GLNet for Memory-Efficient Segmentation of Ultra-High Resolution Images

Collaborative Global-Local Networks for Memory-Efficient Segmentation of Ultra-High Resolution Images
Wuyang Chen*, Ziyu Jiang*, Zhangyang Wang, Kexin Cui, and Xiaoning Qian
In CVPR 2019 (Oral). [Youtube]
Overview
Segmentation of ultra-high resolution images is increasingly demanded in a wide range of applications (e.g. urban planning), yet poses significant challenges for algorithm efficiency, in particular considering the (GPU) memory limits.
We propose collaborative Global-Local Networks (GLNet) to effectively preserve both global and local information in a highly memory-efficient manner.
-
Memory-efficient: training w. only one 1080Ti and inference w. less than 2GB GPU memory, for ultra-high resolution images of up to 30M pixels.
-
High-quality: GLNet outperforms existing segmentation models on ultra-high resolution images.
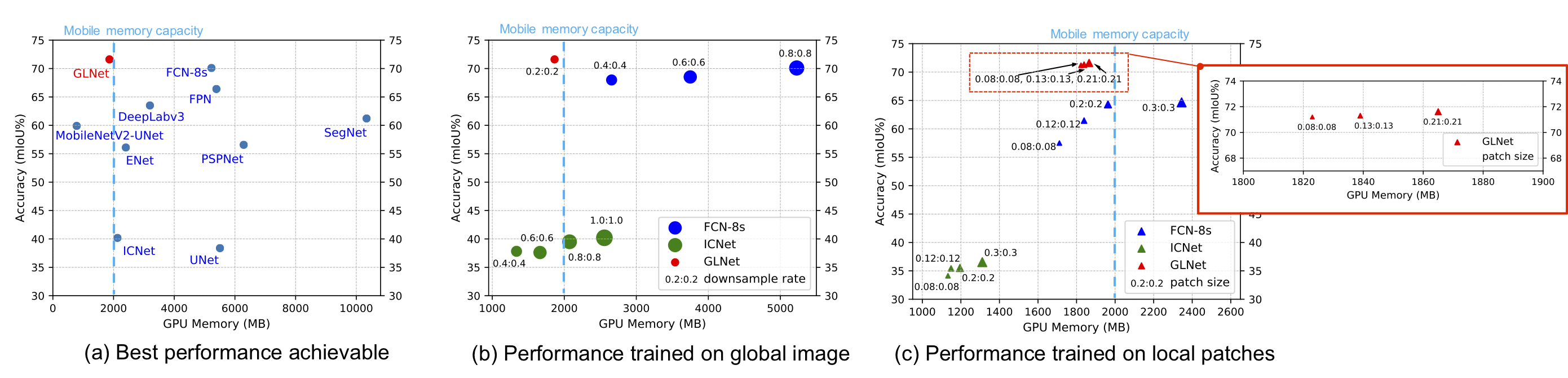
Inference memory v.s. mIoU on the DeepGlobe dataset.
GLNet (red dots) integrates both global and local information in a compact way, contributing to a well-balanced trade-off between accuracy and memory usage.
