当前位置:网站首页>从斐波那契 - 谈及动态规划 - 优化
从斐波那契 - 谈及动态规划 - 优化
2022-08-10 21:23:00 【i_erlich】
最开始学习递归,经典算法就是斐波那契

你是否留意过它的算法复杂度如何
复杂度分析
在这里我们忘掉意识里已有的复杂度观念,从最基础代码分析
我们把 代码执行的行数 作为时间复杂度
fibonacci(3)
- fibonacci(1) 占一行代码
- fibonacci(2) 占一行代码
- fibonacci(1) 调用 return 1,占一行代码
- fibonacci(2) 调用 return 1,占一行代码
因此 fibonacci(3) 总共执行了4行代码,复杂度就是具体的4次
可以看出,重要不是 fibonacci(1) 或 fibonacci(2),暂时也不考虑具体中间递归调度过程
只看最直接的调度,执行两行代码,这有助于后面的分析
以fibonacci(5)计算为例,我们把整个过程平摊开来
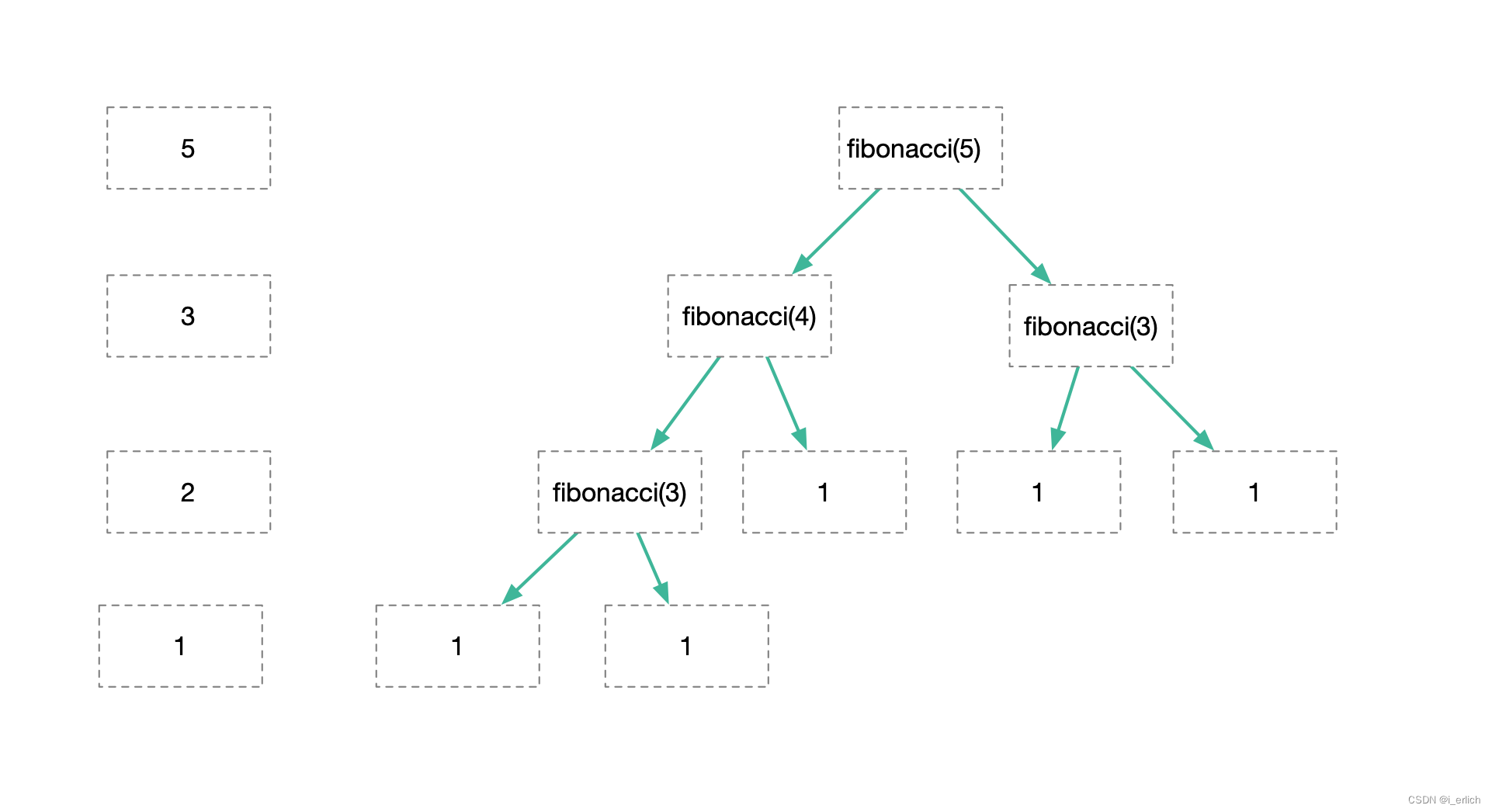
- 最终 return 1的代码执行是 5次,也就是 图中二叉树结构的叶子结点个数,正好是fibonacci(5)的结果
- 非叶子节点 个数为 5 - 1,比叶子结点个数少1个
- 除了叶子节点,每个节点执行的代码行数为两行
fibonacci(5) 总共执行的代码行数 = 5个叶子结点 + 4个非叶子结点 * 2
- 5个叶子节点 return 1, 正好也是 fibonacci(5)结果
- 4个非叶子结点 * 2,是因为每个非叶子结点直接执行两行代码,正如前面分析的那样
整理之后 fibonacci(5) 总共执行的代码行数 = fibonacci(5) + (fibonacci(5) - 1) * 2
最终的到 fibonacci函数复杂度:
F(n) = 3 * fibonacci(n) - 2
如果 n == 5, 最终执行了13行代码,也就是复杂度 13次
这样不会觉得有什么问题
如果 n = 50, 数据太大,整型溢出,换n = 30, 复杂度 832040 * 3 - 2,2 * 10^6, 这是一个很高的复杂度了
简化fibonacci执行次数
fibonacci 递归,期间经历很多重复的递归计算,如果我们把一些中间过程缓存起来,就能省去很多不必要的计算

统计代码执行行数: 3 + (n - 2 + 1)[for] + n - 2 = 2n
按之前的n = 30, 与简化前的版本比较 就是 60 与 2 * 10^6 差别,复杂度差出5个数量级
已经有点动态规划的思想在这个简化版本里了
但存在一个问题,复杂度降低了,却开辟了很多内存,
数据特别大超出平时脑子里意识的时候,虽然时间复杂度比较可观,但是需要庞大的内存开销作为代价,甚至可能算法都执行不起来
