当前位置:网站首页>Weekly Report 2022-8-4
Weekly Report 2022-8-4
2022-08-05 09:05:00 【Alice01010101】
周报2022-8-4
一、MoE(Mixture of Experts)相关论文
Adaptive mixtures of local experts, Neural Computation’1991
- 参考:https://zhuanlan.zhihu.com/p/542465517
- 期刊/会议:Neural Computation (1991)
- 论文链接:https://readpaper.com/paper/2150884987
- Representative authors:Michael Jordan, Geoffrey Hinton
- Main Idea:
A new supervised learning process is proposed,A system contains multiple separate networks,Each network processes a subset of all training samples.This approach can be seen as a modular transformation of the multi-layer network.
Suppose we already know that there are some natural subsets in the dataset(such as from differentdomain,不同的topic),Then use a single model to learn,There will be a lot of interference(interference),lead to slow learning、Generalization is difficult.这时,We can use multiple models(i.e. expert,expert)去学习,Use a gate network(gating network)to decide which model should be trained on each data,This mitigates interference between different types of samples.
Actually this approach,Nor is it the first time the paper has been proposed,Similar methods have been proposed earlier.对于一个样本c,第i个 expert 的输出为 o i c o_i^c oic理想的输出是 d c d^c dc,Then the loss function is calculated like this:
其中 p i c p_i^c pic是 gating network 分配给每个 expert 的权重,相当于多个 expert Work together to get the current sample c c c的输出.
