当前位置:网站首页>The Principle of Union Search and API Design
The Principle of Union Search and API Design
2022-08-10 05:52:00 【cbys-1357】
目录
前言:
In the last chapter, I introduced you to the tree structure of the red-black tree,以及实现原理,In this chapter I will introduce you to a simple union search,It is also a tree structure,但相对于二叉查找树,红黑树等,会相对比较简单,好理解.
原理:
并查集,在一些有N个元素的集合应用问题中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中.
并查集是一种树型的数据结构,用于处理一些不相交集合(Disjoint Sets)的合并及查询问题.常常在使用中以森林来表示.



并查集API设计
1.UF(int N)构造方法实现

2.union(int p,int q)合并方法实现
1. 如果p和q已经在同一个分组中,则无需合并

代码实现:
public class UF {
//记录结点元素和该元素所在分组的标识
private int[] eleAndGroup;
//Record the number of groups to group by
private int count;
// 构造方法
public UF(int N) {
//初始情况下,每个元素都在一个独立的分组中,所以,初始情况下,并查集中的数据默认分为N个组
this.count=N;
//初始化数组
this.eleAndGroup=new int[N];
//把eleAndGroup数组的索引看做是每个结点存储的元素,把eleAndGroup数组每个索引处的值看做是该结点所在的分组,那么初始化情况下,i索引处存储的值就是i
for(int i=0;i<eleAndGroup.length;i++) {
eleAndGroup[i]=i;
}
}
//获取当前并查集中的数据有多少个分组
public int count() {
return this.count;
}
//元素p所在分组的标识符
public int find(int p) {
return this.eleAndGroup[p];
}
//判断并查集中元素p和元素q是否在同一分组中
public boolean connected(int p,int q) {
return find(p)==find(q);
}
//把p元素所在分组和q元素所在分组合并
public void union(int p,int q) {
//如果p和q已经在同一个分组中,则无需合并;
if(connected(p,q)) {
return;
}
//如果p和q不在同一个分组,则只需要将p元素所在组的所有的元素的组标识符修改为q元素所在组的标识 符即可
int pGroup=find(p);
int qGroup=find(q);
for(int i=0;i<eleAndGroup.length;i++) {
if(find(i)==pGroup) {
eleAndGroup[i]=qGroup;
}
}
//分组数量-1
count--;
}
}
Everyone's brain thinks and wants to put oneN个小组,All together, how many times do we have to use it at leastunion方法?Probably everyone knows it isN-1次,而我们在union方法中又使用for循环,That is to say, combine all the groups together,The time complexity of the merge algorithm is O(n^2).If so then it might be relatively better for few groupings,Well, for problems like computing networks, the interconnection may have tens of millions,That is not optimistic.所以我们需要对算法进行优 化.
UF_Tree算法优化

1 UF_Tree API设计

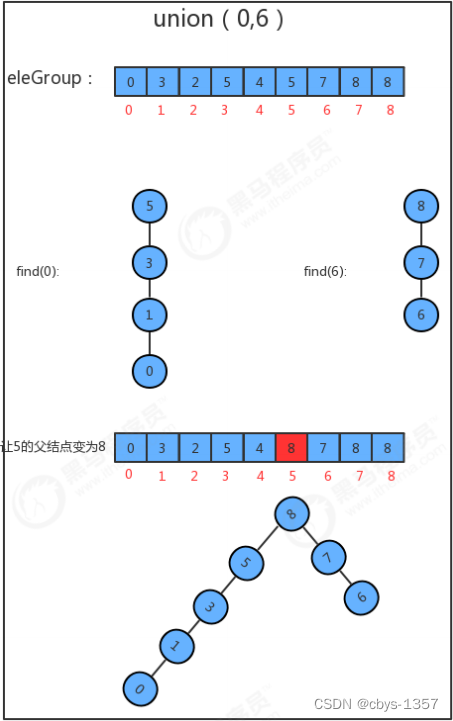
public class UF_Tree {
private int[] eleAndGroup;
private int count;
public UF_Tree(int N) {
this.count=N;
this.eleAndGroup=new int[N];
for(int i=0;i<eleAndGroup.length;i++) {
eleAndGroup[i]=i;
}
}
public int count() {
return this.count;
}
public boolean connected(int p,int q) {
return find(p)==find(q);
}
//元素p所在分组的标识符
public int find(int p) {
while(true) {
//判断当前元素p的父结点eleAndGroup[p]是不是自己,如果是自己则证明已经是根结点了;
if(p==eleAndGroup[p]) {
return p;
}
//如果当前元素p的父结点不是自己,则让p=eleAndGroup[p],继续找父结点的父结点,直到找到根 until the node;
p=eleAndGroup[p];
}
}
public void union(int p,int q) {
//找到p元素所在树的根结点
int proot=find(p);
//找到q元素所在树的根结点
int qroot=find(q);
//如果p和q已经在同一个树中,则无需合并;
if(proot==qroot) {
return;
}
//如果p和q不在同一个分组,则只需要将p元素所在树根结点的父结点设置为q元素的根结点即可;
eleAndGroup[p]=qroot;
//分组数量-1
this.count--;
}
}
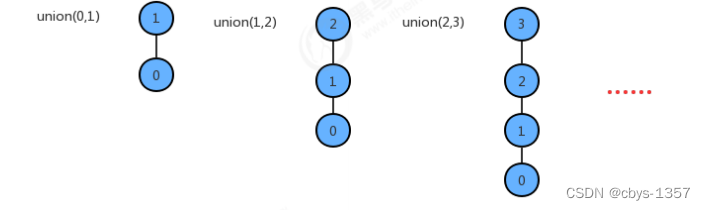
在union方法中调用了fifind方法,所以在最坏情况下union算法的时间复杂度仍然为O(N^2).
路径压缩

