当前位置:网站首页>redis学习笔记
redis学习笔记
2022-08-09 07:02:00 【巷口暖风】
Redis介绍
Redis是NOSQL,即非关系型数据库,也是缓存数据库,即将数据存储在缓存中,缓存的读取速度快,能够大大的提高运行效率,但是保存时间有限.
Redis是现在最受欢迎的NoSQL数据库之一,Redis是一个使用ANSI C编写的开源、包含多种数据结构、支持网络、基于内存、可选持久性的键值对存储数据库,其具备如下特性:
基于内存运行,性能高效
支持分布式,理论上可以无限扩展
key-value存储系统
开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API
相比于其他数据库类型,Redis具备的特点是:
C/S通讯模型
单进程单线程模型
丰富的数据类型
操作具有原子性
持久化
高并发读写
支持lua脚本
五大数据结构
String类型:
它是一个二进制安全的字符串,意味着它不仅能够存储字符串、还能存储图片、视频等多种类型, 最大长度支持512M。
对每种数据类型,Redis都提供了丰富的操作命令,如:
GET/MGET
SET/SETEX/MSET/MSETNX
INCR/DECR
GETSET
DEL
哈希类型:
该类型是由field和关联的value组成的map。其中,field和value都是字符串类型的。
Hash的操作命令如下:
HGET/HMGET/HGETALL
HSET/HMSET/HSETNX
HEXISTS/HLEN
HKEYS/HDEL
HVALS
列表类型:
该类型是一个插入顺序排序的字符串元素集合, 基于双链表实现。
List的操作命令如下:
LPUSH/LPUSHX/LPOP/RPUSH/RPUSHX/RPOP/LINSERT/LSET
LINDEX/LRANGE
LLEN/LTRIM
集合类型:
Set类型是一种无顺序集合, 它和List类型最大的区别是:集合中的元素没有顺序, 且元素是唯一的。
Set类型的底层是通过哈希表实现的,其操作命令为:
SADD/SPOP/SMOVE/SCARD
SINTER/SDIFF/SDIFFSTORE/SUNION
Set类型主要应用于:在某些场景,如社交场景中,通过交集、并集和差集运算,通过Set类型可以非常方便地查找共同好友、共同关注和共同偏好等社交关系。
顺序集合类型:
ZSet是一种有序集合类型,每个元素都会关联一个double类型的分数权值,通过这个权值来为集合中的成员进行从小到大的排序。与Set类型一样,其底层也是通过哈希表实现的。
ZSet命令:
ZADD/ZPOP/ZMOVE/ZCARD/ZCOUNT
ZINTER/ZDIFF/ZDIFFSTORE/ZUNION
string:有点像java的hashMap,存的时候什么key,取的时候也什么key,常用于做缓存,保存用户信息、查询列表等;
hash:这个有点像hashMap的value又套了个hashMap,下文有举例,一看就明白了;
list:有序列表,类似Java的linkedList,可以在左边右边插入数据;
set:去重集合,类似Java的hashset,可用于求交集,比如共同好友;
zset:带权重的set集合,可用于做排行榜;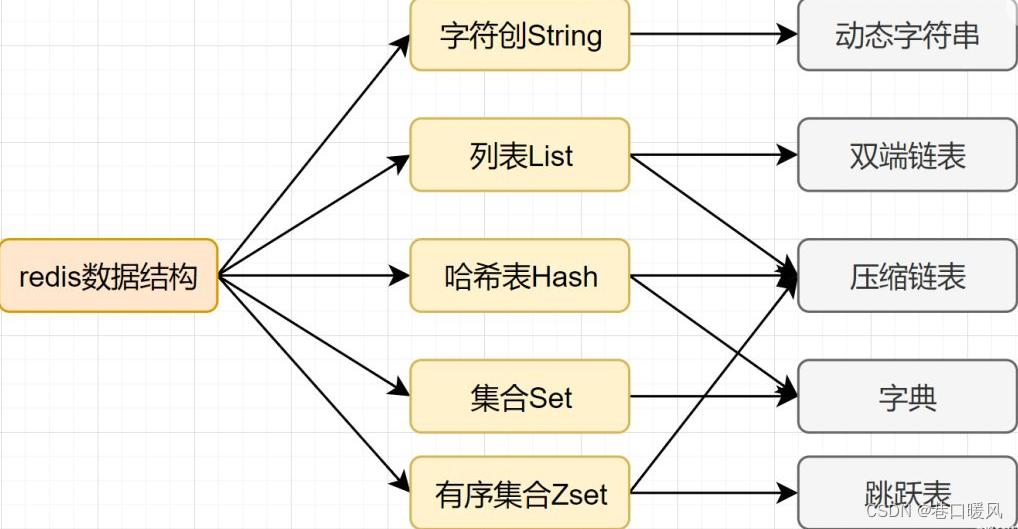

redis永久化
二者的区别
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
二者优缺点
RDB存在哪些优势呢?
