当前位置:网站首页>3.2-分类-Logistic回归
3.2-分类-Logistic回归
2022-08-11 06:50:00 【一条大蟒蛇6666】
文章目录
一、函数集合(Function Set)
- 后验概率(Posterior probability):P(x)就是后验概率,右图是P(x)的图解,整个过程也被称为逻辑回归(Logistic Regression)


二、更好的函数(Goodness of a Function)
- 最好的w*和b*就是拥有最大概率产生这笔训练集的w和b,右图是公式恒等变形后进行的简化运算。


- 蓝线部分是两个伯努利分布(Bernoulli distribution)的交叉熵(Cross entropy),而交叉熵则是用来计算两个分布p和q之间有多接近,如果p和q一模一样的话,那么最终计算出来的交叉熵就是0
- 对于逻辑回归(Logistic Regression)而言,他用来衡量模型好坏的loss函数是在训练集上的交叉熵之和。该值越小,则代表在训练集上的表现越好。


三、找出最佳函数(Find the best function)
- 对loss函数进行化简,最终结果如右图绿色部分,当模型的输出和期望值之间的差距越大时,那么我们更新的量也要越大


- 从左图我们可以看到,逻辑回归和线性回归在做参数更新时的方法是一样的,都只需要去调这个学习率 η \eta η


- 根据下图可以清晰的看到如果做逻辑回归时采用方差(SquareError)来做loss函数的弊端,在离最优解很远的地方,其微分值仍然非常小,这就不利于我们做梯度下降。

- 逻辑回归是一种判别法(Discriminative),不同于上一章的概率生成模型是一种生成法(Generative)。
- 尽管这两种方法都是在同一个函数集合里面去找一个最好的模型,但由于逻辑回归是通过直接做梯度下降来找w和b,概率生成模型是通过找𝜇1, 𝜇2, Σ来间接找w和b,采取的方法不同,因此最终得出的模型也会有很大的区别。
- 在宝可梦这个示例中,我们发现逻辑回归要比概率生成模型要好。

