News
05/17/2021To make the comparison on ZJU-MoCap easier, we save quantitative and qualitative results of other methods at here, including Neural Volumes, Multi-view Neural Human Rendering, and Deferred Neural Human Rendering.05/13/2021To make the following works easier compare with our model, we save our rendering results of ZJU-MoCap at here and write a document that describes the training and test protocols.05/12/2021The code supports the test and visualization on unseen human poses.05/12/2021We update the ZJU-MoCap dataset with better fitted SMPL using EasyMocap. We also release a website for visualization. Please see here for the usage of provided smpl parameters.
Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans
Project Page | Video | Paper | Data
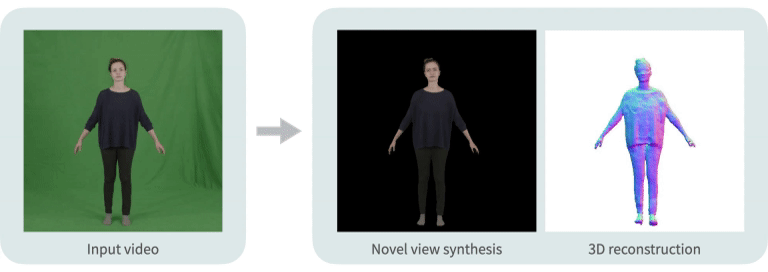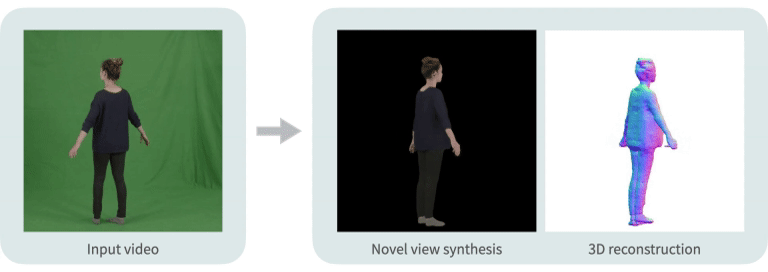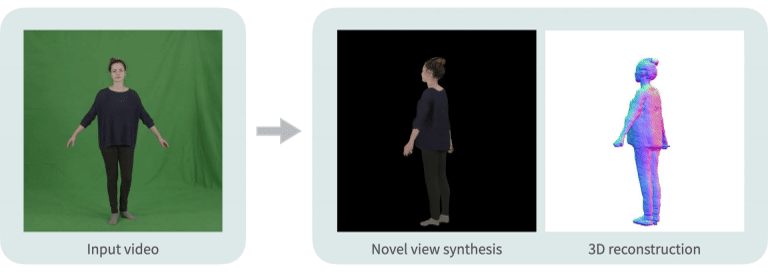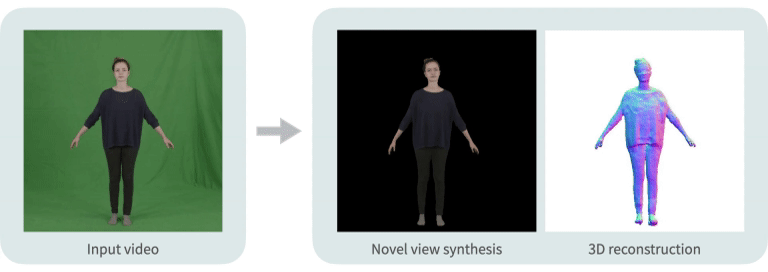
Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans
Sida Peng, Yuanqing Zhang, Yinghao Xu, Qianqian Wang, Qing Shuai, Hujun Bao, Xiaowei Zhou
CVPR 2021
Any questions or discussions are welcomed!
Installation
Please see INSTALL.md for manual installation.
Installation using docker
Please see docker/README.md.
Thanks to Zhaoyi Wan for providing the docker implementation.
Run the code on the custom dataset
Please see CUSTOM.
Run the code on People-Snapshot
Please see INSTALL.md to download the dataset.
We provide the pretrained models at here.
Process People-Snapshot
We already provide some processed data. If you want to process more videos of People-Snapshot, you could use tools/process_snapshot.py.
