当前位置:网站首页>【机器学习】笔记 4、KNN+交叉验证
【机器学习】笔记 4、KNN+交叉验证
2022-04-23 06:03:00 【若小鱼】
KNN分类模型
- 概念:简单地说,K-近邻算法采用测量不同特征值之间的距离方法进行分类(k-Nearest Neighbor ,KNN)
- k值的作用

- 欧几里得距离

- 在scikit-learn库中使用k-近邻算法
# 鸢尾花分类实现
import sklearn.datasets as ds
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
if __name__ == '__main__':
# 1、获取鸢尾花数据集
iris = ds.load_iris()
# 2、提取样本数据
feature = iris['data'] # 特征数据
target = iris['target'] # 标签数据
# 3、数据集进行拆分
x_train,x_test,y_train,y_test = train_test_split(feature,target,test_size=0.2,random_state=2021)
# 4、观察数据集:看是否需要特征工程的处理
x_train.shape
# 5、实例化模型对象(knn中的k取值不同会直接导致分类结果的不同)
# 模型的超参数:如果模型参数有不同的取值且不同的取值会对模型的分类或预测结果产生直系的影响
knn = KNeighborsClassifier(n_neighbors=3)#n_neighbors == K
# 6、使用训练集数据训练模型
# X:训练集的特征数据。特征数据的维度必须是二维
# Y:训练集的标签数据
knnModel = knn.fit(x_train,y_train)
print(knnModel)
# 7、测试模型:使用测试数据
y_pred= knnModel.predict(x_test) #模型基于测试数据预测返回的分类结果
y_true = y_test #测试集真实的分类结果
# 7.1、对比模型分类结果和真实的分类结果
# 模型的分类结果: [0 0 1 0 0 0 0 0 0 0 0 1 2 2 1 2 1 1 0 1 1 2 2 0 2 1 1 2 0 0]
# 真是的分类结果: [0 0 1 0 0 0 0 0 0 0 0 1 2 2 1 2 1 1 0 1 1 2 2 0 2 1 1 1 0 0]
print('模型的分类结果:',y_pred)
print('真是的分类结果:',y_true)
# 7.2、计算模型预测准确率
# 入参X:测试集的特征数据
# 入参Y:测试集的标签数据
score = knnModel.score(x_test,y_test)
# 模型预测准确率
# score= 0.9666666666666667
print('score=',score)
# 8、使用模型对目标数据集进行预测
targetResult = knnModel.predict([[6.1,5.1,4.5,3.6],[2.1,3.1,4.5,5.6]])
# 预测结果: [2 2]
print('预测结果:',targetResult)
- 如何选择最优k值
- 学习曲线寻找最优k值
# 通过学习曲线寻找最优的K值
import numpy as np
scores = []
ks = []
# 比如我们尝试k值范围为1至50
for i in range(1,50):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(x_train,y_train)#训练模型
score = knn.score(x_test,y_test)#计算模型预测准确率
ks.append(i)
scores.append(score)
scores_arr = np.array(scores)
ks_arr = np.array(ks)
# %matplotliib inline
import matplotlib.pyplot as plt
plt.plot(ks_arr,scores_arr)
plt.xlabel('k_value')
plt.ylabel('score')
plt.show()

K折交叉验证
- 目的:
- 选出最为适合的模型超参数的取值,然后将超参数的值作用到模型的创建中。
- 思想:
- 将样本的训练数据交叉的拆分出不同的训练集和验证集,使用交叉拆分出不同的训练集和验证集分布测试模型的精准度,然后求出的精准度的均值就是此处交叉验证的结果。将交叉验证作到不同的超参数中,选取出精准度最高的超参数作为模型的超参数即可。
- 实现思路
- 将数据集评价分割成K个等份
- 使用1份数据作为测试数据,其余作为训练数据
- 计算测试准确率
- 使用不同的测试集,重复2、3步骤
- 对准确率做平均,作为对未知数据预测准确率的估计

