当前位置:网站首页>1.1-回归
1.1-回归
2022-08-11 06:50:00 【一条大蟒蛇6666】
文章目录
一、模型model
一个函数function的集合:
- 其中wi代表权重weight,b代表偏置值bias
- 𝑥𝑖可以取不同的属性,如: 𝑥𝑐𝑝, 𝑥ℎ𝑝, 𝑥𝑤,𝑥ℎ…
𝑦 = 𝑏 + ∑ w i x i 𝑦=𝑏+∑w_ix_i y=b+∑wixi
我们将𝑥𝑐𝑝拿出来作为未知量,来寻找一个最优的线性模型Linear model:
y = b + w ∙ X c p y = b + w ∙Xcp~ y=b+w∙Xcp
二、较好的函数function
损失函数Loss function 𝐿:
L的输入Input是一个函数 f ,输出output则是一个具体的数值,而这个数值是用来评估输入的函数 f 到底有多坏
y ^ n \widehat{y}^n yn代表真实值,而 f ( x c p n ) f(x^n_{cp}) f(xcpn)代表预测值, L ( f ) L(f) L(f)代表真实值与预测值之间的总误差
L ( f ) = ∑ n = 1 10 ( y ^ n − f ( x c p n ) ) 2 L(f)=\sum_{n=1}^{10}(\widehat{y}^n-f(x^n_{cp}))^2 L(f)=n=1∑10(yn−f(xcpn))2将函数 f 用w,b替换,则可以写成下面这样
L ( w , b ) = ∑ n = 1 10 ( y ^ n − ( b + w ⋅ x c p n ) ) 2 L(w,b)=\sum_{n=1}^{10}(\widehat{y}^n-(b+w \cdot x^n_{cp}))^2 L(w,b)=n=1∑10(yn−(b+w⋅xcpn))2当 L 越小时,则说明该函数 f 越好,也就是该模型越好。在下图中的每一个点都代表一个函数 f

三、最好的函数function
梯度下降Gradient Descent:就是求最好函数的过程
$f^{ } 代表最好的函数 f u n c t i o n , 代表最好的函数function, 代表最好的函数function,w{*},b{ }:$代表最好的权重weight和偏置值bias
f ∗ = a r g m i n f L ( f ) f^{*} =arg \underset{f}{min} L(f) f∗=argfminL(f)
w ∗ , b ∗ = a r g m i n w , b L ( w , b ) w^{*},b^{*}=arg \underset{w,b}{min} L(w,b) w∗,b∗=argw,bminL(w,b)