public class UF_Tree_Weighted {
//记录结点元素和该元素所的父结点
private int[] eleAndGroup;
//记录并查集中数据的分组个数
private int count;
//存储每个根结点对应的树中元素的个数
private int[] sz;
public UF_Tree_Weighted(int N) {
this.count=N;
this.eleAndGroup=new int[N];
// /把eleAndGroup数组的索引看做是每个结点存储的元素,把eleAndGroup数组每个索引处的值看做是该 结点的父结点,那么初始化情况下,i索引处存储的值就是i
for(int i=0;i<eleAndGroup.length;i++) {
eleAndGroup[i]=i;
}
//把sz数组中所有的元素初始化为1,默认情况下,每个结点都是一个独立的树,每个树中只有一个元素
this.sz=new int[N];
for(int i=0;i<sz.length;i++) {
sz[i]=1;
}
}
public int count() {
return this.count;
}
public boolean connected(int p,int q) {
return find(p)==find(q);
}
public int find(int p) {
while(true) {
if(p==eleAndGroup[p]) {
return p;
}
p=eleAndGroup[p];
}
}
public void union(int p,int q) {
int proot=find(p);
int qroot=find(q);
//如果p和q已经在同一个树中,则无需合并;
if(proot==qroot) {
return;
}
//如果p和q不在同一个分组,比较p所在树的元素个数和q所在树的元素个数,Merge the smaller tree into the larger tree
if(sz[proot]<sz[qroot]) {
//重新调整较大树的元素个数
eleAndGroup[proot]=qroot;
sz[qroot]+=sz[proot];
}else {
eleAndGroup[qroot]=proot;
sz[proot]=sz[qroot];
}
//分组数量-1
this.count--;
}
}
案例-畅通工程
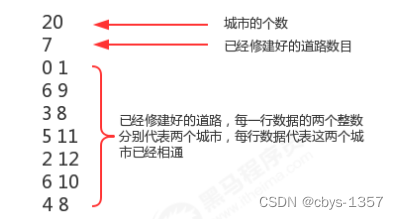
总共有20个城市,目前已经修改好了7条道路,问还需要修建多少条道路,才能让这20个城市之间全部相通?
public class Traffic_Project_Test {
public static void main(String[] args) throws IOException{
BufferedReader br=new BufferedReader(new InputStreamReader(Traffic_Project.class.getClassLoader().getResourceAsStream("traffic_projec t.txt")));
读取城市数目,初始化并查集
int totalNumber=Integer.parseInt(br.readLine());
UF_Tree_Weighted uf=new UF_Tree_Weighted(totalNumber);
//读取已经修建好的道路数目
int roadNumber=Integer.parseInt(br.readLine());
//循环读取已经修建好的道路,并调用union方法
for(int i=0;i<roadNumber;i++) {
String line=br.readLine();
String[] s=line.split(" ");
int p=Integer.parseInt(s[0]);
int q=Integer.parseInt(s[1]);
uf.union(p, q);
}
//At least the number of roads that need to be built=获取剩余的分组数量-1;
int roads=uf.count()-1;
System.out.println("还需要修建"+roads+"to smooth the project");
}
}
And the explanation of the collection is over here,Then see you next time!!!
活动地址:CSDN21天学习挑战赛
边栏推荐
- 微信小程序--模板与设置WXML
- win12 modify dns script
- 去中心化和p2p网络以及中心化为核心的传统通信
- Link reading good article: What is the difference between hot encrypted storage and cold encrypted storage?
- Bifrost micro synchronous database implementation services across the library data synchronization
- 各个架构指令集对应的机型
- Models corresponding to each architecture instruction set
- 网络安全3
- Content related to ZigBee network devices
- Chain Reading|The latest and most complete digital collection sales calendar-08.02
猜你喜欢








随机推荐
国内数字藏品投资价值分析
一个基于.Net Core跨平台小程序考试系统
Consensus calculation and incentive mechanism
文本元素
Canal reports Could not find first log file name in binary log index file
我不喜欢我的代码
优先队列
力扣——情侣牵手
generic notes()()()
error in ./node_modules/cesium/Source/ThirdParty/zip.js
你不知道的常规流
学生管理系统以及其简单功能的实现
opencv
Linux database Oracle client installation, used for shell scripts to connect to the database with sqlplus
opencv
transaction, storage engine
2021-06-22
MySql constraints
堆的原理与实现以及排序
Operation table Function usage