当前位置:网站首页>[code analysis (5)] communication efficient learning of deep networks from decentralized data
[code analysis (5)] communication efficient learning of deep networks from decentralized data
2022-04-23 13:47:00 【Silent city of the sky】
models.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Python version: 3.6
from torch import nn
import torch.nn.functional as F
class MLP(nn.Module):
'''
MLP Model
General code
'''
def __init__(self, dim_in, dim_hidden, dim_out):
super(MLP, self).__init__()
'''
Defined function
torch.Linear() Set up the full connection layer in the network
'''
self.layer_input = nn.Linear(dim_in, dim_hidden)
self.relu = nn.ReLU()
self.dropout = nn.Dropout()
self.layer_hidden = nn.Linear(dim_hidden, dim_out)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
'''
It can't be written like this :
nn.ReLU(input)
It should be written like this :
relu = nn.ReLU()
input = relu(input)
'''
x = x.view(-1, x.shape[1]*x.shape[-2]*x.shape[-1])
'''
1.torch.randn()
torch.randn Is a random variable with standard normal distribution
# Assume that the input image shape is [64,64,3]
input = torch.randn(1,3,4,4)
Express
The first parameter :batch_size by 1
The second parameter :3 Indicates that the channel picture is RGB Color picture
The third parameter and the fourth parameter :
Picture size is 4*4
x.shape[1]*x.shape[-2]*x.shape[-1]
Express 3*4*4
Input the image as [4,4,3]
2.x.view(-1,)
For example, a length of 16 vector x,
x.view(-1, 4) Equivalent to x.view(4, 4)
x.view(-1, 2) Equivalent to x.view(8,2)
The length is 48 Vector
So for the above x=x.view(-1,48)
Equivalent to x.view(1,48)
'''
x = self.layer_input(x)
'''
Send it to the network
layer_input = nn.Linear(dim_in, dim_hidden)
'''
x = self.dropout(x)
x = self.relu(x)
x = self.layer_hidden(x)
'''
The process analysis is in test.py
'''
return self.softmax(x)
class CNNMnist(nn.Module):
def __init__(self, args):
super(CNNMnist, self).__init__()
self.conv1 = nn.Conv2d(args.num_channels, 10, kernel_size=5)
'''
torch.nn.Conv2d
(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
in_channels: Number of input image channels
out_channels: The number of channels generated by convolution
kernel_size: Convolution kernel size , Can be set as 1 individual int Type number or one (int, int) Tuples of type
stride: Convolution step , The default is 1. Can be set as 1 individual int Type number or one (int, int) Tuples of type .
x = torch.randn(3,1,4,4)
x[ batch_size, channels, height_1, width_1 ]
batch_size, One batch Number of samples in 3
channels, The channel number , That is, the depth of the current layer 1
height_1, Picture height 4
width_1, Picture width 4
conv = torch.nn.Conv2d(1,4,(2,2))
****************************
channels, The channel number , Same as above , That is, the depth of the current layer 1
output , Depth of output 4【 need 4 individual filter】
height_2, The height of the convolution kernel 2
width_2, The width of the convolution kernel 2
res = conv(x)
res[ batch_size,output, height_3, width_3 ]
batch_size,, One batch The number of samples in , ditto 3
output, Depth of output 4
height_3, Convolution height 3
width_3, The width of the convolution result 3
'''
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
'''
After convolution torch.Tensor Dimension for 1*320
torch.Tensor
'''
self.fc2 = nn.Linear(50, args.num_classes)
'''
Through the second full connection layer, the output dimension 1*10
'''
'''
# 1 Is the number of picture channels
# Local batch_size=10
x = torch.randn(1, 1, 28, 28)
# x = x.view(-1, x.shape[1]*x.shape[-2]*x.shape[-1])
# print(x.shape):(10, 1, 28, 28)->torch.Size([10, 784])
# (1, 1, 28, 28)->torch.Size([1, 784])
# 1 Is the number of input image channels ,10 Is the number of output image channels
# need 10 A convolution kernel will output 10 The result of two channels
conv1 = nn.Conv2d(1, 10, kernel_size=5) # num_channels Passageway is 1, Colorless graph
# 10 Is the number of input image channels ,20 Is the number of output image channels
conv2 = nn.Conv2d(10, 20, kernel_size=5)
