当前位置:网站首页>memcached 源码分析
memcached 源码分析
2022-04-23 05:58:00 【魏言华】
1.Memcached概述
memcached是一个高性能的分布式内存缓存服务器,memcached在Linux上可以通过yum命令安装,这样方便很多,在生产环境下建议用Linux系统,memcached使用libevent这个库在Linux系统上才能发挥它的高性能。它的分布式其实在服务端是不具有分布式的特征的,是依靠客户端的分布式算法进行了分布式,memcached是一个纯内存型的数据库,这样在读写速度上相对来说比较快。

MemCache虽然被称为分布式缓存,但是MemCache本身完全不具备分布式的功能,MemCache集群之间不会相互通信(与之形成对比的,比如JBoss Cache,某台服务器有缓存数据更新时,会通知集群中其他机器更新缓存或清除缓存数据),所谓的分布式,完全依赖于客户端程序的实现,就像上面这张图的流程一样。
| 命 令 |
作 用 |
| get |
返回Key对应的Value值 |
| add |
添加一个Key值,没有则添加成功并提示STORED,有则失败并提示NOT_STORED |
| set |
无条件地设置一个Key值,没有就增加,有就覆盖,操作成功提示STORED |
| replace |
按照相应的Key值替换数据,如果Key值不存在则会操作失败 |
| stats |
返回MemCache通用统计信息 |
| stats items |
返回各个slab中item的数目和最老的item的年龄 |
| stats slabs |
返回MemCache运行期间创建的每个slab的信息 |
| version |
返回当前MemCache版本号 |
| flush_all |
清空所有键值,但不会删除items,所以此时MemCache依旧占用内存 |
| quit |
关闭连接 |
2.memcached内存管理
MemCache的数据存放在内存中,存放在内存中认为意味着几点:
1)访问数据的速度比传统的关系型数据库要快,因为Oracle、MySQL这些传统的关系型数据库为了保持数据的持久性,数据存放在硬盘中,IO操作速度慢
2)MemCache的数据存放在内存中同时意味着只要MemCache重启了,数据就会消失
3)既然MemCache的数据存放在内存中,那么势必受到机器位数的限制,32位机器最多只能使用2GB的内存空间,64位机器可以认为没有上限
MemCache采用的内存分配方式是固定空间分配

这里面涉及了slab_class、slab、page、chunk四个概念,它们之间的关系是:
1)MemCache将内存空间分为一组slab
2)每个slab下又有若干个page,每个page默认是1M,如果一个slab占用100M内存的话,那么这个slab下应该有100个page
3)每个page里面包含一组chunk,chunk是真正存放数据的地方,同一个slab里面的chunk的大小是固定的
4)有相同大小chunk的slab被组织在一起,称为slab_class
MemCache内存分配的方式称为allocator,slab的数量是有限的,几个、十几个或者几十个,这个和启动参数的配置相关。MemCache中的value过来存放的地方是由value的大小决定的,value总是会被存放到与chunk大小最接近的一个slab中,比如slab[1]的chunk大小为80字节、slab[2]的chunk大小为100字节、slab[3]的chunk大小为128字节(相邻slab内的chunk基本以1.25为比例进行增长,MemCache启动时可以用-f指定这个比例),那么过来一个88字节的value,这个value将被放到2号slab中。放slab的时候,首先slab要申请内存,申请内存是以page为单位的,所以在放入第一个数据的时候,无论大小为多少,都会有1M大小的page被分配给该slab。申请到page后,slab会将这个page的内存按chunk的大小进行切分,这样就变成了一个chunk数组,最后从这个chunk数组中选择一个用于存储数据。
如果这个slab中没有chunk可以分配了怎么办,如果MemCache启动没有追加-M(禁止LRU,这种情况下内存不够会报Out Of Memory错误),那么MemCache会把这个slab中最近最少使用的chunk中的数据清理掉,然后放上最新的数据。针对MemCache的内存分配及回收算法,总结三点:
1)MemCache的内存分配chunk里面会有内存浪费,88字节的value分配在128字节(紧接着大的用)的chunk中,就损失了30字节,但是这也避免了管理内存碎片的问题
MemCache的LRU算法不是针对全局的,是针对slab的
2)应该可以理解为什么MemCache存放的value大小是限制的,因为一个新数据过来,3)slab会先以page为单位申请一块内存,申请的内存最多就只有1M,所以value大小自然不能大于1M了
2.1MemCache的特性和限制
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2.2 slab内存管理
2.2.1 item 数据存储节点
typedef struct _stritem {
/* Protected by LRU locks */
//一个item的地址, 主要用于LRU链和freelist链
struct _stritem *next;
//下一个item的地址,主要用于LRU链和freelist链
struct _stritem *prev;
/* Rest are protected by an item lock */
//用于记录哈希表槽中下一个item节点的地址
struct _stritem *h_next; /* hash chain next */
//最近访问时间
rel_time_t time; /* least recent access */
//缓存过期时间
rel_time_t exptime; /* expire time */
int nbytes; /* size of data */
//当前item被引用的次数,用于判断item是否被其它的线程在操作中
//refcount == 1的情况下该节点才可以被删除
unsigned short refcount;
uint8_t nsuffix; /* length of flags-and-length string */
uint8_t it_flags; /* ITEM_* above */
//记录该item节点位于哪个slabclass_t中
uint8_t slabs_clsid;/* which slab class we're in */
uint8_t nkey; /* key length, w/terminating null and padding */
/* this odd type prevents type-punning issues when we do
* the little shuffle to save space when not using CAS. */
union {
uint64_t cas;
char end;
} data[];
/* if it_flags & ITEM_CAS we have 8 bytes CAS */
/* then null-terminated key */
/* then " flags length\r\n" (no terminating null) */
/* then data with terminating \r\n (no terminating null; it's binary!) */
} item;slab与chunk
slab是一块内存空间,默认大小为1M,memcached会把一个slab分割成一个个chunk, 这些被切割的小的内存块,主要用来存储item
slabclass
每个item的大小都可能不一样,item存储于chunk,如果chunk大小不够,则不足以分配给item使用,如果chunk过大,则太过于浪费内存空间。因此memcached采取的做法是,将slab切割成不同大小的chunk,这样就满足了不同大小item的存储。被划分不同大小chunk的slab的内存在memcached就是用slabclass这个结构体来表现的
typedef struct {
unsigned int size; /* sizes of items */
unsigned int perslab; /* how many items per slab */
void *slots; /* list of item ptrs */
unsigned int sl_curr; /* total free items in list */
unsigned int slabs; /* how many slabs were allocated for this class */
void **slab_list; /* array of slab pointers */
unsigned int list_size; /* size of prev array */
} slabclass_t;


1)slabclass数组初始化的时候,每个slabclass_t都会分配一个1M大小的slab,slab会被切分为N个小的内存块,这个小的内存块的大小取决于slabclass_t结构上的size的大小
2)每个slabclass_t都只存储一定大小范围的数据,并且下一个slabclass切割的chunk块大于前一个slabclass切割的chunk块大小
3)memcached中slabclass数组默认大小为64,slabclass切割块大小的增长因子默认是1.25
例如:slabclass[1]切割的chunk块大小为100字节,slabclass[2]为125,如果需要存储一个110字节的缓存,那么就需要到slabclass[2] 的空闲链表中获取一个空闲节点进行存储。
2.2.2 slabclass的初始化
| slabs_init |---> slabs_preallocate |---> do_slabs_newslab |--->grow_slab_list |--->split_slab_page_into_freelist
|
2.2.3 item节点的分配流程
| 序号 |
描述 |
| 1 |
根据大小,找到合适的slabclass |
| 2 |
slabclass空闲列表中是否有空闲的item节点,如果有直接分配item,用于存储内容 |
| 3 |
空闲列表没有空闲的item可以分配,会重新开辟一个slab(默认大小为1M)的内存块,然后切割slab并放入到空闲列表中,然后从空闲列表中获取节点 |
| void *slabs_alloc(size_t size, unsigned int id, unsigned int flags) { void *ret; pthread_mutex_lock(&slabs_lock); ret = do_slabs_alloc(size, id, flags); pthread_mutex_unlock(&slabs_lock); return ret; } /*@null@*/ static void *do_slabs_alloc(const size_t size, unsigned int id, unsigned int flags) { slabclass_t *p; void *ret = NULL; item *it = NULL; if (id < POWER_SMALLEST || id > power_largest) { MEMCACHED_SLABS_ALLOCATE_FAILED(size, 0); return NULL; } p = &slabclass[id]; assert(p->sl_curr == 0 || (((item *)p->slots)->it_flags & ITEM_SLABBED)); assert(size <= p->size); /* 没有空闲slab时,需要重新分配*/ if (p->sl_curr == 0 && flags != SLABS_ALLOC_NO_NEWPAGE) { do_slabs_newslab(id); } if (p->sl_curr != 0) { /* return off our freelist */ it = (item *)p->slots; p->slots = it->next; if (it->next) it->next->prev = 0; /* Kill flag and initialize refcount here for lock safety in slab * mover's freeness detection. */ it->it_flags &= ~ITEM_SLABBED; it->refcount = 1; p->sl_curr--; ret = (void *)it; } else { ret = NULL; } if (ret) { MEMCACHED_SLABS_ALLOCATE(size, id, p->size, ret); } else { MEMCACHED_SLABS_ALLOCATE_FAILED(size, id); } return ret; } |
2.2.4 item节点的释放
释放一个item节点,并不会free内存空间,而是将item节点归还到slabclass的空闲列表中
