当前位置:网站首页>28.异常检测
28.异常检测
2022-08-08 04:44:00 【WuJiaYFN】
文章目录
一、异常检测的概念和应用
1.1 异常检测的概念
异常检测(Anomaly detection)问题——这是机器学习算法的一个常见应用。这种算法的一个有趣之处在于:它虽然主要用于非监督学习问题,但从某些角度看,它又类似于一些监督学习问题
所谓的异常检测问题就是:我们希望知道这个新的飞机引擎是否有某种异常,或者说,我们希望判断这个引擎是否需要进一步测试
异常检测是指在给定的一组无标签数据集 x ( 1 ) , x ( 2 ) , . . . , x ( m ) { x ^{( 1 )} ,x ^{( 2 )}, . . . , x ^{( m )} } x(1),x(2),...,x(m),针对这组数据集训练一个模型 p ( x ) p ( x ) p(x),来判定某个数据和数据集中大多数数据之间的相似程度(某个数据落在给定数据集中心区域的概率),
- 若某个数据 x t e s t x _{t e s t} xtest和大多数给定数据之间很相似,则 p ( x t e s t ) ≥ ϵ p ( x _{t e s t} ) ≥ ϵ p(xtest)≥ϵ,说明数据无明显异常情况;
- 否则 p ( x t e s t ) < ϵ p ( x _{t e s t} ) < ϵ p(xtest)<ϵ,说明数据 x t e s t x _{t e s t} xtest和大多数数据之间差异很大,说明给定的数据可能是一个异常数据

在上图中,蓝色圈内的数据属于该组数据的可能性较高;而越偏远,属于该组数据的可能性就越低。 这种方法称为密度估计,表达式如下:

即若某个数据不落在大多数数据所在的范围之内,则这种数据出现的概率比较小,将检测出的这种数据视为异常数据
1.2 异常检测的应用
- 飞机引擎检测:给定一系列正常的引擎参数,要求确定一个新生产的引擎是否正常,或者说,我们希望判断这个引擎是否需要进一步测试;
- 异常检测主要用来识别欺骗,异常用户检测:网站检测用户刷新频率,登录次数、登陆位置等信息,判断用户行为是否异常;根据特征构建一个模型,可以用这个模型来识别那些不符合该模式的用户
- 数据中心的计算机检测:检测计算机内存消耗、硬盘容量等信息,判断计算机是否异常;
二、高斯分布
高斯分布,也称为正态分布
通常如果我们认为变量 x x x 符合高斯分布 x ∼ N ( μ , σ 2 ) x \sim N(\mu, \sigma^2) x∼N(μ,σ2)则其概率密度函数为:
p ( x , μ , σ 2 ) = 1 2 π σ exp ( − ( x − μ ) 2 2 σ 2 ) p(x,\mu,\sigma^2)=\frac{1}{\sqrt{2\pi}\sigma}\exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right) p(x,μ,σ2)=2πσ1exp(−2σ2(x−μ)2)- μ \mu μ 是均值
- σ是标准差,确定了高斯分布概率密度函数的宽度
- σ2就是方差
- 概率密度函数与x轴的面积为1,即积分值=1

可以利用已有的数据来预测总体中的 μ μ μ和 σ 2 σ^2 σ2的计算方法如下:
- μ = 1 m ∑ i = 1 m x ( i ) \mu=\frac{1}{m}\sum\limits_{i=1}^{m}x^{(i)} μ=m1i=1∑mx(i)
- σ 2 = 1 m ∑ i = 1 m ( x ( i ) − μ ) 2 \sigma^2=\frac{1}{m}\sum\limits_{i=1}^{m}(x^{(i)}-\mu)^2 σ2=m1i=1∑m(x(i)−μ)2
高斯分布样例如下图(其中 μ 决定中心点的位置, σ2 决定曲线的高度):

机器学习中对于方差我们通常只除以 m m m而非统计学中的 ( m − 1 ) (m-1) (m−1)
- 在实际使用中,到底是选择使用 1 / m 1/m 1/m还是 1 / ( m − 1 ) 1/(m-1) 1/(m−1)其实区别很小,只要你有一个还算大的训练集,在机器学习领域大部分人更习惯使用 1 / m 1/m 1/m这个版本的公式
- 这两个版本的公式在理论特性和数学特性上稍有不同,但是在实际使用中,他们的区别甚小,几乎可以忽略不计
三、异常检测算法
- 利用高斯分布开发异常检测算法
3.1 密度估计
对于给定的数据集 x ,针对每一个特征计算均值 μ 和方差 σ2 的估计值。然后,当出现一个新的训练实例,可以根据模型计算其对应的 p(x),这个过程也叫做密度估计(Density estimation),公式如下:

(注:每个特征 xi 都对应不同的高斯分布)

3.2 异常检测算法
异常检测的具体流程:
首先针对 m m m个数据样本选择出 n n n个可能出现异常的特征 x j , j ∈ n x_j , j ∈ n xj,j∈n;
之后针对所有样本计算每一个特征的均值 μ j , j ∈ n μ_j , j ∈ n μj,j∈n和方差 σ j 2 , j ∈ n σ_j^ 2 , j ∈ n σj2,j∈n;
针对新给定的某个数据 x x x计算 p ( x ) p ( x ) p(x),若 p ( x ) < ϵ p ( x ) < ϵ p(x)<ϵ,则判定数据为异常数据

3.3 具体例子
下图2D 图形是一个具有两个特征的训练集及其两个特征的分布情况,3D 图形表示密度估计函数,z轴为根据两个特征对 x t e s t x_{test} xtest估计出的 p ( x ) p(x) p(x)值

选择一个 ε=0.02,将p(x) = ε作为决策边界,当p(x) > ε时预测为正常数据,否则为异常
四、开发和评价一个异常检测系统
4.1 数据的划分
异常检测算法是一个无监督学习算法
但事实上,如果我们拥有一些带标记的数据,为了检验算法是否有效
可以在最开始将其看作一个监督学习算法将已有数据分开
从中选择一部分正常数据作为训练集,
剩下的正常数据和异常数据混合构成交叉检验集和测试集

4.2 具体的算法评估方法
根据测试集数据,我们估计特征的平均值和方差并构建 p ( x ) p(x) p(x)函数
对交叉检验集,我们尝试使用不同的 ε \varepsilon ε值作为阀值,并预测数据是否异常,根据** F 1 F1 F1值或者查准率与查全率的比例来选择 ε \varepsilon ε**
选出 ε \varepsilon ε 后,针对测试集进行预测,计算异常检验系统的 F 1 F1 F1值,或者查准率与查全率之比

4.3 具体例子
我们有10000台正常引擎的数据,有20台异常引擎的数据。 我们这样分配数据:
- 6000台正常引擎的数据作为训练集
- 2000台正常引擎和10台异常引擎的数据作为交叉检验集
- 2000台正常引擎和10台异常引擎的数据作为测试集
还有一些人把同样一组数据既用作交叉检验CV集,也用作测试Test集,但不推荐这样做

五、异常检测与监督学习对比
| 异常检测 | 监督学习 |
|---|---|
| 非常少量的正向类(异常数据 y = 1 y=1 y=1), 大量的负向类( y = 0 y=0 y=0) | 同时有大量的正向类和负向类 |
| 许多不同种类的异常,非常难。根据非常 少量的正向类数据来训练算法。 | 有足够多的正向类实例,足够用于训练 算法,未来遇到的正向类实例可能与训练集中的非常近似。 |
| 未来遇到的异常可能与已掌握的异常、非常的不同。 | |
| 例如: 欺诈行为检测 生产(例如飞机引擎)检测数据中心的计算机运行状况 | 例如:邮件过滤器 天气预报 肿瘤分类 |
- 通常来说,正样本的数量很少,甚至有时候是0,也就是说,出现了太多没见过的不同的异常类型,那么对于这些问题,通常应该使用的算法就是异常检测算法
六、特征选择
6.1 特征转换
异常检测假设特征符合高斯分布,如果数据的分布不是高斯分布,异常检测算法也能够工作,但是最好还是将数据转换成高斯分布
例如使用对数函数: x = l o g ( x + c ) x= log(x+c) x=log(x+c),其中 c c c 为非负常数; 或者 x = x c x=x^c x=xc, c c c为 0-1 之间的一个分数等方法(注:在python中,通常用
np.log1p()函数, l o g 1 p log1p log1p就是 l o g ( x + 1 ) log(x+1) log(x+1),可以避免出现负数结果,反向函数就是np.expm1())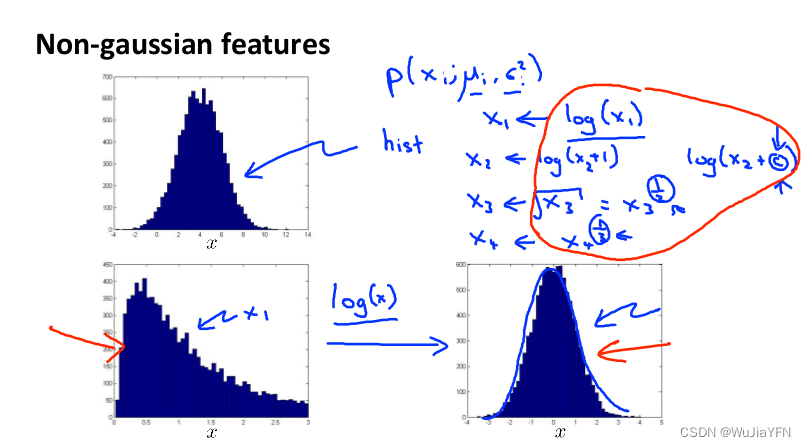
6.2 误差分析
一个常见的问题是一些异常的数据可能也会有较高的 p ( x ) p(x) p(x)值,因而被算法认为是正常的
误差分析能够帮助我们,我们可以分析那些被算法错误预测为正常的数据,观察能否找出一些问题。我们可能能从问题中发现我们需要增加一些新的特征,增加这些新特征后获得的新算法能够帮助我们更好地进行异常检测
通常可以通过将一些相关的特征进行组合,来获得一些新的更好的特征(异常数据的该特征值异常地大或小)。例如增加两个特征值的比例
误差分析步骤: 同监督学习,先简单地搞出一套完整的算法,然后用验证集对其进行验证,然后对判断错误的验证集样本进行分析,看能不能找到一些其他的特征,让这些判断出错的样本能表现得更好