减少内存空间开辟
简化的版本,用到了 n+1 个整型内存空间,主要的执行部分逻辑,其实只涉及两个需要的变量,可以省去额外的内存开销
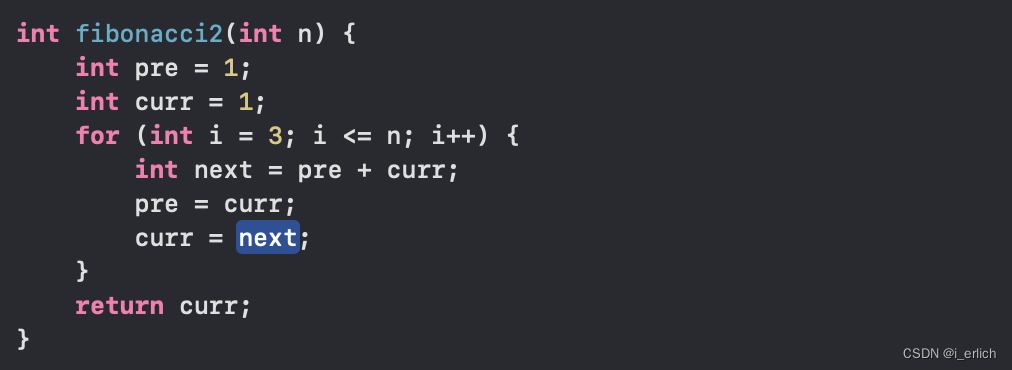
稍微对比下 修正后的简化版本,与初始的递归版本
就是 n 与 10^6的差别
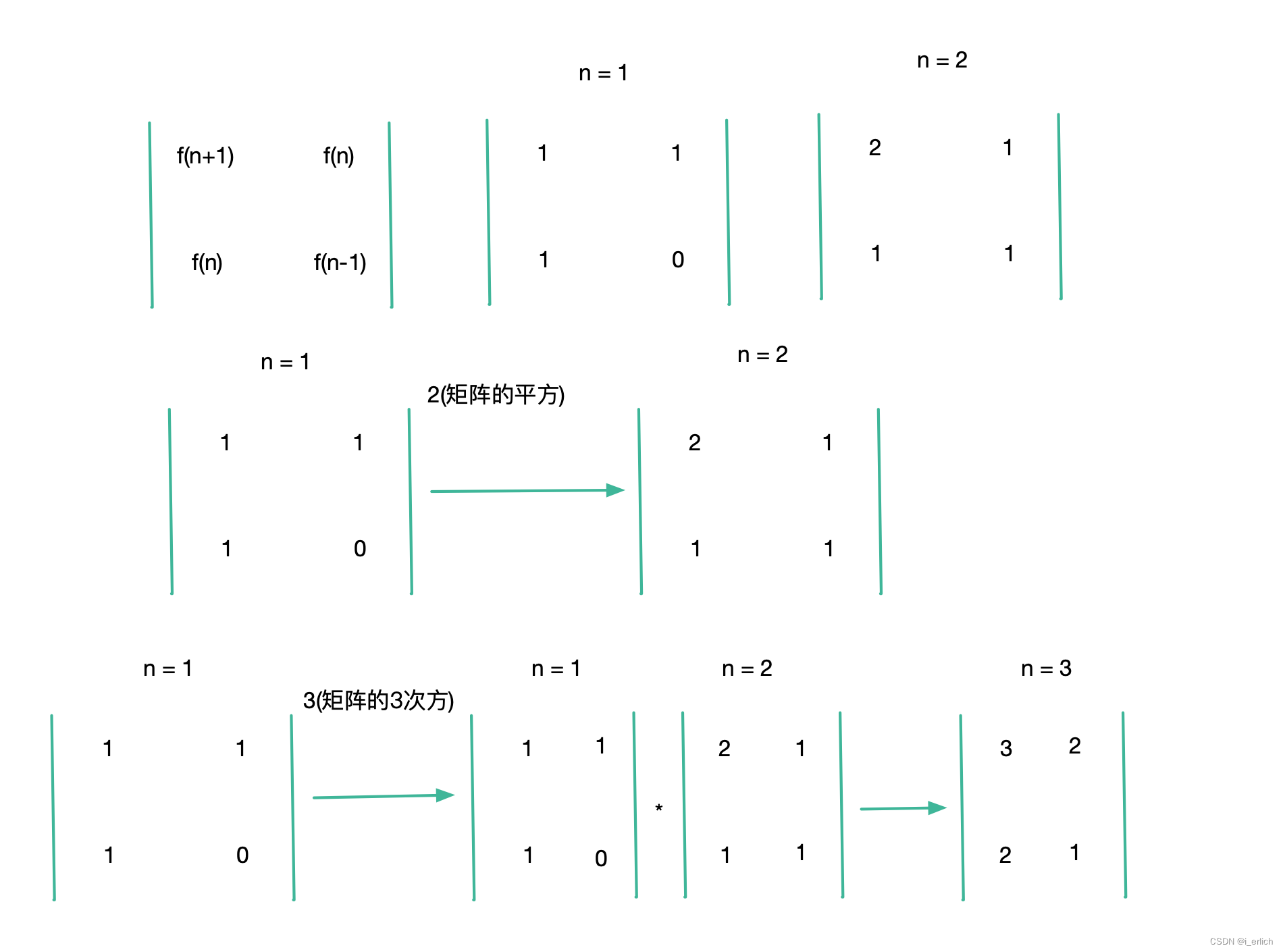
- n = 1代表 第一个索引,索引从1开始
- 矩阵的平方 就是 矩阵与自己相乘
- 矩阵的立方 可以换为 矩阵 * 矩阵的平方
- 矩阵的乘法
- 矩阵用大写字母表示
- Rij 表示 第i行第j列上的元素
- Rij = Ai0 * B0j + Ai1 * B1j, 也就是i行j列位置的元素 = A矩阵的i行 与 B矩阵的j列上的每个元素相乘之后 再相加一起 得到的结果
算法也许是个很枯燥的过程,但如果善于运用工具,比如fibonacci利用矩阵,就很好的体现了代码的执行过程 矩阵相乘包含着前两项的相加过程
追踪矩阵的 第(0,0)元素,就得到 fibonacci(n)的结果
struct matrix_struct {
int matrix[2][2];
};
// 两个 2x2 矩阵相乘
void matrixMultiply(struct matrix_struct matrix_structA,
struct matrix_struct *matrix_structB) {
struct matrix_struct matrix_structX;
matrix_structX.matrix;
for (int i = 0; i < 2; i++) {
for (int j = 0; j < 2; j++) {
matrix_structX.matrix[i][j]
= matrix_structA.matrix[i][0] * matrix_structB->matrix[0][j]
+ matrix_structA.matrix[i][1] * matrix_structB->matrix[1][j];
}
}
*matrix_structB = matrix_structX;
}
// 矩阵的平方运算
// n: 矩阵与初始矩阵执行 n次相乘运算,每次相乘之后,结果替换掉原矩阵 执行下一次相乘
// matrix: 2行2列的矩阵
void matrixPower(int n, struct matrix_struct *matrix_structY) {
struct matrix_struct matrix_structX;
matrix_structX.matrix[0][0] = 1;