| void slabs_free(void *ptr, size_t size, unsigned int id) { pthread_mutex_lock(&slabs_lock); do_slabs_free(ptr, size, id); pthread_mutex_unlock(&slabs_lock); } static void do_slabs_free(void *ptr, const size_t size, unsigned int id) { slabclass_t *p; item *it; assert(id >= POWER_SMALLEST && id <= power_largest); if (id < POWER_SMALLEST || id > power_largest) return; MEMCACHED_SLABS_FREE(size, id, ptr); p = &slabclass[id]; it = (item *)ptr; if ((it->it_flags & ITEM_CHUNKED) == 0) { it->it_flags = ITEM_SLABBED; it->slabs_clsid = id; it->prev = 0; it->next = p->slots; if (it->next) it->next->prev = it; p->slots = it; p->sl_curr++; } else { do_slabs_free_chunked(it, size); } return; } |
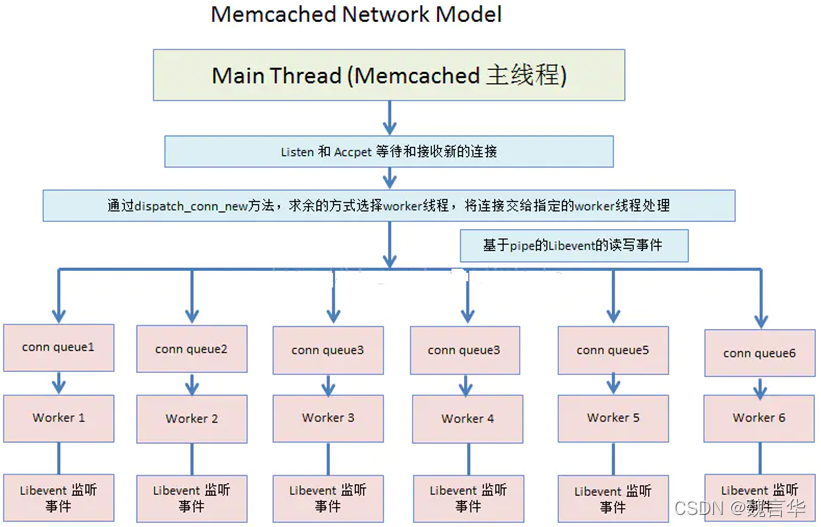
3 Memcached网络模型
| 1 |
Memcached主要是基于Libevent 网络事件库进行开发的 |
| 2 |
Memcached的网络模型分为两部分:主线程和工作线程。主线程主要用来接收客户端的连接信息;工作线程主要用来接管客户端连接,处理具体的业务逻辑 |
| 3 |
主线程和工作线程之间主要是通过pipe管道来进行通信。当主线程接收到客户端的连接的时候,会通过轮询的方式选择一个工作线程,然后向该工作线程的管道pipe写数据。工作线程监听到管道中有数据写入的时候,就会触发代码逻辑去接管客户端的连接 |
| 4 |
每个工作线程也是基于Libevent的事件机制,当客户端有数据写入的时候,就会触发读取的操作 |
"主线程统一accept/dispatch子线程"的基础设施:主线程创建多个子线程(这些子线程也称为worker线程),每一个线程都维持自己的事件循环,即每个线程都有自己的epoll,并且都会调用epoll_wait函数进入事件监听状态。每一个worker线程(子线程)和主线程之间都用一条管道相互通信。每一个子线程都监听自己对应那条管道的读端。当主线程想和某一个worker线程进行通信,直接往对应的那条管道写入数据即可。
"主线程统一accept/dispatch子线程"模型的工作流程:主线程负责监听进程对外的TCP监听端口。当客户端申请连接connect到进程的时候,主线程负责接收accept客户端的连接请求。然后主线程选择其中一个worker线程,把客户端fd通过对应的管道传给worker线程。worker线程得到客户端的fd后负责和这个客户端进行一切的通信。

1. memcached使用libevent作为进行事件监听;
2.memcached往管道里面写的内容不是fd,而是一个简单的字符。每一个worker线程都维护一个CQ队列,主线程把fd和一些信息写入一个CQ_ITEM里面,然后主线程往worker线程的CQ队列里面push这个CQ_ITEM。接着主线程使用管道通知worker线程:“唤醒work线程处理新的链接请求”。

3.1 CQ_ITEM
memcached每一个worker线程都有一个CQ队列,主线程accept到新客户端后,就把新客户端的信息封装成一个CQ_ITEM,然后push到选定线程的CQ队列中
| typedef struct conn_queue_item CQ_ITEM; struct conn_queue_item { int sfd; enum conn_states init_state; int event_flags; int read_buffer_size; enum network_transport transport; enum conn_queue_item_modes mode; conn *c; void *ssl; io_pending_t *io; // IO when used for deferred IO handling. STAILQ_ENTRY(conn_queue_item) i_next; }; /* A connection queue. */ typedef struct conn_queue CQ; struct conn_queue { STAILQ_HEAD(conn_ev_head, conn_queue_item) head; pthread_mutex_t lock; cache_t *cache; /* freelisted objects */ }; |
可以看到结构体conn_queue(即CQ队列结构体)有一个pthread_mutex_t类型变量lock,这说明主线程往某个worker线程的CQ队列里面push一个CQ_ITEM的时候必然要加锁的。下面是初始化CQ队列,以及push、pop一个CQ_ITEM的代码
| static void cq_init(CQ *cq) { pthread_mutex_init(&cq->lock, NULL); cq->head = NULL; cq->tail = NULL; } static CQ_ITEM *cq_pop(CQ *cq) { CQ_ITEM *item; pthread_mutex_lock(&cq->lock); item = cq->head; if (NULL != item) { cq->head = item->next; if (NULL == cq->head) cq->tail = NULL; } pthread_mutex_unlock(&cq->lock); return item; } /* * Adds an item to a connection queue. */ static void cq_push(CQ *cq, CQ_ITEM *item) { item->next = NULL; pthread_mutex_lock(&cq->lock); if (NULL == cq->tail) cq->head = item; else cq->tail->next = item; cq->tail = item; pthread_mutex_unlock(&cq->lock); } |

3.2 线程模型
3.2.1 主线程初始化逻辑
Memcached主线程的初始化逻辑比较简单,主要作用是启动监听的master线程和工作的worker线程。,其中启动worker线程通过memcached_thread_init函数进行实现,这部分逻辑分析在worker线程初始化当中进行分析,这里主要分析监听的master线程。整个master线程的启动过程就是socket的server端初始化结合libevent的初始化。整个过程如下:
1)server_sockets,该方法主要是遍历所有listen的socket列表并逐个进行绑定。
2)server_socket,该方法主要是操作单个socket到listen状态。
3)conn_new,将socket注册到libevent当中。
4)event_handler,监听socket的回调函数。
5)最后event_base_loop让整个libevent进行循环工作状态
| int main (int argc, char **argv) { //检查libevent的版本是否足够新.1.3即可 if (!sanitycheck()) { return EX_OSERR; } //对memcached的关键设置取默认值 settings_init(); ...//解析memcached启动参数 //main_base是一个struct event_base类型的全局变量 main_base = event_init();//为主线程创建一个event_base conn_init();//先不管,后面会说到 //创建settings.num_threads个worker线程,并且为每个worker线程创建一个CQ队列 //并为这些worker申请各自的event_base,worker线程然后进入事件循环中 thread_init(settings.num_threads, main_base); //设置一个定时event(也叫超时event),定时(频率为一秒)更新current_time变量 //这个超时event是add到全局变量main_base里面的,所以主线程负责更新current_time(这是一个很重要的全局变量) clock_handler(0, 0, 0); /* create the listening socket, bind it, and init */ if (settings.socketpath == NULL) { FILE *portnumber_file = NULL; //创建监听客户端的socket if (settings.port && server_sockets(settings.port, tcp_transport,//tcp_transport是枚举类型 portnumber_file)) { vperror("failed to listen on TCP port %d", settings.port); exit(EX_OSERR); } ... } if (event_base_loop(main_base, 0) != 0) {//主线程进入事件循环 retval = EXIT_FAILURE; } return retval; } |
解析参数并把遍历所有的监听socket进行绑定。执行方法server_socket(p, the_port, transport, portnumber_file)
| static int server_sockets(int port, enum network_transport transport, FILE *portnumber_file) { if (settings.inter == NULL) { return server_socket(settings.inter, port, transport, portnumber_file); } else { // tokenize them and bind to each one of them.. char *b; int ret = 0; char *list = strdup(settings.inter); for (char *p = strtok_r(list, ";,", &b); ret |= server_socket(p, the_port, transport, portnumber_file); } free(list); return ret; } } |
针对单个listen的socket的初始化过程,这里主要做的事情是socket的相关初始化过程,主要是指设置socket相关的一些参数;进行socket的bind操作;通过方法conn_new关联socket和libevent当中
| static int server_socket(const char *interface, int port, enum network_transport transport, FILE *portnumber_file) { int sfd; struct linger ling = {0, 0}; struct addrinfo *ai; struct addrinfo *next; struct addrinfo hints = { .ai_flags = AI_PASSIVE, .ai_family = AF_UNSPEC }; char port_buf[NI_MAXSERV]; int error; int success = 0; int flags =1; for (next= ai; next; next= next->ai_next) { conn *listen_conn_add; if ((sfd = new_socket(next)) == -1) { continue; } //todo 设置socket相关的属性,这里省略相关代码 // 绑定socket,省略相关代码 if (bind(sfd, next->ai_addr, next->ai_addrlen) == -1) {} // 暂时只关心TCP协议的,忽略UDP协议实现 if (IS_UDP(transport)) { } else { if (!(listen_conn_add = conn_new(sfd, conn_listening, EV_READ | EV_PERSIST, 1, transport, main_base))) { fprintf(stderr, "failed to create listening connection\n"); exit(EXIT_FAILURE); } listen_conn_add->next = listen_conn; listen_conn = listen_conn_add; } } freeaddrinfo(ai); /* Return zero iff we detected no errors in starting up connections */ return success == 0; } |