This is a very natural way of designing,但是存在一个问题——不同的 expert The interaction between them will be very large,一个expertparameters have changed,Everything else will follow,That is to say, pulling one hair and moving the whole body.这样的设计,The end result is that one sample will be used a lotexpert来处理.于是,This article designs a new way,调整了一下loss的设计,to encourage the differentexpert之间进行竞争: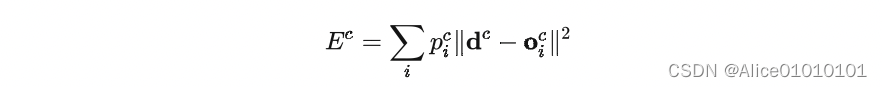
就是让不同的 expert 单独计算 loss,Then the weighted sum is obtained to get the overall loss.这样的话,每个专家,have the ability to make independent judgments,rather than relying on others expert Let's get predictions together.下面是一个示意图: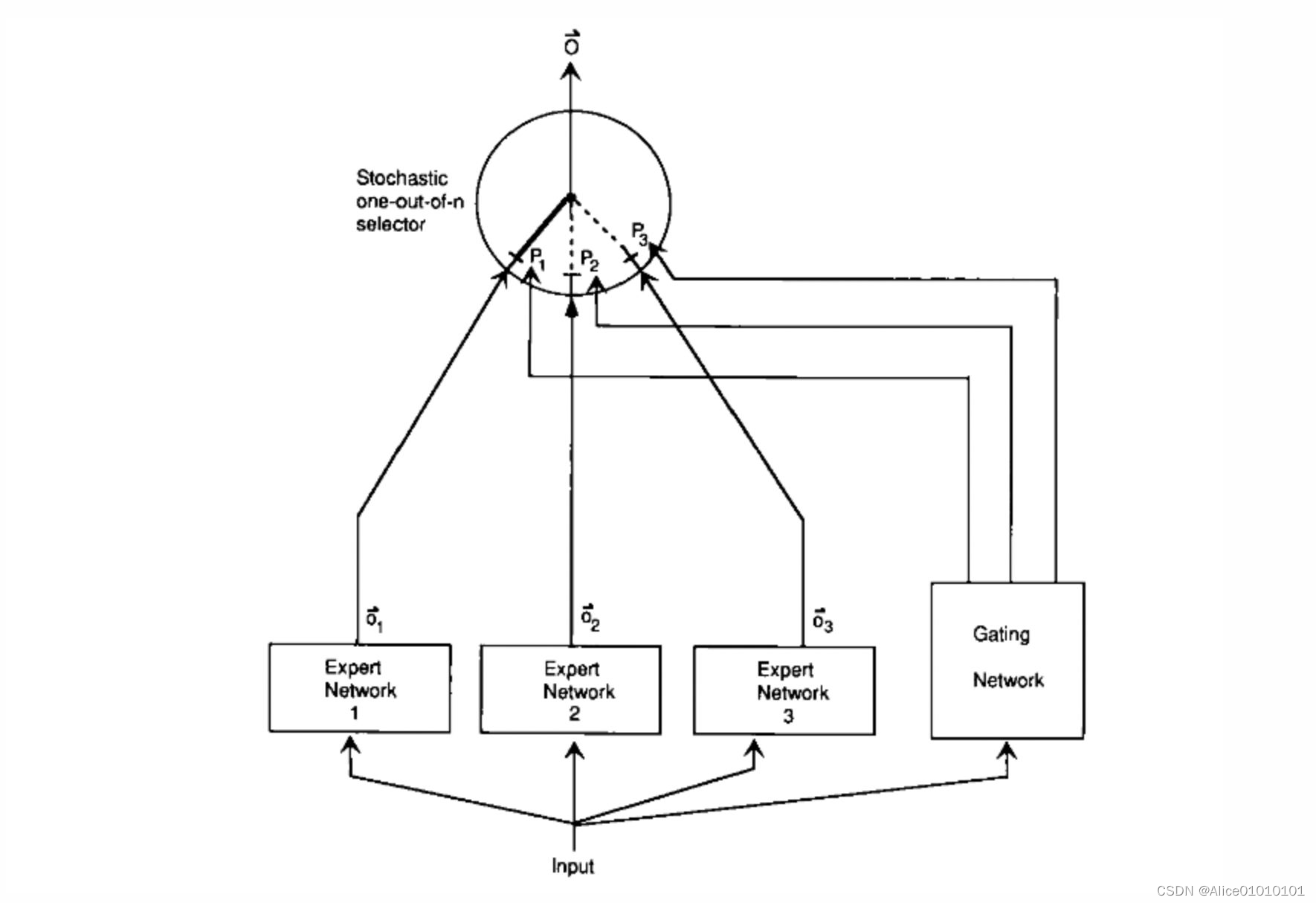
在这种设计下,我们将 experts 和 gating network 一起进行训练,The final system will tend to allow one expert to process a sample.
上面的两个 loss function,Actually looks very similar,But one is to encourage cooperation,One is to encourage competition.This is still quite inspiring.
The paper also mentions another very inspiring trick,This is the loss function above,When the author is actually doing the experiment,A variant was used,使得效果更好:
It can be seen by comparison,在计算每个 expert after the loss,It is first indexed and then weighted and summed,最后取了log.This is also a technique we often see in papers.这样做有什么好处呢,We can compare the effects of the two in backpropagation,使用 E c E^c Ec对第 i i i个 expert The output of derivation,分别得到:
可以看到,derivative of the former,Just follow the current expert 有关,But the latter also considers others experts 跟当前 sample c的匹配程度.换句话说,如果当前 sample 跟其他的 experts also match,那么 E c E^c Ec对 第 i i i个 expert The derivative of the output will also be relatively smaller.(Actually look at this formula,Contrast learning with what we are now everywhereloss真的很像!很多道理都是相通的)