# dropout
conv2_drop = nn.Dropout2d()
# The first full connection layer , 320 Enter a dimension for ,50 Output dimensions for the full connectivity layer
fc1 = nn.Linear(320, 50)
# The second full connection layer
fc2 = nn.Linear(50, 10) # args.num_classes
# After full connection and other processes 1*320 # 320*50 = 1*50, 1*50 # 50*10 = 1*10
'''
def forward(self, x):
'''
x=x = torch.randn(1, 1, 28, 28)
One sample picture at a time
batch_size=1
28×28 after conv1->24×24 after max_pool->12×12
12×12 after conv2->8×8 after max_pool->4×4
At this time, the number of channels 20
Before entering the full connection layer is :20*4*4
to pave nicely x by 1*320
Through the first layer, the whole connection layer (320*50) x by 1*50
Through the second layer, the whole connection layer (50*10) x by 1*10
Last pass softmax Take the logarithm again log
'''
'''
F.dropout It's actually torch.nn.functional.dropout
'''
x = F.relu(F.max_pool2d(self.conv1(x), 2))
''''
Halve the dimension , step stride by 2
'''
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
'''
28×28 after conv1->24×24 after max_pool->12×12
12×12 after conv2->8×8 after max_pool->4×4
At this time, the number of channels 20
'''
x = x.view(-1, x.shape[1]*x.shape[2]*x.shape[3])
'''
torch.Tensor Pave for 1×320
'''
x = F.relu(self.fc1(x))
'''
The first full connection layer , 320 Enter a dimension for ,50 Output dimensions for the full connectivity layer
Output x by 1×50
'''
x = F.dropout(x, training=self.training)
'''
When training When it's true , Will set some elements to 0,
Other elements will be multiplied by scale 1/(1-p)
F.dropout(input,p=0.5, training = True)
By default, half of them are dropout namely p=0.5
'''
x = self.fc2(x)
'''
The second full connection layer , 50 Enter a dimension for ,10 Output dimensions for the full connectivity layer
Output x by 1×10
'''
return F.log_softmax(x, dim=1)
class CNNFashion_Mnist(nn.Module):
def __init__(self, args):
super(CNNFashion_Mnist, self).__init__()
'''
1.torch.nn.MaxPool2d and torch.nn.functional.max_pool2d
nn.MaxPool2d(2)) Written in nn.Sequential() Inside
amount to torch.nn.MaxPool2d()
2.torch.nn.MaxPool2d In their own forward() Method is called
torch.nn.functional.max_pool2d.
The two are essentially the same
3.import torch.nn.functional as F
torch.nn.functional.max_pool2d As a function, you can call
Pass in the parameter (input( Four dimensions (***4D***) The input tensor of ), kernel_size( Convolution kernel size )
stride( Stride ),padding( fill ) wait
F.max_pool2d(self.conv1(x), 2)
2 by kernel_size
4.torch.nn.MaxPool2d, First instantiate , And in its own class
forward Called torch.nn.functional.max_pool2d function .
5. once
We usually first pooling Again relu
but relu and maxpooling, If you look at them as operators ,
Are insensitive to order , That is, exchangeable .
'''
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2)) # from torch import nn
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2))
self.fc = nn.Linear(7*7*32, 10)
'''
6.
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True, device=None, dtype=None)
effect : Yes 4D Input ( With additional channel dimensions 2D Enter a small batch ) Apply batch normalization
1e-05==0.00001
(1) Input data format :batch_size ,num_features , height , width
num_features by channel Count
(2)affine A Boolean value , When set to True when , This module has learnable affine parameters .
γ(gamma) and β(beta) ( Learnable affine transformation parameters )
The default value is :True
(3) Before model training , The data need to be normalized , Make it uniformly distributed .
In the process of deep neural network training , Usually a workout is a batch, Not all data .
Every batch Having different distributions produces internal covarivate shift
problem —— In the process of training , The data distribution will change , Learning from the next layer of network
Bring difficulties .Batch Normalization Force the data back to the mean value of 0,