conn_new内部就是执行libevent相关的配置,包括event_set和event_base_set,这里需要关注的是event_set当中绑定了回调函数event_handler,用于连接到来后执行的逻辑
| conn *conn_new(const int sfd, enum conn_states init_state, const int event_flags, const int read_buffer_size, enum network_transport transport, struct event_base *base, void *ssl) { conn *c; assert(sfd >= 0 && sfd < max_fds); c = conns[sfd]; 。。。。。。。。。。。 event_set(&c->event, sfd, event_flags, event_handler, (void *)c); event_base_set(base, &c->event); c->ev_flags = event_flags; if (event_add(&c->event, 0) == -1) { perror("event_add"); return NULL; } return c; } |
回调函数event_handler的核心在于drive_machine,这个函数是整个Memcached的状态转移中心,所有的操作都通过drive_machine进行驱动来实现的
| void event_handler(const evutil_socket_t fd, const short which, void *arg) { conn *c; c = (conn *)arg; assert(c != NULL); c->which = which; /* sanity */ if (fd != c->sfd) { if (settings.verbose > 0) fprintf(stderr, "Catastrophic: event fd doesn't match conn fd!\n"); conn_close(c); return; } drive_machine(c); /* wait for next event */ return; } |
3.2.2 work线程初始化
memcached_thread_init主要用于工作线程worker的初始化,核心的三个操作主要是:
1)初始化master线程和worker线程通信的pipe管道,pipe(fds)。
2)setup_thread,主要用于设置工作线程libevent相关的参数。
3)create_worker,主要是启动工作线程开始循环处理工作
| void memcached_thread_init(int nthreads, void *arg) { int i; int power; threads = calloc(nthreads, sizeof(LIBEVENT_THREAD)); for (i = 0; i < nthreads; i++) { #ifdef HAVE_EVENTFD threads[i].notify_event_fd = eventfd(0, EFD_NONBLOCK); if (threads[i].notify_event_fd == -1) { perror("failed creating eventfd for worker thread"); exit(1); } #else int fds[2]; if (pipe(fds)) { perror("Can't create notify pipe"); exit(1); } threads[i].notify_receive_fd = fds[0]; threads[i].notify_send_fd = fds[1]; #endif #ifdef EXTSTORE threads[i].storage = arg; #endif setup_thread(&threads[i]); /* Reserve three fds for the libevent base, and two for the pipe */ stats_state.reserved_fds += 5; } /* Create threads after we've done all the libevent setup. */ for (i = 0; i < nthreads; i++) { create_worker(worker_libevent, &threads[i]); } /* Wait for all the threads to set themselves up before returning. */ pthread_mutex_lock(&init_lock); wait_for_thread_registration(nthreads); pthread_mutex_unlock(&init_lock); } |
setup_thread内部主要是初始化工作线程worker的libevent相关参数,这里我们重点关注包括:
1)回调函数thread_libevent_process。
2)初始化master线程和worker线程通信的队cq_init(me->new_conn_queue)
static void setup_thread(LIBEVENT_THREAD *me) {
me->base = event_init();
event_set(&me->notify_event, me->notify_receive_fd,
EV_READ | EV_PERSIST, thread_libevent_process, me);
event_base_set(me->base, &me->notify_event);
if (event_add(&me->notify_event, 0) == -1) {
fprintf(stderr, "Can't monitor libevent notify pipe\n");
exit(1);
}
me->new_conn_queue = malloc(sizeof(struct conn_queue));
if (me->new_conn_queue == NULL) {
perror("Failed to allocate memory for connection queue");
exit(EXIT_FAILURE);
}
cq_init(me->new_conn_queue);
}
create_worker主要是启动工作线程worker使其开始工作就可以了。
create_worker(worker_libevent, &threads[i])传入函数是worker_libevent
通过pthread_create方法触发worker_libevent的工作,在worker_libevent方法内部通过event_base_loop最终使得libevent开始工作
| static void create_worker(void *(*func)(void *), void *arg) { pthread_attr_t attr; int ret; pthread_attr_init(&attr); if ((ret = pthread_create(&((LIBEVENT_THREAD*)arg)->thread_id, &attr, func, arg)) != 0) { fprintf(stderr, "Can't create thread: %s\n", strerror(ret)); exit(1); } } static void *worker_libevent(void *arg) { LIBEVENT_THREAD *me = arg; /* Any per-thread setup can happen here; memcached_thread_init() will block until * all threads have finished initializing. */ me->l = logger_create(); me->lru_bump_buf = item_lru_bump_buf_create(); if (me->l == NULL || me->lru_bump_buf == NULL) { abort(); } if (settings.drop_privileges) { drop_worker_privileges(); } register_thread_initialized(); event_base_loop(me->base, 0); // same mechanism used to watch for all threads exiting. register_thread_initialized(); event_base_free(me->base); return NULL; } |
3.2.3 主从线程通信
在master线程接受连接以后会触发drive_machine方法,其中master的状态为conn_listening,最终我们通过dispatch_conn_new方法实现master到worker的分发操作
| static void drive_machine(conn *c) { bool stop = false; int sfd; socklen_t addrlen; struct sockaddr_storage addr; int nreqs = settings.reqs_per_event; int res; const char *str; #ifdef HAVE_ACCEPT4 static int use_accept4 = 1; #else static int use_accept4 = 0; #endif assert(c != NULL); while (!stop) { switch(c->state) { case conn_listening: addrlen = sizeof(addr); sfd = accept(c->sfd, (struct sockaddr *)&addr, &addrlen); // 中间省略一系列的socket相关的初始化工作 if (settings.maxconns_fast && } else { dispatch_conn_new(sfd, conn_new_cmd, EV_READ | EV_PERSIST, DATA_BUFFER_SIZE, c->transport); } stop = true; break; |
| void dispatch_conn_new(int sfd, enum conn_states init_state, int event_flags, int read_buffer_size, enum network_transport transport, void *ssl) { CQ_ITEM *item = NULL; LIBEVENT_THREAD *thread; if (!settings.num_napi_ids) thread = select_thread_round_robin(); else thread = select_thread_by_napi_id(sfd); item = cqi_new(thread->ev_queue); if (item == NULL) { close(sfd); /* given that malloc failed this may also fail, but let's try */ fprintf(stderr, "Failed to allocate memory for connection object\n"); return; } item->sfd = sfd; item->init_state = init_state; item->event_flags = event_flags; item->read_buffer_size = read_buffer_size; item->transport = transport; item->mode = queue_new_conn; item->ssl = ssl; MEMCACHED_CONN_DISPATCH(sfd, (int64_t)thread->thread_id); notify_worker(thread, item); } static void notify_worker(LIBEVENT_THREAD *t, CQ_ITEM *item) { cq_push(t->ev_queue, item); #ifdef HAVE_EVENTFD uint64_t u = 1; if (write(t->notify_event_fd, &u, sizeof(uint64_t)) != sizeof(uint64_t)) { perror("failed writing to worker eventfd"); /* TODO: This is a fatal problem. Can it ever happen temporarily? */ } #else char buf[1] = "c"; if (write(t->notify_send_fd, buf, 1) != 1) { perror("Failed writing to notify pipe"); /* TODO: This is a fatal problem. Can it ever happen temporarily? */ } #endif } |
