当前位置:网站首页>爬虫效率提升方法
爬虫效率提升方法
2022-04-23 05:46:00 【圆滚滚的程序员】
协程:在函数(特殊函数)定义的时候,使用async修饰,函数调用后,内部语句不会立即执行,而是会返回一个协程对象
任务对象:任务对象=高级的协程对象(进一步封装)=特殊的函数,任务对象必须要注册到时间循环对象中,给任务对象绑定回调:爬虫的数据解析中
事件循环:当做是一个装载任务对象的容器,当启动事件循环对象的时候,存储在内的任务对象会异步执行
先起个flask服务
from flask import Flask
import time
app = Flask(__name__)
@app.route('/张三')
def index_bobo():
time.sleep(2)
return 'hello 张三!'
@app.route('/李四')
def index_jay():
time.sleep(2)
return 'hello 李四!'
@app.route('/王五')
def index_tom():
time.sleep(2)
return 'hello 王五!'
if __name__ == '__main__':
app.run(threaded=True)
一,aiohttp模块+单线程多任务异步协程
import asyncio
import aiohttp
import requests
import time
start = time.time()
async def get_page(url):
# page_text = requests.get(url=url).text
# print(page_text)
# return page_text
async with aiohttp.ClientSession() as s: #生成一个session对象
async with await s.get(url=url) as response:
page_text = await response.text()
print(page_text)
return page_text
urls = [
'http://127.0.0.1:5000/张三',
'http://127.0.0.1:5000/李四',
'http://127.0.0.1:5000/王五',
]
tasks = []
for url in urls:
c = get_page(url)
task = asyncio.ensure_future(c)
tasks.append(task)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print(end-start)
二,aiohttp模块实现单线程+多任务异步协程
import aiohttp
import asyncio
from lxml import etree
import time
start = time.time()
# 特殊函数:请求的发送和数据的捕获
# 注意async with await关键字
async def get_request(url):
async with aiohttp.ClientSession() as s:
async with await s.get(url=url) as response:
page_text = await response.text()
return page_text # 返回页面源码
# 回调函数,解析数据
def parse(task):
page_text = task.result()
tree = etree.HTML(page_text)
msg = "".join(tree.xpath('//text()'))
print(msg)
urls = [
'http://127.0.0.1:5000/张三',
'http://127.0.0.1:5000/李四',
'http://127.0.0.1:5000/王五',
]
tasks = []
for url in urls:
c = get_request(url)
task = asyncio.ensure_future(c)
task.add_done_callback(parse) #绑定回调函数!
tasks.append(task)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print(end-start)
三,requests模块+线程池
import time
import requests
from multiprocessing.dummy import Pool
start = time.time()
urls = [
'http://127.0.0.1:5000/张三',
'http://127.0.0.1:5000/李四',
'http://127.0.0.1:5000/王五',
]
def get_request(url):
page_text = requests.get(url=url).text
print(page_text)
return page_text
pool = Pool(3)
pool.map(get_request, urls)
end = time.time()
print('总耗时:', end-start)
版权声明
本文为[圆滚滚的程序员]所创,转载请带上原文链接,感谢
https://blog.csdn.net/qq_39483957/article/details/124322610
边栏推荐
猜你喜欢
Best practices for MySQL storage time
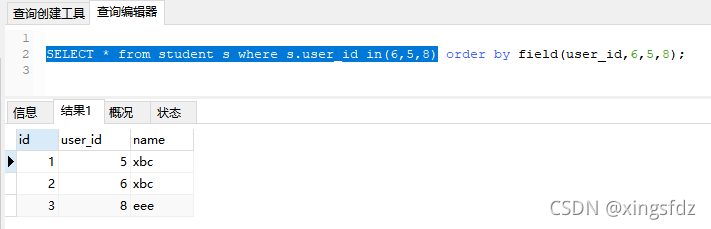
SQL sorts according to the specified content

Addition, deletion, query and modification of data

Mysql database foundation

Type conversion in C #

Explanation of the second I interval of 2020 Niuke summer multi school training camp

基于Sentinel+Nacos 对Feign Client 动态添加默认熔断规则

Detection technology and principle
Kalman filter and inertial integrated navigation

小区房价可视化

随机推荐
MySQL table constraints and table design
Collection and map thread safety problem solving
Common shortcut keys of IDE
安装pyshp库
Usage scenario of copyonwritearraylist
[leetcode 6] zigzag transformation
[leetcode 401] binary Watch
gst-launch-1.0用法小记
@Problems caused by internal dead loop of postconstruct method
Kibana search syntax
Import of data
SQL -- data filtering and grouping
用C语言实现重写strcmp等四个函数
MySQL best practices for creating tables
[leetcode 59] spiral matrix II
NVIDIA Jetson: GStreamer 和 openMAX(gst-omx) 插件
Definition of C class and method
6.Reversal
4. Print form
基于Sentinel+Nacos 对Feign Client 动态添加默认熔断规则