1). 一旦采用该方式,那么你的整个Redis数据库将只包含一个文件,这对于文件备份而言是非常完美的。比如,你可能打算每个小时归档一次最近24小时的数据,同时还要每天归档一次最近30天的数据。通过这样的备份策略,一旦系统出现灾难性故障,我们可以非常容易的进行恢复。
2). 对于灾难恢复而言,RDB是非常不错的选择。因为我们可以非常轻松的将一个单独的文件压缩后再转移到其它存储介质上。
3). 性能最大化。对于Redis的服务进程而言,在开始持久化时,它唯一需要做的只是fork出子进程,之后再由子进程完成这些持久化的工作,这样就可以极大的避免服务进程执行IO操作了。
4). 相比于AOF机制,如果数据集很大,RDB的启动效率会更高。
RDB又存在哪些劣势呢?
1). 如果你想保证数据的高可用性,即最大限度的避免数据丢失,那么RDB将不是一个很好的选择。因为系统一旦在定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失。
2). 由于RDB是通过fork子进程来协助完成数据持久化工作的,因此,如果当数据集较大时,可能会导致整个服务器停止服务几百毫秒,甚至是1秒钟。
AOF的优势有哪些呢?
1). 该机制可以带来更高的数据安全性,即数据持久性。Redis中提供了3中同步策略,即每秒同步、每修改同步和不同步。事实上,每秒同步也是异步完成的,其效率也是非常高的,所差的是一旦系统出现宕机现象,那么这一秒钟之内修改的数据将会丢失。而每修改同步,我们可以将其视为同步持久化,即每次发生的数据变化都会被立即记录到磁盘中。可以预见,这种方式在效率上是最低的。至于无同步,无需多言,我想大家都能正确的理解它。
2). 由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容。然而如果我们本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,我们可以通过redis-check-aof工具来帮助我们解决数据一致性的问题。
3). 如果日志过大,Redis可以自动启用rewrite机制。即Redis以append模式不断的将修改数据写入到老的磁盘文件中,同时Redis还会创建一个新的文件用于记录此期间有哪些修改命令被执行。因此在进行rewrite切换时可以更好的保证数据安全性。
4). AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,我们也可以通过该文件完成数据的重建。
AOF的劣势有哪些呢?
1). 对于相同数量的数据集而言,AOF文件通常要大于RDB文件。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
2). 根据同步策略的不同,AOF在运行效率上往往会慢于RDB。总之,每秒同步策略的效率是比较高的,同步禁用策略的效率和RDB一样高效。
二者选择的标准,就是看系统是愿意牺牲一些性能,换取更高的缓存一致性(aof),还是愿意写操作频繁的时候,不启用备份来换取更高的性能,待手动运行save的时候,再做备份(rdb)。rdb这个就更有些 eventually consistent的意思了。不过生产环境其实更多都是二者结合使用的。
常用配置
RDB持久化配置
Redis会将数据集的快照dump到dump.rdb文件中。此外,我们也可以通过配置文件来修改Redis服务器dump快照的频率,在打开6379.conf文件之后,我们搜索save,可以看到下面的配置信息:
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照。
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,则dump内存快照。
AOF持久化配置
在Redis的配置文件中存在三种同步方式,它们分别是:
appendfsync always #每次有数据修改发生时都会写入AOF文件。
appendfsync everysec #每秒钟同步一次,该策略为AOF的缺省策略。
appendfsync no #从不同步。高效但是数据不会被持久化。
5.redis启用持久化 aof 之后 报错
