当前位置:网站首页>S TYLE N E RF: A S TYLE - BASED 3D-A WARE G ENERA - TOR FOR H IGH - RESOLUTION I MAGE S YNTHESIS
S TYLE N E RF: A S TYLE - BASED 3D-A WARE G ENERA - TOR FOR H IGH - RESOLUTION I MAGE S YNTHESIS
2022-04-21 12:48:00 【_Summer tree】

文章目录
Abstract
StyleNeRF:
- 具有多视图一致性的3D感知生成模型
- 基于没有组织的2D图像进行训练。
- 结合NeRF和 基于风格的生成器,用于:提升高分辨率图像的渲染效果和3D一致性(目标)
- 仅使用volume rendering来产生低分辨率的特征映射,然后逐渐在2D上采样来解决渲染效果的问题。
- 缓解不一致性的方法:
- a better unsampler
- 新的正则化损失
- ……
- 达到的效果: StyleNerf可以快速和合成高分辨率图像,并且保留3D一致性。
- 可以控制相机poses 和不同层级的风格。 这可以用生成看不见的视角。
- 它还支持具有挑战性的任务,包括放大和缩小、样式混合、反转和语义编辑
现有方法的问题:
- 不能合成高分辨率的图像
- 产生明显的3D不一致的伪影。
- 缺少对风格属性和明确相机姿势的控制
Method

- 上采样方法和其他方法的对比,我们的方法能够保持较好的3D一致性。
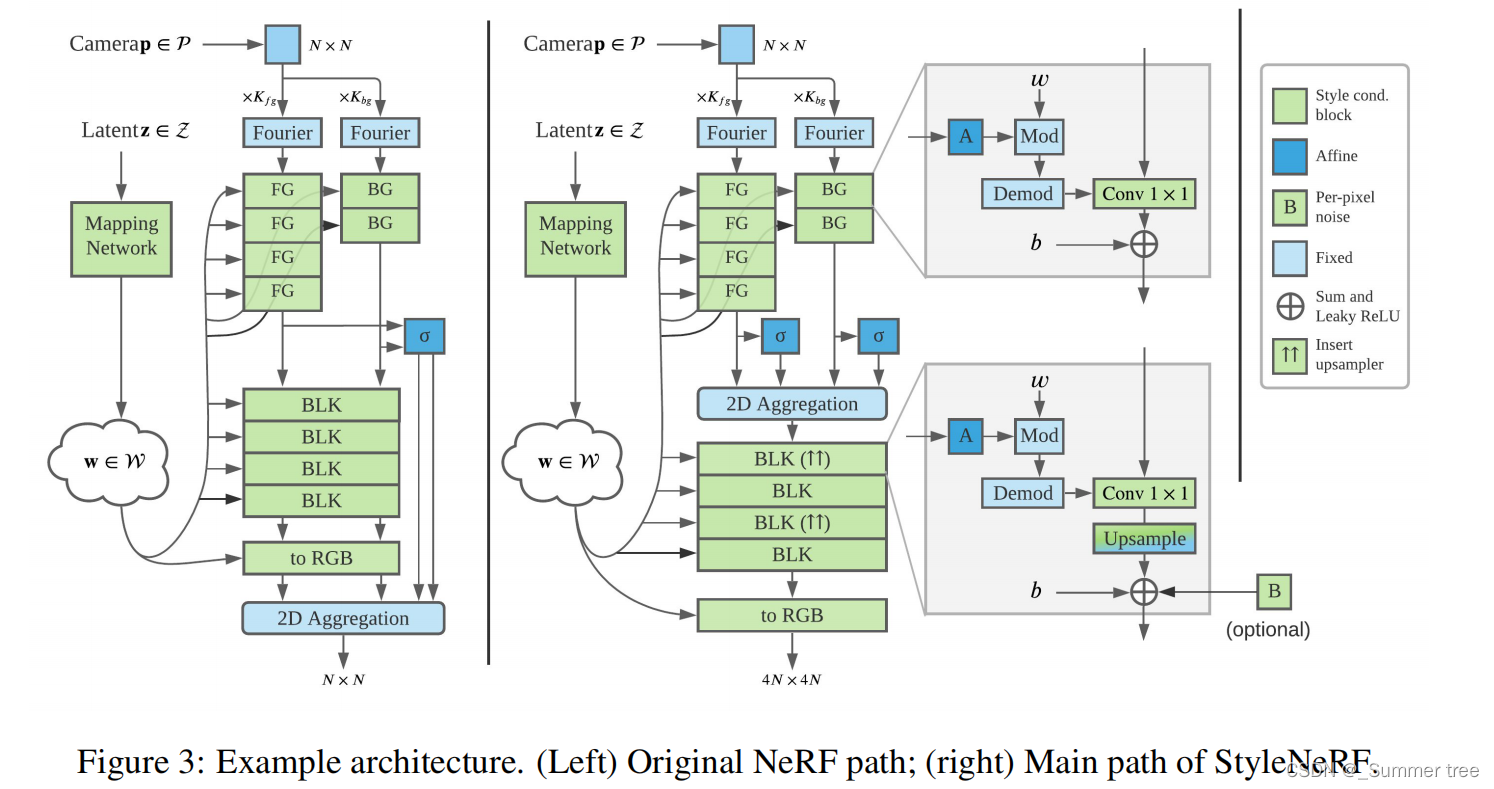
3.1 IMAGE SYNTHESIS AS NEURAL IMPLICIT FIELD RENDERING
基于风格生成的 NeRF
- 为了建模高频细节, 我们映射x和d的每个维度到傅里叶特征(fourier feature)