You can also visualize smpl parameters of People-Snapshot with tools/vis_snapshot.py.
Visualization on People-Snapshot
Take the visualization on female-3-casual as an example. The command lines for visualization are recorded in visualize.sh.
-
Download the corresponding pretrained model and put it to
$ROOT/data/trained_model/if_nerf/female3c/latest.pth. -
Visualization:
- Visualize novel views of single frame
python run.py --type visualize --cfg_file configs/snapshot_exp/snapshot_f3c.yaml exp_name female3c vis_novel_view True num_render_views 144- Visualize views of dynamic humans with fixed camera
python run.py --type visualize --cfg_file configs/snapshot_exp/snapshot_f3c.yaml exp_name female3c vis_novel_pose True- Visualize mesh
# generate meshes python run.py --type visualize --cfg_file configs/snapshot_exp/snapshot_f3c.yaml exp_name female3c vis_mesh True train.num_workers 0 # visualize a specific mesh python tools/render_mesh.py --exp_name female3c --dataset people_snapshot --mesh_ind 226 -
The results of visualization are located at
$ROOT/data/render/female3cand$ROOT/data/perform/female3c.


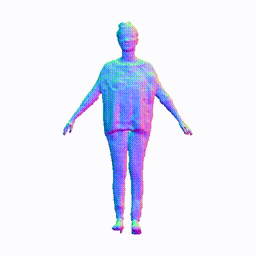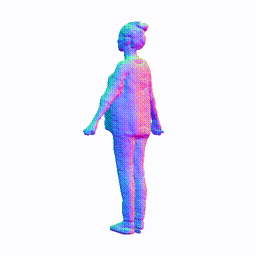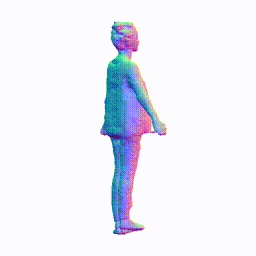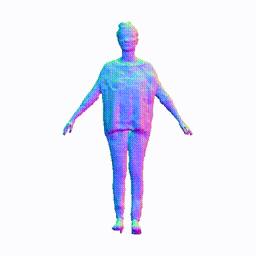
Training on People-Snapshot
Take the training on female-3-casual as an example. The command lines for training are recorded in train.sh.
- Train:
# training python train_net.py --cfg_file configs/snapshot_exp/snapshot_f3c.yaml exp_name female3c resume False # distributed training python -m torch.distributed.launch --nproc_per_node=4 train_net.py --cfg_file configs/snapshot_exp/snapshot_f3c.yaml exp_name female3c resume False gpus "0, 1, 2, 3" distributed True - Train with white background:
# training python train_net.py --cfg_file configs/snapshot_exp/snapshot_f3c.yaml exp_name female3c resume False white_bkgd True - Tensorboard:
tensorboard --logdir data/record/if_nerf
Run the code on ZJU-MoCap
Please see INSTALL.md to download the dataset.
We provide the pretrained models at here.
Potential problems of provided smpl parameters
- The newly fitted parameters locate in
new_params. Currently, the released pretrained models are trained on previously fitted parameters, which locate inparams. - The smpl parameters of ZJU-MoCap have different definition from the one of MPI's smplx.
- If you want to extract vertices from the provided smpl parameters, please use
zju_smpl/extract_vertices.py. - The reason that we use the current definition is described at here.
- If you want to extract vertices from the provided smpl parameters, please use
It is okay to train Neural Body with smpl parameters fitted by smplx.
Test on ZJU-MoCap
The command lines for test are recorded in test.sh.
Take the test on sequence 313 as an example.
- Download the corresponding pretrained model and put it to
$ROOT/data/trained_model/if_nerf/xyzc_313/latest.pth. - Test on training human poses:
python run.py --type evaluate --cfg_file configs/zju_mocap_exp/latent_xyzc_313.yaml exp_name xyzc_313 - Test on unseen human poses:
python run.py --type evaluate --cfg_file configs/zju_mocap_exp/latent_xyzc_313.yaml exp_name xyzc_313 test_novel_pose True
Visualization on ZJU-MoCap
Take the visualization on sequence 313 as an example. The command lines for visualization are recorded in visualize.sh.
