当前位置:网站首页>Paper Notes: BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition
Paper Notes: BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition
2022-08-11 04:52:00 【shier_smile】

论文地址:https://arxiv.org/abs/1912.02413
代码地址:https://github.com/megvii-research/BBN
文章目录
1 动机
1.1 问题
The author states that it is used for long-tailed任务中常用的class rebalanceThe method shows good results though,But will break the model fordeep features的表现能力.
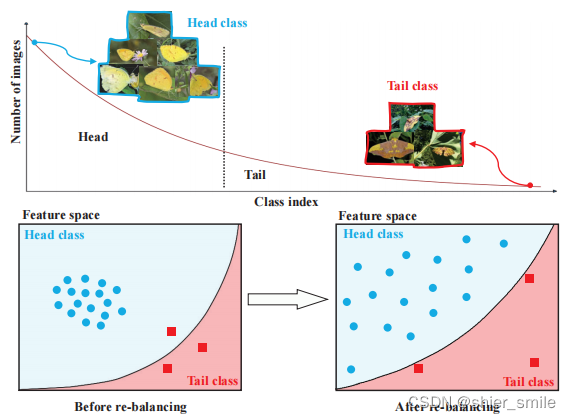
作者分析Class re-balance The method can produce better classification performance,但是在通过class re-balance之后,The intra-class distribution for each class becomes more dispersed.
1.2 How class re-balancing strategies work
In order to further verify the correctness of the above point of view,Controlled experiments were performed using the single control variable method.
The model is divided intofeature extrator(backbone)和classifier两部分.
对于class re-balancemethods were selectedRe-Sampling、Re-Weighting两种,Plus what is often used during normal classificationCross entropy进行实验.
A two-stage experimental approach was designed:
(1)Representation learning manner:先直接使用Cross Entropy或class re-balancemethod only for classification modelsfeature extratorpart of the training.
(2)Classifier learning manner:Fix the model againfeature extratorThe parameter does not move,参照(1)The training strategy in is focused on the modelclassifierpart of the training.

通过横向对比(控制Classifier learning manner不变),对于Representation learning manner使用RW(Re-Weighting)和RS(Re-Sampling)both degrade performance.
通过纵向对比(控制Representation learning manner不变),对于Classifier learning manner使用RW和RSThe classification performance is improved.
不仅在Long-tailed CIFAR-100-IR50(左图)This phenomenon appears above,在Long-tailed-10-IR50(右图)The same result is also reflected in the above.
在训练模型feature extrator阶段使用Cross Entropy,在训练classifier阶段使用RSThe best classification results were obtained.
结论: RW和RSIt can improve the performance of the classifier,But will reduce the model fordeep features的表达.
1.3 解决方法
A general model is proposedBBN,兼顾了representation learning 和classifier learning,
A new cumulative learning strategy is developed,用于调整BBNTwo branches of the model(conventional learning和Re-Balancing)学习,Its specific manifestation is as follows: Make the model more inclined to learn first during the training processuniversal patternThen gradually focus ontail class
2 BBN(Bilateral-Branch Network)

