AdaBound




An optimizer that trains as fast as Adam and as good as SGD, for developing state-of-the-art deep learning models on a wide variety of popular tasks in the field of CV, NLP, and etc.
Based on Luo et al. (2019). Adaptive Gradient Methods with Dynamic Bound of Learning Rate. In Proc. of ICLR 2019.
Quick Links
Installation
AdaBound requires Python 3.6.0 or later. We currently provide PyTorch version and AdaBound for TensorFlow is coming soon.
Installing via pip
The preferred way to install AdaBound is via pip with a virtual environment. Just run
pip install adabound
in your Python environment and you are ready to go!
Using source code
As AdaBound is a Python class with only 100+ lines, an alternative way is directly downloading adabound.py and copying it to your project.
Usage
You can use AdaBound just like any other PyTorch optimizers.
optimizer = adabound.AdaBound(model.parameters(), lr=1e-3, final_lr=0.1)
As described in the paper, AdaBound is an optimizer that behaves like Adam at the beginning of training, and gradually transforms to SGD at the end. The final_lr parameter indicates AdaBound would transforms to an SGD with this learning rate. In common cases, a default final learning rate of 0.1 can achieve relatively good and stable results on unseen data. It is not very sensitive to its hyperparameters. See Appendix G of the paper for more details.
Despite of its robust performance, we still have to state that, there is no silver bullet. It does not mean that you will be free from tuning hyperparameters once using AdaBound. The performance of a model depends on so many things including the task, the model structure, the distribution of data, and etc. You still need to decide what hyperparameters to use based on your specific situation, but you may probably use much less time than before!
Demos
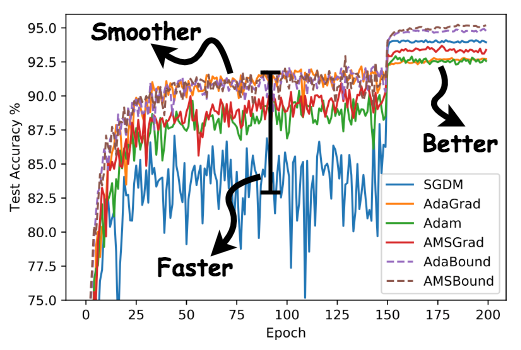
Thanks to the awesome work by the GitHub team and the Jupyter team, the Jupyter notebook (.ipynb) files can render directly on GitHub. We provide several notebooks (like this one) for better visualization. We hope to illustrate the robust performance of AdaBound through these examples.
For the full list of demos, please refer to this page.
Citing
If you use AdaBound in your research, please cite Adaptive Gradient Methods with Dynamic Bound of Learning Rate.
@inproceedings{Luo2019AdaBound,
author = {Luo, Liangchen and Xiong, Yuanhao and Liu, Yan and Sun, Xu},
title = {Adaptive Gradient Methods with Dynamic Bound of Learning Rate},
booktitle = {Proceedings of the 7th International Conference on Learning Representations},
month = {May},
year = {2019},
address = {New Orleans, Louisiana}
}










 1k Dec 28, 2022
1k Dec 28, 2022
 8.7k Dec 31, 2022
8.7k Dec 31, 2022
 180 Dec 30, 2022
180 Dec 30, 2022
 105 Dec 16, 2022
105 Dec 16, 2022
 1.8k Jan 06, 2023
1.8k Jan 06, 2023
 55 Dec 01, 2022
55 Dec 01, 2022
 169 Dec 23, 2022
169 Dec 23, 2022
 3.7k Dec 29, 2022
3.7k Dec 29, 2022
 300 Dec 11, 2022
300 Dec 11, 2022
 107 Apr 20, 2022
107 Apr 20, 2022
 251 Dec 25, 2022
251 Dec 25, 2022
 592 Jan 07, 2023
592 Jan 07, 2023
 1.7k Jan 06, 2023
1.7k Jan 06, 2023
 2.6k Jan 03, 2023
2.6k Jan 03, 2023
 704 Dec 14, 2022
704 Dec 14, 2022
 4.1k Dec 28, 2022
4.1k Dec 28, 2022
 203 Nov 28, 2022
203 Nov 28, 2022
 1.2k Jan 07, 2023
1.2k Jan 07, 2023
 150 Dec 24, 2022
150 Dec 24, 2022