6.3 具体例子
例如,在检测计算机状况的例子中,可以用 CPU负载与网络通信量的比例作为一个新的特征,如果该值异常地大,便有可能意味着该服务器是陷入了一些问题中。如下图:

七、多元高斯分布
7.1 多元高斯分布的概念
假使我们有两个相关的特征,而且这两个特征的值域范围比较宽,这种情况下,一般的高斯分布模型可能不能很好地识别异常数据。其原因在于,一般的高斯分布模型尝试的是去同时抓住两个特征的偏差,因此创造出一个比较大的判定边界
下图中是两个相关特征,洋红色的线(根据ε的不同其范围可大可小)是一般的高斯分布模型获得的判定边界,很明显绿色的X所代表的数据点很可能是异常值,但是其 p ( x ) p(x) p(x)值却仍然在正常范围内
如果使用多元高斯分布,获得蓝色曲线所示的判定边界,范围更小,判定结果会更准确

在多元高斯分布模型中,我们将构建特征的协方差矩阵,用所有的特征一起来计算 p ( x ) p(x) p(x)。
我们首先计算所有特征的平均值,然后再计算协方差矩阵:
p ( x ) = ∏ j = 1 n p ( x j ; μ , σ j 2 ) = ∏ j = 1 n 1 2 π σ j e x p ( − ( x j − μ j ) 2 2 σ j 2 ) p(x)=\prod_{j=1}^np(x_j;\mu,\sigma_j^2)=\prod_{j=1}^n\frac{1}{\sqrt{2\pi}\sigma_j}exp(-\frac{(x_j-\mu_j)^2}{2\sigma_j^2}) p(x)=∏j=1np(xj;μ,σj2)=∏j=1n2πσj1exp(−2σj2(xj−μj)2)
μ = 1 m ∑ i = 1 m x ( i ) \mu=\frac{1}{m}\sum_{i=1}^mx^{(i)} μ=m1∑i=1mx(i)
Σ = 1 m ∑ i = 1 m ( x ( i ) − μ ) ( x ( i ) − μ ) T = 1 m ( X − μ ) T ( X − μ ) \Sigma = \frac{1}{m}\sum_{i=1}^m(x^{(i)}-\mu)(x^{(i)}-\mu)^T=\frac{1}{m}(X-\mu)^T(X-\mu) Σ=m1∑i=1m(x(i)−μ)(x(i)−μ)T=m1(X−μ)T(X−μ)
注:其中 μ \mu μ 是一个向量,其每一个单元都是原特征矩阵中一行数据的均值。最后我们计算多元高斯分布的 p ( x ) p\left( x \right) p(x):
p ( x ) = 1 ( 2 π ) n 2 ∣ Σ ∣ 1 2 e x p ( − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ) p(x)=\frac{1}{(2\pi)^{\frac{n}{2}}|\Sigma|^{\frac{1}{2}}}exp\left(-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu)\right) p(x)=(2π)2n∣Σ∣211exp(−21(x−μ)TΣ−1(x−μ))
其中: ∣ Σ ∣ |\Sigma| ∣Σ∣是定矩阵,在 Octave 中用
det(sigma)计算; Σ − 1 \Sigma^{-1} Σ−1 是逆矩阵
7.2 协方差矩阵对模型的影响
协方差对角线上的值影响图像的平缓程度,逆对角线上的值影响图像的角度(正值为顺时针旋转45度,负值为逆时针45度)