Can’t open the append-only file: Input/output error
是因为 在win下 没用管理员权限 (一个坑)
redis三大问题
一、缓存处理流程
前台请求,后台先从缓存中取数据,取到直接返回结果,取不到时从数据库中取,数据库取到更新缓存,并返回结果,数据库也没取到,那直接返回空结果。
二、缓存穿透
描述:
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决方案:
接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
三、缓存击穿
描述:
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
解决方案:
设置热点数据永远不过期。
加互斥锁,互斥锁参考代码如下:
说明:
1)缓存中有数据,直接走上述代码13行后就返回结果了
2)缓存中没有数据,第1个进入的线程,获取锁并从数据库去取数据,没释放锁之前,其他并行进入的线程会等待100ms,再重新去缓存取数据。这样就防止都去数据库重复取数据,重复往缓存中更新数据情况出现。
3)当然这是简化处理,理论上如果能根据key值加锁就更好了,就是线程A从数据库取key1的数据并不妨碍线程B取key2的数据,上面代码明显做不到这点。
四、缓存雪崩
描述:
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是, 缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
设置热点数据永远不过期。
边栏推荐
猜你喜欢

学习小笔记---机器学习
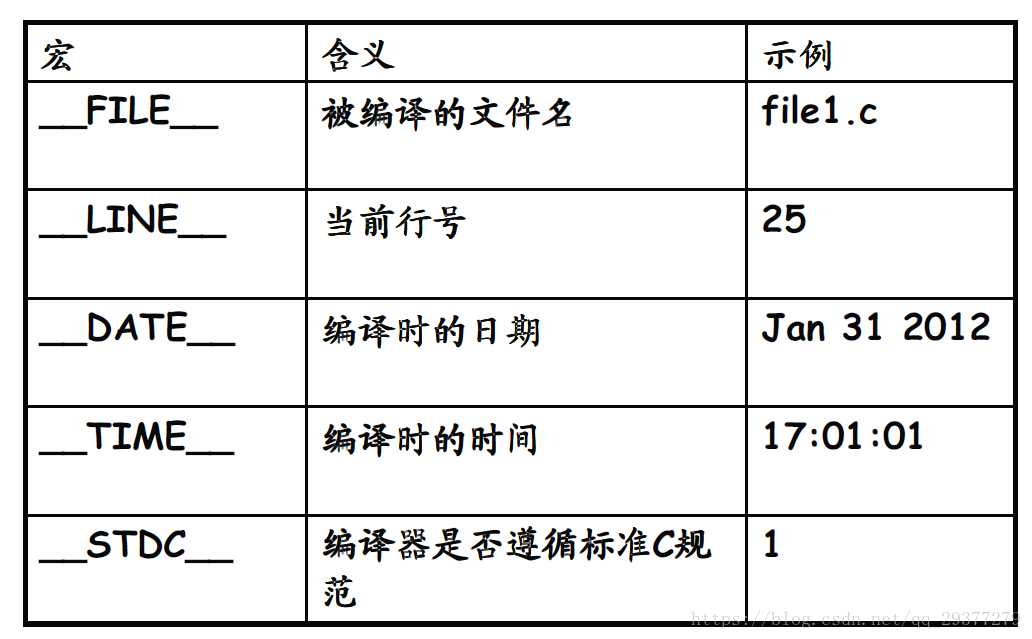
Built-in macros in C language (define log macros)
Leetcode 70 stairs issues (Fibonacci number)
无重复的字符的最长子串
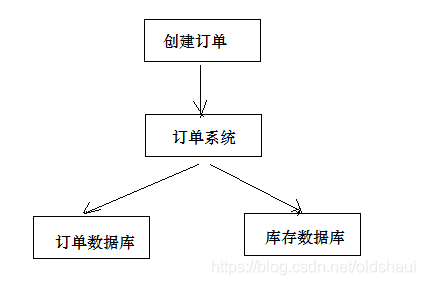
什么是分布式事务
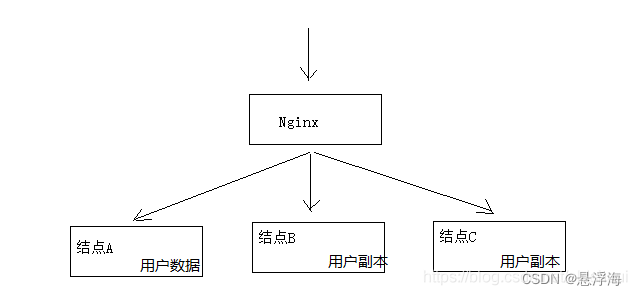
分布式理论
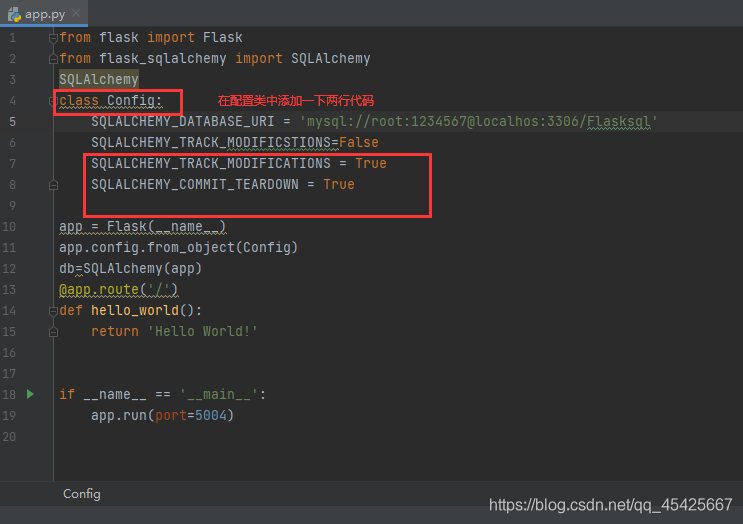
报错:FSADeprecationWarning: SQLALCHEMY_TRACK_MODIFICATIONS重大开销和将disab补充道
Altium designer软件常用最全封装库,包含原理图库、PCB库和3D模型库
Distributed id generator implementation
ByteDance Interview Questions: Mirror Binary Tree 2020
随机推荐
Common Oracle Commands
crc calculation
The working principle of the transformer (illustration, schematic explanation, understand at a glance)
Flask failed to create database without error
Quectel EC20 4G module dial related
cut命令的使用实例
报错:FSADeprecationWarning: SQLALCHEMY_TRACK_MODIFICATIONS重大开销和将disab补充道
tianqf的解题思路
Lottie系列二:高级属性
Mysql实操
bzoj 5333 [Sdoi2018]荣誉称号
长沙学院2022暑假训练赛(一)六级阅读
Built-in macros in C language (define log macros)
way of thinking problem-solving skills
vlucas/phpdotenv phpdotenv获取变量内容偶尔出现返回false
jvm线程状态
MongDb query method
线程池总结
stm32定时器之简单封装
sklearn数据预处理