当前位置:网站首页>spark面试常问问题
spark面试常问问题
2022-08-10 15:20:00 【默主归沙】
Spark如何解决数据倾斜问题?
分为简单倾斜和复杂倾斜
简单是数据资源分布不均衡,或者执行入filter操作导致的partition之间数据大小不一致 使用coalesce重分区就可以(spark3。X版本引入AQE功能,自适应查询执行,会自动对小分区数据进行合并)
复杂数据倾斜一般是根据业务字段进行聚合运算时进行shuffle之后导致partition之间数据严重不均衡。比如针对全国信息表,以城市作为key,其他信息作为value,通过reduceByKey,你会发现]只有四个城市的数据非常大。
解决方案:
1)提高数据处理频率,同事降低单次数据处理量,这样可以导致每个partition之中的数据量减少
2)减少spark任务的并行度,把并行度降低到4 对象4个数据倾斜严重的分区(--num-executors 4 --executor-memory 5G)同时加大每个executor的内存和CPU核数 添加硬件资源同时不至于让硬件资源过于浪费。
3)尽量精简(单个)value的大小 只取聚合计算时value中需要的字段,不参加的字段全部抛弃 让value大小有效减少
4)对于严重的key进行加盐,把分区数增加,先进行聚合操作,然后再把key进行减盐操作,恢复到原本的kye,再次聚合得到最终结果
jar冲突(主要是版本要一致)
为什么会jar冲突?就是涉及到不同的依赖下面的子依赖有冲突
加载到不该加载的jar包
idea解决:(非社区版)
右击 Maven-> Show Dependencies
Driver和Executor
driver负责创建 SparkContext rdd SparkSession df或者ds
driver 负责关联广播变量(就是把一个变量加载到所有的executor端,提供计算需要)和累加器(收集executor端数据的累计行为)
executor 对rdd或者df或者ds数据模型进行计算
对计算好的数据进行持久化存储
为什么spark要比mapreduce快?
1)mapreduce的计算框架只有简单粗暴的map和reduce,map阶段的数据都会写入到磁盘中,而且这些数据会进行sort和combine操作,才会进入reduce阶段,IO效率很低
spark无论哪个阶段都最大化使用内存
2)多阶段方面:
mr会启动多个应用
spark可以利用独有的DAG依赖关系,只需要启动一个应用就可以完成所有计算,避免重复启动应用带来的性能损耗
3)编程模型角度:
spark提供了更多灵活便捷的算子,让编程变得更加优雅和高效
分区数和并行度 的区别
分区数是固定的概念
并行度是计算引擎决定的
spark中的reduceByKey和groupByKey的区别?
reduceByKey : reduceByKey会在结果发送至reducer之前会对每个mapper在本地进行merge,类似于MapReduce中的combiner。这样做的好处在于,在map端进行一次reduce之后,数据量会大幅度减小,从而减小传输,保证reduce端能够更快的进行结果计算。
groupByKey : groupByKey会对每一个RDD中的value值进行聚合形成一个序列(Iterator),此操作发生在reduce端,所以势必会将所有的数据通过网络进行传输,造成不必要的浪费。同时如果数据量十分大,可能还会造成OutOfMemoryError。
完整问题
RDD做如下转换流程:RDD A——>RDD B——>RDD C-—>RDD D
如果RDD D中的分区数据丢失,是只需要在RDD C的分区上重算?还是需要从 RDDA开始从头重新计算?
如果RDD D中的分区数据丢失,在B或C都没有做cache的情况下会从头开始计算,也就是从A开始计算。如果C做了cache,那么就会从C开始计算。
RDD不做cache的话可以这么理解:变换前后的新旧RDD的分区,在物理上可能是同一块内存存储,所以后面的RDD会覆盖前面RDD的内存,所以RDD是个瞬时状态,生成新的RDD后它自己就会消失,所以必要的时候可以对RDD做cache持久化。
Spark RDD有哪些特性?
