衰减率分别为2,0.01和0.001,并使用余弦退火策略改变学习率。在推理阶段,我们过滤掉那些置信度小于0.3的边界框,非极大值抑制的交并比设置为0.1。
Data augmentation. 我们采用常规的复制-粘贴的数据増广方法。具体而言,我们收集得到所有的ground-truth边界框及其落在这些边界框中的点作为实例池。对于每个样本没我们随机从样例池中选择10个实例,然后将其放置到当前的点云中。每一次防止都要进行碰撞检测来避免违反物理原则,所有的ground-truth边界框都会独立的进行増广,每一个边界框都会随机的旋转。噪声的旋转的角度在![\left [ -\pi/15, \pi/15 \right ]](http://img.inotgo.com/imagesLocal/202208/09/202208090234477948_26.gif) 之间,,且服从
之间,,且服从 分布。此外,我们对整个点云进行随机翻转、全局旋转和全局缩放操作,全局旋转角度也在之间,并且缩放尺度在
分布。此外,我们对整个点云进行随机翻转、全局旋转和全局缩放操作,全局旋转角度也在之间,并且缩放尺度在![\left [ 0.95, 1.05 \right ]](http://img.inotgo.com/imagesLocal/202208/09/202208090234477948_33.gif) 之间。
之间。

4.2 Weight selection of auxiliary tasks
公式7中和的权重影响主工作中每个辅助工作的性能,它是我们工作中的主要超参数。为了寻找到它们最优的值,我们首先将置零,然后微调的值,确定的值之后再寻找最佳的。如图5所示,当前景分割任务的权重在一定的范围之间的时候,检测性能够有着明显的提升。太小的权重对主要工作并没有什么影响,而太大的权重会弱化主要工作的性能,我们使用相同的策略来观察对检测精度的影响。在接下来的实验中,超参数确定为 。
。

4.3 Comparison with state-of-the arts
我们将基于点云的SA-SSD检测器和其他顶级的检测方法进行对比,结果如表1所示,我们的方法在3D和BEV检测任务重都获得了最好的检测性能。截止到提交的时间,我们的方法在3D/BEV目标检测排行榜的car类别中排名第一。此外,我们的方法比排名第二的STD算法的速度快2.5倍左右。在BEV的中等难度的的检测中我们比STD方法的AP值要高1.8左右。在一阶段的检测器中,我们的方法比其他方法的检测精度要高很多。具体而言,我们的模型比PointPillars在3D检测任务中要高(6.2%, 5.5%, 5.2%)、在BEV检测任务重要高(5.0%,4.5%,3.1%),我们的检测网络建立在SECOND模型之上,但是也获得了(5.4%,7.2%,8.3%)的性能提升。性能提升的主要源于辅助任务的丰富的隐藏信息。因为一阶段的检测架构和无体素的预处理方法,SA-SSD模型的推理速度可达25FPS,这要优于大部分的检测方法。

图6显示了在不同召回率的情况下,我们的方法和其他先进方法的性能比较。在图7中我们展示了某些预测结果,并且为了更好的进行可视化,我们将从LiDAR预测得到的3D边界框投影到RGB图像上。显而易见,在不同的场景下,我们的方法可以得到好质量的3D边界框。

4.4 Ablation study
在本节中,我们对模型中不同模块的性能进行了综合的分析。我们首先在验证集上对模型进行了评估,并且在只有11个召回率分界点的评估指标上,将我们模型的AP结果和之前模型的进行了。如表2所示,SA-SSD在简单和中等的任务中都要优于其他的方法。然后我们研究了辅助任务和PSWarp在我们模型中的性能,其结果如表3所示。

Effect of segmentation tasks. 如表3所示,利用分割任务来辅助进行推理的方法在三个子集上的性能贡献分别是(0.5%,0.4%,0.2%)。在简单和中等子集上的性能提升要优于在困难子集上的性能提升,这是因为在困难样本上所包含的点更少,为分割任务提供了非常有限的信息。
Effect of estimation task. 中心点预测任务在三个子集上的性能提升分别为(0.6%,0.3%,0.8%),在困难样本样的性能提升最大。这是符合我们的语气的,当点的个数相对稀疏的时候,学习物体的内部特征对于预测物体的缩放尺度和尺寸至关重要。
Effect of part-sensitive warping. PSWarp方法在三个子集上的性能提升分别为(0.4%,0.3%,0.5%),验证了微调分类置信度和预测边界框的有效性。我们也比较了PSWarp和PSRoIAlign方法。边界框对齐的三个空间分辨率分别为2*3,3*5和4*7。如表4所示,PSWarp在高分辨率的检测性能和PSRoIAlign的差不多,只有当分辨率较低的时候,前者的性能略低于后者的。这是因为预测的边界框通常在最终的特征图中占据更少的像素点,因此每个子窗口的中心点都具有代表性。然后,PSWarp不需要从稠密的特征图中得到大量的感兴趣区域,因此其所消耗的时间大约是PSRoIAlign的1/10。

