当前位置:网站首页>Attentional Feature Fusion
Attentional Feature Fusion
2022-08-09 10:04:00 【ZZE15832206526】
Attentional Feature Fusion
目录
Abstract
特征融合是指来自不同层次或分支的特征的组合,是现代网络架构中无所不在的组成部分.它通常通过简单的操作来实现,如求和或连接,但这可能不是最好的选择.在这项工作中,我们提出了一个统一而通用的方案,即注意特征融合,它适用于大多数常见的场景,包括由短、长跳跃连接引起的特征融合以及在初始层内的特征融合.为了更好地融合不一致语义和尺度的特征,我们提出了一个Multi-scale channel attention模块,解决了融合不同尺度给出的特征时出现的问题.我们还证明了特征映射的初始集成可以成为一个瓶颈,这个问题可以通过添加另一个层次的注意力来缓解,我们称之为迭代注意特征融合.由于具有更少的层或参数,我们的模型在CIFAR-100和ImageNet数据集上都优于最先进的网络,这表明更复杂的特征融合注意机制具有巨大的潜力,可以持续产生更好的结果
1.引言
卷积神经网络(CNNs)By going deeper、更宽的、Increase cardinality and dynamic refinement features,这与许多计算机视觉任务的进步相对应.在特征金字塔网络(FPN)[23]和U-Net[30]中,通过长跳连接将低级特征和高级特征融合,获得高分辨率和语义强的特征,这对语义分割和目标检测至关重要.然而,尽管它在现代网络中很流行,但大多数关于特征融合的工作都集中于构建复杂的路径,以组合在不同的内核、组或层中的特征.特征融合方法很少被解决,通常通过简单的操作实现,如加法或连接,只提供固定的线性聚合,完全不知道这种组合是否适合特定的对象.在残差网络(ResNet)and its subsequent work,The identity mapping features and residual learning features are fused as output,Makes the training of very deep networks possible.在特征金字塔网络(FPN)和U-Net中,通过长跳连接将低级特征和高级特征融合,获得高分辨率和语义强的特征,这对语义分割和目标检测至关重要.然而,尽管它在现代网络中很流行,但大多数关于特征融合的工作都集中于构建复杂的路径,以组合在不同的内核、组或层中的特征.特征融合方法很少被解决,通常通过简单的操作实现,如加法或连接,This just provides a fixed linear aggregation,完全不知道这种组合是否适合特定的对象.
近年来,选择性核网络SKNet和ResNeSt被提出基于全局信道注意机制,对同一层中多个核或组的特征进行动态加权平均.虽然这种基于注意力的方法提出了特征融合的非线性方法,但它们仍存在以下缺点:
- 有限的场景:SKNet和ResNeSt只关注同一层的软特征选择,而跳过连接中的跨层融合没有被修饰,使得他们的方案相当启发式.尽管有不同的场景,但各种特性融合实现都面临着相同的挑战,从本质上讲,也就是说,如何集成不同规模的特性以获得更好的性能.A module that can overcome semantic inconsistencies and effectively integrate feature structures of different scales should be able to remain consistent.在各种网络场景下,提高了融合特性的质量.然而,到目前为止,目前还缺乏一种能够以一致的方式统一不同的特征融合场景的通用方法.
- 简单的初始集成:为了将接收到的特征输入注意模块,SKNet以一种非自愿但不可避免的方式引入了另一个特征融合阶段,我们称之为初始集成,并通过加法来实现.因此,除了注意模块的设计外,初始集成方法作为其输入,对融合权值的质量也有很大的影响.考虑到这些特征在规模和语义层面上可能有很大的不一致,一个忽略这个问题的不简单的初始集成策略可能是一个瓶颈.
- 偏置上下文聚合规模:SKNet和ResNeSt中的融合权值是通过全局通道注意机制生成的,这是更全局分布的信息的首选.然而,图像中的物体在大小上可能会有非常大的变化.许多研究都强调了在设计CNN时出现的这个问题,即预测器的接受域应该与对象尺度范围相匹配.因此,Just aggregating contextual information globally is too biased,并削弱了小物体的特征.这就产生了一个问题,即网络是否能够以一种上下文规模感知的方式动态地和自适应地融合接收到的特性.
基于上述观察结果,我们提出了注意特征融合(AFF)模块,试图回答各种特征融合场景的统一方法的问题,并解决上下文聚合和初始集成的问题.AFF框架将基于注意力的特征融合从同一层场景推广到跨层场景,包括短跳过连接和长跳过连接,甚至是AFF本身内部的初始集成.它提供了一种通用和一致的方法来提高各种网络的性能,control network、ResNet、ResNeXt和FPN,通过简单地用提议的AFFThe module replaces the existing feature fusion.此外,AFF框架支持通过将接收到的特征与另一个AFF模块进行迭代积分,逐步细化初始积分,即融合权重发生器的输入,我们称为迭代注意特征融合(iAFF).
