当前位置:网站首页>盘点检索任务中的损失函数
盘点检索任务中的损失函数
2022-08-08 17:31:00 【FightingCV】

【写在前面】
最近在看检索和匹配相关的任务,之前对这个任务不太了解,只知道就是相似度对比,找出相似度最高的样本就可以了。但是了解之后,在模型训练过程中,有许多方法(损失函数)来拉近正样本的距离,拉远负样本的距离。
Triplet loss
先从最经典的三元组 loss 说起, 三元组的构成:从训练数据集中随机选一个样本,该样本称为Anchor,然后再随机选取一个和Anchor属于同一类的样本和不同类的样本,这两个样本对应的称为Positive 和Negative,由此构成一个三元组。
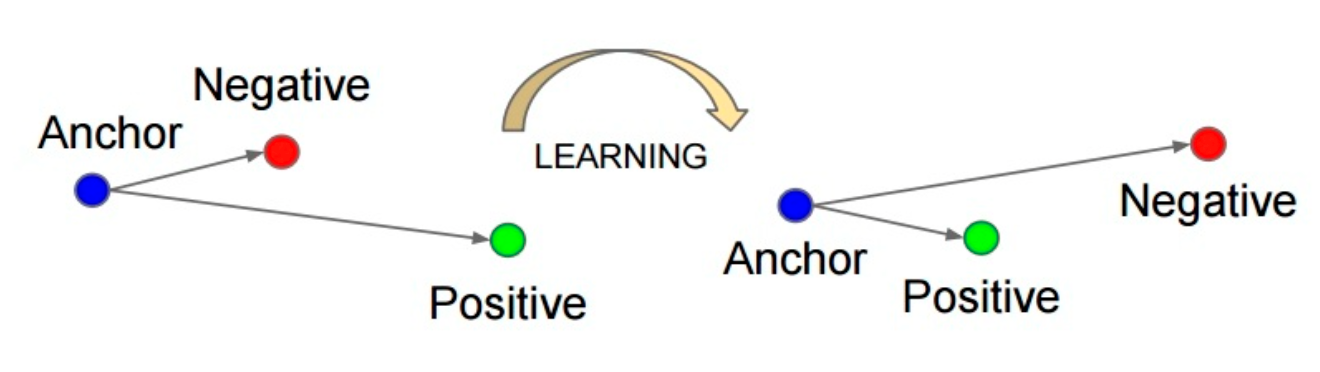
通过学习,让正样本特征表达之间的距离尽可能小,而负样本的特征表达之间的距离尽可能大,并且要让正样本之间的距离和负样本之间的距离之间有一个最小的间隔(margin)。 损失函数如下所示:
相当于一个ReLU函数。
Sum Hinge Loss & Max Hinge Loss
接下来介绍一下和 Triplet loss 非常接近的 loss Max Hinge loss,像是 Triplet loss 的升维操作。
Triplet loss 的输入是 (a, p, n),一般的做法是 b 个 (ai,pi) i∈[0,b] pair 对,我们对 pi 旋转一下得到 (p1,p2,...,pb,p0) 作为负样本列表。最后得到一个一维的 loss 向量 (l1,l2...,lb)。
Triplet loss 实际上只考虑了由 a 和 p 组成矩阵的部分情况产生的loss,我们实际上可以对 a、p 产生的相似度矩阵中所有非对角线的负样本进行计算损失,从而充分利用 batch 内的信息,通过这个思路我们可以得到 Sum Hinge Loss 如下,Triplet loss 的计算中是用的 L2 距离,这里改为了余弦相似度,所以之前的 ap - an + margin,改为了 an - ap + margin 了,目标是让 an 的相似度更小,ap 的相似度更大
Sum Hinge Loss
Max Hinge Loss
VSE++ 提出了一个新的损失函数max hinge loss,它主张在排序过程中应该更多地关注困难负样例,困难负样本是指与anchor靠得近的负样本,实验结果也显示max hinge loss性能比之前常用的排序损失sum hinge loss好很多:
Max Hinge Loss pytorch 代码如下:
def cosine_sim(im, s):
"""Cosine similarity between all the image and sentence pairs
"""
return im.mm(s.t())
class MaxHingLoss(nn.Module):
def __init__(self, margin=0.2, measure=False, max_violation=True):
super(MaxHingLoss, self).__init__()
self.margin = margin
self.sim = cosine_sim
self.max_violation = max_violation
def forward(self, im, s):
an = self.sim(im, s) # an
diagonal = scores.diag().view(im.size(0), 1)
ap1 = diagonal.expand_as(scores)
ap2 = diagonal.t().expand_as(scores)
# query2doc retrieval
cost_s = (self.margin + an - ap1).clamp(min=0)
# doc2query retrieval
cost_im = (self.margin + an - ap2).clamp(min=0)
# clear diagonals
mask = torch.eye(scores.size(0)) > .5
I = Variable(mask)
if torch.cuda.is_available():
I = I.cuda()
cost_s = cost_s.masked_fill_(I, 0)
cost_im = cost_im.masked_fill_(I, 0)
# keep the maximum violating negative for each query
if self.max_violation:
cost_s = cost_s.max(1)[0][:1]
cost_im = cost_im.max(0)[0][:1]
return cost_s.mean() + cost_im.mean()
# or # return cost_s.sum() + cost_im.sum()
NCE