thread_libevent_process是worker线程接受master分发新来连接时候的回调函数,内部通过conn_new来处理新连接的到来,conn_new的内部操作就是把新连接的socket注册到worker线程的libevent当中。
| static void thread_libevent_process(evutil_socket_t fd, short which, void *arg) { LIBEVENT_THREAD *me = arg; CQ_ITEM *item; conn *c; uint64_t ev_count = 0; // max number of events to loop through this run. #ifdef HAVE_EVENTFD if (read(fd, &ev_count, sizeof(uint64_t)) != sizeof(uint64_t)) { if (settings.verbose > 0) fprintf(stderr, "Can't read from libevent pipe\n"); return; } #else char buf[MAX_PIPE_EVENTS]; ev_count = read(fd, buf, MAX_PIPE_EVENTS); if (ev_count == 0) { if (settings.verbose > 0) fprintf(stderr, "Can't read from libevent pipe\n"); return; } #endif for (int x = 0; x < ev_count; x++) { item = cq_pop(me->ev_queue); if (item == NULL) { return; } switch (item->mode) { case queue_new_conn: c = conn_new(item->sfd, item->init_state, item->event_flags, item->read_buffer_size, item->transport, me->base, item->ssl); |
3.3 命令解析
memcached 的命令协议从直观逻辑上可以分为获取类型、变更类型、其他类型。但从实际处理层面区分,则可以细分为 get 类型、update 类型、delete 类型、算术类型、touch 类型、stats 类型,以及其他类型。对应的处理函数为,process_get_command, process_update_command, process_arithmetic_command, process_touch_command 等。每个处理函数能够处理不同的协议

工作线程监听到主线程的管道通知后,会从连接队列弹出一个新连接,然后就会创建一个 conn 结构体,注册该 conn 读事件,然后继续监听该连接上的 IO 事件。后续这个连接有命令进来时,工作线程会读取 client 发来的命令,进行解析并处理,最后返回响应。工作线程的主要处理逻辑也是在状态机中,一个名叫 drive_machine 的函数。整个处理流程如下:
| 序号 |
描述 |
| 1 |
当客户端和Memcached建立TCP连接后,Memcached会基于Libevent的event事件来监听客户端是否有可以读取的数据 |
| 2 |
当客户端有命令数据报文上报的时候,就会触发drive_machine方法中的conn_read这个Case,在进入这个状态之前经过conn_new_cmd->conn_waiting->conn_read的流程 |
| 3 |
memcached通过try_read_network方法读取客户端的报文。如果读取失败,则返回conn_closing,去关闭客户端的连接;如果没有读取到任何数据,则会返回conn_waiting,继续等待客户端的事件到来,并且退出drive_machine的循环;如果数据读取成功,则会将状态转交给conn_parse_cmd处理,读取到的数据会存储在c->rbuf容器中 |
| 4 |
conn_parse_cmd主要的工作就是用来解析命令。主要通过try_read_command这个方法来读取c->rbuf中的命令数据,通过\n来分隔数据报文的命令。如果c->buf内存块中的数据匹配不到\n,则返回继续等待客户端的命令数据报文到来conn_waiting;否则就会转交给process_command方法,来处理具体的命令(命令解析会通过\0符号来分隔) |
| 5 |
process_command主要用来处理具体的命令。其中tokenize_command这个方法非常重要,将命令拆解成多个元素(KEY的最大长度250)。例如我们以get命令为例,最终会跳转到process_get_command这个命令 process_*_command这一系列就是处理具体的命令逻辑的 |
| 6 |
我们进入process_get_command,当获取数据处理完毕之后,会转交到conn_mwrite这个状态。如果获取数据失败,则关闭连接 |
| 7 |
进入conn_mwrite后,主要是通过transmit方法来向客户端提交数据。如果写数据失败,则关闭连接或退出drive_machine循环;如果写入成功,则又转交到conn_new_cmd这个状态 |
| 8 |
conn_new_cmd这个状态主要是处理c->rbuf中剩余的命令。主要看一下reset_cmd_handler这个方法,这个方法会去判断c->rbytes中是否还有剩余的报文没处理,如果未处理,则转交到conn_parse_cmd(第四步)继续解析剩余命令;如果已经处理了,则转交到conn_waiting,等待新的事件到来。在转交之前,每次都会执行一次conn_shrink方法 |
| 9 |
conn_shrink方法主要用来处理命令报文容器c->rbuf和输出内容的容器是否数据满了?是否需要扩大buffer的大小,是否需要移动内存块。接受命令报文的初始化内存块大小2048,最大8192 |
 1)memcached启动后,主线程监听并准备接受新连接接入。当有新连接接入时,主线程进入 conn_listening 状态,accept 新连接,并将新连接调度给工作线程。
1)memcached启动后,主线程监听并准备接受新连接接入。当有新连接接入时,主线程进入 conn_listening 状态,accept 新连接,并将新连接调度给工作线程。
2)Worker 线程监听管道,当收到主线程通过管道发送的消息后,工作线程中的连接进入 conn_new_cmd 状态,创建 conn 结构体,并做一些初始化重置操作,然后进入 conn_waiting 状态,注册读事件,并等待网络 IO。
3)有数据到来时,连接进入 conn_read 状态,读取网络数据。
4)读取成功后,就进入 conn_parse_cmd 状态,然后根据 Mc 协议解析指令。
5)对于读取指令,获取到 value 结果后,进入 conn_mwrite 状态。
6)对于变更指令,则进入 conn_nread,进行 value 的读取,读取到 value 后,对 key 进行变更,当变更完毕后,进入 conn_write,然后将结果写入缓冲。然后和读取指令一样,也进入 conn_mwrite 状态。
7)进入到 conn_mwrite 状态后,将结果响应发送给 client。发送响应完毕后,再次进入到 conn_new_cmd 状态,进行连接重置,准备下一次命令处理循环。
8)在读取、解析、处理、响应过程,遇到任何异常就进入 conn_closing,关闭连接
3.3.1 状态机解析
| 状态机 |
说明 |
| conn_new_cmd |
主线程通过调用 dispatch_conn_new,把新连接调度给工作线程后,worker 线程创建 conn 对象,这个连接初始状态就是 conn_new_cmd。除了通过新建连接进入 conn_new_cmd 状态之外,如果连接命令处理完毕,准备接受新指令时,也会将连接的状态设置为 conn_new_cmd 状态。 进入 conn_new_cmd 后,工作线程会调用 reset_cmd_handler 函数,重置 conn 的 cmd 和 substate 字段,并在必要时对连接 buf 进行收缩。因为连接在处理 client 来的命令时,对于写指令,需要分配较大的读 buf 来存待更新的 key value,而对于读指令,则需要分配较大的写 buf 来缓冲待发送给 client 的 value 结果。持续运行中,随着大 size value 的相关操作,这些缓冲会占用很多内存,所以需要设置一个阀值,超过阀值后就进行缓冲内存收缩,避免连接占用太多内存。在后端服务以及中间件开发中,这个操作很重要,因为线上服务的连接很容易达到万级别,如果一个连接占用几十 KB 以上的内存,后端系统仅连接就会占用数百 MB 甚至数 GB 以上的内存空间。 工作线程处理完 conn_new_cmd 状态的主要逻辑后,如果读缓冲区有数据可以读取,则进入 conn_parse_cmd 状态,否则就会进入到 conn_waiting 状态,等待网络数据进来。 |
| conn_waiting |
连接进入 conn_waiting 状态后,处理逻辑很简单,直接通过 update_event 函数注册读事件即可,之后会将连接状态更新为 conn_read。 |
| conn_read |
当工作线程监听到网络数据进来,连接就进入 conn_read 状态。对 conn_read 的处理,是通过 try_read_network 从 socket 中读取网络数据。如果读取失败,则进入 conn_closing 状态,关闭连接。如果没有读取到任何数据,则会返回 conn_waiting,继续等待 client 端的数据到来。如果读取数据成功,则会将读取的数据存入 conn 的 rbuf 缓冲,并进入 conn_parse_cmd 状态,准备解析 cmd |
| conn_parse_cmd |
conn_parse_cmd 状态的处理逻辑就是解析命令。工作线程首先通过 try_read_command 读取连接的读缓冲,并通过 \n 来分隔数据报文的命令。如果命令首行长度大于 1024,关闭连接,这就意味着 key 长度加上其他各项命令字段的总长度要小于 1024 字节。当然对于 key,Mc 有个默认的最大长度,key_max_length,默认设置为 250 字节。校验完毕首行报文的长度,接下来会在 process_command 函数中对首行指令进行处理。 备注: conn_parse_cmd 的状态处理,只有读取到 \n,有了完整的命令首行协议,才会进入 process_command,否则会跳转到 conn_waiting,继续等待客户端的命令数据报文。在 process_command 处理中,如果是获取类命令,在获取到 key 对应的 value 后,则跳转到 conn_mwrite,准备写响应给连接缓冲。而对于 update 变更类型的指令,则需要继续读取 value 数据,此时连接会跳转到 conn_nread 状态。在 conn_parse_cmd 处理过程中,如果遇到任何失败,都会跳转到 conn_closing 关闭连接 |
| conn_write |
连接 conn_write 状态处理逻辑很简单,直接进入 conn_mwrite 状态。或者当 conn 的 iovused 为 0 或对于 udp 协议,将响应写入 conn 消息缓冲后,再进入 conn_mwrite 状态。 |
| conn_mwrite |
进入 conn_mwrite 状态后,工作线程将通过 transmit 来向客户端写数据。如果写数据失败,跳转到 conn_closing,关闭连接退出状态机。如果写数据成功,则跳转到 conn_new_cmd,准备下一次新指令的获取 |
| conn_closing |
最后一个 conn_closing 状态,前面提到过很多次,在任何状态的处理过程中,如果出现异常,就会进入到这个状态,关闭连接。 |

3.3.2 状态机源码分析
3.3.2.1 conn_new_cmd
conn_new_cmd内部通过reset_cmd_handler将状态设置为conn_parse_cmd,重新进入命令解析过程。重新进行一个大循环