为了缓解尺度变化和小物体所带来的问题,We argue that the attention module should also aggregate contextual information from different receptive fields for objects of different scales.更具体地说,我们提出了Multi-scale channel attention模块(MS-CAM),This is a simple yet effective scheme to correct the attentive feature fusion in which the features at different scales are inconsistent.我们的关键观察是,尺度不是空间注意独有的问题,通道注意也可以通过改变空间池的大小而具有全局以外的尺度.MS-CAM通过沿通道维度聚合多尺度上下文信息,可以同时强调更全局分布的大型对象,And highlight small objects that are more locally distributed,促进网络在极端尺度变化下识别和检测的对象.
2.相关工作
2.1.多尺度注意机制
物体的尺度变化是计算机视觉中的关键挑战之一.为了解决这个问题,一种直观的方法是利用多尺度图像金字塔,即在多个尺度上识别对象,并使用非最大抑制将预测相结合.另一项工作是利用CNN固有的多尺度层次特征金字塔来近似图像金字塔,将多层的特征融合,获得高分辨率的语义特征.
深度学习中的注意机制模仿了人类的视觉注意机制,It was originally developed on a global scale.例如,Matrix multiplication in self-attention maps the global dependencies for each word in a sentence or each pixel in an image.Squeeze and excite the network(SENet)将全局空间信息压缩到一个信道描述符中,to capture channel-level dependencies.最近,研究人员开始考虑注意机制的规模问题.与上述处理CNN中尺度变化的方法类似,多尺度注意机制是通过将多尺度特征输入一个注意模块或在一个注意模块内结合多个尺度的特征上下文来实现的.在第一种类型中,将多个尺度的特征或其连接的结果输入注意模块,生成多尺度的注意图,While the feature context aggregation scale within the attention module remains single.第二种类型,也被称为多尺度空间注意,它通过不同大小的卷积核或从注意模块内的金字塔来聚合特征上下文.
提出MS-CAM遵循ParseNetCombine the idea of local and global feature networks and spatial attention with aggregating multi-scale feature contexts in the attention module,But it differs in at least two important ways:1)MS-CAMAsk the question of scale,通过pointwiseConvolutions instead of kernels of different sizes.2)MS-CAMNot in the backbone network,but in the channel-2Local and global feature contexts are aggregated in modules.据我们所知,多尺度渠道的关注以前从未被讨论过.
2.2.在深度学习中跳过连接
跳过连接一直是现代卷积网络中的一个重要组成部分.短时间的跳过连接,即添加在残差块内的身份映射快捷方式,为在反向传播期间不中断的梯度流动提供了另一种路径.长跳过连接通过连接来自较低级的精细细节特征和粗分辨率的高级语义特征,帮助网络获得高分辨率的语义特征.Although used to combine different paths[9]中的特征,但连接特征的融合通常是通过添加或连接来实现的,它以固定的权重分配特征,而不管内容的方差如何.近年来,一些基于注意的方法,如全局注意上采样(Gau)和跳过注意(SA),It has been proposed to use high-level features as a guide,来调节长跳过连接中的低水平特征.然而,被调制特征的融合权值仍然是固定的.
据我们所知,是HighwayFor the first time, the network introduces a selection mechanism in short skip connections.在某种程度上,本文提出的注意力跳过连接可以视为其后续,但不同的三点:1)HighwayThe network employs a simple fully connected layer,Only one scalar fusion weight can be generated,而我们提出MSCAM生成融合权重相同大小feature map,使动态软选择元素的方式.2)HighwayThe network uses only one input feature to generate weights,而我们的AFF模块都知道这两个特性.3)指出了初始特征集成的重要性,并提出了iAFF模块作为一种解决方案.
3.Multi-scale channel attention
3.1在SENetRecover channel attention
Given an intermediate feature X ∈ R C × H × W X∈R^{C×H×W} X∈RC×H×W与Cchannel and sizeH×Wfeature map,SENetChannel attention weights in W ∈ R C W∈R^C W∈RC可以计算为 W = σ ( g ( X ) ) = σ ( β ( W 2 δ ( β ( W 1 ( g ( X ) ) ) ) ) ) W=σ(g(X))=σ(\beta(W_2\delta(\beta(W_1(g(X)))))) W=σ(g(X))=σ(β(W2δ(β(W1(g(X))))))
其中 g ( X ) ∈ R C g(X)∈R^C g(X)∈RC表示全局特征上下文,g(X)是全局平均池(GAP). δ \delta δ表示校正后的线性单位(ReLU),B表示批处理归一化(BN).σ是s型函数.这是通过具有两个完全连接(FC)层的瓶颈来实现的,其中 W 1 ∈ R C / r × C W_1∈R^{C/r×C} W1∈RC/r×C是一个降维层,而 W 2 ∈ R C × C / r W_2∈R^{C×C/r} W2∈RC×C/r是一个增维层.r为通道还原比.