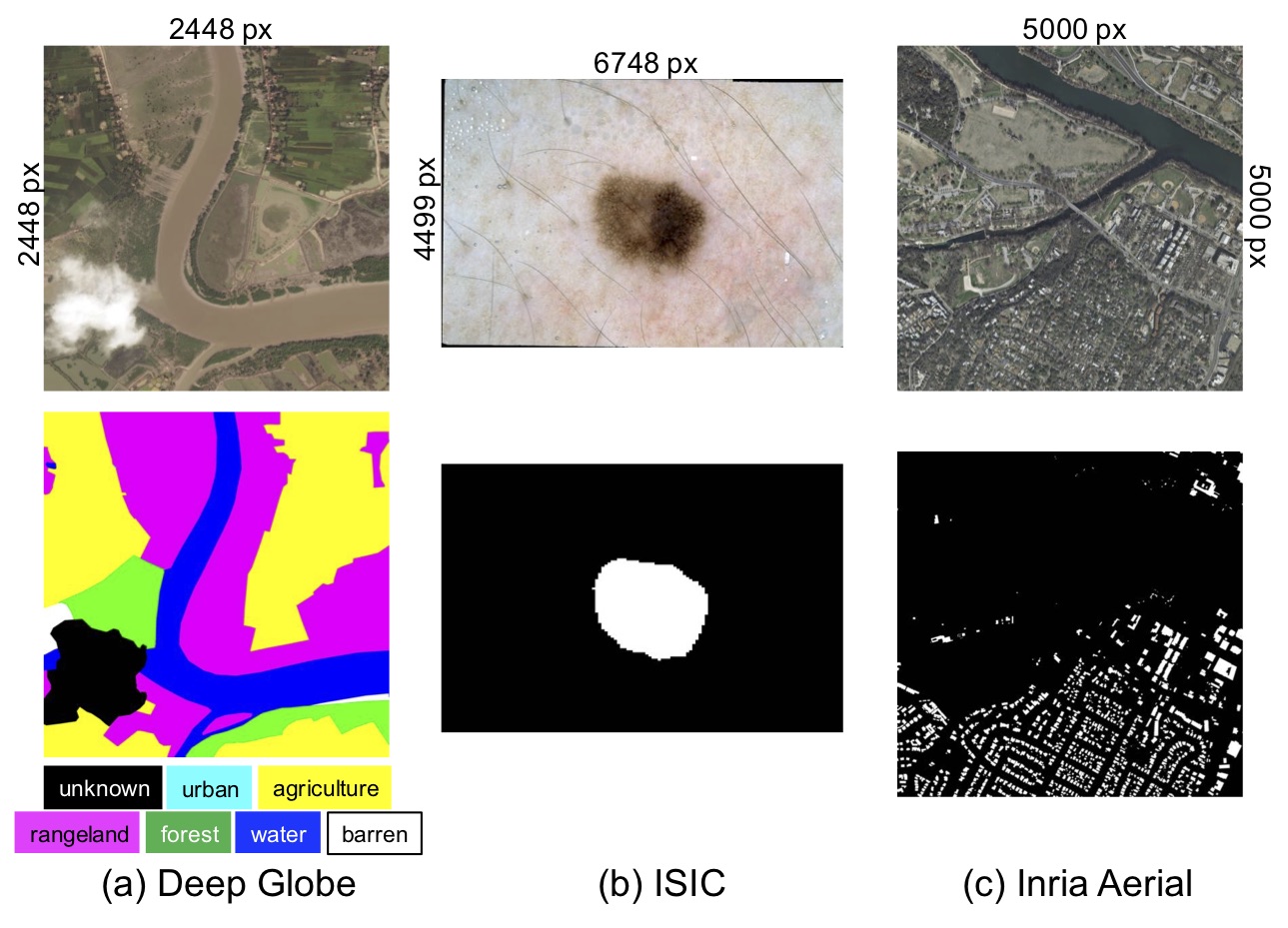
Ultra-high resolution Datasets: DeepGlobe, ISIC, Inria Aerial
Methods
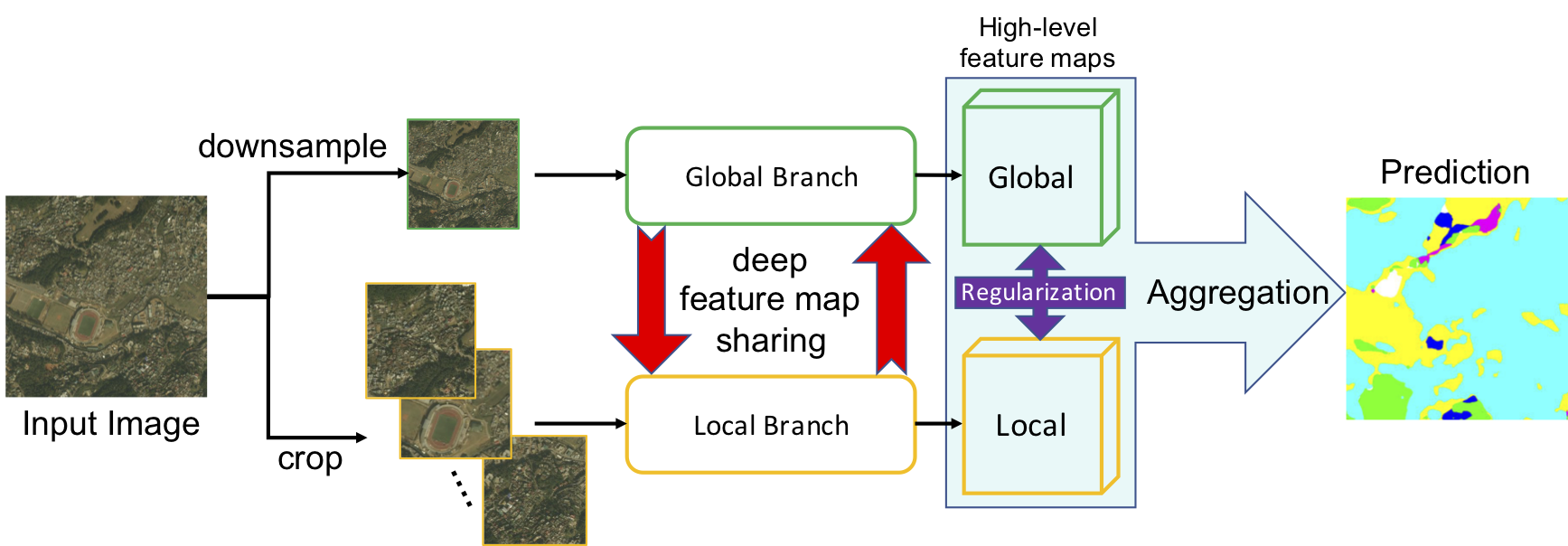
GLNet: the global and local branch takes downsampled and cropped images, respectively. Deep feature map sharing and feature map regularization enforce our global-local collaboration. The final segmentation is generated by aggregating high-level feature maps from two branches.
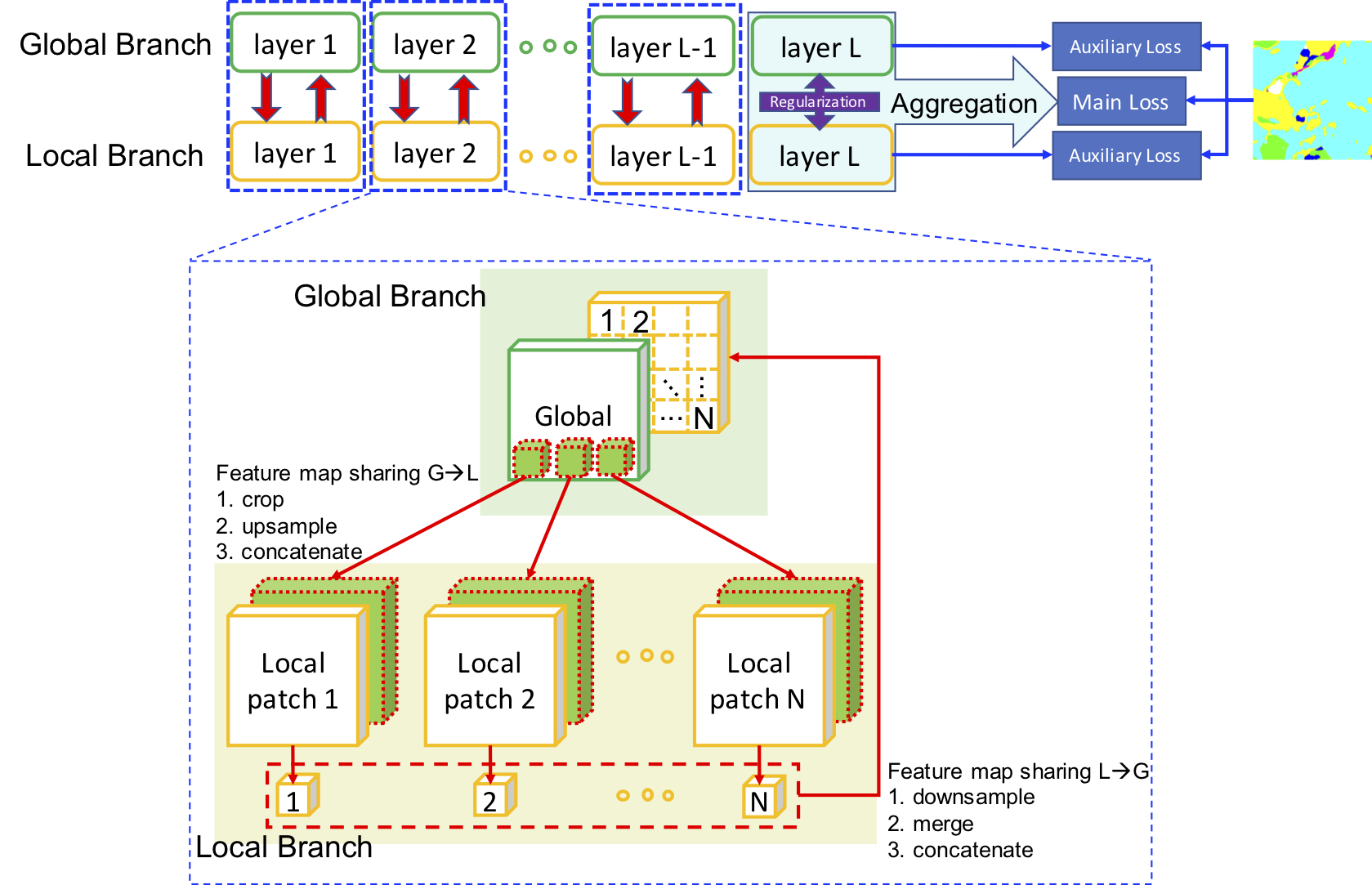
Deep feature map sharing: at each layer, feature maps with global context and ones with local fine structures are bidirectionally brought together, contributing to a complete patch-based deep global-local collaboration.
Training
Current this code base works for Python version >= 3.5.
Please install the dependencies: pip install -r requirements.txt
First, you could register and download the Deep Globe "Land Cover Classification" dataset here: https://competitions.codalab.org/competitions/18468
Then please sequentially finish the following steps:
./train_deep_globe_global.sh./train_deep_globe_global2local.sh./train_deep_globe_local2global.sh
The above jobs complete the following tasks:
- create folder "saved_models" and "runs" to store the model checkpoints and logging files (you could configure the bash scrips to use your own paths).
- step 1 and 2 prepare the trained models for step 2 and 3, respectively. You could use your own names to save the model checkpoints, but this requires to update values of the flag
path_gandpath_g2l.
Evaluation
- Please download the pre-trained models for the Deep Globe dataset and put them into folder "saved_models":
- Download (see above "Training" section) and prepare the Deep Globe dataset according to the train.txt and crossvali.txt: put the image and label files into folder "train" and folder "crossvali"
- Run script
./eval_deep_globe.sh
Citation
If you use this code for your research, please cite our paper.
@inproceedings{chen2019GLNET,
title={Collaborative Global-Local Networks for Memory-Efficient Segmentation of Ultra-High Resolution Images},
author={Chen, Wuyang and Jiang, Ziyu and Wang, Zhangyang and Cui, Kexin and Qian, Xiaoning},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2019}
}
Acknowledgement
We thank Prof. Andrew Jiang and Junru Wu for helping experiments.

 2 Oct 08, 2022
2 Oct 08, 2022
 2 Dec 13, 2021
2 Dec 13, 2021
 11 Dec 10, 2022
11 Dec 10, 2022
 142 Jan 01, 2023
142 Jan 01, 2023
 129 Dec 24, 2022
129 Dec 24, 2022
 81 Dec 14, 2022
81 Dec 14, 2022
 280 Dec 23, 2022
280 Dec 23, 2022
 1.4k Jan 01, 2023
1.4k Jan 01, 2023
 9 Aug 22, 2022
9 Aug 22, 2022
 2.1k Dec 27, 2022
2.1k Dec 27, 2022
 104 Jan 06, 2023
104 Jan 06, 2023
 9 Mar 03, 2022
9 Mar 03, 2022
 121 Jan 01, 2023
121 Jan 01, 2023
 244 Jan 06, 2023
244 Jan 06, 2023
 57 Nov 17, 2022
57 Nov 17, 2022
 561 Jan 08, 2023
561 Jan 08, 2023
 514 Dec 18, 2022
514 Dec 18, 2022
 2.6k Jan 01, 2023
2.6k Jan 01, 2023
 1 Jan 26, 2022
1 Jan 26, 2022
 11 Nov 25, 2022
11 Nov 25, 2022