The project is based on older versions of tesseract and other tools, and is now superseded by another project which allows for more granular control over the text recognition process.
go-ocr
A tool for extracting plain text from scanned documents (pdf or djvu), with user-defined postprocessing.
Motivation
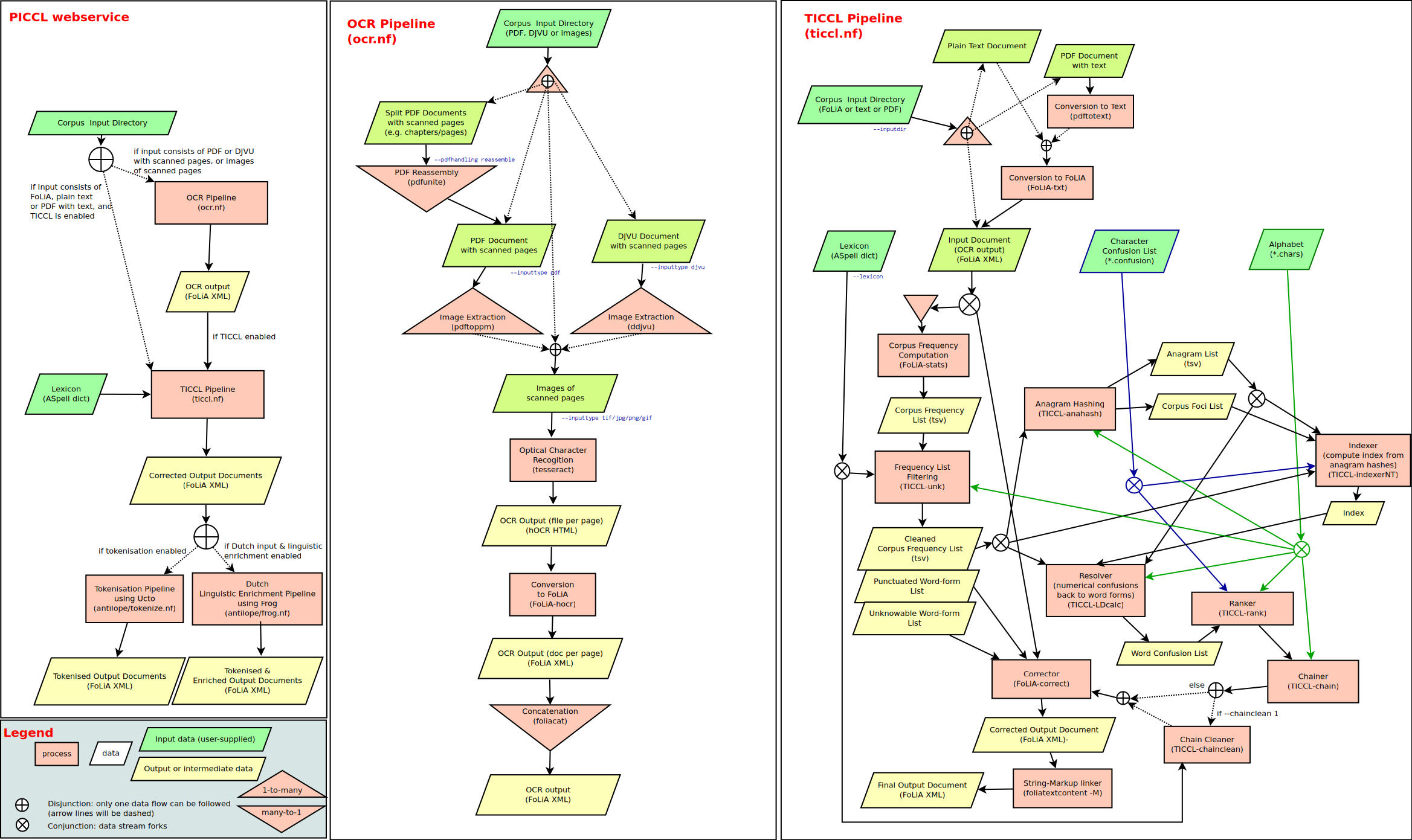
Once I had a task of OCR'ing a number of scanned documents in pdf format. I quickly built a pipeline of the tools to extract images from the input files and to convert them to plain text, but then I realised that modern OCR software is still less than ideal in terms of recognising text, so a good deal of postprocessing was needed in order to remove at least some of those OCR artefacts and irregularities. I ended up with a long pipeline of sed/grep filters which also had to be adjusted per each document and per each document language. What I wanted was a tool that could combine the OCR tools invocation with filters application, also giving an easy way of modifying and combining the filter definitions.
The tool
Given an input file in either pdf or djvu format, the tool performs the following steps:
- Images get extracted from the input file using
pdfimagesorddjvutool; - The extracted images get converted to plain text using
tesseracttool, in parallel; - The specified filters get applied to the text.
Invocation
go-ocr [OPTION]... FILE
Command line options:
-f,--first N first page number (optional, default: 1)
-l,--last N last page number (optional, default: last page of the document)
-F,--filter FILE filter specification file name (optional, may be given multiple times)
-L,--language LANG document language (optional, default: 'eng')
-o,--output FILE output file name (optional, default: stdout)
-h,--help display this help and exit
-v,--version output version information and exit
Example
The following command processes a document some.pdf in Russian, from page 12 to page 26 (inclusive), without any postprocessing, storing the result in the file document.txt:
./go-ocr --first 12 --last 26 --language rus --output document.txt some.pdf
Filter definitions
Filter definition file is a plain text file containing rewriting rules and C-style comments. Each rewriting rule has the following format:
scope type "match" "substitution"
where
scopeis eitherlineortext;typeis eitherwordorregex;matchandsubstitutionare Go strings.
Each rule must be on one line.
Each rule of the scope line is applied to each line of the text. There is no processing done to the line by the tool itself other than trimming the trailing whitespace, which means that a line does not have a trailing newline symbol when the rule is applied. After that all the lines get combined into text with newline symbols inserted between them.
Each rule of the scope text is applied to the whole text after all the line rules. All newline symbols are visible to the rule which allows for combining multiple lines into one.
The reason for having two different scopes for the rules is that applying a rule to a line is computationally cheaper that applying to the whole text. Also, this makes the line regular expressions a bit simpler as, for example, \s regex cannot match a newline.
Rules of type word do a simple substitution replacing any match string with its corresponding substitution string.
Rules of type regex search the input for any match of the match regular expression and replace it with the substitution string. The syntax of the regular expression is that of the Go regexp engine. The substuitution string may contain references to the content of capturing groups from the corresponding match regular expression. From the Go documentation, each reference
is denoted by a substring of the form $name or ${name}, where name is a non-empty sequence of letters, digits, and underscores. A purely numeric name like $1 refers to the submatch with the corresponding index; other names refer to capturing parentheses named with the (?P<name>...) syntax. A reference to an out of range or unmatched index or a name that is not present in the regular expression is replaced with an empty slice.
In the $name form, name is taken to be as long as possible: $1x is equivalent to ${1x}, not ${1}x, and, $10 is equivalent to ${10}, not ${1}0.
To insert a literal $ in the output, use $$ in the template.
All filter definition files are always processed in the order in which they are specified on the command line. Within each file, the rules are grouped by the scope, and applied in the order of specification. This allows for each rule to rely on the outcome of all the rules before it.
Rewriting rules examples
Rule to replace ellipsis with a single utf-8 symbol:
line word "..." "…"
Rule to replace all whitespace sequences with a single space character:
line regex `\s+` " "
Rule to remove all newline characters from the middle of a sentence:
text regex `([a-z\(\),])\n+([a-z\(\)])` "${1} ${2}"
More examples can be found in the files filter-eng and filter-rus.
In practice, it is often useful to maintain one filter definition file with rules to remove common OCR artefacts, and another file with rules specific to a particular document. In general, it is probably impossible to avoid all manual editing altogether by using this tool, but from my experience, a few hours spent on setting up the appropriate filters for a 700 pages document can dramatically reduce the amount of manual work needed afterwards.
Other tools
Internally the program relies on pdfimages and ddjvu tools for extracting images from the input file, and on tesseract program for the actual OCR'ing. The tool pdfimages is usually a part of poppler-utils package, the tool ddjvu comes from djvulibre-bin package, and tesseract is included in tesseract-ocr package. By default, tesseract comes with the English language support only, other languages should be installed separately, for example, run sudo apt install tesseract-ocr-rus to install the Russian language support. To find out what languages are currently installed type tesseract --list-langs.
Compilation
Invoke make (or make debug) from the directory of the project to compile the code with debug information included, or make release to compile without debug symbols. This creates executable file go-ocr.
Technical details
The tool first runs pdfimages or ddjvu program to extract images to a temporary directory, and then invokes tesseract on each image in parallel to produce lines of plain text. Those lines are then passed through the line filters, if any, then assembled into one text string and passed through text filters, if any. regexp filters are implemented using Regexp.ReplaceAll() function, and word filters are invocations of bytes.Replace() function.
Known issues
Older versions of pdfimages tool do not have -tiff option, resulting in an error.
Platform
Linux (tested on Linux Mint 18 64bit, based on Ubuntu 16.04), will probably work on MacOS as well.
Tools:
$ go version
go version go1.6.2 linux/amd64
$ tesseract --version
tesseract 3.04.01
...
$ pdfimages --version
pdfimages version 0.41.0
...
$ ddjvu --help
DDJVU --- DjVuLibre-3.5.27
...
 41 Dec 27, 2022
41 Dec 27, 2022
 117 Nov 10, 2022
117 Nov 10, 2022