2.1 bilator-branch结构
(1) Data samplers
conventional learning branch采用uniform sampler
Re-Balance brach采用reversed sampler, The sampling probability is calculated as :
P i = w i ∑ j = 1 C w j w i = N m a x N i P_i=\frac{w_i}{\sum^C_{j=1}w_j}\\ w_i=\frac{N_{max}}{N_i} Pi=∑j=1Cwjwiwi=NiNmax
Pass probability first P i P_i Pi对类别进行采样,Then uniformly sample the class samples.Then, the samples obtained by the two branches are simultaneously input into the model for training.
(2) Weight share
使用了ResNet-32和ResNet50作为骨干网络, 除去最后一个residual block之外, 其他的blockWeights are shared on both branches.
作用:
conventional learningFeatures learned on branches can be better usedRe-Balance分支
Reduce the amount of network computation.
2.2 cumulative learning strategy
在训练过程中通过 α \alpha αThe parameter adjusts the weights of the two different branches, α \alpha α随着epochincrease gradually decreased,而在inference过程In the simple will α \alpha α设置为0.5.
训练过程中 α \alpha αThe way to change is:
α = 1 − ( T T m a x ) 2 T : 当前的 e p o c h T m a x : 最大 e p o c h \alpha=1-(\frac{T}{T_{max}})^2\\ T:当前的epoch\\ T_{max}:最大epoch α=1−(TmaxT)2T:当前的epochTmax:最大epoch
2.3 输出logit和损失函数
输出logit:
z = α W c T f c + ( 1 − α ) W r T f r z=\alpha W^T_cf_c+(1-\alpha)W^T_rf_r z=αWcTfc+(1−α)WrTfr
loss:
L = α E ( p ^ , y c ) + ( 1 − α ) E ( p ^ , y c ) L=\alpha E(\hat{p}, y_c)+(1-\alpha)E(\hat{p}, y_c) L=αE(p^,yc)+(1−α)E(p^,yc)
其中:
f c f_c fc: conventional learning分支中通过GAPeigenvectors after that
f r f_r fr: Re-Balance 分支中通过GAPeigenvectors after that
W T W^T WT: classifier的权重.
3 实验
3.1 实验参数
1 CIFAR-LT(10, 100)
(1) preprocess:
random crop:32x32
horizontal flip
padding:4 pixels each side
(2) backbone: ResNet32
(3):training details:
- momentum: 0.9
- weight decay: 2 ∗ 1 0 − 4 2*10^{-4} 2∗10−4
- batchsize:128
- epochs:200
- lrschduler: multistep(0, 120, 160), gamma:0.01, startlr=0.1
2 iNaturalist(2017,2018)
(1)preprocess:
- random_resized_crop(先resize到256再crop到224)
- random_horizontal_flip
(2)backbone:ResNet50
(3)training details:
momentum:0.9
weight decay:$1*10{-4}
batchsize: 128(代码中参数)
epochs:180 (代码中参数)
lrscheduler: multistep(0, 120, 160) gamma:0.1, base_lr:0.4(代码中参数) ps:given in the paper hereepoch是60, 80But the code is specific120, 160
3.2 实验结果
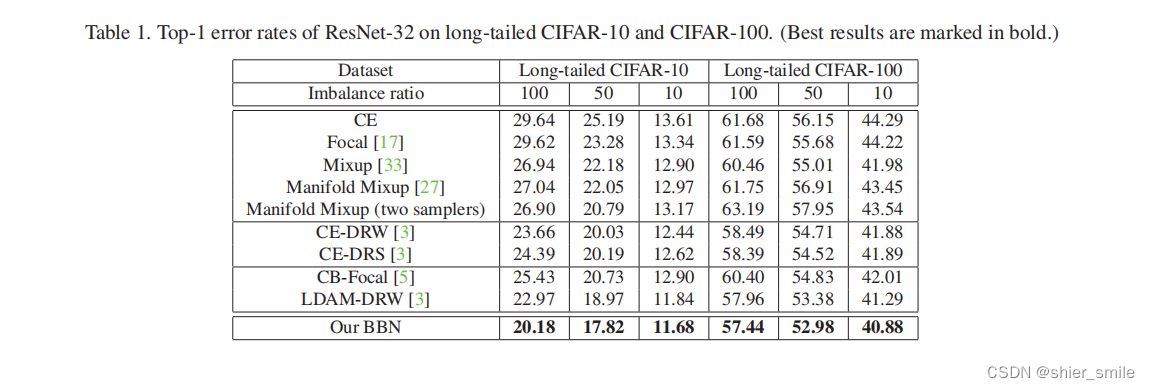
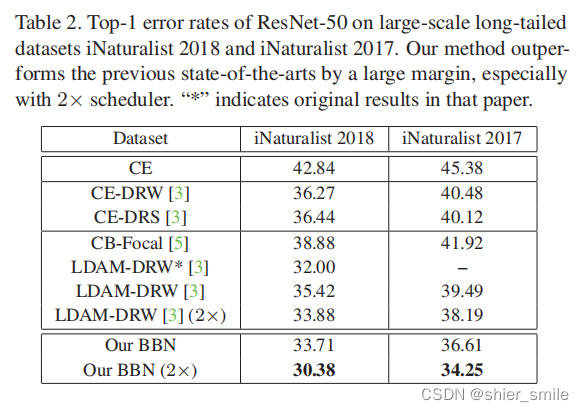
1 同其他Class balance性能对比
2 自身对比
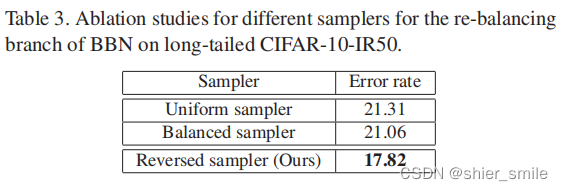
在Re-Balancing Branches are compared using different sampling methods.
对于 α \alpha αcomparison of different changes.