| case conn_new_cmd: /* Only process nreqs at a time to avoid starving other connections */ --nreqs; if (nreqs >= 0) { reset_cmd_handler(c); } else if (c->resp_head) { // flush response pipe on yield. conn_set_state(c, conn_mwrite); } else { pthread_mutex_lock(&c->thread->stats.mutex); c->thread->stats.conn_yields++; pthread_mutex_unlock(&c->thread->stats.mutex); if (c->rbytes > 0) { /* We have already read in data into the input buffer, so libevent will most likely not signal read events on the socket (unless more data is available. As a hack we should just put in a request to write data, because that should be possible ;-) */ if (!update_event(c, EV_WRITE | EV_PERSIST)) { if (settings.verbose > 0) fprintf(stderr, "Couldn't update event\n"); conn_set_state(c, conn_closing); break; } } stop = true; } static void reset_cmd_handler(conn *c) { c->cmd = -1; c->substate = bin_no_state; if (c->item != NULL) { // TODO: Any other way to get here? // SASL auth was mistakenly using it. Nothing else should? if (c->item_malloced) { free(c->item); c->item_malloced = false; } else { item_remove(c->item); } c->item = NULL; } if (c->rbytes > 0) { conn_set_state(c, conn_parse_cmd); } else if (c->resp_head) { conn_set_state(c, conn_mwrite); } else { conn_set_state(c, conn_waiting); } } |
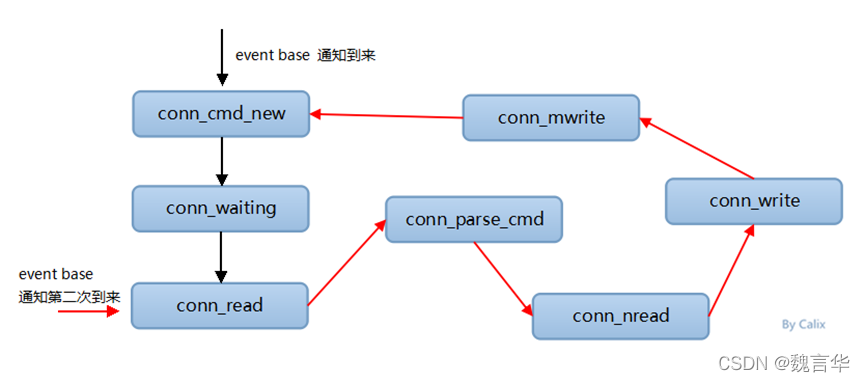
客户端输入的第一条命令时,epoll触发了两次函数(epoll为水平触发,没有read的话会有第二次触发)
3.3.2.2 conn_waiting
| case conn_waiting: rbuf_release(c); if (!update_event(c, EV_READ | EV_PERSIST)) { if (settings.verbose > 0) fprintf(stderr, "Couldn't update event\n"); conn_set_state(c, conn_closing); break; } conn_set_state(c, conn_read); stop = true; break; |
3.3.2.3 conn_read
memcached通过try_read_network方法读取客户端的报文。如果读取失败,则返回conn_closing,去关闭客户端的连接;如果没有读取到任何数据,则会返回conn_waiting,继续等待客户端的事件到来,并且退出drive_machine的循环;如果数据读取成功,则会将状态转交给conn_parse_cmd处理,读取到的数据会存储在c->rbuf容器中
| case conn_read: if (!IS_UDP(c->transport)) { // Assign a read buffer if necessary. if (!rbuf_alloc(c)) { // TODO: Some way to allow for temporary failures. conn_set_state(c, conn_closing); break; } res = try_read_network(c); } else { // UDP connections always have a static buffer. res = try_read_udp(c); } switch (res) { case READ_NO_DATA_RECEIVED: conn_set_state(c, conn_waiting); break; case READ_DATA_RECEIVED: conn_set_state(c, conn_parse_cmd); break; case READ_ERROR: conn_set_state(c, conn_closing); break; case READ_MEMORY_ERROR: /* Failed to allocate more memory */ /* State already set by try_read_network */ break; } break; |
3.3.2.4 conn_parse_cmd
这个方法主要是用来读取rbuf中的命令的。因为数据报文会有粘包和拆包的特性,所以只有等到命令行完整了才能进行解析。所有只有匹配到了\n符号,才能匹配一个完整的命令。在整个解析过程中,每次解析到\n符号就说明一个完整的命令了,然后就进入处理这个命令的过程,进行处理后返回客户端后再次解析。
| case conn_parse_cmd: c->noreply = false; if (c->try_read_command(c) == 0) { /* we need more data! */ if (c->resp_head) { // Buffered responses waiting, flush in the meantime. conn_set_state(c, conn_mwrite); } else { conn_set_state(c, conn_waiting); } } break; |
| int try_read_command_ascii(conn *c) { char *el, *cont; if (c->rbytes == 0) return 0; el = memchr(c->rcurr, '\n', c->rbytes); if (!el) { if (c->rbytes > 2048) { char *ptr = c->rcurr; while (*ptr == ' ') { /* ignore leading whitespaces */ ++ptr; } if (ptr - c->rcurr > 100 || (strncmp(ptr, "get ", 4) && strncmp(ptr, "gets ", 5))) { conn_set_state(c, conn_closing); return 1; } if (!c->rbuf_malloced) { if (!rbuf_switch_to_malloc(c)) { conn_set_state(c, conn_closing); return 1; } } } return 0; } cont = el + 1; if ((el - c->rcurr) > 1 && *(el - 1) == '\r') { el--; } *el = '\0'; assert(cont <= (c->rcurr + c->rbytes)); c->last_cmd_time = current_time; process_command_ascii(c, c->rcurr); c->rbytes -= (cont - c->rcurr); c->rcurr = cont; assert(c->rcurr <= (c->rbuf + c->rsize)); return 1; } |
tokenize_command需要分析的下一个细节就是关于最后一个元素的问题,如果解析的命令个数没有达到max_tokens,最后一个元素内容为空,如果达到了max_tokens,最后一个元素时剩余的未解析字符串
| static size_t tokenize_command(char *command, token_t *tokens, const size_t max_tokens) { char *s, *e; size_t ntokens = 0; assert(command != NULL && tokens != NULL && max_tokens > 1); size_t len = strlen(command); unsigned int i = 0; s = e = command; for (i = 0; i < len; i++) { if (*e == ' ') { if (s != e) { tokens[ntokens].value = s; tokens[ntokens].length = e - s; ntokens++; *e = '\0'; if (ntokens == max_tokens - 1) { e++; s = e; /* so we don't add an extra token */ break; } } s = e + 1; } e++; } if (s != e) { tokens[ntokens].value = s; tokens[ntokens].length = e - s; ntokens++; } /* * If we scanned the whole string, the terminal value pointer is null, * otherwise it is the first unprocessed character. */ tokens[ntokens].value = *e == '\0' ? NULL : e; tokens[ntokens].length = 0; ntokens++; return ntokens; } |
| void process_command_ascii(conn *c, char *command) { token_t tokens[MAX_TOKENS]; size_t ntokens; int comm; assert(c != NULL); MEMCACHED_PROCESS_COMMAND_START(c->sfd, c->rcurr, c->rbytes); if (settings.verbose > 1) fprintf(stderr, "<%d %s\n", c->sfd, command); // Prep the response object for this query. if (!resp_start(c)) { conn_set_state(c, conn_closing); return; } ntokens = tokenize_command(command, tokens, MAX_TOKENS); // All commands need a minimum of two tokens: cmd and NULL finalizer // There are also no valid commands shorter than two bytes. if (ntokens < 2 || tokens[COMMAND_TOKEN].length < 2) { out_string(c, "ERROR"); return; } // Meta commands are all 2-char in length. char first = tokens[COMMAND_TOKEN].value[0]; if (first == 'm' && tokens[COMMAND_TOKEN].length == 2) { switch (tokens[COMMAND_TOKEN].value[1]) { ………………………………………….. } else if (first == 'g') { // Various get commands are very common. WANT_TOKENS_MIN(ntokens, 3); if (strcmp(tokens[COMMAND_TOKEN].value, "get") == 0) { process_get_command(c, tokens, ntokens, false, false); } else if (strcmp(tokens[COMMAND_TOKEN].value, "gets") == 0) { process_get_command(c, tokens, ntokens, true, false); } else if (strcmp(tokens[COMMAND_TOKEN].value, "gat") == 0) { process_get_command(c, tokens, ntokens, false, true); } else if (strcmp(tokens[COMMAND_TOKEN].value, "gats") == 0) { process_get_command(c, tokens, ntokens, true, true); } else { out_string(c, "ERROR"); } } else if (first == 's') { if (strcmp(tokens[COMMAND_TOKEN].value, "set") == 0 && (comm = NREAD_SET)) { WANT_TOKENS_OR(ntokens, 6, 7); process_update_command(c, tokens, ntokens, comm, false); } else if (strcmp(tokens[COMMAND_TOKEN].value, "stats") == 0) { process_stat(c, tokens, ntokens); } else if (strcmp(tokens[COMMAND_TOKEN].value, "shutdown") == 0) { process_shutdown_command(c, tokens, ntokens); } else if (strcmp(tokens[COMMAND_TOKEN].value, "slabs") == 0) { process_slabs_command(c, tokens, ntokens); } else { out_string(c, "ERROR"); } ……………………………………….. |