matrix_structX.matrix[0][1] = 1;
matrix_structX.matrix[1][0] = 1;
matrix_structX.matrix[1][1] = 0;
for (int i = 0; i < n; i++) {
matrixMultiply(matrix_structX, matrix_structY);
}
}
int fibonacci3(int n) {
if (n < 2) {
return n;
}
struct matrix_struct matrix_structInit;
matrix_structInit.matrix[0][0] = matrix_structInit.matrix[1][1] = 1;
matrix_structInit.matrix[0][1] = matrix_structInit.matrix[1][0] = 0;
struct matrix_struct *matrix_structI = &matrix_structInit;
// 其中第一次相乘 的到 初始 矩阵
matrixPower(n - 1, matrix_structI);
return matrix_structI->matrix[0][0];
}
这个版本并没有不合适的内存问题
接下来继续分析是执行次数,也就是时间复杂度
matrixPower for循环还是n,所以复杂度继续保持在n这个数量级,与之前的版本没多大差别
复杂度继续优化
根据 矩阵的平方运算 matrixPower,执行了n次
其实也就是矩阵 (1,1,1,0)【标识 两行两列, 第一行: 1,1 ,第二行: 1,0】 执行了n次相乘
我们可以考虑减少 相乘计算的次数,比如16次相乘,其实就是 4次相乘结果的平方
void matrixPowerEnhance(int n, struct matrix_struct *matrix_structY) {
if (n > 1) {
matrixPower(n / 2, matrix_structY);
matrixMultiply(*matrix_structY, matrix_structY);
}
if (n & 0x1) {
// n奇数
struct matrix_struct matrix_structX;
matrix_structX.matrix[0][0] = 1;
matrix_structX.matrix[0][1] = 1;
matrix_structX.matrix[1][0] = 1;
matrix_structX.matrix[1][1] = 0;
matrixMultiply(matrix_structX, matrix_structY);
}
}
折半操作还可以持续重复,因为折半收敛非常快