4.5 Runtime analysis
在推理阶段,我们评估了检测模型的每一步的运行时间。在Intel i7 CPU和2080TI GPU的环境下,除了运行我们的程序,我们还运行了SECOND算法的程序。总的步骤如下:
(1)从LiDAR文件中读取数据,然后移除相机视野之外的点云(Data)
(2)将点云编码为输入张量(Input)
(3)使用神经网络处理输入张量(Net)
(4)移除重复的预测值(NMS)
如图5所示,我们的方法总的时间消耗为40.1ms,和SECOND算法相比,不使用体素编码进行预处理可以节约大约6.6毫秒,使用PSWarp只增加了0.4毫秒的额外损耗。
5. Conclusion
在本项任务中,我们研究来了当期那单阶段的三维目标检测器的不足,并且提出了一个新的三维检测器,即结构感知的单阶段感受器。我们首次提出使用具有两个点级监督任务的辅助网络来指导骨干网络的特征学习,依次来学习三维物体的结构信息。在推理阶段,它极大的提高了检测精度并且并没有增加额外的计算损耗。我们进一步提出了part-sensitive warping操作来消除在NMS后处理算法中预测边界框和它们相应置信度的不匹配问题。在KITTI 3D/BEV检测基准上,显示了该方法的能够以较高的效率取得顶级的性能。
边栏推荐
- [LeetCode305周赛] 6136. 算术三元组的数目,6139. 受限条件下可到达节点的数目,6137. 检查数组是否存在有效划分,6138. 最长理想子序列
- 历史最全DL相关书籍、课程、视频、论文、数据集、会议、框架和工具整理分享
- Pytest+request+Allure实现接口自动化框架
- 科大讯飞笔试题复盘
- 313. 超级丑数-暴力解法
- Yii2开启 Schema 缓存
- 2022年最流行的自动化测试工具有哪些?全网最全最细都在这里了
- uart_spi练习
- Etcd realize large-scale application service management of actual combat
- 终于有人把灰度发布架构设计讲明白了
猜你喜欢

终于有人把灰度发布架构设计讲明白了

MT4/MQL4 Getting Started to Mastering EA Tutorial Lesson 1 - MQL Language Common Functions (1) OrderSend() Function
The most fierce "employee" in history, madly complaining about the billionaire boss Xiao Zha: So rich, he always wears the same clothes!

Flume (四) --------- Flume 企业开发案例

2022年最流行的自动化测试工具有哪些?全网最全最细都在这里了

uart_spi练习
MT4/MQL4入门到精通EA教程第一课-MQL语言常用函数(一)OrderSend()函数

Maya engine modeling

gpio子系统和pinctrl子系统(上)

Likou Brush Question Record 1.5-----367. Valid perfect squares
随机推荐
NPDP改版前最后一次考试!请注意
2020.12.4 log
最新工业界推荐系统数据集-召回排序模型原理、结构及代码实战整理分享
Force buckled brush problem record 7.1 -- -- -- -- -- 707. The design list
Programmer's Daily Life | Daily Fun
点击div内部默认文本被选中
数字 05 verilog&vivado2018.2零散笔记
uart_spi练习
Likou Brush Question Record 5.1-----59. Spiral Matrix II
Likou Brush Question Record 8.1-----206. Reverse linked list
MT4/MQL4入门到精通外汇EA教程第一课 认识MetaEditor
ROS2错误:不支持OpenGL 1.5 GLRenderSystem:: ci initialiseContext在C: \ \ ws \构建……
HMS Core分析服务智能运营6.5.1版本上线
MT4 / MQ4L entry to the master of EA tutorial lesson two (2) - - MQL language commonly used function account information commonly used functions
gpio子系统和pinctrl子系统(中)
SQLite切换日志模式优化
[LeetCode84双周赛] [模拟] 6174. 任务调度器 II,[贪心&数学] 6144. 将数组排序的最少替换次数
【Jenkins 学习笔记】玩转持续集成与持续交付
连接数据库且在网页运行的RDLC
Likou Brush Question Record 3.1-----977. Square of ordered array