= a r g m i n w , b ∑ n = 1 10 ( y ^ n − ( b + w ⋅ x c p n ) ) 2 =arg \underset{w,b}{min}\sum_{n=1}^{10}(\widehat{y}^n-(b+w \cdot x^n_{cp}))^2 =argw,bmin∑n=110(yn−(b+w⋅xcpn))2
3.1 一维函数
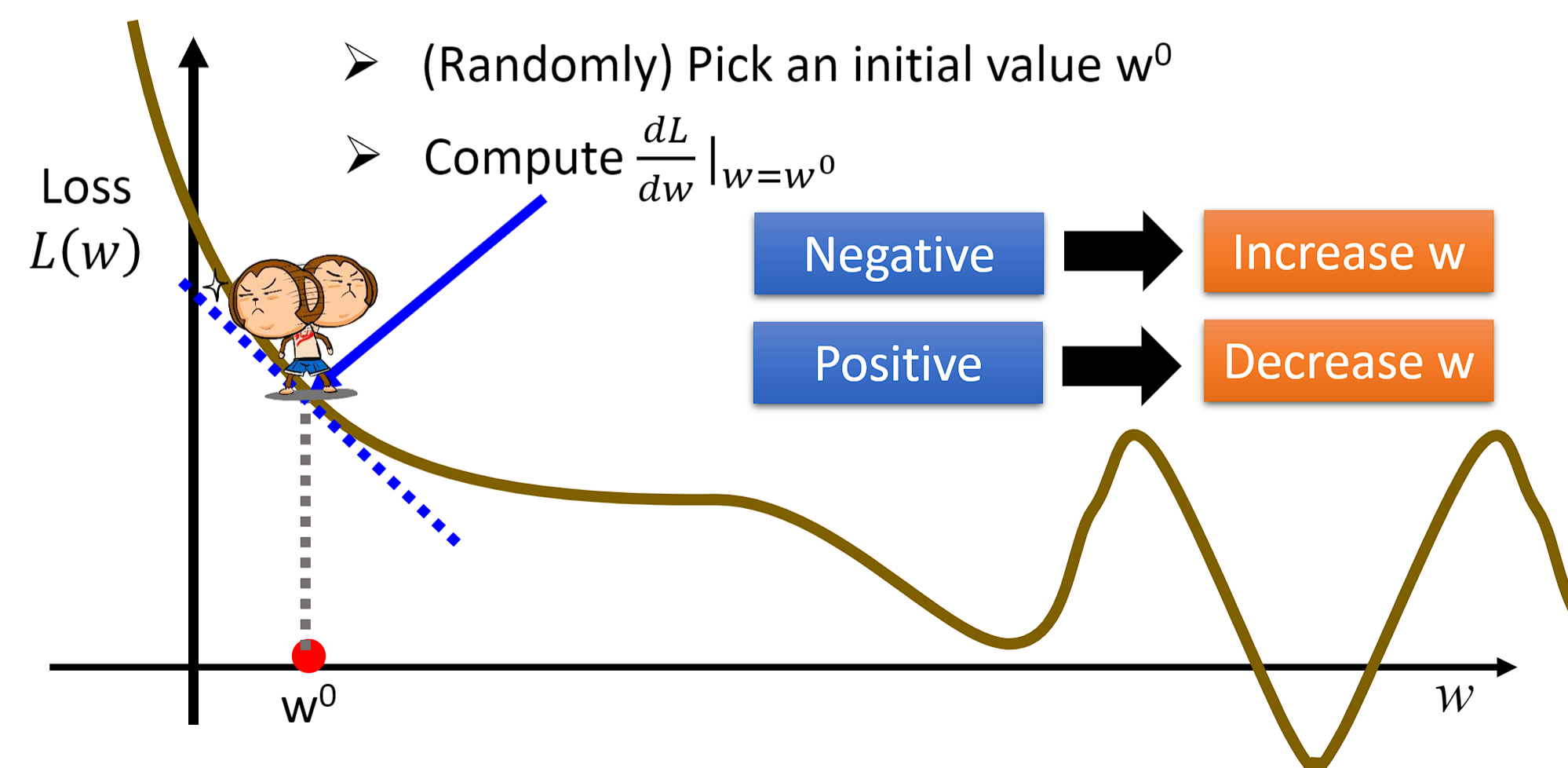
下图代表Loss函数求梯度下降(Gradient Descent)的过程,首先随机选择一个 w 0 w^{0} w0。在该点对w求微分,如果为负数,那么我们增大 w 0 w^{0} w0的值;如果为正数,那么我们减小 w 0 w^{0} w0的值。
- w ∗ = a r g m i n w L ( w ) w^{*}=arg\underset{w}{min}L(w) w∗=argwminL(w)
- w 0 = − η d L d w ∣ w w^{0}=-\eta\frac{dL}{dw}|_{w} w0=−ηdwdL∣w,其中 η 代表学习率:Learning rate,意味着每次移动的步长(step)
- w 1 ← w 0 − η d L d w ∣ w = w 0 w^{1}\leftarrow w^{0}-\eta\frac{dL}{dw}|_{w=w^{0}} w1←w0−ηdwdL∣w=w0, w 1 w1 w1代表初始点 w 0 w^{0} w0要移动的下一个点,就这样一直迭代(Iteration)下去,最终就会找到我们的局部最优解:Local optimal solution


3.2 二维函数
- 对二维函数$Loss $ L ( w , b ) L(w,b) L(w,b)求梯度下降: [ ∂ L ∂ w ∂ L ∂ b ] g r a d i e n t \begin{bmatrix} \frac{\partial L}{\partial w}\\ \frac{\partial L}{\partial b} \end{bmatrix}_{gradient} [∂w∂L∂b∂L]gradient
- w ∗ , b ∗ = a r g m i n w , b L ( w , b ) w^{*},b^{*}=arg \underset{w,b}{min} L(w,b) w∗,b∗=argw,bminL(w,b)