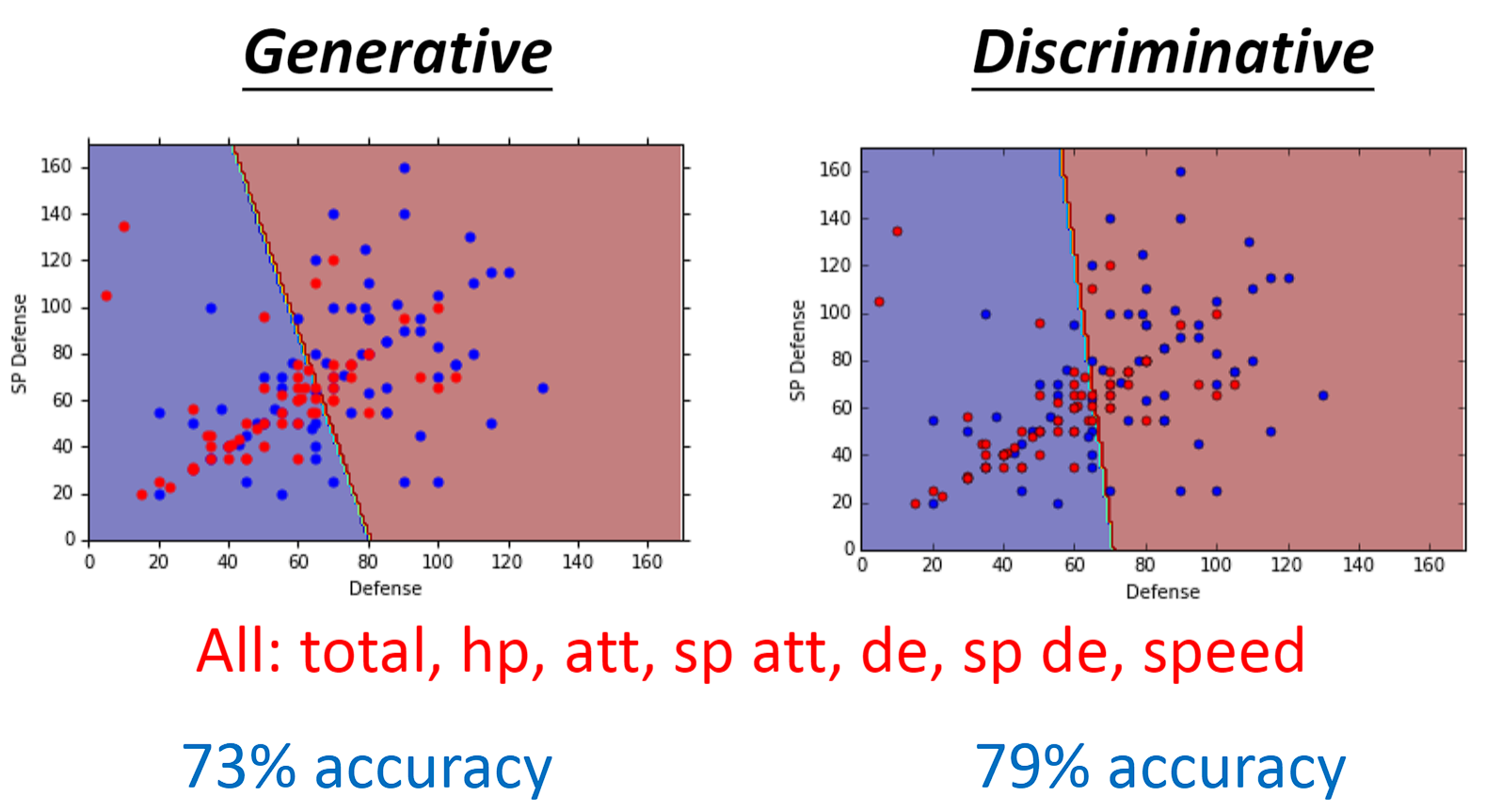
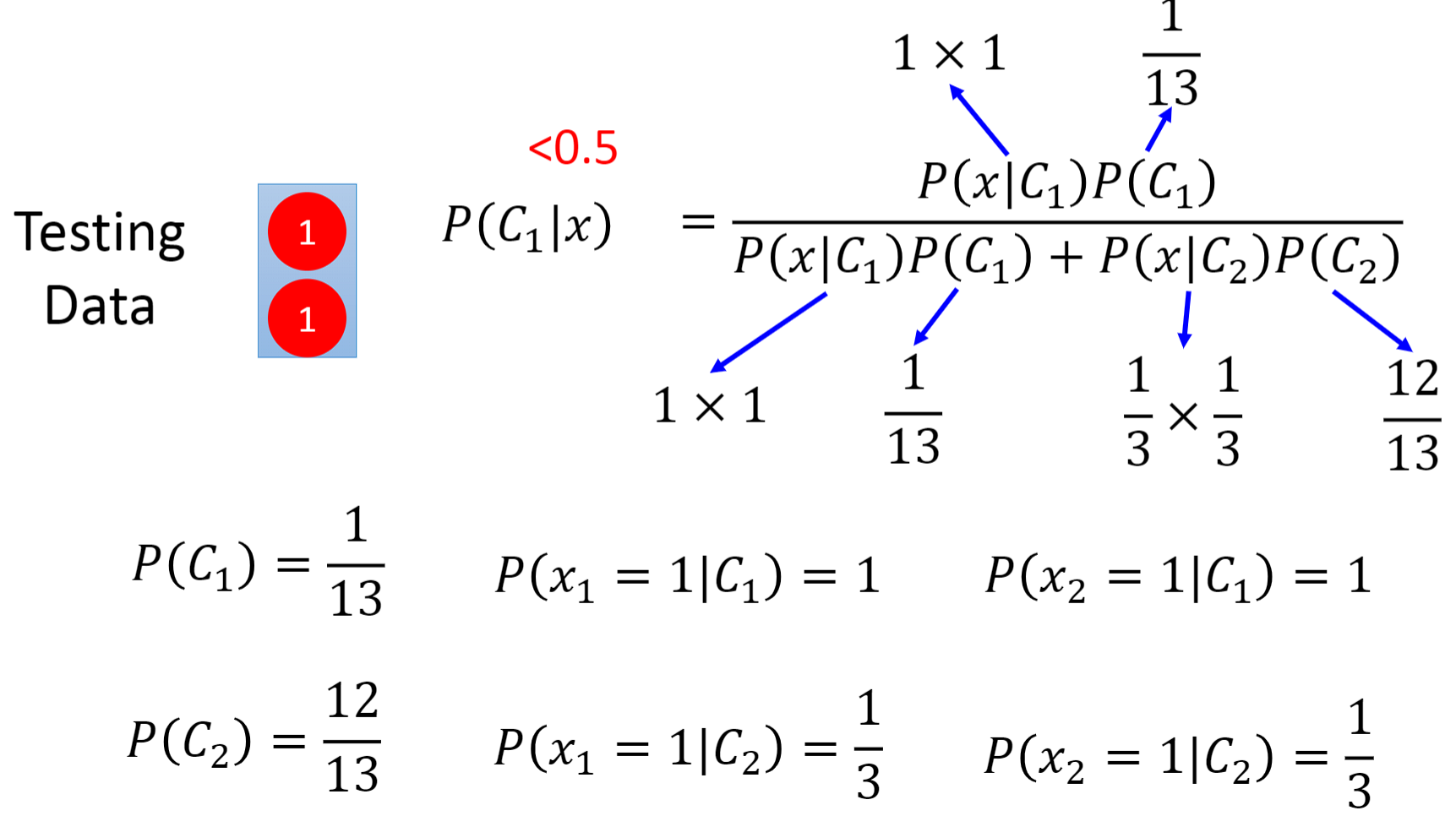
- 在下面这个示例中我们凭借直觉很容易认为测试集是属于class 1的,然而在概率生成模型中的朴素贝叶斯分类器最终却告诉我们测试集来自class 2。这是为什么呢?
- 这是因为在朴素贝叶斯分类器中,它从不考虑不同维度之间的相关性(correlation),它认为下面每一个数据中的两维参数都是互相独立的。因为概率生成模型总是会做一些假设,比如假设这些数据来自于某个概率分布,就像它会脑补一些事情一样,