process_command_ascii 根据tokens里存储的命令字段进行不同的操作,按照set 操作进行分析。
process_update_command函数申请分配一个item后,并没有直接把这个item插入到LRU队列和哈希表中,而不过用conn结构体的item成员指向这个申请得到的item,而且用ritem成员指向item结构体的数据域(这为了方便写入数据)。最后conn的状态改动为conn_nread
| static void process_update_command(conn *c, token_t *tokens, const size_t ntokens, int comm, bool handle_cas) { ……………………………………………………. item *it; assert(c != NULL); set_noreply_maybe(c, tokens, ntokens); if (tokens[KEY_TOKEN].length > KEY_MAX_LENGTH) { out_string(c, "CLIENT_ERROR bad command line format"); return; } key = tokens[KEY_TOKEN].value; nkey = tokens[KEY_TOKEN].length; if (! (safe_strtoul(tokens[2].value, (uint32_t *)&flags) && safe_strtol(tokens[3].value, &exptime_int) && safe_strtol(tokens[4].value, (int32_t *)&vlen))) { out_string(c, "CLIENT_ERROR bad command line format"); return; } exptime = realtime(EXPTIME_TO_POSITIVE_TIME(exptime_int)); // does cas value exist? if (handle_cas) { if (!safe_strtoull(tokens[5].value, &req_cas_id)) { out_string(c, "CLIENT_ERROR bad command line format"); return; } } if (vlen < 0 || vlen > (INT_MAX - 2)) { out_string(c, "CLIENT_ERROR bad command line format"); return; } vlen += 2; it = item_alloc(key, nkey, flags, exptime, vlen); ………………………………………………… ITEM_set_cas(it, req_cas_id); c->item = it; c->ritem = ITEM_data(it); c->rlbytes = it->nbytes; c->cmd = comm; conn_set_state(c, conn_nread); } |
3.3.2.5 conn_nread
conn_parse_cmd状态机中的process_update_command命令处理过程是没有把item的数据写入到item结构体中。只是把状态机迁移到了conn_nread就退出到drive_machine函数中。
尽管process_update_command留下了尾巴,但它也用conn的成员变量记录了一些重要值,用于填充item的数据域。rlbytes表示须要用多少字节填充item(需要填充的数据的长度),rbytes表示读缓冲区还有多少字节能够使用,ritem指向数据填充地点。
| case conn_nread: if (c->rlbytes == 0) { complete_nread(c); break; } /* Check if rbytes < 0, to prevent crash */ if (c->rlbytes < 0) { if (settings.verbose) { fprintf(stderr, "Invalid rlbytes to read: len %d\n", c->rlbytes); } conn_set_state(c, conn_closing); break; } if (c->item_malloced || ((((item *)c->item)->it_flags & ITEM_CHUNKED) == 0) ) { /* first check if we have leftovers in the conn_read buffer */ if (c->rbytes > 0) { int tocopy = c->rbytes > c->rlbytes ? c->rlbytes : c->rbytes; memmove(c->ritem, c->rcurr, tocopy); c->ritem += tocopy; c->rlbytes -= tocopy; c->rcurr += tocopy; c->rbytes -= tocopy; if (c->rlbytes == 0) { break; } } /* now try reading from the socket */ res = c->read(c, c->ritem, c->rlbytes); if (res > 0) { pthread_mutex_lock(&c->thread->stats.mutex); c->thread->stats.bytes_read += res; pthread_mutex_unlock(&c->thread->stats.mutex); if (c->rcurr == c->ritem) { c->rcurr += res; } c->ritem += res; c->rlbytes -= res; break; } } else { res = read_into_chunked_item(c); if (res > 0) break; } if (res == 0) { /* end of stream */ c->close_reason = NORMAL_CLOSE; conn_set_state(c, conn_closing); break; } if (res == -1 && (errno == EAGAIN || errno == EWOULDBLOCK)) { if (!update_event(c, EV_READ | EV_PERSIST)) { if (settings.verbose > 0) fprintf(stderr, "Couldn't update event\n"); conn_set_state(c, conn_closing); break; } stop = true; break; } /* Memory allocation failure */ if (res == -2) { out_of_memory(c, "SERVER_ERROR Out of memory during read"); c->sbytes = c->rlbytes; conn_set_state(c, conn_swallow); // Ensure this flag gets cleared. It gets killed on conn_new() // so any conn_closing is fine, calling complete_nread is // fine. This swallow semms to be the only other case. c->set_stale = false; c->mset_res = false; break; } /* otherwise we have a real error, on which we close the connection */ if (settings.verbose > 0) { fprintf(stderr, "Failed to read, and not due to blocking:\n" "errno: %d %s \n" "rcurr=%p ritem=%p rbuf=%p rlbytes=%d rsize=%d\n", errno, strerror(errno), (void *)c->rcurr, (void *)c->ritem, (void *)c->rbuf, (int)c->rlbytes, (int)c->rsize); } conn_set_state(c, conn_closing); break; |
当rlbytes值减少到0后,代表需要的数据值全部读取出来了,会进行complete_nread处理,
| void complete_nread_ascii(conn *c) { assert(c != NULL); item *it = c->item; int comm = c->cmd; enum store_item_type ret; bool is_valid = false; pthread_mutex_lock(&c->thread->stats.mutex); c->thread->stats.slab_stats[ITEM_clsid(it)].set_cmds++; pthread_mutex_unlock(&c->thread->stats.mutex); if ((it->it_flags & ITEM_CHUNKED) == 0) { if (strncmp(ITEM_data(it) + it->nbytes - 2, "\r\n", 2) == 0) { is_valid = true; } } if (!is_valid) { // metaset mode always returns errors. if (c->mset_res) { c->noreply = false; } out_string(c, "CLIENT_ERROR bad data chunk"); } else { ret = store_item(it, comm, c); …………………………………………. if (c->mset_res) { _finalize_mset(c, ret); } else { switch (ret) { case STORED: out_string(c, "STORED"); break; case EXISTS: out_string(c, "EXISTS"); break; case NOT_FOUND: out_string(c, "NOT_FOUND"); break; case NOT_STORED: out_string(c, "NOT_STORED"); break; default: out_string(c, "SERVER_ERROR Unhandled storage type."); } } } c->set_stale = false; /* force flag to be off just in case */ c->mset_res = false; item_remove(c->item); /* release the c->item reference */ c->item = 0; } |
根据处理结果给client返回不同信息,并把状态机迁移到conn_new_cmd