- 随机初始化 w 0 , b 0 w^{0},b^{0} w0,b0,然后计算 ∂ L ∂ w ∣ w = w 0 , b = b 0 \frac{\partial L}{\partial w}|_{w=w^{0},b=b^{0}} ∂w∂L∣w=w0,b=b0和 ∂ L ∂ b ∣ w = w 0 , b = b 0 \frac{\partial L}{\partial b}|_{w=w^{0},b=b^{0}} ∂b∂L∣w=w0,b=b0:
- w 1 ← w 0 − η ∂ L ∂ w ∣ w = w 0 , b = b 0 w^{1}\leftarrow w^{0}-\eta\frac{\partial L}{\partial w}|_{w=w^{0},b=b^{0}} w1←w0−η∂w∂L∣w=w0,b=b0
- b 1 ← b 0 − η ∂ L ∂ b ∣ w = w 0 , b = b 0 b^{1}\leftarrow b^{0}-\eta\frac{\partial L}{\partial b}|_{w=w^{0},b=b^{0}} b1←b0−η∂b∂L∣w=w0,b=b0

3.3 局部最优解和全局最优解
公式化(Formulation) ∂ L ∂ w \frac{\partial L}{\partial w} ∂w∂L和$
\frac{\partial L}{\partial b}$:- L ( w , b ) = ∑ n = 1 10 ( y ^ n − ( b + w ⋅ x c p n ) ) 2 L(w,b)=\sum_{n=1}^{10}(\widehat{y}^n-(b+w \cdot x^n_{cp}))^2 L(w,b)=∑n=110(yn−(b+w⋅xcpn))2
- ∂ L ∂ w = 2 ∑ n = 1 10 ( y ^ n − ( b + w ⋅ x c p n ) ) ( − x c p n ) \frac{\partial L}{\partial w}=2\sum_{n=1}^{10}(\widehat{y}^n-(b+w \cdot x^n_{cp}))(-x^{n}_{cp}) ∂w∂L=2∑n=110(yn−(b+w⋅xcpn))(−xcpn)
- ∂ L ∂ b = 2 ∑ n = 1 10 ( y ^ n − ( b + w ⋅ x c p n ) ) \frac{\partial L}{\partial b}=2\sum_{n=1}^{10}(\widehat{y}^n-(b+w \cdot x^n_{cp})) ∂b∂L=2∑n=110(yn−(b+w⋅xcpn))
在非线性系统中,可能会存在多个局部最优解:

3.4 模型的泛化(Generalization)能力