struct matrix_struct matrixMultiply1(struct matrix_struct matrix_structA,
struct matrix_struct matrix_structB) {
struct matrix_struct matrix_structX;
for (int i = 0; i < 2; i++) {
for (int j = 0; j < 2; j++) {
matrix_structX.matrix[i][j]
= matrix_structA.matrix[i][0] * matrix_structB.matrix[0][j]
+ matrix_structA.matrix[i][1] * matrix_structB.matrix[1][j];
}
}
return matrix_structX;
}
struct matrix_struct matrixPowerEnhance1(int n,
struct matrix_struct matrix_structY) {
struct matrix_struct result = matrix_structY;
if (n > 1) {
result = matrixPowerEnhance1(n / 2, matrix_structY);
result = matrixMultiply1(result, result);
if (n & 0x1) {
// n奇数
struct matrix_struct matrix_structX;
matrix_structX.matrix[0][0] = 1;
matrix_structX.matrix[0][1] = 1;
matrix_structX.matrix[1][0] = 1;
matrix_structX.matrix[1][1] = 0;
result = matrixMultiply1(matrix_structX, result);
}
return result;
}
struct matrix_struct matrix_structX;
matrix_structX.matrix[0][0] = 1;
matrix_structX.matrix[0][1] = 1;
matrix_structX.matrix[1][0] = 1;
matrix_structX.matrix[1][1] = 0;
return matrixMultiply1(matrix_structX, matrix_structY);
}
虽然递归了,但是每次递归的作用是为了 折半
如此 原来的执行次数n 做了个折扣处理,2^t = n
即 t = log(n)
时间复杂度变为了 log(n)
总结