- API
- from sklearn.model_selection import cross_val_score
- cross_val_score(estimator,X,y,cv)
- estimator:模型对象
- X,y;训练集数据
- cv:折数
- 交叉验证在KNN中的基本使用
# 交叉验证
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
import sklearn.datasets as ds
if __name__ == '__main__':
# 1、获取鸢尾花数据集
iris = ds.load_iris()
# 2、提取样本数据
feature = iris['data'] # 特征数据
target = iris['target'] # 标签数据
# 3、数据集进行拆分
x_train,x_test,y_train,y_test = train_test_split(feature,target,test_size=0.2,random_state=2021)
# 4、观察数据集:看是否需要特征工程的处理
x_train.shape
# 5、实例化模型对象(knn中的k取值不同会直接导致分类结果的不同)
# 模型的超参数:如果模型参数有不同的取值且不同的取值会对模型的分类或预测结果产生直系的影响
knn = KNeighborsClassifier(n_neighbors=5)#n_neighbors == K
# 对训练集进行交叉验证
crossScore= cross_val_score(knn,x_train,y_train,cv=5).mean()
print(crossScore)
- 使用交叉验证&学习曲线找寻最优的超参数
# 学习曲线&交叉验证
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
import sklearn.datasets as ds
import matplotlib.pyplot as plt
import numpy as np
if __name__ == '__main__':
# 1、获取鸢尾花数据集
iris = ds.load_iris()
# 2、提取样本数据
feature = iris['data'] # 特征数据
target = iris['target'] # 标签数据
# 3、数据集进行拆分
x_train, x_test, y_train, y_test = train_test_split(feature, target, test_size=0.2, random_state=2020)
scores = []
ks = []
for k in range(3,20):
knn = KNeighborsClassifier(n_neighbors=k)
cross_score = cross_val_score(knn,x_train,y_train,cv=6).mean()
scores.append(cross_score)
ks.append(k)
ks_arr = np.array(ks)
scores_arr = np.array(scores)
plt.plot(ks_arr, scores_arr)
plt.xlabel('k_value')
plt.ylabel('score')
plt.show()
# 取最大值的下标
max_idx = scores_arr.argmax()
#最大值对应的k值
max_k = ks[max_idx]
# 最大值下标: 4
print('最大值下标:',max_idx)
# 最大值对应的k值: 7
print('最大值对应的k值:',max_k)