将根据loss函数找到的最好模型拿出来,分别计算它在训练集(Training Data)和测试集(Testing Data)上的均方误差(Average Error),当然我们只关心模型在测试集上的具体表现如何。
- y = b + w ∙ x c p y = b + w ∙x_{cp} y=b+w∙xcp Average Error=35.0
由于原来的模型均方误差还是比较大,为了做得更好,我们来提高模型的复杂度。比如,引入二次项(xcp)2
- y = b + w 1 ∙ x c p + w 2 ∙ ( x c p ) 2 y = b + w1∙x_{cp} + w2∙(x_{cp)}2 y=b+w1∙xcp+w2∙(xcp)2 Average Error = 18.4
继续提高模型的复杂度,引入三次项(xcp)3
- y = b + w 1 ∙ x c p + w 2 ∙ ( x c p ) 2 + w 3 ∙ ( x c p ) 3 y = b + w1∙x_{cp} + w2∙(x_{cp})2+ w3∙(x_{cp})3 y=b+w1∙xcp+w2∙(xcp)2+w3∙(xcp)3 Average Error = 18.1
继续提高模型的复杂度,引入三次项(xcp)4,此时模型在训练集上的均方误差变得更小了,但测试集上的反而变大了,这种现象被称为模型的过拟合(Over-fitting)
- $y = b + w1∙x_{cp} + w2∙(x_{cp})2+ w3∙(x_{cp})3+ w4∙(x_{cp})4 $ Average Error = 28.8

3.5 隐藏的因素(hidden factors)
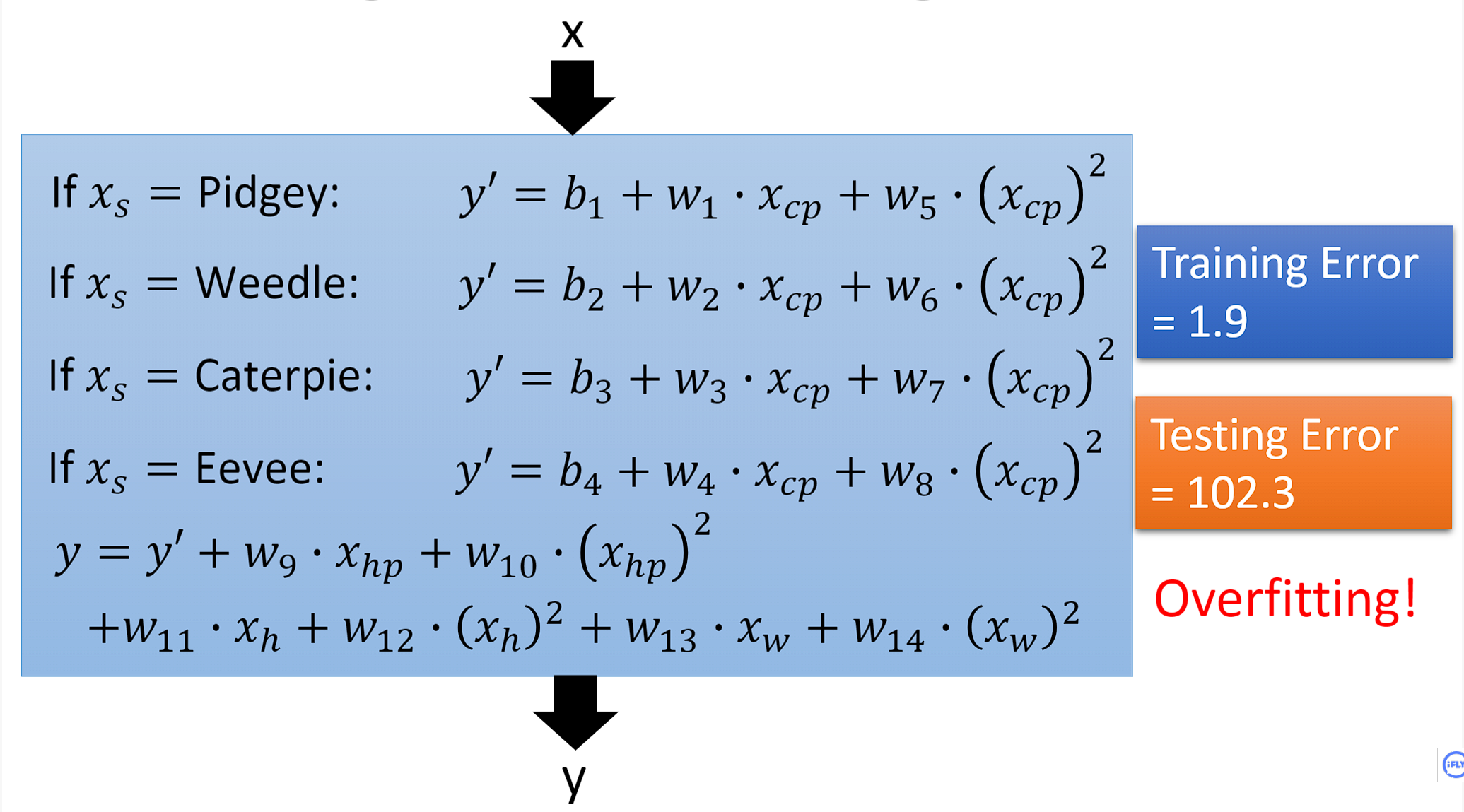
- 当我们不仅仅只考虑宝可梦的cp值,将宝可梦的物种因素也考虑进去的话,在测试集上的均方误差降低到了14.3


- 当我们继续考虑其他的因素,比如每只宝可梦的身高Height,体重weight,经验值HP。模型此时变得更加复杂了,让我们来看看它在测试集上的具体表现如何,非常不幸模型再次出现过拟合。
3.5 正则化(Regularization)
为了解决过拟合的问题,我们需要重新设计一下损失函数 L,原来的损失函数只计算了方差,而没有考虑到含有干扰的输入对模型的影响。因此我们在 L 后面加上一项: λ ∑ ( w i ) 2 \lambda \sum (w_i)^2 λ∑(wi)2 ,以此来提高模型的泛化能力,使模型变得更加平滑,降低模型对输入的敏感(Sensitive)