-
Download the corresponding pretrained model and put it to
$ROOT/data/trained_model/if_nerf/xyzc_313/latest.pth. -
Visualization:
- Visualize novel views of single frame
python run.py --type visualize --cfg_file configs/zju_mocap_exp/latent_xyzc_313.yaml exp_name xyzc_313 vis_novel_view True- Visualize novel views of single frame by rotating the SMPL model
python run.py --type visualize --cfg_file configs/zju_mocap_exp/latent_xyzc_313.yaml exp_name xyzc_313 vis_novel_view True num_render_views 100- Visualize views of dynamic humans with fixed camera
python run.py --type visualize --cfg_file configs/zju_mocap_exp/latent_xyzc_313.yaml exp_name xyzc_313 vis_novel_pose True num_render_frame 1000 num_render_views 1- Visualize views of dynamic humans with rotated camera
python run.py --type visualize --cfg_file configs/zju_mocap_exp/latent_xyzc_313.yaml exp_name xyzc_313 vis_novel_pose True num_render_frame 1000- Visualize mesh
# generate meshes python run.py --type visualize --cfg_file configs/zju_mocap_exp/latent_xyzc_313.yaml exp_name xyzc_313 vis_mesh True train.num_workers 0 # visualize a specific mesh python tools/render_mesh.py --exp_name xyzc_313 --dataset zju_mocap --mesh_ind 0 -
The results of visualization are located at
$ROOT/data/render/xyzc_313and$ROOT/data/perform/xyzc_313.
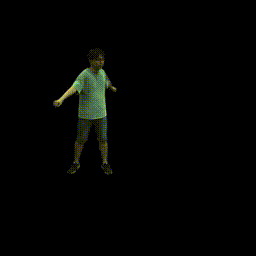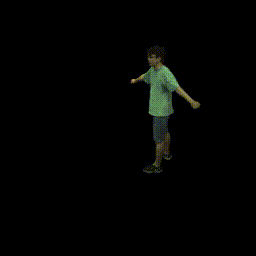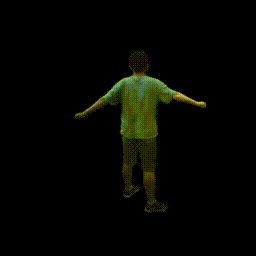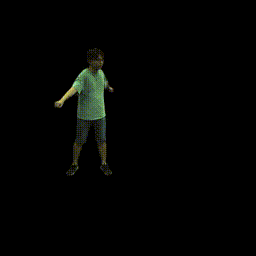
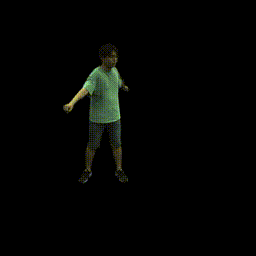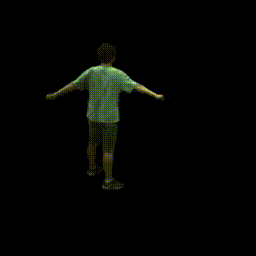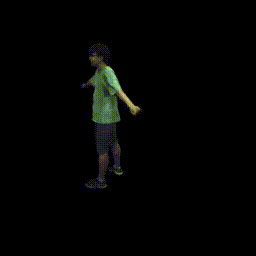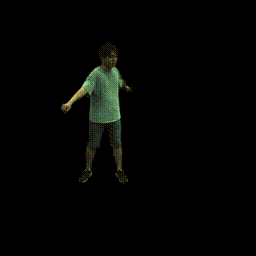
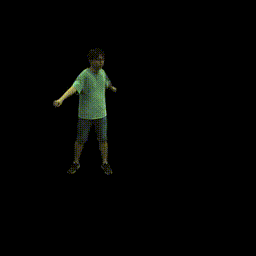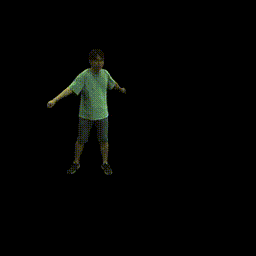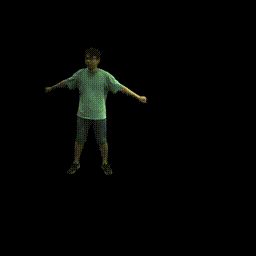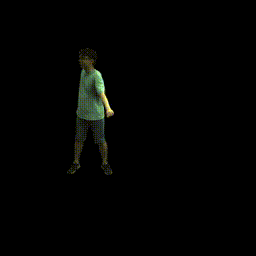