The variance of 1 On the normal distribution of ,
On the one hand, it makes the data distribution consistent ,
On the other hand, avoid the disappearance of the gradient .
x = torch.randn(1, 1, 28, 28)
'''
def forward(self, x):
'''
1*1*28*28 after padding=2
1*1*32*32 Through the convolution layer
1*16*28*28 after pooling
1*16*14*14 after padding=2
1*16*18*18 Through the convolution layer
1*32*14*14 after pooling
1*32*7*7
'''
out = self.layer1(x)
out = self.layer2(out)
'''
Through the convolution layer :1*32*7*7
1*448
'''
out = out.view(out.size(0), -1)
'''
16
x.view(-1, 4) Equivalent to x.view(4, 4)
x.view(-1, 2) Equivalent to x.view(8,2)
The length is 48 Vector
So for the above x=x.view(-1,48)
Equivalent to x.view(1,48)
7*7*32
out.view(out.size(0), -1)
Equivalent to :
out.view(out.size(0), 1)
out.view(1, 448)
'''
out = self.fc(out)
'''
The full connection layer defined above is :
nn.Linear(448, 10)
After passing through the full connection layer tensor Turn into
1*10
[,,,,,,,,,]
'''
return out
'''
CIFAR-10 The size of the picture is 32 x 32,
Slightly greater than MNIST Of 28 x 28 CIFAR-10 The proportions and characteristics of objects in the are different ,
It's noisy , Difficult to identify MNIST high
MNIST It's black and white
Cifar It's color
Passageway is RGB==3
'''
class CNNCifar(nn.Module):
def __init__(self, args):
super(CNNCifar, self).__init__()
'''
(1)nn.Conv2d(3, 6, 5)
Convolution kernel channel is 3
The output channel is 6
Convolution kernel size 5*5
(2)nn.MaxPool2d(2, 2)
Pooled convolution kernel size 2*2
In steps of 2
'''
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5) # There's nothing less down there ?
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, args.num_classes)
def forward(self, x):
'''
CIFAR-10 Data set containing 60000 Zhang 32x32 The color picture of , Will be divided into 10 Species category , Each category 6000 Zhang
'''
'''
(1) Convolution formula
1 + int((H-F+2p)/s)
(2) Pooling formula
1 + int((H-H_filter)/s)
1*3*32*32 Through the convolution layer 32-5+1, The denominator is step size =1
1*6*28*28 after pooling (28-2)/2 + 1 = 14 x = self.pool(F.relu(self.conv1(x)))
1*6*14*14 Through the convolution layer
1*16*10*10 after pooling
1*16*5*5 x = self.pool(F.relu(self.conv2(x)))
'''
x = self.pool(F.relu(self.conv1(x)))
# print('0000000000000000000000000000000')
# print(x.size(0))
# print(x.size(1))
# print(x.size(2))
# print(x.size(3))
x = self.pool(F.relu(self.conv2(x)))
# print('0000000000000000000000000000000')
# print(x.size(0))
# print(x.size(1))
# print(x.size(2))
# print(x.size(3))
x = x.view(-1, 16 * 5 * 5)
'''
x = x.view(-1, 16 * 5 * 5)
amount to :
x = x.view(10, 16 * 5 * 5)
here x.size(0)=10
'''
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
'''
The input of this experiment is 10*3*32*32
batch_size=10
Put... All at once 10 Two samples enter the neural network training
After convolution, it is :
(10, 400)
Through the first layer, the whole connection layer ;(400, 120)
(10, 120)
Through the second layer, the whole connection layer ;(120, 84)
(10, 84)
Through the third floor ;(84, 10)
(10, 10)
(10,10) What does it look like ?
tensor([ [],[],[],[],[],[],[],[],[],[] ])
'''
return F.log_softmax(x, dim=1)
版权声明
本文为[Silent city of the sky]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204230556365723.html
边栏推荐
- Solve tp6 download error course not find package topthink / think with stability stable
- Information: 2021 / 9 / 29 10:01 - build completed with 1 error and 0 warnings in 11S 30ms error exception handling
- Apache Atlas Compilation and installation records
- 函数只执行第一次的执行一次 once函数
- Operations related to Oracle partition
- Analysis of redo log generated by select command
- QT calling external program
- Use future and countdownlatch to realize multithreading to execute multiple asynchronous tasks, and return results after all tasks are completed
- Analysis of cluster component gpnp failed to start successfully in RAC environment
- Resolution: argument 'radius' is required to be an integer
猜你喜欢