NCE(noise contrastive estimation)核心思想是将多分类问题转化成二分类问题,一个类是数据类别 data sample,另一个类是噪声类别 noisy sample,通过学习数据样本和噪声样本之间的区别,将数据样本去和噪声样本做对比,也就是“噪声对比(noise contrastive)”,从而发现数据中的一些特性。但是,如果把整个数据集剩下的数据都当作负样本(即噪声样本),虽然解决了类别多的问题,计算复杂度还是没有降下来,解决办法就是做负样本采样来计算loss,这就是estimation的含义,也就是说它只是估计和近似。一般来说,负样本选取的越多,就越接近整个数据集,效果自然会更好。
NCE loss 函数如下,一个正样本的二分类和 k 个负样本的二分类:
Info NCE
Info NCE loss是NCE的一个简单变体,它认为如果你只把问题看作是一个二分类,只有数据样本和噪声样本的话,可能对模型学习不友好,因为很多噪声样本可能本就不是一个类,因此还是把它看成一个多分类问题比较合理(但这里的多分类 k 指代的是负采样之后负样本的数量),于是就有了InfoNCE loss 函数如下:
其中相当于是 logits, 是温度系数,整体和 cross entropy 是非常相近的。

温度系数的作用就是控制了模型对负样本的区分度。
OHEM(Online Hard Example Mining)
Hard Negatie Mining与Online Hard Example Mining(OHEM)都属于难例挖掘,它是解决目标检测老大难问题的常用办法,运用于R-CNN,fast R-CNN,faster rcnn等two-stage模型与SSD等(有anchor的)one-stage模型训练时的训练方法。(个人理解就是只计算Top K的难例的loss)
OHEM和难负例挖掘名字上的不同。
Hard Negative Mining只注意难负例
OHEM 则注意所有难例,不论正负(Loss大的例子)
难例挖掘的思想可以解决很多样本不平衡/简单样本过多的问题,比如说分类网络,将hard sample 补充到数据集里,重新丢进网络当中,就好像给网络准备一个错题集,哪里不会点哪里。
def ohem_loss(
batch_size, cls_pred, cls_target, loc_pred, loc_target, smooth_l1_sigma=1.0
):
"""
Arguments:
batch_size (int): number of sampled rois for bbox head training
loc_pred (FloatTensor): [R, 4], location of positive rois
loc_target (FloatTensor): [R, 4], location of positive rois
pos_mask (FloatTensor): [R], binary mask for sampled positive rois
cls_pred (FloatTensor): [R, C]
cls_target (LongTensor): [R]
Returns:
cls_loss, loc_loss (FloatTensor)
"""
ohem_cls_loss = F.cross_entropy(cls_pred, cls_target, reduction='none', ignore_index=-1)
ohem_loc_loss = smooth_l1_loss(loc_pred, loc_target, sigma=smooth_l1_sigma, reduce=False)
#这里先暂存下正常的分类loss和回归loss
loss = ohem_cls_loss + ohem_loc_loss
#然后对分类和回归loss求和
sorted_ohem_loss, idx = torch.sort(loss, descending=True)
#再对loss进行降序排列
keep_num = min(sorted_ohem_loss.size()[0], batch_size)
#得到需要保留的loss数量
if keep_num < sorted_ohem_loss.size()[0]:
#这句的作用是如果保留数目小于现有loss总数,则进行筛选保留,否则全部保留
keep_idx_cuda = idx[:keep_num]
#保留到需要keep的数目
ohem_cls_loss = ohem_cls_loss[keep_idx_cuda]
ohem_loc_loss = ohem_loc_loss[keep_idx_cuda]
#分类和回归保留相同的数目
cls_loss = ohem_cls_loss.sum() / keep_num
loc_loss = ohem_loc_loss.sum() / keep_num
#然后分别对分类和回归loss求均值
return cls_loss, loc_loss
一些不相关的内容
1. 为什么LogSoftmax比Softmax更好?