- 我们通过使用样式向量 w 调节 NeRF 来形式化 StyleNeRF 表示,如下所示

- f是个映射网络,将噪音向量从 球形高斯空间映射到风格空间 W。
- g w i ( ⋅ ) g_w^i(\cdot) gwi(⋅)表示第i个通过输入风格向量 ω \omega ω 进行调整的MLP层
- ϕ ω n ( x ) \phi_{\omega}^n(x) ϕωn(x) 是x点的第n层特征。
- 我们使用提取的特征来预测密度和颜色。

- 其中 hσ 和 hc 可以是线性投影或 2 层 MLP。
- 前min(nσ, nc) 层在网络中共享。
Volume Rendering
- 我们假设相机位于单位球体上,指向具有固定视场 (FOV) 的原点。
- 我们根据数据集从均匀或高斯分布中采样相机的俯仰和偏航(pitch & yaw)。
- 渲染图像 I。 (和基本公式一致)

- 和NeRF一样,使用了 stratified 和 hierarchical sampling
Challenges
- these models cost much more computation to render an image at the exact resolution
- consumes much more memory to cache the intermediate results for gradient back-propagation during
training
3.2 高分辨率图像生成的近似值
2D 图像生成快的原因
- 每个像素只需要单次前向通过网络;
- 图像特征是由粗到细逐步生成的,分辨率越高的特征图通常通道数越少,以节省内存。
通过在计算最终颜色之前将特征早期聚合到 2D 空间中来部分实现第一点。 ,我们将公式4调整为:


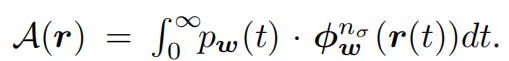
我们使用up-sample 将低分辨率的特征空间近似到高分辨率的特征空间。

- 递归插入上采样算子可实现高效的高分辨率图像合成,因为计算量大的体积渲染只需要生成低分辨率特征图。
- 当使用更少的通道以获得更高的分辨率时,效率会进一步提高。
虽然早期聚合和上采样操作可以加速高分辨率图像合成的渲染过程,但它们会破坏 NeRF 的固有一致性。
不一致性是如何导致的?
- ,the resulting model contains non-linear transformations to capture spurious correlations in 2D observation, mainly when substantial ambiguity exists.
- Second, such a pixel-space operation like up-sampling would compromise 3D consistency.
3.3 PRESERVING 3D CONSISTENCY
Unsampler design
We achieve the balance between consistency and image quality by combining these two approaches (see Figure 2).
对于任意输入的特征映射 X ∈ R N ∗ N ∗ D X \in R^{N * N * D} X∈RN∗N∗D:

- ψ θ : R D → R 4 D \psi_{\theta}:R^D \rightarrow R^{4D} ψθ:RD→R4D 是一个科学系的两层MLP。
- K是固定的模糊内核
NeRF path regularization
正则化模型输出以匹配原始路径(等式(4))。
这是通过对输出上的像素进行二次采样并将它们与 NeRF 生成的像素进行比较来实现的:
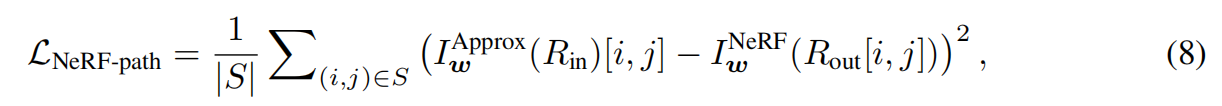
- S是随机采样的像素集合。
- Rin 和Rout 是通过NeRF生成的低分辨率的图像 和 StyleNeRF生成的高分辨率的图像 对应的像素的光速。
Remove view direction condition
Predicting colors with view direction condition would give the model additional freedom to capture spurious correlations and dataset bias, especially if only a single-view target is provided.
使用视图方向条件预测颜色将为模型提供额外的自由来捕获虚假相关性和数据集偏差,尤其是在仅提供单视图目标的情况下。因此我们移除了视角方向来提高一致性。 如图8所示。

Fix 2D noise injection
已有研究表明:注入每像素噪声可以提高模型对随机变化(例如头发、胡茬)的建模能力
我们的默认解决方案是通过消除噪声注入来交换模型捕获变化的能力。
我们还提出了一种基于 StyleNeRF 估计表面的新型几何感知噪声注入。(见附录A3)
3.4 StyleNeRF 架构
Mapping Network
从标准的高斯分布中采样 latent codes, 并经过mapping network进行处理。 最后输出向量被广播到synthesis network
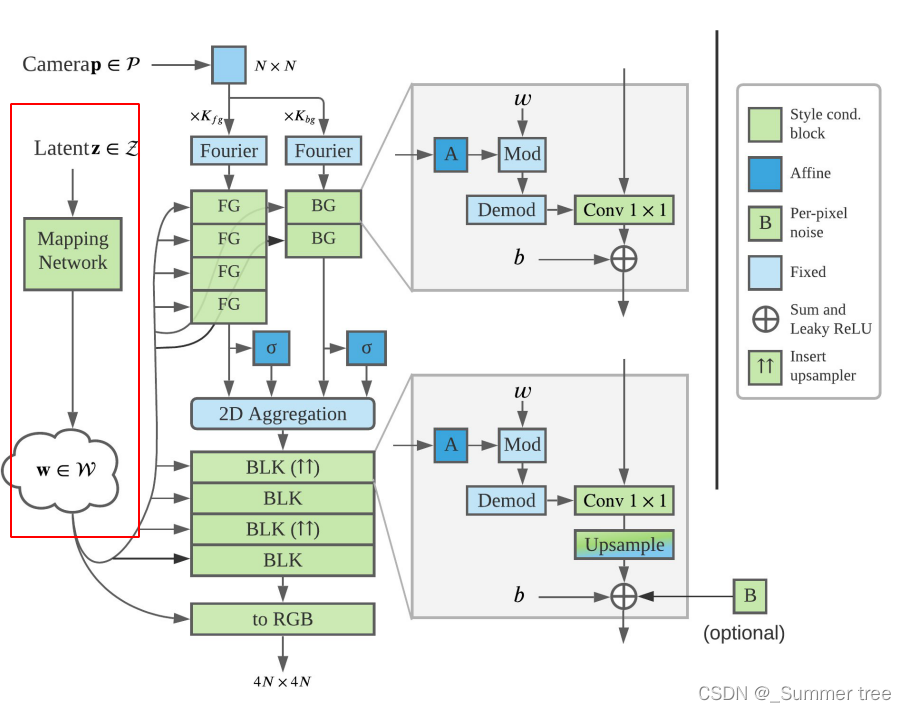
Synthesis Network
我们用 NeRF++作为 styleNeRF的骨干。
NeRF++ 由一个单位球体中的前景 NeRF 和一个用倒转球体参数化表示的背景 NeRF 组成。
两个MLP用于预测密度,其中BG 比 FG参数要少。
然后一个共享的MLP用来预测颜色。
每个风格条件块由一个仿射变换(affine transformaton)层和一个1×1卷积层(Conv)组成。
Conv的群中用放射变换风格来进行调整。
Leaky_Relu用于非线性激活。
块的数量依赖于输入和目标图像的分辨率。
Discriminator & Objectives
StyleNeRF采用带有R1 正则的 非饱和的GAN 目标。
新的NeRF路径正则化 被应用来增3D一致性。
最终的损失函数定义入下:

- G是包含了 Mapping和 synthsis network的生成器。
Progressive training
从底到高分辨率开始训练。
我们提出了一种新的三阶段渐进训练策略:
- 对于前T1张图片,不做低分辨率的近似。
- 在T1-T2张图片,生气城和判别器增加输出分辨率直到到达目标分辨率。
- 最后,我们固定架构,持续训练模型在高分辨率,直到T3 张图片。
- 细节参考 附录A4。
实验
用FFHQ、 MetFaces、AFHQ、CompCars 评估styleNeRF
baseline:
- HoloGAN
- GRAF
- pi-GAN
- CIRAFFE
batch_size 64, T1 = 500k , T2 = 5000k, T3=25000k.
输入分辨率固定为32x 32
结果


高分辨率合成

可控图像合成
相机控制:(这个效果并不好)

风格混合和插值:

重要参考文献
Michael Niemeyer and Andreas Geiger. Giraffe: Representing scenes as compositional generative neural feature fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition, pp. 11453–11464, 2021b.
Kai Zhang, Gernot Riegler, Noah Snavely, and Vladlen Koltun. Nerf++: Analyzing and improving
neural radiance fields. arXiv preprint arXiv:2010.07492, 2020.
问题
版权声明
本文为[_Summer tree]所创,转载请带上原文链接,感谢
https://blog.csdn.net/NGUever15/article/details/124312044
边栏推荐
- open-mmlab / mmpose安装、使用教程
- selenium的滑块验证码的模拟登录(猪八戒网站)
- 斐波那契数列
- Mysql database operation statement exercise
- AES自动生成base64密钥加密解密
- Simulated Login of selenium's slider verification code (pig Bajie website)
- 字段行相同则合并在另外一个字段sql 语句?
- Operation of simulated examination platform of test question bank for operation certificate of safety management personnel of hazardous chemical business units in 2022
- 风丘科技为您提供10M以太网解决方案
- Revit二次开发——创建楼板(第十二期)
猜你喜欢

How nodejs converts buffer data to string
SKU中的销售属性值必须成对填写,那这是什么原因

Title and answer of G3 boiler water treatment certificate in 2022

上个网课都能被AI分析“在走神”,英特尔这个情绪检测AI火了

2022年监理工程师考试质量、投资、进度控制练习题及答案

2022语言与智能技术竞赛再升级,推出NLP四大前沿任务

redis-常见问题

Eight common probability distribution formulas and visualization

斐波那契数列

BEVSegFormer:一个来自任意摄像头的BEV语义分割方法
随机推荐
Controlling the release and introduction of rip routing based on Routing
[untitled]
Call for Papers | IEEE/IAPR IJCB 2022 会议
The soul of the frame - Reflection
SM国密学习
框架的灵魂------反射
实例:用C#.NET手把手教你做微信公众号开发(7)--普通消息处理之位置消息
Office Word 2016 中Word自带公式编辑器编辑的公式转Mathtype出现omml2mml.xsl 问题的解决方法
The 2022 language and intelligent technology competition was upgraded to launch four cutting-edge tasks of NLP
AES automatically generates Base64 key encryption and decryption
Revit二次开发——多管道线性标注(第十八期)
Title and answer of G3 boiler water treatment certificate in 2022
I think you can tear the linked list by hand (1)
【论文学习】YOLO v2
Finally someone made it clear! It turns out that this is the global one-piece network technology with low delay
2022年一级注册建筑师考试建筑物理与设备复习题及答案
利用Cisco配置VRRP(虚拟路由器冗余协议)
[MySQL] extract and query JSON type field data
Pytroch 深度学习 跑CIFAR10数据集
2022年监理工程师合同管理练习题及答案