Transliterator Text Editor
This is a simple transliteration program which is used to convert english word to phonetically matching word in another language.
Tkinter is used for text editor creation and indic-transliteration is used for transliteration function.
Requirements
- The system should have python3 installed. Ths system is tested on python 3.8.
- The system works on linux and Mac. Minor changes may be required to run this on windows OS.
- The code requires tkinter to be installed in the system
How to use
- download or clone the repository using command
git clone - It is recommended to run the code in a separate virtual environment.
- Add the required packages by the command
pip install -r requirements.txt - Get into the main folder
transliterator_text_editorbycd transliterator_text_editorin terminal. - run
python3 main.py. This will open the text editor in another window. - The text editor is self-explanatory.
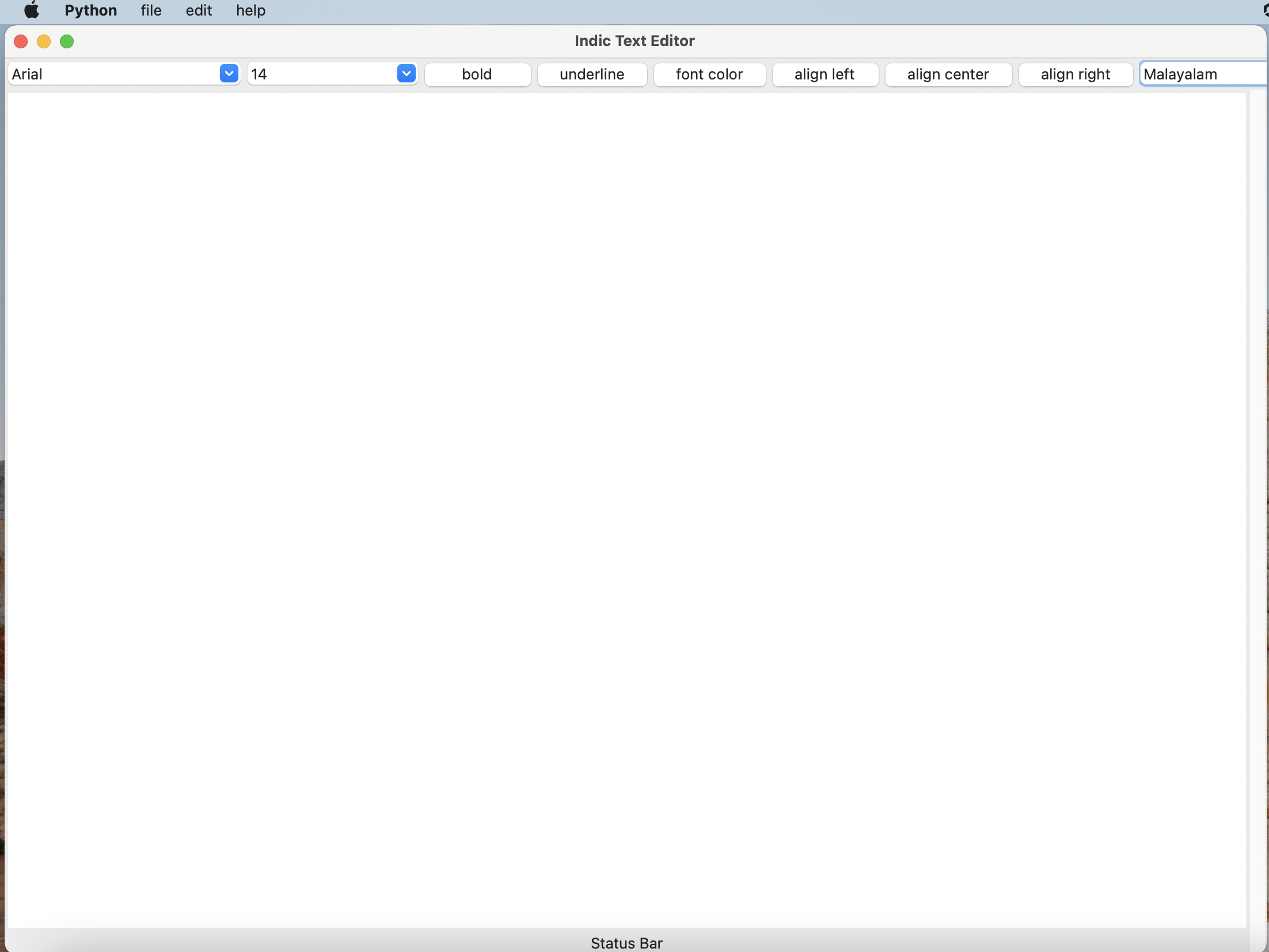
Features
- Text editor in which the typed english word will be converted to another language on pressing space or enter key.
- The text editor has options file save, open, save as, new etc.
Languages Supported
As the program uses the module indic transliterator the languages available in it will be available. Detailed documentation can be found in https://pypi.org/project/indic-transliteration/ . The languages are
- Devanagari
- Gujarati
- Gurmukhi
- Gondi_Gunjala
- Bengali
- Oriya
- Kannada
- Malayalam
- Tamil
- Grantha
- Telugu
Future Scope
- Improve learning algorithm
- Conversion of an entire file at once, Delete file etc
- Add option select all, points, new window etc.
Contributions
- Pull requests are welcome. If someone wants to contribute to this project can fork and add the Functionalities.

 23 Oct 27, 2022
23 Oct 27, 2022
 15 Oct 24, 2022
15 Oct 24, 2022
 9 Sep 13, 2021
9 Sep 13, 2021
 1 Nov 27, 2021
1 Nov 27, 2021
 2 Apr 24, 2022
2 Apr 24, 2022
 70 Dec 06, 2022
70 Dec 06, 2022
 1 Jan 06, 2022
1 Jan 06, 2022
 112 Dec 22, 2022
112 Dec 22, 2022
 2 Apr 05, 2022
2 Apr 05, 2022
 99 Jan 06, 2023
99 Jan 06, 2023
 74 Dec 05, 2022
74 Dec 05, 2022
 22 Dec 27, 2022
22 Dec 27, 2022
 0 Aug 06, 2021
0 Aug 06, 2021
 11.4k Jan 01, 2023
11.4k Jan 01, 2023
 28 Nov 21, 2022
28 Nov 21, 2022
 6 May 22, 2022
6 May 22, 2022
 5 Nov 23, 2022
5 Nov 23, 2022
 1.1k Dec 27, 2022
1.1k Dec 27, 2022
 230 Nov 22, 2022
230 Nov 22, 2022
 1.2k Dec 21, 2022
1.2k Dec 21, 2022