我们可以看到,通道注意将每个大小为H×W的特征图压缩成一个标量.这个极端粗糙的描述符更倾向于强调全局分布的大型对象,并可能消除一个小对象中出现的大部分图像信号.然而,检测非常小的对象是最先进的网络的关键性能瓶颈.例如,COCO的差异性在很大程度上是由于大多数对象实例都小于图像面积的1%.因此,Focusing on global channels may not be the best option.多尺度特征上下文应该聚合在注意模块内,以缓解由尺度变化和小对象实例引起的问题.
3.2聚合本地和全局上下文
在这部分中,我们详细描述了所提出的Multi-scale channel attention模块(MS-CAM).其关键思想是,通过改变空间池化的大小,可以在多个尺度上实现通道注意.为了尽可能保持它的轻量级,我们只是将本地上下文添加到注意模块内的全局上下文中.我们选择PWConv作为本地信道上下文聚合器,It only exploits point-to-channel interactions at each spatial location.为了保存参数,Pass a bottleneck structure to the local channel context L ( X ) ∈ R C × H × W L(X)∈R^{C×H×W} L(X)∈RC×H×W进行计算,如下:
L ( X ) = β ( P W C o n v 2 ( δ ( β ( P W C o n v 1 ( X ) ) ) ) ) L(X) = \beta (PWConv_2 (\delta (\beta (PWConv_1(X))))) L(X)=β(PWConv2(δ(β(PWConv1(X)))))
P W C o n v 1 PWConv_1 PWConv1和 P W C o n v 2 PWConv_2 PWConv2的内核大小分别为 C / r × C × 1 × 1 C/r×C×1×1 C/r×C×1×1, P W C o n v 2 PWConv_2 PWConv2分别为 C × C / r × 1 × 1 C×C/r×1×1 C×C/r×1×1.值得注意的是,L(X)与输入特征具有相同的形状,它可以保留并突出显示低级特征中的细微细节.给定全局信道上下文g(X)和局部信道上下文L(X),通过MS-CAMThe resulting refined features X ′ ∈ R C × H × W X^{'}∈R^{C×H×W} X′∈RC×H×W如下:
X ′ = X ⊗ M ( X ) = X ⊗ σ ( L ( X ) ⊕ g ( X ) ) X^{'} = X ⊗ M(X) = X ⊗ σ (L(X) ⊕ g(X)) X′=X⊗M(X)=X⊗σ(L(X)⊕g(X))
式中, M ( X ) ∈ R C × H × W M(X)∈R^{C×H×W} M(X)∈RC×H×W为MS-CAM产生的注意权重.⊕表示广播加法,⊗表示元素级乘法.
4.注意特征融合
4.1.The uniformity of the feature fusion scene
给定两个特征图 X , Y ∈ R C × H × W X,Y∈R^{C×H×W} X,Y∈RC×H×W,默认情况下,我们假设Y是具有更大接受域的特征图.更具体地说,
- 同层场景:X是3×3内核的输出,Yis in the control network5×5内核的输出;
- Short skip connection scene:X是身份映射,Y是在ResNet块中学习到的残差;
- Long skip connection scenarios:X是低级特征映射,Y是特征金字塔中的高级语义特征映射.
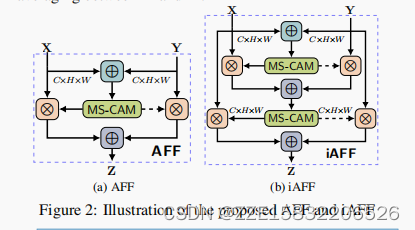
基于多尺度信道注意模块M,注意特征融合(AFF)可以表示为
Z = M ( X ] Y ) ⊗ X + ( 1 − M ( X ] Y ) ) ⊗ Y , ( 4 ) Z = M(X ] Y) ⊗ X + (1 − M(X ] Y)) ⊗ Y, (4) Z=M(X]Y)⊗X+(1−M(X]Y))⊗Y,(4)
其中 Z ∈ R C × H × W Z∈R^{C×H×W} Z∈RC×H×W为融合特征,]表示初始特征积分.在本小节中,为了简单起见,我们选择元素级求和作为初始积分.AFF如图2(a)所示,其中虚线表示1−M(X]Y).需要注意的是,融合权值M(X]Y)由0和1之间的实数组成,1−M(X]Y)也是如此,这使得网络能够在X和Y之间进行软选择或加权平均.