四、概率生成模型的优点
- 逻辑回归的受数据的影响比较大,因为他不做任何假设,所以它的误差会随着数据量的增大而减小
- 概率生成模型受数据的影响比较小,因为他有自己的一个假设,有的时候它会无视那个data,而遵从它自己内心的那个假设。因此在数据量比较小的时候,概率生成模型是有可能赢过逻辑回归的。
- 当数据集有噪声时,比如标签有一部分是错误的,因为概率生成模型受数据的影响比较小,那么最终的结果就可能过滤掉这些不好的因素。
- 以语音辨识为例,虽然用的是神经网络,这是一个逻辑回归的方法。但事实上,整个系统却是一个概率生成模型,DNN只是其中的一块而已。
五、多分类
- Softmax是最大值强化的意思,因为中间通过了一层指数(exponential)运算来放大输出之间的差距。


逻辑回归的限制(Limitation of Logistic Regression):
下面就是逻辑回归无法解决的问题,我们需要进行一定的特征变换(Feature Transformation)
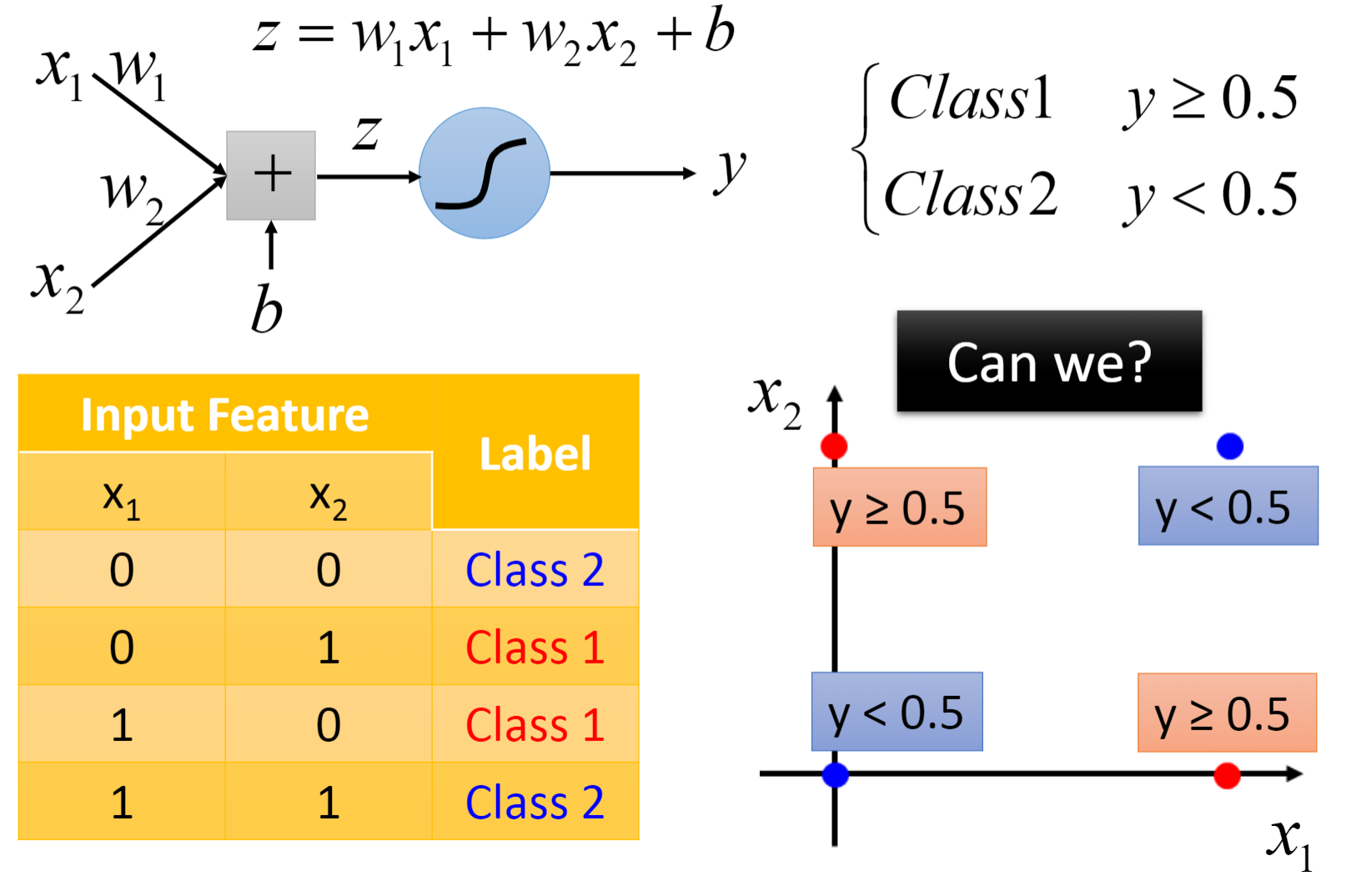