3 消融实验
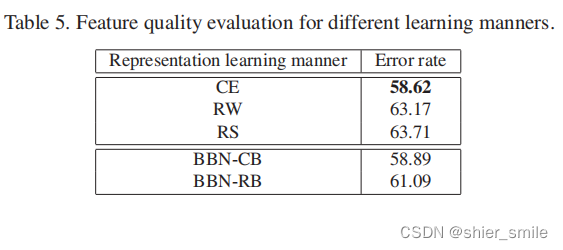
BBN的ConventionalBranching performance versus direct useCE相近,这表明了BBNModel reserved forLong-tailedFeature extraction capabilities of the data.而BBN的Re-BalancingBranching effect ratioRW和RS要好,The author stated that this is because of the weight sharing among the modelsConventionalThe features learned by the branch are better usedRe-Balance分支上.
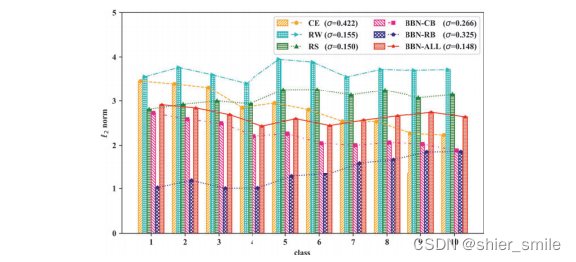
作者还对BBN模型的ClassifierThe weights in are visualized,并与其他class balancemethods were compared.
- BBN-ALL的方差最小, RW和RSAlthough the distribution is relatively flat, the variance ratio is higherBBN-ALL略大.
- BBN-CB(Conventional分支)的分布情况和CE相似.
- BBN-RB(Re-Balance分支)distribution fitsreversed sampling distribution.
4 参考文献
论文:BBN: Bilateral-Branch Network with Cumulative Learningfor Long-Tailed Visual Recognition
blog:https://zhuanlan.zhihu.com/p/109648173
This post is written in2022年8月8号, 未经本人允许,禁止转载.
边栏推荐
猜你喜欢










随机推荐
send_sig: kernel execution flow
开发工具篇第七讲:阿里云日志查询与分析
在 关闭页面/卸载(unload)文档 之前向服务器发送请求
交换机和路由器技术-36-端口镜像
How to add icons to web pages?
二叉堆的基础~
Layered Architecture & SOA Architecture
交换机和路由器技术-30-标准ACL
【实战场景】商城-折扣活动设计方案
zabbix构建企业级监控告警平台
洛谷P2370 yyy2015c01 的 U 盘
洛谷P1763 埃及分数
「转」“搜索”的原理,架构,实现,实践,面试不用再怕了
[Note] Is the value of BatchSize the bigger the better?
leetcode 9. 回文数
[QNX Hypervisor 2.2用户手册]10.16 vdev virtio-blk
Dry goods: The principle and practice of server network card group technology
直播平台开发,Flutter,Drawer侧滑
1815. Get the maximum number of groups of fresh donuts state compression
Jetson Orin platform 4-16 channel GMSL2/GSML1 camera acquisition kit recommended