从表1中可以进一步看出,Except for the weight generation moduleG的实现外,State-of-the-art fusion schemes differ mainly in two key points:(a)is the level of context awareness.Linear methods like addition and concatenation are completely context-agnostic.特征的细化和调制是非线性的,但只是部分地意识到输入的特征映射.在大多数情况下,它们只利用高级特性映射.完全上下文感知的方法利用这两种输入特征图作为指导,但代价是提高最初的集成问题.(b)细化vs调制vs选择.在软选择方法中,应用于两个特征映射的权值之和被约束为1,而这不是重新细化和调制的情况.
4.2.迭代注意特征融合
与部分上下文感知的方法不同,完全上下文感知的方法有一个不可避免的问题,即如何最初集成输入特性.作为注意模块的输入,初始整合质量可能会深刻地影响最终的融合权重.由于它仍然是一个特征融合的问题,一个直观的方法是有另一个注意模块来融合输入特征.我们称这种两阶段的方法为迭代注意特征融合(iAFF),如图2(b).所示然后,在等式中的初始积分X]Y可以被重新表述为:
X ] Y = M ( X + Y ) ⊗ X + ( 1 − M ( X + Y ) ) ⊗ Y X ] Y = M(X + Y) ⊗ X + (1 − M(X + Y)) ⊗ Y X]Y=M(X+Y)⊗X+(1−M(X+Y))⊗Y
4.3.示例:InceptionNet、ResNet和FPN
为了验证所提出的AFF/iAFF作为一个统一和通用的方案,我们选择ResNet、FPN和InceptionNet作为最常见的场景:短跳和长跳连接以及同一层融合.通过替换原始的添加或连接,可以直接将AFF/iAFF应用到现有的网络中.具体来说,我们替换了InceptionNet模块中的连接以及ResNet块(ResBlock)和FPN中的添加,以获得注意网络,我们分别称之为AFF-初始模块、AFF-ResBlock和AFF-FPN.这种替换和我们提出的架构的方案如图3所示.
边栏推荐
- What is the reason for the suspended animation of the migration tool in the GBase database?
- 字符串函数和内存函数
- Attentional Feature Fusion
- Master-slave postition changes cannot be locked_Slave_IO_Running shows No_Slave_Sql_Running shows No---Mysql master-slave replication synchronization 002
- EndNoteX9 OR X 20 Guide
- LeetCode(剑指 Offer)- 25. 合并两个排序的链表
- 蓄电池建模、分析与优化(Matlab代码实现)
- 【Linux】宝塔面板设置MySQL慢查询日志,未走索引日志
- Command line query database
- 1. The concept of flow
猜你喜欢
Demand side power load forecasting (Matlab code implementation)
Arrays类、冒泡排序、选择排序、插入排序、稀疏数组!
mac 上安装Redis和配置

实用小技能:一键获取Harbor中镜像信息,快捷查询镜像
![[Machine Learning] Basics of Data Science - Basic Practice of Machine Learning (2)](/img/9f/5afabec1b9ab1871130c8bf1bae472.png)
[Machine Learning] Basics of Data Science - Basic Practice of Machine Learning (2)
Battery modeling, analysis and optimization (Matlab code implementation)
Redis 回击 Dragonfly:13 年后,Redis 的架构依然是同类最佳
文件操作
JDBC中的增删改查操作

搭建Tigase进行二次开发
随机推荐
写一个通讯录小程序
【八大排序④】归并排序、不基于比较的排序(计数排序、基数排序、桶排序)
Redis 缓存主动更新策略
JDBC中的增删改查操作
基本运算符
多线程案例——阻塞式队列
条件控制语句
【八大排序③】快速排序(动图演绎Hoare法、挖坑法、前后指针法)
Master-slave postition changes cannot be locked_Slave_IO_Running shows No_Slave_Sql_Running shows No---Mysql master-slave replication synchronization 002
m个样本的梯度下降
慕课网-简易扑克牌游戏 思路清晰 简易版
【Linux】宝塔面板设置MySQL慢查询日志,未走索引日志
循环嵌套以及列表的基本操作
Tom Morgan | Twenty-One Rules of Life
程序环境和预处理
Command line query database
Dream Notes 0809
3. Coding method
元组 字典 集合
The GNU Privacy Guard