log_softmax能够解决函数overflow和underflow,加快运算速度,提高数据稳定性。
因为softmax[1]会进行指数操作,当上一层的输出,也就是softmax的输入比较大的时候,可能就会产生overflow。比如上图中,z1、z2、z3[2]取值很大的时候,超出了float[3]能表示的范围。
同理当输入为负数且绝对值也很大的时候,会分子、分母会变得极小,有可能四舍五入为0,导致下溢出。
尽管在数学表示式上是对softmax在取对数的情况。但是在实操中是通过:
来实现,其中 ,即 M为所有中最大的值。可以解决这个问题,在加快运算速度的同时,可以保持数值的稳定性。
2. 什么是label smoothing?
label smoothing是一种正则化的方式,全称为Label Smoothing Regularization(LSR),即标签平滑正则化。
在传统的分类任务计算损失的过程中,是将真实的标签做成one-hot的形式,然后使用交叉熵来计算损失。而label smoothing是将真实的one hot标签做一个标签平滑处理,使得标签变成又概率值的soft label.其中,在真实label处的概率值最大,其他位置的概率值是个非常小的数。
在label smoothing中有个参数epsilon,描述了将标签软化的程度,该值越大,经过label smoothing后的标签向量的标签概率值越小,标签越平滑,反之,标签越趋向于hard label,在训练ImageNet-1k的实验里通常将该值设置为0.1。
参考文献
https://zhuanlan.zhihu.com/p/514859125[4]
https://www.zhihu.com/question/358069078/answer/912691444[5]
已建立深度学习公众号——FightingCV,欢迎大家关注!!!
ICCV、CVPR、NeurIPS、ICML论文解析汇总:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading
面向小白的Attention、重参数、MLP、卷积核心代码学习:https://github.com/xmu-xiaoma666/External-Attention-pytorch
加入交流群,请添加小助手wx:FightngCV666
参考资料
softmax: https://www.zhihu.com/search?q=softmax&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={"sourceType":"answer","sourceId":"912691444"}
[2]z3: https://www.zhihu.com/search?q=z3&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={"sourceType":"answer","sourceId":"912691444"}
[3]float: https://www.zhihu.com/search?q=float&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={"sourceType":"answer","sourceId":"912691444"}
[4]https://zhuanlan.zhihu.com/p/514859125: https://zhuanlan.zhihu.com/p/514859125
[5]https://www.zhihu.com/question/358069078/answer/912691444: https://www.zhihu.com/question/358069078/answer/912691444
边栏推荐
猜你喜欢









随机推荐
L2-015 互评成绩 (25 分)
Obtain - 64 [chances] : the soldier, subtlety also - 5 - read sun tzu - melee meter
DSPE-PEG-NH2,DSPE-PEG-amine,474922-26-4,磷脂-聚乙二醇-氨基科研试剂
LeetCode_回溯_中等_491.递增子序列
Tensorflow教程(四)——MNIST项目入门
Fluorescein-PEG-CLS,胆固醇-聚乙二醇-荧光素用于缩短包封周期
【TypeScript】函数类型:返回值类型和参数类型到底如何定义?
彻底理解 volatile 关键字及应用场景,面试必问,小白都能看懂!
Open source summer | I have nothing to do during the epidemic, I made a button display box special effect to display my blog
离线安装 Anaconda + TensorFlow
第二十章 源代码文件 REST API 参考(二)
2.MySQL链接和创建数据库,创建数据表
B. Stairs
L2-024 部落 (25 分)(并查集)
glide4入门
手机ETF基金开户哪家证券公司好?哪个更安全
DSPE-PEG-Biotin,385437-57-0,磷脂-聚乙二醇-生物素用于生物分子的检测和纯化
Qt——获取文件夹下所有子文件名称
Appium 自动化测试环境搭建
瑞利衰落条件下扩频通信系统误码率仿真