Oracle defines self incrementing primary keys through triggers and sequences, and sets a scheduled task to insert a piece of data into the target table every second

【重心坐标插值、透视矫正插值】原理以及用法见解

Leetcode? The first common node of two linked lists

零拷贝技术

Double pointer instrument panel reading (I)
![MySQL [acid + isolation level + redo log + undo log]](/img/52/7e04aeeb881c8c000cc9de82032e97.png)
MySQL [acid + isolation level + redo log + undo log]
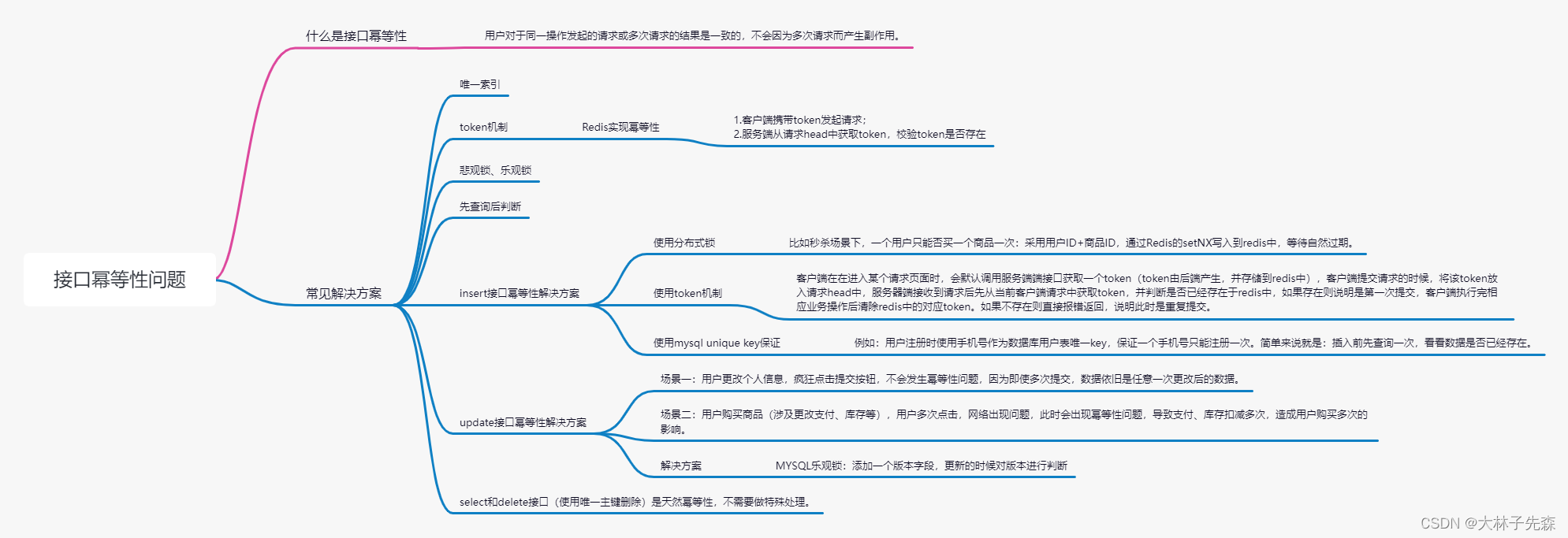
Interface idempotency problem
自动化的艺术

为什么从事云原生开发需要学习容器技术

The query did not generate a result set exception resolution when the dolphin scheduler schedules the SQL task to create a table
随机推荐
Leetcode? The first common node of two linked lists
Oracle creates tablespaces and modifies user default tablespaces
Exemple de méthode de réalisation de l'action d'usinage à point fixe basée sur l'interruption de déclenchement du compteur à grande vitesse ob40 pendant le voyage de tia Expo
Special window function rank, deny_ rank, row_ number
PG library checks the name
Modification of table fields by Oracle
The query did not generate a result set exception resolution when the dolphin scheduler schedules the SQL task to create a table
Analysis of redo log generated by select command
Publish custom plug-ins to local server
SSM project deployed in Alibaba cloud
Storage scheme of video viewing records of users in station B
MySQL [SQL performance analysis + SQL tuning]
Oracle view related
kettle庖丁解牛第16篇之输入组件周边讲解
Utilisation de GDB
Parameter comparison of several e-book readers
Analysis of unused index columns caused by implicit conversion of timestamp
Leetcode brush question 𞓜 13 Roman numeral to integer
Opening: identification of double pointer instrument panel
Zero copy technology