 27.5k Jan 8, 2023
27.5k Jan 8, 2023
 5 Dec 6, 2021
5 Dec 6, 2021

 273 Jan 6, 2023
273 Jan 6, 2023

 243 Dec 30, 2022
243 Dec 30, 2022
 209 Dec 6, 2022
209 Dec 6, 2022
 165 Dec 31, 2022
165 Dec 31, 2022
 15 Nov 9, 2022
15 Nov 9, 2022


 4 Jan 24, 2022
4 Jan 24, 2022
 171 Aug 04, 2022
171 Aug 04, 2022
 1.2k Dec 29, 2022
1.2k Dec 29, 2022
 4 Feb 18, 2022
4 Feb 18, 2022
 197 Jan 05, 2023
197 Jan 05, 2023
 41 Jan 03, 2023
41 Jan 03, 2023
 1 Nov 04, 2021
1 Nov 04, 2021
 1 Jan 31, 2022
1 Jan 31, 2022
 2 Jan 19, 2022
2 Jan 19, 2022
 496 Jan 05, 2023
496 Jan 05, 2023
 2 Nov 11, 2021
2 Nov 11, 2021
 147 Dec 04, 2022
147 Dec 04, 2022
 34 Nov 17, 2022
34 Nov 17, 2022
 21 Mar 11, 2022
21 Mar 11, 2022
 4 May 29, 2022
4 May 29, 2022
 46 Nov 14, 2022
46 Nov 14, 2022
 2 Nov 16, 2021
2 Nov 16, 2021
 1 Jan 01, 2022
1 Jan 01, 2022
 33 May 24, 2022
33 May 24, 2022
 19 Aug 17, 2022
19 Aug 17, 2022