通过最基础的斐波那契,我们可以先通过自己的理解,在自己能力范围内先实现算法
在实现的基础上分析复杂度问题
在自己实现的版本基础上发现可优化的点,比如常规的递归实现,包含了大量的重复执行,去掉不必要的执行,其实就是在优化算法了
算法的复杂度优化是一步步循序渐进完善的,并非一蹴而就,也不是刷多少算法能解决的,其实是一种本质的思维方式
没有什么高深的点,守得住耐心,总会找到完善的空间
不抛弃底层的本质思维,不眼高手低,慢慢就会触及到一些思想的门槛,比如文章中的优化思路就摸到了 动态规划的思想
有了这个引子,再去看一些算法思想,看别人的实现,才会深有体会,不致于过眼烟云
边栏推荐
猜你喜欢

Kerberos认证

shell编程之正则表达式与文本处理器

带你一文读懂SaaS版多租户商城系统对多品牌企业的应用价值
什么是Jmeter?Jmeter使用的原理步骤是什么?
直播课堂系统08-腾讯云对象存储和课程分类管理
JVM classic fifty questions, now the interview is stable
LeetCode-36-Binary search tree and doubly linked list
C#【必备技能篇】Hex文件转bin文件的代码实现

RADIUS Authentication Server Deployment Costs That Administrators Must Know

黑猫带你学Makefile第13篇:Makefile编译问题合集
随机推荐
Redis Command Manual
F. Binary String Reconstruction
Bedtime story | made a Bitmap and AST length system configuration
社区分享|货拉拉通过JumpServer纳管大规模云上资产
黑猫带你学Makefile第12篇:常见Makefile问题汇总
C. Social Distance
2022.8.9 模拟赛
PROCEDURE :存储过程结构——《mysql 从入门到内卷再到入土》
B. Same Parity Summands
Shell编程之条件语句(二)
力扣221题,最大正方形
xshell (sed 命令)
Labelme-5.0.1 version edit polygon crash
ES6中的for...in/of的使用
Web Reverse Lilac Garden
MySQL高级指令
关于 DataFrame: 处理时间
我的世界整合包 云服务器搭建方法(ECS)
每次打开chrome会跳出What's new
【PCBA solution】Electronic grip strength tester solution she'ji