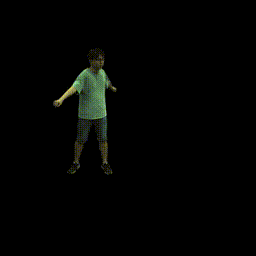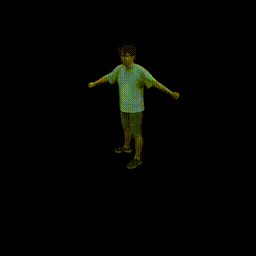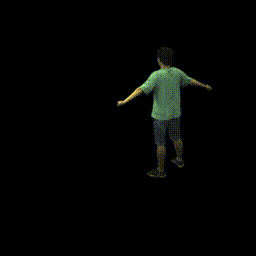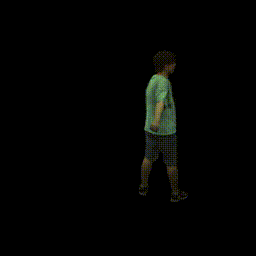

Training on ZJU-MoCap
Take the training on sequence 313 as an example. The command lines for training are recorded in train.sh.
- Train:
# training python train_net.py --cfg_file configs/zju_mocap_exp/latent_xyzc_313.yaml exp_name xyzc_313 resume False # distributed training python -m torch.distributed.launch --nproc_per_node=4 train_net.py --cfg_file configs/zju_mocap_exp/latent_xyzc_313.yaml exp_name xyzc_313 resume False gpus "0, 1, 2, 3" distributed True - Train with white background:
# training python train_net.py --cfg_file configs/zju_mocap_exp/latent_xyzc_313.yaml exp_name xyzc_313 resume False white_bkgd True - Tensorboard:
tensorboard --logdir data/record/if_nerf
Citation
If you find this code useful for your research, please use the following BibTeX entry.
@inproceedings{peng2021neural,
title={Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans},
author={Peng, Sida and Zhang, Yuanqing and Xu, Yinghao and Wang, Qianqian and Shuai, Qing and Bao, Hujun and Zhou, Xiaowei},
booktitle={CVPR},
year={2021}
}

 18 Aug 25, 2022
18 Aug 25, 2022
 2.1k Jan 04, 2023
2.1k Jan 04, 2023
 44 Dec 20, 2022
44 Dec 20, 2022
 19 Oct 11, 2022
19 Oct 11, 2022
 34 Nov 21, 2022
34 Nov 21, 2022
 1 Nov 16, 2021
1 Nov 16, 2021
 2 Dec 29, 2021
2 Dec 29, 2021
 90 Sep 10, 2021
90 Sep 10, 2021
 18 Nov 01, 2022
18 Nov 01, 2022
 37 Oct 23, 2022
37 Oct 23, 2022
 456 Nov 07, 2022
456 Nov 07, 2022
 172 Dec 29, 2022
172 Dec 29, 2022
 40 Oct 11, 2022
40 Oct 11, 2022
 18 Nov 18, 2022
18 Nov 18, 2022
 142 Dec 24, 2022
142 Dec 24, 2022
 9 Nov 24, 2022
9 Nov 24, 2022
 85 Oct 13, 2022
85 Oct 13, 2022
 93 Dec 28, 2022
93 Dec 28, 2022
 210 Dec 18, 2022
210 Dec 18, 2022
 8 Jun 07, 2022
8 Jun 07, 2022