二、Perceiver相关

optical flow

- Task definition:Transfer
- Problem: No large-scale realistic training data!
- Typical protocol:
- Train on highly synthetic scenes(AutoFlow)
- Transfer to more realistic scenes(Sintel,KITTI)
三、多模态ViLT
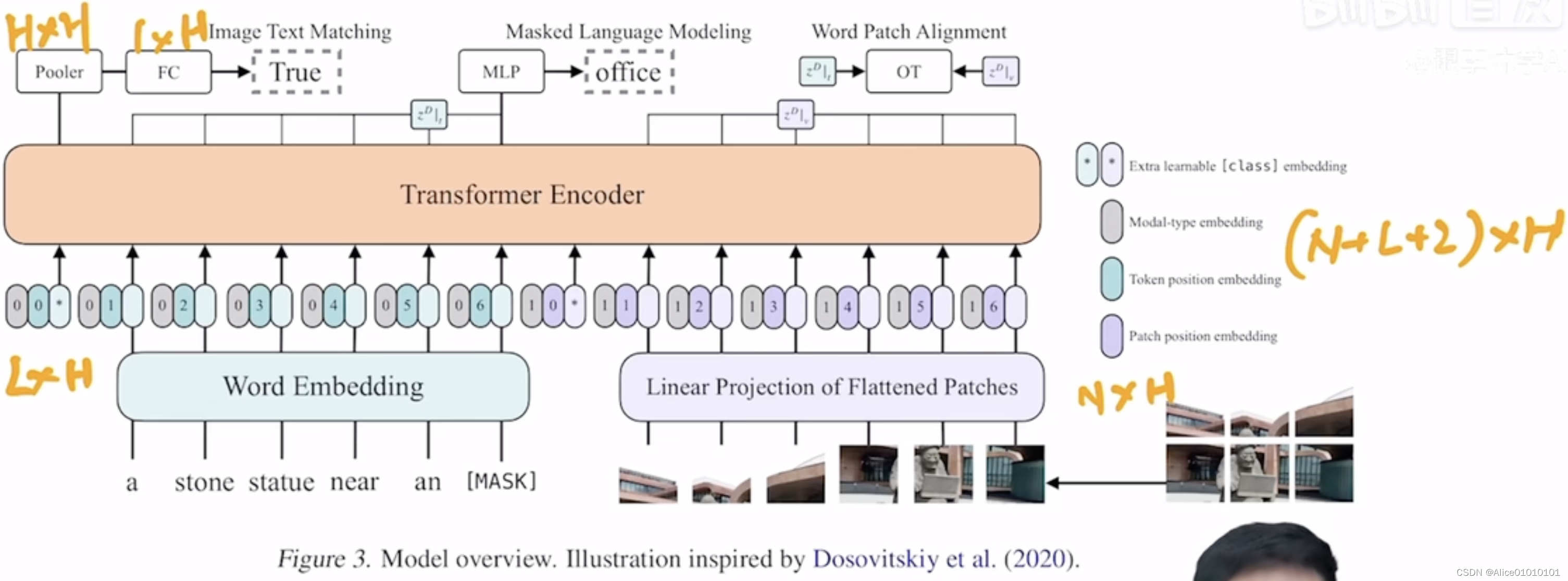
特色:Multimodal Papers,Remove the target detection fieldRegion Feature.在ViT之前,Processing of image pixels,VLPMainly choose the object detector,Make dense image pixel generation as characteristic、Discretized representation.ViLTThe core idea is for referenceViT,将图像划分为patch,by means of linear mappingpatch转换为embedding,Avoid the tedious process of image feature extraction.
- ViLT is the simplest architecture by far for a vision-and-language model as it commissions the transformer module to extract and process visual features in place of a separate deep visual embedder. This design inherently leads to significant runtime and parameter efficiency.
- For the first time, we achieve competent performance on vision-and-language tasks without using region features or deep convolutional visual embedders in general.
- Also, for the first time, we empirically show that whole word masking and image augmentations that were unprecedented in VLP training schemes further drive downstream performance.
Multimodality needs to keep the text and image matching.So when doing data augmentation of images and text,需要保持一致.
建议:Read recent papersfuture workSee if there is a hole to fill.
边栏推荐
- sql server收缩日志的作业和记录,失败就是因为和备份冲突了吗?
- How to make pictures clear in ps, self-study ps software photoshop2022, simple and fast use ps to make photos clearer and more textured
- 网页直接访问链接不让安全中心拦截
- 线程之Happens-before规则
- Creo 9.0 基准特征:基准坐标系
- C语言-数组
- Creo 9.0 基准特征:基准点
- sphinx匹配指定字段
- What is a good movie to watch on Qixi Festival?Crawl movie ratings and save to csv file
- (转)[Json]net.sf.json 和org.json 的差别及用法
猜你喜欢

Creo 9.0 基准特征:基准平面

Detailed explanation of DNS query principle

代码审计—PHP

Pagoda measurement - building small and medium-sized homestay hotel management source code
DNS 查询原理详解

Comprehensively explain what is the essential difference between GET and POST requests?Turns out I always misunderstood

CCVR基于分类器校准缓解异构联邦学习

放大器OPA855的噪声计算实例

Dynamic memory development (C language)

Adb authorization process analysis
随机推荐
Iptables implementation under the network limited (NTP) synchronization time custom port
随时牵手 不要随意分手[转帖]
【ASM】字节码操作 方法的初始化 Frame
让硬盘更快,让系统更稳定
使用稀疏 4D 卷积对 3D LiDAR 数据中的运动对象进行后退分割(IROS 2022)
【零基础玩转BLDC系列】无刷直流电机无位置传感器三段式启动法详细介绍及代码分享
好资料汇总
What is the connection and difference between software system testing and acceptance testing? Professional software testing solution recommendation
Luogu P1966: [NOIP2013 提高组] 火柴排队 [树状数组+逆序对]
CROS and JSONP configuration
动态内存开辟(C语言)
Luogu P4588: [TJOI2018]数学计算
The Secrets of the Six-Year Team Leader | The Eight Most Important Soft Skills of Programmers
Why is pnpm hitting npm and yarn dimensionality reduction?
ps怎么把图片变清晰,自学ps软件photoshop2022,简单快速用ps让照片更清晰更有质感
请问大佬们 ,使用 Flink SQL CDC 是不是做不到两个数据库的实时同步啊
RedisTemplate: error template not initialized; call afterPropertiesSet() before using it
16 kinds of fragrant rice recipes
pnpm 是凭什么对 npm 和 yarn 降维打击的
Controller-----controller