当前位置:网站首页>[high quality original] share some unknown and super easy-to-use API functions in sklearn module
[high quality original] share some unknown and super easy-to-use API functions in sklearn module
2022-04-21 11:18:00 【Xia Junxin】
I believe that for many machine learning enthusiasts , Training models 、 Verify the performance of the model, etc. generally sklearn Some functions and methods in the module , Today, Xiaobian will talk to you about the less well-known in this module API, Not many people may know , But it's very easy to use .
Extreme value detection
There are extreme values in the data set , This is a very normal phenomenon , There are also many extreme value detection algorithms on the market , and sklearn Medium EllipticalEnvelope The algorithm is worth trying , It is especially good at detecting extreme values in data sets satisfying normal distribution , The code is as follows
import numpy as np
from sklearn.covariance import EllipticEnvelope
# Randomly generate some false data
X = np.random.normal(loc=5, scale=2, size=100).reshape(-1, 1)
# Fitting data
ee = EllipticEnvelope(random_state=0)
_ = ee.fit(X)
# New test set
test = np.array([6, 8, 30, 4, 5, 6, 10, 15, 30, 3]).reshape(-1, 1)
# Predict which extreme values are
ee.predict(test)output
array([ 1, 1, -1, 1, 1, 1, -1, -1, -1, 1])In predicting which data are extreme results , In the end “-1” Corresponding to the extreme value , That is to say 30、10、15、30 These results
Feature screening (RFE)
In modeling , We screened out important features , about Reduce the risk of over fitting as well as Reduce the complexity of the model Are of great help .Sklearn Recursive feature elimination algorithm in module (RFE) It can achieve the above purpose very effectively , Its main idea is to return through the learner coef_ Property or feature_importance_ Attribute to get the importance of each feature . Then remove the least important feature from the current feature set . In the rest of the feature set Keep repeating this step of recursion , Until the required number of features is reached .
Let's take a look at the following sample code
from sklearn.datasets import make_regression
from sklearn.feature_selection import RFECV
from sklearn.linear_model import Ridge
# Randomly generate some false data
X, y = make_regression(n_samples=10000, n_features=20, n_informative=10)
# New learner
rfecv = RFECV(estimator=Ridge(), cv=5)
_ = rfecv.fit(X, y)
rfecv.transform(X).shapeoutput
(10000, 10) We use Ridge() The regression algorithm is a learner , By means of cross validation, the 10 A redundant feature , Retain other important features .
Drawing of decision tree
I believe that for many machine learning enthusiasts , The decision tree algorithm is familiar , If we can chart it at the same time , You can more intuitively understand its principle and context , Let's take a look at the following example code
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
%matplotlib inline
# New dataset , The decision tree algorithm is used for fitting training
df = load_iris()
X, y = iris.data, iris.target
clf = DecisionTreeClassifier()
clf = clf.fit(X, y)
# Charting
plt.figure(figsize=(12, 8), dpi=200)
plot_tree(clf, feature_names=df.feature_names,
class_names=df.target_names);output

HuberRegressor Return to
If there are extreme values in the data set, the performance of the finally trained model will be greatly reduced , In most cases , We can find these extreme values through some algorithms and remove them , Of course, there is also an introduction here HuberRegressor Regression algorithm provides us with another idea , Its treatment of extreme values is to give these extreme values when training and fitting Less weight , In the middle of epsilon The parameter to control should be the number of extreme values , The more obvious the value, the stronger the robustness to extreme values . Please see the following picture for details
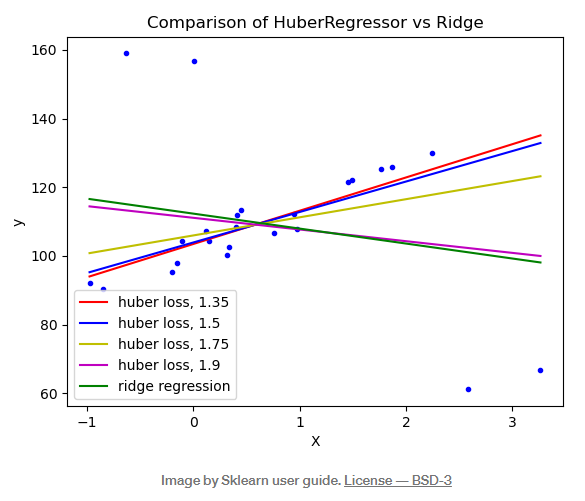
When epsilon The value is equal to the 1.35、1.5 as well as 1.75 When , The interference from extreme values is relatively small . The specific use method and parameter description of the algorithm can refer to its official document .
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.HuberRegressor.html
Feature screening SelectFromModel
Another feature filtering algorithm is SelectFromModel, Different from the recursive feature elimination method mentioned above to screen features , It is used more in the case of large amount of data, because it has Lower computing costs , As long as the model has feature_importance_ Property or coef_ Properties can be similar to SelectFromModel Algorithm compatible , The sample code is as follows
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import ExtraTreesRegressor
# Randomly generate some false data
X, y = make_regression(n_samples=int(1e4), n_features=50, n_informative=15)
# Initialize model
selector = SelectFromModel(estimator=ExtraTreesRegressor()).fit(X, y)
# Screen out important models
selector.transform(X).shapeoutput
(10000, 9)NO.1
Previous recommendation
Historical articles
【 Original content 】 Introduce an advanced version of Pandas Data analysis artifact :Polars
【 Classic original 】 Share some good ones Python Built-in module
Share 、 Collection 、 give the thumbs-up 、 I'm looking at the arrangement ?




版权声明
本文为[Xia Junxin]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204211114040927.html
边栏推荐
- Suffix array special training
- Nocalhost for dapr remote debugging
- New features of ES6 (7): proxy proxy / model module / import / export
- P4 Tutorials---- source routing
- Unix哲学与高并发
- 粉笔科技推行OMO一体化模式 双核驱动营收快速增长
- Matlab GUI --- animation demonstration of singleselectionlistbox
- Tgpimage in GDI + loads images from streams
- Matlab --- making analog clock with coordinate axis and its sub objects (animation demonstration)
- From station B and little red book, how to do a good job of community products?
猜你喜欢


![[二叉数]对称二叉树](/img/15/a1285ae7f31dd2e9f7b00350b1fdc6.png)





随机推荐
Suffix Array
How does IOT platform realize business configuration center
JS implementation top input text box
Rhino software plug-in rhino plug-in visual studio create your first plug-in
注册新西兰公司流程和需要的资料
Topological sorting & Critical Path & Digital DP
Matlab --- select provinces and cities for application
Matlab --- multi picture display of coordinate axis
MySQL修改最大连接数限制
AC自动机
Arrow function / class class of ES6 new feature (6)
RMQ&线段树复习
make the inifile support unicode in delphi
阿里超大规模 Flink 集群运维体系介绍
Development of digital collection platform and construction of digital collection app
Brutally crack the latest JVM interview questions of meituan
【leetcode】647. Palindrome substring
AC automata
pgpool-II 4.3 中文手册 - 入门教程
左程云 - 大厂刷题班 - 一种字符在左,另一种字符在右的最少交换次数