- 交叉验证可以帮助我们进行模型选择
# 学习曲线&交叉验证
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
import sklearn.datasets as ds
if __name__ == '__main__':
# 1、获取鸢尾花数据集
iris = ds.load_iris()
# 2、提取样本数据
feature = iris['data'] # 特征数据
target = iris['target'] # 标签数据
# 3、数据集进行拆分
x_train, x_test, y_train, y_test = train_test_split(feature, target, test_size=0.2, random_state=2020)
# # 使用交叉验证进行模型选择
from sklearn.linear_model import LogisticRegression
# knn模型
knn = KNeighborsClassifier(n_neighbors=7)
# KNN模型准确率 0.9916666666666666
print('KNN模型准确率',cross_val_score(knn,x_train,y_train,cv=10).mean())
# lr模型
lr = LogisticRegression()
# LR模型准确率 0.9833333333333332
print('LR模型准确率',cross_val_score(lr,x_train,y_train,cv=10).mean())
K-Fold(作为了解)
- Scikit中提供了K-Fold的API
- n-split就是折数
- shuffle指是否对数据洗牌
- random_state为随机种子,固定随机性
from numpy import array
from sklearn.model_selection import KFold
if __name__ == '__main__':
data = array([0.1,0.2,0.3,0.4,0.5,0.6])
kfold = KFold(n_splits=3,shuffle=True,random_state=1)
for train,test in kfold.split(data):
# train: [0.1 0.4 0.5 0.6],test:[0.2 0.3]
# train: [0.2 0.3 0.4 0.6],test:[0.1 0.5]
# train: [0.1 0.2 0.3 0.5],test:[0.4 0.6]
print('train: %s,test:%s' % (data[train],data[test]))
- Scikit中交叉验证接口sklearn.model_selection.cross_val_score,但是该接口没有数据shuffle功能,所以一般结合Kfold一起使用。如果Train数据在分组前已经经过了shuffle处理,比如使用train_test_split分组,那就可以直接使用cross_val_score接口
# 交叉验证结合Kfold
from sklearn.model_selection import cross_val_score
import sklearn.datasets as ds
from sklearn.neighbors import KNeighborsClassifier
iris = ds.load_iris()
X,y = iris.data,iris.target
knn = KNeighborsClassifier(n_neighbors=5)
n_folds = 5
# 对训练数据随机拆分
kf = KFold(n_folds,shuffle=True,random_state=42).get_n_splits(X)
# 交叉验证
scores = cross_val_score(knn,X,y,cv=kf)
print(scores.mean())
版权声明
本文为[若小鱼]所创,转载请带上原文链接,感谢
https://blog.csdn.net/weixin_44162809/article/details/119455631
边栏推荐
- Relabel of Prometheus_ Configs and metric_ relabel_ Configs explanation and usage examples
- MySQL索引【数据结构+索引创建原则】
- oracle undo使用率高问题处理
- 异常记录-8
- Prometheus cortex Architecture Overview (horizontally scalable, highly available, multi tenant, long-term storage)
- 异常记录-22
- Arranges the objects specified in the array in front of the array
- OVS and OVS + dpdk architecture analysis
- Practice of openvswitch VLAN network
- 用反射与注解获取两个不同对象间的属性值差异
猜你喜欢
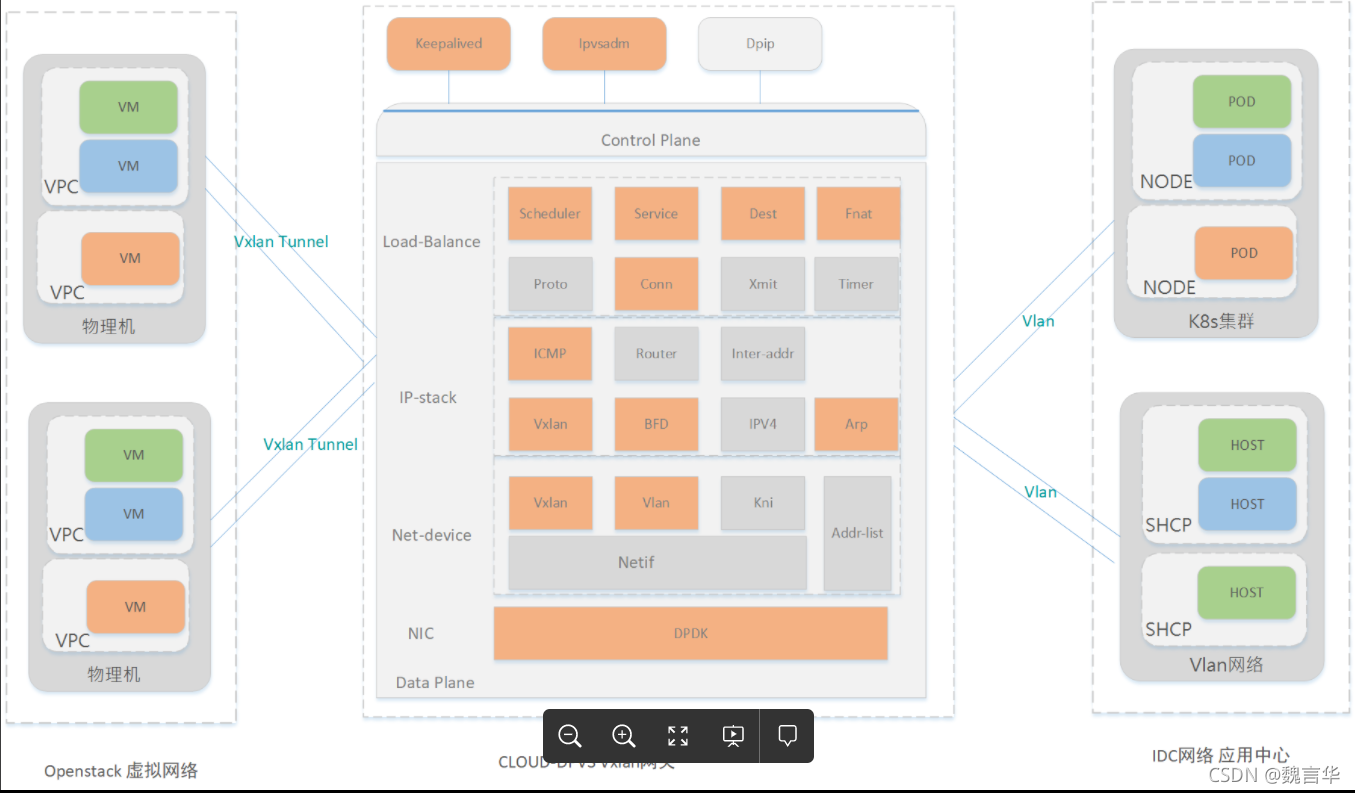
High performance gateway for interconnection between VPC and IDC based on dpdk

MySQL 【读写锁+表锁+行锁+MVCC】

实践使用PolarDB和ECS搭建门户网站
基於ECS搭建雲上博客(雲小寶碼上送祝福,免費抽iphone13任務詳解)

Try catch cannot catch asynchronous errors

MySQL【sql性能分析+sql调优】

Dolphinscheduler调度spark任务踩坑记录
Ali vector library Icon tutorial (online, download)

Build a cloud blog based on ECS (polite experience)

Introduction to RDMA
随机推荐
将博客搬至CSDN
Common views of Oracle database performance analysis
[ES6 quick start]
Basic concepts of database: OLTP / OLAP / HTAP, RPO / RTO, MPP
异常记录-15
Web登录小案例(含验证码登录)
MySQL 【读写锁+表锁+行锁+MVCC】
异常记录-8
try catch 不能捕获异步错误
BCC installation and basic tool instructions
Oracle和mysql批量查询用户下所有表名和表名注释
Thanos Compact组件测试总结(处理历史数据)
异常记录-18
High performance gateway for interconnection between VPC and IDC based on dpdk
Chaos takes you to the chaos project quickly
Prometheus的relabel_configs和metric_relabel_configs解释及用法示例
ORACLE表有逻辑坏块时EXPDP导出报错排查
异常记录-17
19C中ASM network未自动启动的处理
prometheus告警记录持久化(历史告警保存与统计)