- 重新设计的损失函数 L : L ( f ) = ∑ n ( y ^ n − ( b + ∑ w i x i ) ) 2 + λ ∑ ( w i ) 2 L(f)=\underset{n}{\sum}(\widehat{y}^n-(b+\sum w_ix_i))^2+\lambda \sum (w_i)^2 L(f)=n∑(yn−(b+∑wixi))2+λ∑(wi)2
很显然根据下面的实验,我们取得了更好的表现, 当 λ = 100 时, T e s t E r r o r = 11.1 当\lambda=100时,Test Error = 11.1 当λ=100时,TestError=11.1

边栏推荐
- When MySQL uses GROUP BY to group the query, the SELECT query field contains non-grouping fields
- 1101 B是A的多少倍 (15 分)
- golang fork 进程的三种方式
- Pico neo3 Unity打包设置
- tf.cast(),reduce_min(),reduce_max()
- TF中的四则运算
- 2022-08-10 第四小组 修身课 学习笔记(every day)
- 1051 复数乘法 (15 分)
- Discourse's Close Topic and Reopen Topic
- 梅科尔工作室——BP神经网络
猜你喜欢




随机推荐
Service的两种启动方式与区别
下一代 无线局域网--强健性
动态代理学习
Item 2 - Annual Income Judgment
【@网络工程师:用好这6款工具,让你的工作效率大翻倍!】
易观分析联合中小银行联盟发布海南数字经济指数,敬请期待!
[Recommender System]: Overview of Collaborative Filtering and Content-Based Filtering
js根据当天获取前几天的日期
Unity开发者必备的C#脚本技巧
【Pytorch】nn.ReLU(inplace=True)
DDR4内存条电路设计
STM32CUBEIDE(11)----输出PWM及修改PWM频率与占空比
1061 判断题 (15 分)
Tf中的平方,多次方,开方计算
Implementation of FIR filter based on FPGA (5) - FPGA code implementation of parallel structure FIR filter
【软件测试】(北京)字节跳动科技有限公司二面笔试题
SQL sliding window
PIXHAWK飞控使用RTK
tf.cast(), reduce_min(), reduce_max()
机器学习总结(二)