- 图像从左往右:
a. 一般的高斯分布模型
b. 令特征 1 拥有较小的偏差,同时保持特征 2 的偏差
c. 令特征 2 拥有较大的偏差,同时保持特征 1 的偏差
d. 在不改变两个特征的原有偏差的基础上,增加两者之间的正相关性
e. 在不改变两个特征的原有偏差的基础上,增加两者之间的负相关性
- 图像从左往右:
7.3 均值 µ 对中心点的影响
改变μ就是改变中心点的位置,在中心点具有最高的概率值

八、 使用多元高斯分布进行异常检测
8.1 使用多元高斯分布来进行异常检测
计算出均值 µ 和协方差矩阵 Σ
- μ \mu μ 是你的训练样本的平均值: μ = 1 m ∑ i = 1 m x ( i ) \mu=\frac{1}{m}\sum_{i=1}^{m}x^{(i)} μ=m1∑i=1mx(i)
- Σ \Sigma Σ: Σ = 1 m ∑ i = 1 m ( x ( i ) − μ ) ( x ( i ) − μ ) T \Sigma=\frac{1}{m}\sum_{i=1}^{m}(x^{(i)}-\mu)(x^{(i)}-\mu)^T Σ=m1∑i=1m(x(i)−μ)(x(i)−μ)T
对新实例 x, 根据公式计算其 p(x) 的值,如果小于 ε 则异常

8.2 原始高斯分布模型 和 多元高斯分布模型

对于一个多元高斯分布模型,如果其协方差矩阵只有正对角线上元素非零,则退化为原始高斯分布模型
原高斯分布模型 多元高斯分布模型 不能捕获特征之间的相关性,但可以通过将特征进行组合的方法来解决 自动捕获特征之间的相关性 计算代价低,能适应大规模的特征 计算代价高,训练集较小时也同样适应 必须要有 m > n , 不然的话协方差矩阵不可逆,通常需要 m > 10n ,另外特征冗余会导致协方差矩阵不可逆

- 两个模型的选择:
- 原高斯分布模型被广泛使用,如果特征之间在某种程度上相互关联,可以通过构造新特征的方法来捕捉这些相关性
- 如果训练集不是太大,并且没有太多的特征,可以使用多元高斯分布模型
边栏推荐
- Let your text be seen by more people: Come and contribute, the payment is reliable!
- 关于如何做选择
- leetcode: 455. 分发饼干
- 一小时掌握vim基础用法
- vulnhub-DC-3 drone penetration record
- Building a High-Performance Platform on AWS Using Presto and Alluxio to Support Real-Time Gaming Services
- L3-006 迎风一刀斩
- leetcode 112.路经总和 递归
- y90. Chapter 6 Microservices, Service Grids and Envoy Combat -- Service Grid Basics (1)
- 【着色器实现Tricolor三原色型变效果_Shader效果第十八篇】
猜你喜欢

C language - score and loop statement

KDD‘22推荐系统论文梳理(24篇研究&36篇应用论文)

y90. Chapter 6 Microservices, Service Grids and Envoy Combat -- Service Grid Basics (1)

KMP和EXKMP(Z函数)

《动机与人格》笔记(一)——人类似乎从来就没有长久地感到过心满意足

机器学习笔记:学习率预热 warmup

【OAuth2】十八、OIDC的认识应用
![[opencv] Introduction to opencv development kit](/img/1a/7b60426d109c9f7231c67e4a4dad46.png)
[opencv] Introduction to opencv development kit

数据库篇复习篇

leetcode 112.路经总和 递归
随机推荐
如何保存页面的当前的状态
topk()/eq( ) / gt( ) / lt( ) / t( )的用法
全网唯一OpenCyphal/UAVCAN教程(11)用candump和gawk工具写一个Cyphal协议解析小工具
L3-006 Slash in the wind
reduce具体使用以及使用reduce,toString,flat进行数组降维
QMI8658 - 6轴传感器学习笔记 - Ⅱ
Entering the world of audio and video - RGB and YUV formats
leetcode: 874. Simulate a walking robot
leetcode: 322.零钱兑换
走进音视频的世界——RGB与YUV格式
CARLA 笔记(05)— Actors and blueprints(创建和修改 Blueprint、生成 Spawning、使用 Handling、销毁 Destruction)
硬盘基础知识
Let your text be seen by more people: Come and contribute, the payment is reliable!
Error: [Intervention] Unable to preventDefault inside passive event listener due to target ...
leetcode: 122. 买卖股票的最佳时机 II
中间件的一些坑记录
【OAuth2】十八、OIDC的认识应用
风控策略必学|这种用决策树来挖掘规则的方法
Flatten multidimensional array to one dimension
分类、目标检测、语义分割、实例分割的区别