2.Spark RDD有哪些特性?·A list of partitions
RDD是一个由多个partition组成的的List。. A function for computing each split
RDD的每个partition上面都会有function,也就是函数应用,其作用是实现RDD之间partition的转换。
.A list of dependencies on other RDDs
RDD会记录它的依赖,为了容错,也就是说在内存中的RDD操作时出错或丢失会进行重算。
.Optionally,a Partitioner for Key-value RDDS
可选项,如果RDD里面存的数据是key-value形式,则可以传递一个自定义的Partitioner进行重新分区。
Optionally, a list of preferred locations to compute each split on最优的位置去计算,也就是保持数据的本地性。
概述一下Spark中的常用算子区别?
map:用于遍历RDD,将函数应用于每一个元素,返回新的RDD(transformation算子)
foreach :用于遍历RDD,将函数应用于每一个元素,无返回值( action算子)
mapPatitions :用于遍历操作RDD中的每一个分区,返回生成一个新的RDD ( transformation算子)
foreachPatition :用于遍历操作RDD中的每一个分区,无返回值( action算子)
总结:一般使用mapPatitions和foreachPatition算子比map和foreach更加高效,推荐使用。
Transformation与Action算子区别
· Transformation变换/转换算子
Transformation操作是延迟计算的,也就是说从一个RDD 转换生成另一个 RDD的转换操作不是马上执行,需要等到有Action 操作的时候才会真正触发运算。比如map, filter等算子。
. Action行动算子
Action算子会触发Spark提交作业( Job)。比如print , count ,saveAsText等算子。
哪些Spark算子会有shuffle过程?
·去重:distinct
·排序:groupByKey , reduceByKey等·重分区:repartition
·集合或者表连接操作:join
Spark中cache与persist的区别与联系?
联系:cache和persist都是用于将一个RDD进行缓存的,这样在之后使用的过程中就不需要重新计算了,可以大大节省程序运行时间
区别:cache调用了persist方法,cache只有一个默认的缓存级别MEMORY_ONLY ,而persist可以根据情况设置多种缓存级别。
RDD的“弹性”体现在哪?有哪些缺点?
·RDD弹性
√RDD自动进行内存和磁盘切换RDD基于lineage的高效容错
√如果子RDD计算失败或者丢失,会根据父RDD重新计算,而且只会计算失败或者丢失的分区
√数据调度弹性:DAG Task和资源管理无关
√数据分片的高度弹性:repartition
·RDD缺陷
√中间数据默认不会保存,每次行动操作都会对数据重复计算,某些计算量比较大的操作可能会影响到系统的运算效率。
Spark RDD持久化方式?
·持久化操作
可以将RDD持久化到不同层次的存储介质,以便后续操作重复使用.·持久化方式
cache:RDD[T](调用了persist方法) persist:RDD[T]
persist(level:StorageLevel):RDD[T]
首次使用RDD,我们可以选择对RDD进行持久化,当再次使用RDD时就可以直接从之前的缓存中获取,而无需再次进行计算。对于需要反复使用的RDD会带来很大的性能改善。
Spark为什么要对数据进行序列化,有什么优缺点?
·优点:序列化可以减少数据的体积,减少存储空间,高效存储和传输数据。
·缺点:使用的时候要反序列化,非常消耗CPU。
Spark为什么要持久化,一般什么场景下要进行persist操作?
·RDD持久化原因
√Spark RDD中间不产生临时数据,但分布式系统风险很高,所以容易出错。
rdd出错之后可以根据血统重算出来,如果没有对父rdd进行persis1或者cache的持久化,就需要重头计算。
Spark为什么要持久化,一般什么场景下要进行persist操作?
·RDD持久化应用场景
√某个步骤计算非常耗时,需要进行persist持久化。
√计算链条非常长,重新恢复要算很多步骤,最好使用persist. checkpoint所在的rdd要持久化persist。
shuffle之后要persist,因为shuffle要进性网络传输,风险很大,数据丢失重来,恢复代价很大。
shuffle之前进行persist,框架默认将数据持久化到磁盘,这个是框架自动做的。
Spark的rdd有几种操作类型?