| void out_string(conn *c, const char *str) { size_t len; assert(c != NULL); mc_resp *resp = c->resp; // if response was original filled with something, but we're now writing // out an error or similar, have to reset the object first. // TODO: since this is often redundant with allocation, how many callers // are actually requiring it be reset? Can we fast test by just looking at // tosend and reset if nonzero? resp_reset(resp); if (c->noreply) { // TODO: just invalidate the response since nothing's been attempted // to send yet? resp->skip = true; if (settings.verbose > 1) fprintf(stderr, ">%d NOREPLY %s\n", c->sfd, str); conn_set_state(c, conn_new_cmd); return; } if (settings.verbose > 1) fprintf(stderr, ">%d %s\n", c->sfd, str); // Fill response object with static string. len = strlen(str); if ((len + 2) > WRITE_BUFFER_SIZE) { /* ought to be always enough. just fail for simplicity */ str = "SERVER_ERROR output line too long"; len = strlen(str); } memcpy(resp->wbuf, str, len); memcpy(resp->wbuf + len, "\r\n", 2); resp_add_iov(resp, resp->wbuf, len + 2); conn_set_state(c, conn_new_cmd); return; } |
在conn_new_cmd状态下,判断resp_head不为空,迁移状态到conn_mwrite
3.3.2.6 conn_mwrite
| case conn_write: case conn_mwrite: for (io_queue_t *q = c->io_queues; q->type != IO_QUEUE_NONE; q++) { if (q->stack_ctx != NULL) { io_queue_cb_t *qcb = thread_io_queue_get(c->thread, q->type); qcb->submit_cb(q); c->io_queues_submitted++; } } if (c->io_queues_submitted != 0) { conn_set_state(c, conn_io_queue); event_del(&c->event); stop = true; break; } switch (!IS_UDP(c->transport) ? transmit(c) : transmit_udp(c)) { case TRANSMIT_COMPLETE: if (c->state == conn_mwrite) { // Free up IO wraps and any half-uploaded items. conn_release_items(c); conn_set_state(c, conn_new_cmd); if (c->close_after_write) { conn_set_state(c, conn_closing); } } else { if (settings.verbose > 0) fprintf(stderr, "Unexpected state %d\n", c->state); conn_set_state(c, conn_closing); } break; |
发送完出返回TRANSMIT_COMPLETE,迁移状态机到conn_new_cmd。
4 memcached数据存储
| 序号 |
描述 |
| 1 |
Memcached在启动的时候,会默认初始化一个HashTable,这个table的默认长度为65536 |
| 2 |
我们将这个HashTable中的每一个元素称为桶,每个桶就是一个item结构的单向链表 |
| 3 |
Memcached会将key值hash成一个变量名称为hv的uint32_t类型的值 |
| 4 |
通过hv与桶的个数之间的按位与计算,hv & hashmask(hashpower),就可以得到当前的key会落在哪个桶上面 |
| 5 |
然后会将item挂到这个桶的链表上面。链表主要是通过item结构中的h_next实现 |
4.1 Memcached存储结构分析
assoc_init负责初始化hashtable数据结构,通过初始化hashsize(hashpower)大小的数组指针,默认应该是2*16次方大小的数组。
| void assoc_init(const int hashtable_init) { if (hashtable_init) { hashpower = hashtable_init; } primary_hashtable = calloc(hashsize(hashpower), sizeof(void *)); if (! primary_hashtable) { fprintf(stderr, "Failed to init hashtable.\n"); exit(EXIT_FAILURE); } STATS_LOCK(); stats_state.hash_power_level = hashpower; stats_state.hash_bytes = hashsize(hashpower) * sizeof(void *); STATS_UNLOCK(); } |

Memcached存储数据结构item定义,item的结构分两部分, 第一部分定义 item 结构的属性,第二部分是 item 的数据
| typedef struct _stritem { /* Protected by LRU locks */ struct _stritem *next; struct _stritem *prev; /* Rest are protected by an item lock */ struct _stritem *h_next; /* hash chain next */ rel_time_t time; /* least recent access */ rel_time_t exptime; /* expire time */ int nbytes; /* size of data */ unsigned short refcount; uint16_t it_flags; /* ITEM_* above */ uint8_t slabs_clsid;/* which slab class we're in */ uint8_t nkey; /* key length, w/terminating null and padding */ /* this odd type prevents type-punning issues when we do * the little shuffle to save space when not using CAS. */ union { uint64_t cas; char end; } data[]; /* if it_flags & ITEM_CAS we have 8 bytes CAS */ /* then null-terminated key */ /* then " flags length\r\n" (no terminating null) */ /* then data with terminating \r\n (no terminating null; it's binary!) */ } item; |
4.2 数据查找过程
1)首先通过key的hash值hv找到对应的桶,区分是否在扩容。 primary_hashtable[hv & hashmask(hashpower)];
2)然后遍历桶的单链表,比较key值并找到对应item。
| item *assoc_find(const char *key, const size_t nkey, const uint32_t hv) { item *it; uint64_t oldbucket; if (expanding && (oldbucket = (hv & hashmask(hashpower - 1))) >= expand_bucket) { it = old_hashtable[oldbucket]; } else { it = primary_hashtable[hv & hashmask(hashpower)]; } item *ret = NULL; int depth = 0; while (it) { if ((nkey == it->nkey) && (memcmp(key, ITEM_key(it), nkey) == 0)) { ret = it; break; } it = it->h_next; ++depth; } MEMCACHED_ASSOC_FIND(key, nkey, depth); return ret; } |
4.3 数据插入过程
1)首先通过key的hash值hv找到对应的桶。
2)然后将item放到对应桶的单链表的头部
| int assoc_insert(item *it, const uint32_t hv) { uint64_t oldbucket; // assert(assoc_find(ITEM_key(it), it->nkey) == 0); /* shouldn't have duplicately named things defined */ if (expanding && (oldbucket = (hv & hashmask(hashpower - 1))) >= expand_bucket) { it->h_next = old_hashtable[oldbucket]; old_hashtable[oldbucket] = it; } else { it->h_next = primary_hashtable[hv & hashmask(hashpower)]; primary_hashtable[hv & hashmask(hashpower)] = it; } MEMCACHED_ASSOC_INSERT(ITEM_key(it), it->nkey); return 1; } |
4.4数据删除过程
1)首先通过key的hash值hv找到对应的桶。
2)找到桶对应的链表,遍历单链表,删除对应的Item。
| void assoc_delete(const char *key, const size_t nkey, const uint32_t hv) { item **before = _hashitem_before(key, nkey, hv); if (*before) { item *nxt; /* The DTrace probe cannot be triggered as the last instruction * due to possible tail-optimization by the compiler */ MEMCACHED_ASSOC_DELETE(key, nkey); nxt = (*before)->h_next; (*before)->h_next = 0; /* probably pointless, but whatever. */ *before = nxt; return; } /* Note: we never actually get here. the callers don't delete things they can't find. */ assert(*before != 0); } |
4.5 数据扩容过程
1)数据扩容过程是由一个单独线程在检测是否需要扩容,扩容的前提条件是curr_items > (hashsize(hashpower) * 3) / 2,也就是说数据量是原来的1.5倍
2)检测需要扩容后通过信号通知pthread_cond_signal(&maintenance_cond)开始执行扩容
3)以2倍的扩容速度进行扩容,primary_hashtable = calloc(hashsize(hashpower + 1), sizeof(void *))
4)迁移过程是一个逐步迁移过程,每次都只迁移一个桶里面的Item数据
5 LRU内存回收
以往的LRU算法,基本做法都是这样的:
- 创建一个LRU链表,每次新加入的元素都放在链表头。
- 如果元素被访问了一次,同样从当前链表中摘除放到链表头。
3)需要淘汰元素时,从链表尾开始找可以淘汰的元素出来淘汰。
这个算法有如下几个问题:
1)元素被访问一次就会被放到LRU链表的头部,这样即便这个元素可以被淘汰,也会需要很久才会淘汰掉这个元素。
2)由于上面的原因,从链表尾部开始找可以淘汰的元素时,实际可能访问到的是一些虽然不常被访问,但是还没到淘汰时间(即有效时间TTL还未过期)的数据,这样会一直沿着链表往前找很久才能找到适合淘汰的元素。由于这个查找被淘汰元素的过程是需要加锁保护的,加锁时间一长影响了系统的并发。
5.1 改进的分段LRU算法(Segmented LRU)
分段LRU算法中将LRU链表根据活跃度分成了4类:
- HOT_LRU:存储热数据的LRU链表。
- WARM_LRU:存储温数据(即活跃度不如热数据)的LRU链表。
3)COLD_LRU:存储冷数据的LRU链表。
4)TEMP_LRU:存储临时数据(默认不开启)
需要说明的是:热(参数settings.hot_lru_pct)和暖(参数settings.warm_lru_pct)数据的占总体内存的比例有限制,而冷数据则无限。
#define HOT_LRU 0
#define WARM_LRU 64
#define COLD_LRU 128
#define TEMP_LRU 192
同时,使用了heads和tails两个数组用来保存LRU链表:
#define POWER_LARGEST 256 /* actual cap is 255 */
#define LARGEST_ID POWER_LARGEST
static item *heads[LARGEST_ID];
static item *tails[LARGEST_ID];
上面分析slabclass的时候提到过,首先会根据被分配内存大小计算出来一个slabclass数组的索引。在需要从LRU链表中淘汰数据时,由于LRU链表分为了上面三类,那么就还需要再进行一次slabid | lru id计算(其实就是slabid + lru id),到对应的LRU链表中查找元素:

由于从链表尾部往前查找可以淘汰的元素,中间可能会经历很多不能被淘汰的元素,影响了淘汰的速度,因此前面的分级LRU链表就能帮助程序快速识别出哪些元素可以被淘汰。三个分级的LRU链表之间的转换规则如下:
| HOT_LRU |
在HOT LRU队列中的数据绝不会到HOT_LRU队列的前面,只会往更冷的队列中放。规则是:如果元素变得活跃,就放到WARM队列中;否则如果不活跃,就直接放到COLD队列中 |
| WARM_LRU |
如果WARM队列的元素变的活跃,就会移动到WARM队列头;否则往COLD队列移动 |
| COLD_LRU |
COLD队列中的元素,都是不太活跃的了,所以当需要淘汰元素时都会首先到COLD LRU队列中找可以淘汰的数据。当一个在COLD队列的元素重新变成活跃元素时,并不会移动到COLD队列的头部,而是直接移动回去WARM队列 |
| PS:任何操作都不能将一个元素从WARM和COLD队列中移动回去HOT队列了,也就是从HOT队列中移动元素出去的操作是单向操作 |
|
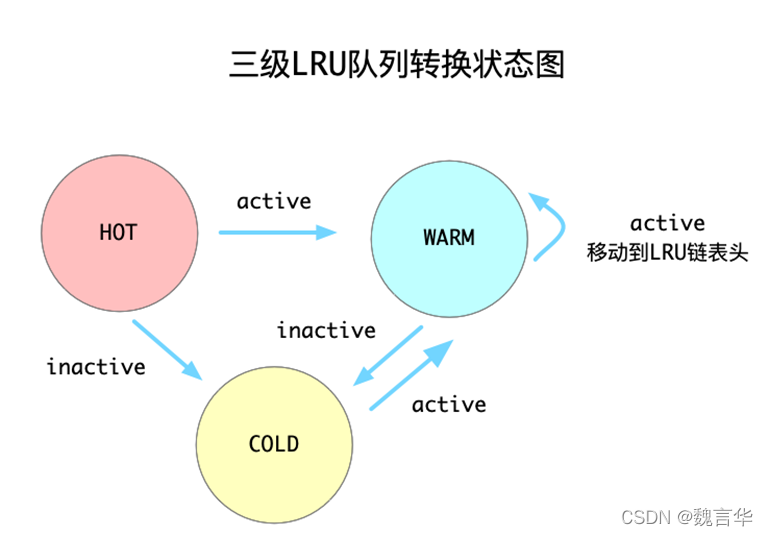
原有LRU算法最大的问题是:只要元素被访问过一次,就马上会被移动到LRU链表的前面,影响了后面对这个元素的淘汰。
改进的算法中,加入了一个机制:只有当元素被访问两次以后,才会标记成活跃元素。
代码中引入了两个标志位,其置位的规则如下:
1)ITEM_FETCHED:第一次被访问时置位该标志位。
2)ITEM_ACTIVE:第二次被访问时(即it->it_flags & ITEM_FETCHED为true的情况下)置位该标志位。
3)INACTIVE:不活跃状态。
4)ITEM_ACTIVE标志位清除的规则,从链表尾遍历到某一个LRU链表时,该元素是链表的最后一个元素,则认为是不活跃的元素,即可以清除ITEM_ACTIVE标志位;
这样,有效避免了只访问一次就变成活跃元素的问题,所以元素变成活跃就意指“至少被访问两次以”。
5.2 memcached 内存回收
| 惰性删除 |
memcached一般不会主动去清除已经过期或者失效的缓存,当get请求一个item才会去检查item是否失效 |
| flush命令 |
flush命令会将所有的item设置为失效 |
| 创建的时候检查 |
Memcached会在创建ITEM的时候去LRU的链表尾部开始检查,是否有失效的ITEM,如果没有的话就重新创建 |
| LRU爬虫 |
memcached默认是关闭LRU爬虫的。LRU爬虫是一个单独的线程,会去清理失效的ITEM |
| LRU淘汰 |
当缓存没有内存可以分配给新的元素的时候,memcached会从LRU链表的尾部开始淘汰一个ITEM,不管这个ITEM是否还在有效期都将会面临淘汰。LRU链表插入缓存ITEM的时候有先后顺序,所以淘汰一个ITEM也是从尾部进行 也就是先淘汰最早的ITEM。 |
5.2.1惰性删除
惰性删除删除其实就是在get数据的时候进行比较判断数据是否过期,这里会跟flush_all命令过期结合起来使用,判断的时候依据了flush_all设置的过期时间settings.oldest_liv
item *do_item_get(const char *key, const size_t nkey, const uint32_t hv, conn *c, const bool do_update) {
item *it = assoc_find(key, nkey, hv);
if (it != NULL) {
refcount_incr(it);
/* Optimization for slab reassignment. prevents popular items from
* jamming in busy wait. Can only do this here to satisfy lock order
* of item_lock, slabs_lock. */
/* This was made unsafe by removal of the cache_lock:
* slab_rebalance_signal and slab_rebal.* are modified in a separate
* thread under slabs_lock. If slab_rebalance_signal = 1, slab_start =
* NULL (0), but slab_end is still equal to some value, this would end
* up unlinking every item fetched.
* This is either an acceptable loss, or if slab_rebalance_signal is
* true, slab_start/slab_end should be put behind the slabs_lock.
* Which would cause a huge potential slowdown.
* Could also use a specific lock for slab_rebal.* and
* slab_rebalance_signal (shorter lock?)
*/
/*if (slab_rebalance_signal &&
((void *)it >= slab_rebal.slab_start && (void *)it < slab_rebal.slab_end)) {
do_item_unlink(it, hv);
do_item_remove(it);
it = NULL;
}*/
}
int was_found = 0;
if (settings.verbose > 2) {
int ii;
if (it == NULL) {
fprintf(stderr, "> NOT FOUND ");
} else {
fprintf(stderr, "> FOUND KEY ");
}
for (ii = 0; ii < nkey; ++ii) {
fprintf(stderr, "%c", key[ii]);
}
}
if (it != NULL) {
was_found = 1;
if (item_is_flushed(it)) {
do_item_unlink(it, hv);
STORAGE_delete(c->thread->storage, it);
do_item_remove(it);
it = NULL;
pthread_mutex_lock(&c->thread->stats.mutex);
c->thread->stats.get_flushed++;
pthread_mutex_unlock(&c->thread->stats.mutex);
if (settings.verbose > 2) {
fprintf(stderr, " -nuked by flush");
}
was_found = 2;
} else if (it->exptime != 0 && it->exptime <= current_time) {
do_item_unlink(it, hv);
STORAGE_delete(c->thread->storage, it);
do_item_remove(it);
it = NULL;
pthread_mutex_lock(&c->thread->stats.mutex);
c->thread->stats.get_expired++;
pthread_mutex_unlock(&c->thread->stats.mutex);
if (settings.verbose > 2) {
fprintf(stderr, " -nuked by expire");
}
was_found = 3;
} else {
if (do_update) {
do_item_bump(c, it, hv);
}
DEBUG_REFCNT(it, '+');
}
}
if (settings.verbose > 2)
fprintf(stderr, "\n");
/* For now this is in addition to the above verbose logging. */
LOGGER_LOG(c->thread->l, LOG_FETCHERS, LOGGER_ITEM_GET, NULL, was_found, key,
nkey, (it) ? it->nbytes : 0, (it) ? ITEM_clsid(it) : 0, c->sfd);
return it;
}5.2.2 flush_all命令删除
| int item_is_flushed(item *it) { rel_time_t oldest_live = settings.oldest_live; uint64_t cas = ITEM_get_cas(it); uint64_t oldest_cas = settings.oldest_cas; if (oldest_live == 0 || oldest_live > current_time) return 0; if ((it->time <= oldest_live) || (oldest_cas != 0 && cas != 0 && cas < oldest_cas)) { return 1; } return 0; } |
5.2.3 新建item会检查数据过期
| 序号 |
描述 |
| 1 |
do_item_alloc进入新增item的内存申请流程 |
| 2 |
do_item_alloc_pull进入item申请的逻辑处理,最多处理10次 |
| 3 |
do_item_alloc_pull内部逻辑是尝试通过slabs_alloc申请内存,失败则尝试通过lru_pull_tail方法释放LRU队列中的item变成可用item |
| 4 |
lru_pull_tail执行释放LRU队列中item的过程,内部包括各种过期item的回收 |
5.2.4 LRU爬虫线程定时清理
后续分析
6 memcached应用中存在的问题
版权声明
本文为[魏言华]所创,转载请带上原文链接,感谢
https://blog.csdn.net/u013743253/article/details/124352123
边栏推荐
- Kids and COVID: why young immune systems are still on top
- 柯里化实现函数连续调用计算累加和
- 阅读笔记:Meta Matrix Factorization for Federated Rating Predictions
- 【代码解析(1)】Communication-Efficient Learning of Deep Networks from Decentralized Data
- JQ序列化后PHP后台解析
- 2021-09-18
- Offset et client pour obtenir des informations sur l'emplacement des éléments Dom
- Mailbox string judgment
- JS realizes modal box dragging
- .Net Core 下使用 Quartz —— 【2】作业和触发器之初步了解作业
猜你喜欢








随机推荐
初步认识Promse
并发优化请求
.Net Core 下使用 Quartz —— 【2】作业和触发器之初步了解作业
时间格式不对,运行sql文件报错
Baidu map coordinates, Google coordinates and Tencent coordinates are mutually transformed
Promise(二)
ES6 specification details
TP6 的 each 遍历用法
Concurrent optimization request
虚拟环境中使用jupyter notebook
Decentralized Collaborative Learning Framework for Next POI Recommendation
tp5 报错variable type error: array解决方法
fdfs启动
JS handwriting compatibility event binding
ASP.NET CORE配置选项(下篇)
Promise(一)
Curry realization of function continuous call calculation and accumulation
Unity3D对象池的理解与小例子
1-2 NodeJS的特点
【代码解析(7)】Communication-Efficient Learning of Deep Networks from Decentralized Data