- 特征变换(Feature Transformation):为了让机器能自主的产生变换(Transformation)规则,我们可以将多个逻辑回归联结(Cascading)起来。右图很好的展示了特征变换和分类这两个过程。
- 最后一张图片中间框起来的就是一个类神经元(Neuron),并且这一整个网络就被称为类神经网络(Neural Network),也被称为深度学习(Deep Learning)



边栏推荐
猜你喜欢




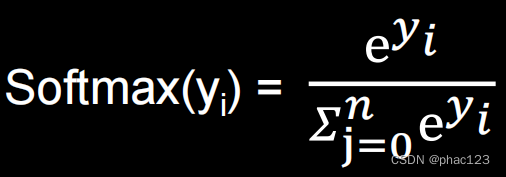
随机推荐
C语言每日一练——Day02:求最小公倍数(3种方法)
Edge provides label grouping functionality
Unity底层是如何处理C#的
2022-08-09 Group 4 Self-cultivation class study notes (every day)
MySQL使用GROUP BY 分组查询时,SELECT 查询字段包含非分组字段
2021-08-11 for循环结合多线程异步查询并收集结果
Daily sql - judgment + aggregation
DDR4内存条电路设计
Pico neo3在Unity中的交互操作
1051 复数乘法 (15 分)
1091 N-自守数 (15 分)
NFT 的价值从何而来
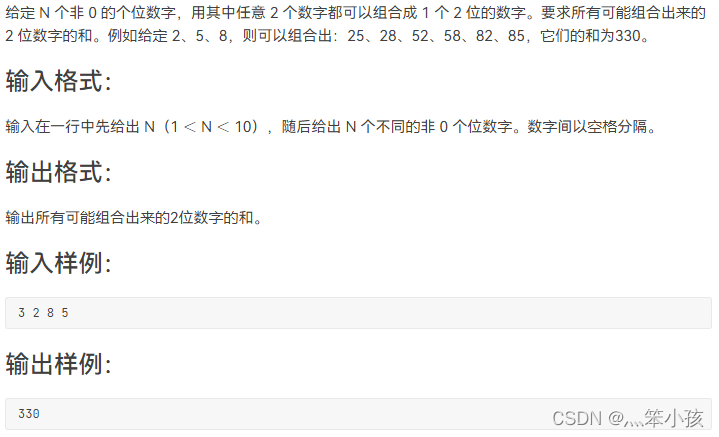
1056 组合数的和 (15 分)
prometheus学习5altermanager
LeetCode brushing series -- 46. Full arrangement
Production and optimization of Unity game leaderboards
daily sql - query for managers and elections with at least 5 subordinates
软件测试基本流程有哪些?北京专业第三方软件检测机构安利
How do you optimize the performance of your Unity project?
CIKM 2022 AnalytiCup Competition: 联邦异质任务学习