·Spark的rdd包含以下操作类型
√transformation转换操作 action行动操作
√控制操作,如cache、persist,对性能和效率的有很好的支持。
边栏推荐
- 嵌入式开发:嵌入式基础——使用指针数组映射外设
- Chapter one module of the re module,
- 持续集成实战 —— Jenkins自动化测试环境搭建
- 【教程】HuggingFace的Optimum组件已支持加速Graphcore和英特尔Habana芯片
- fastposter v2.9.1 程序员必备海报生成器
- 华为云DevCloud获信通院首批云原生技术架构成熟度评估的最高级认证
- Methodology of multi-living in different places
- QOS功能介绍
- SWIG tutorial "four" - package of go language
- 2025年推出 奥迪透露将推出大型SUV产品
猜你喜欢
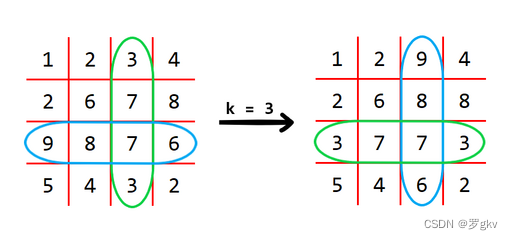
E. Cross Swapping (and check out deformation/good questions)
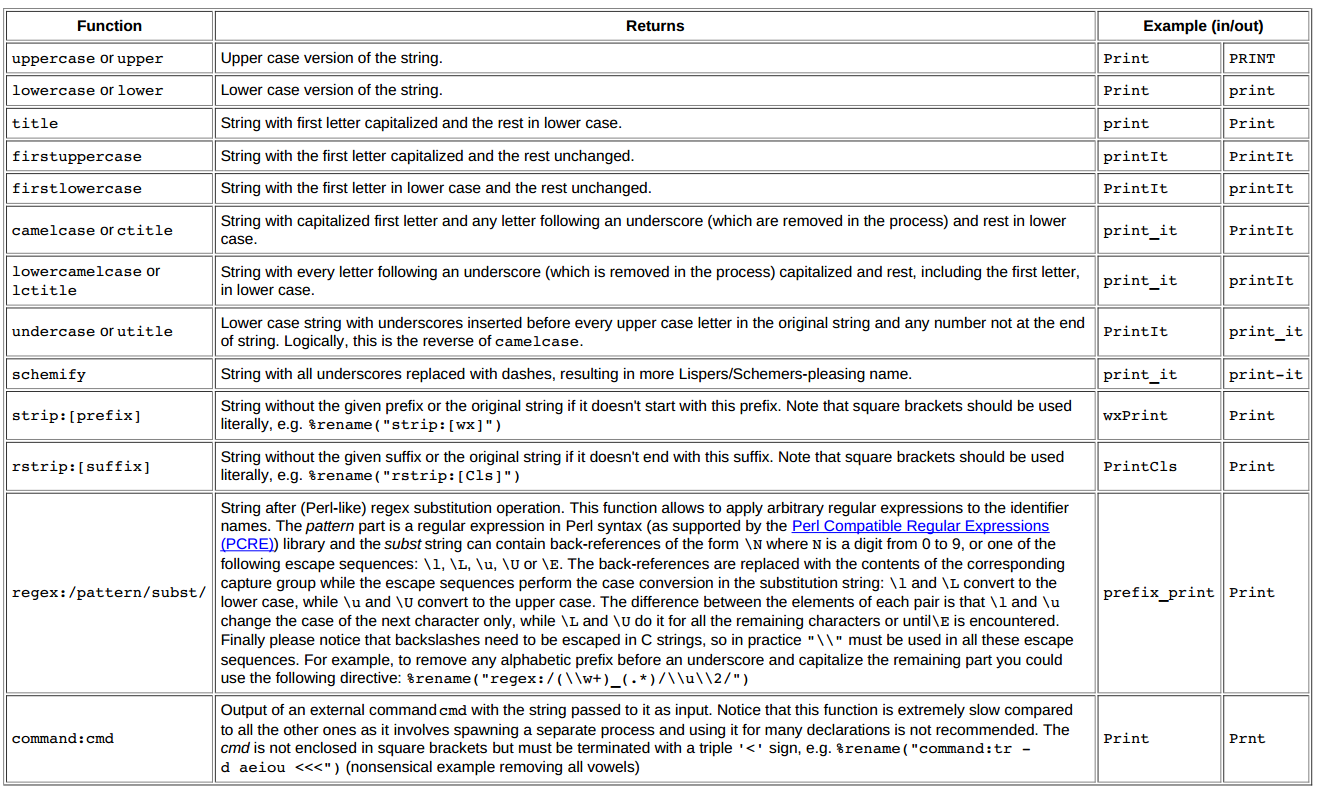
SWIG tutorial "two"
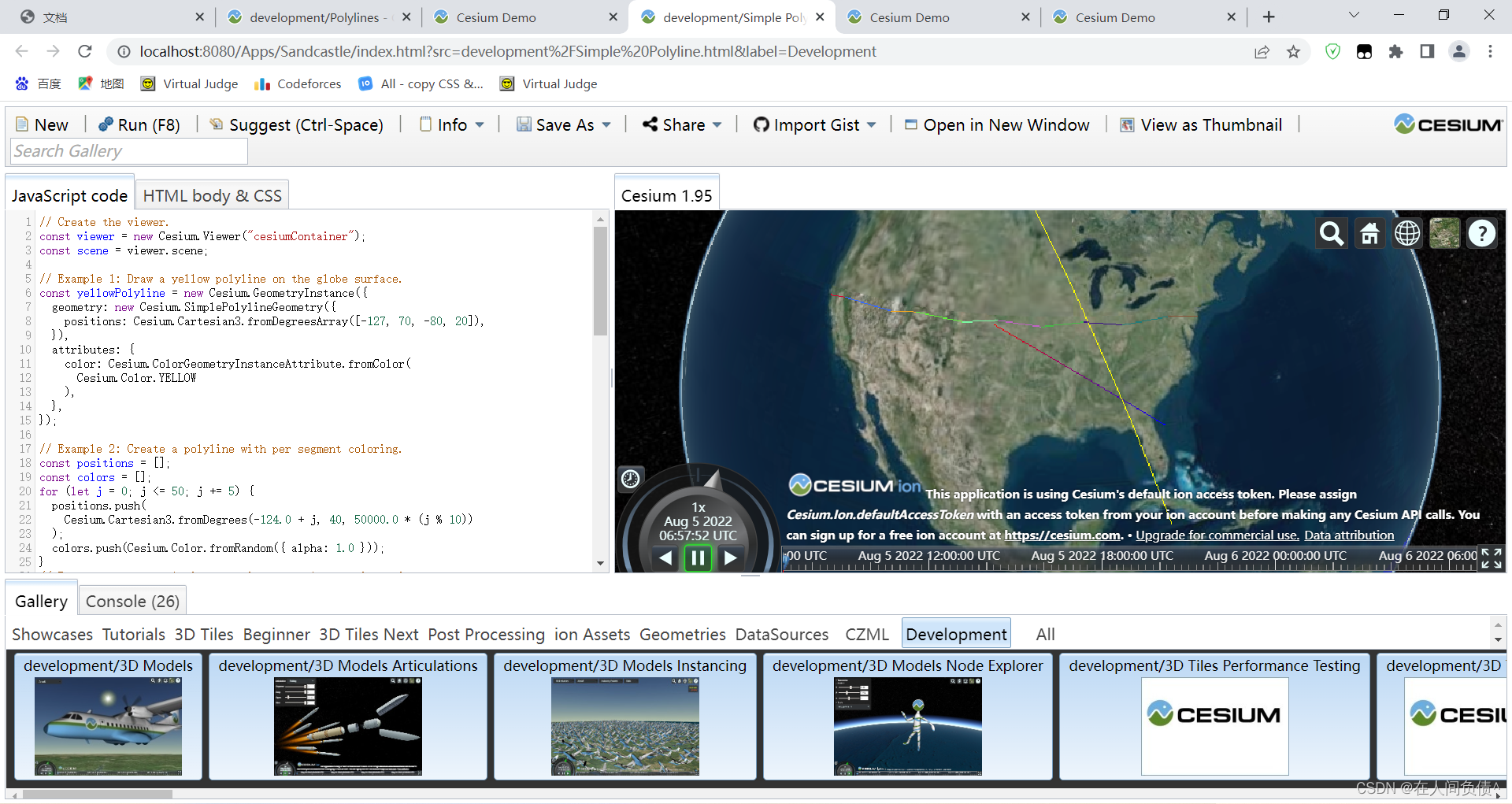
Cesium Quick Start 4-Polylines primitive usage explanation
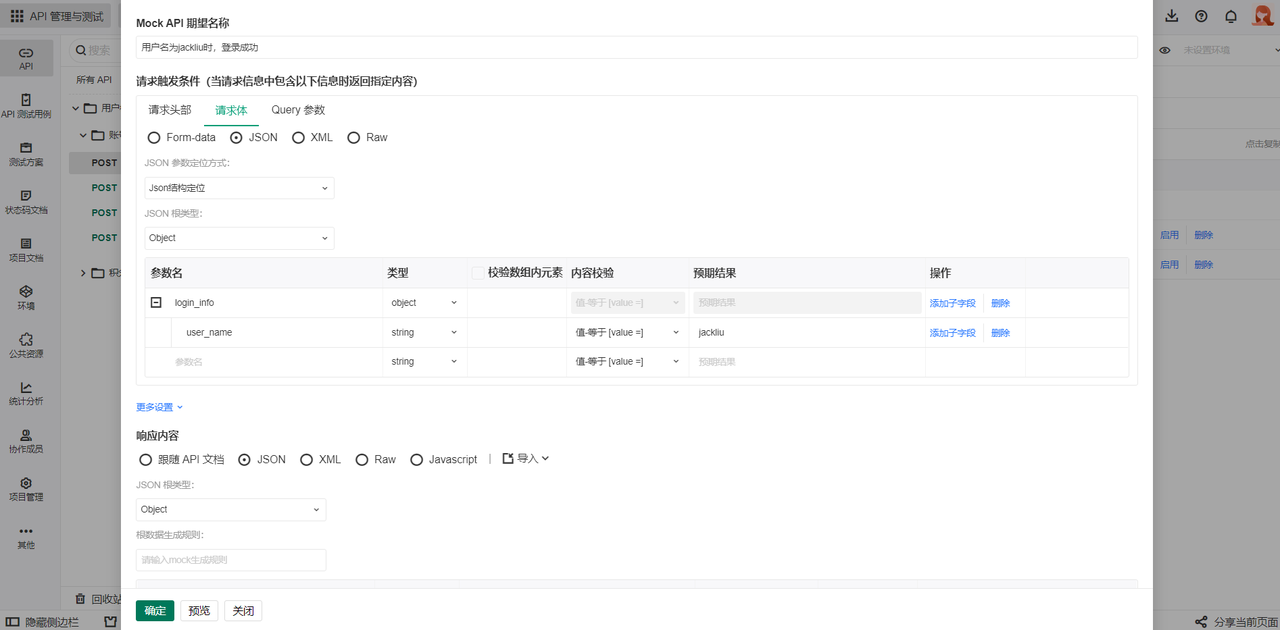
简述 Mock 接口测试

Parse the value of uuid using ABAP regular expressions

Oracle database backup DMP file is too big, what method can be split into multiple DMP when backup?
metaForce佛萨奇2.0系统开发功能逻辑介绍

Problem solving-->Online OJ (19)
秒杀项目收获

消息称原美图高管加盟蔚来手机 顶配产品或超7000元
随机推荐
Basic use of Go Context
全部内置函数详细认识(中篇)
易基因|深度综述:m6A RNA甲基化在大脑发育和疾病中的表观转录调控作用
Problem solving-->Online OJ (19)
Understanding_Data_Types_in_Go
2025年推出 奥迪透露将推出大型SUV产品
【教程】HuggingFace的Optimum组件已支持加速Graphcore和英特尔Habana芯片
scala 基础篇
社区动态——恭喜海豚调度中国区用户组新晋 9 枚“社群管理员”
Zijin Example
程序员=加班??——掌握时间才能掌握人生
小程序-语音播报功能
FFmpeg 交叉编译
Mobileye joins hands with Krypton to open a new chapter in advanced driver assistance through OTA upgrade
基于 Azuki 系列:NFT估值分析框架“DRIC”
Zhaoqi Technology Innovation High-level Talent Entrepreneurship Competition Platform
企业如何开展ERP数据治理工作?_光点科技
redis 源码源文件说明
5G NR MIB Detailed Explanation
华为云DevCloud获信通院首批云原生技术架构成熟度评估的最高级认证