当前位置:网站首页>关于弱监督学习的详细介绍——A Brief Introduction to Weakly Supervised Learning
关于弱监督学习的详细介绍——A Brief Introduction to Weakly Supervised Learning
2022-08-10 23:01:00 【qq_45697032】
目录
介绍
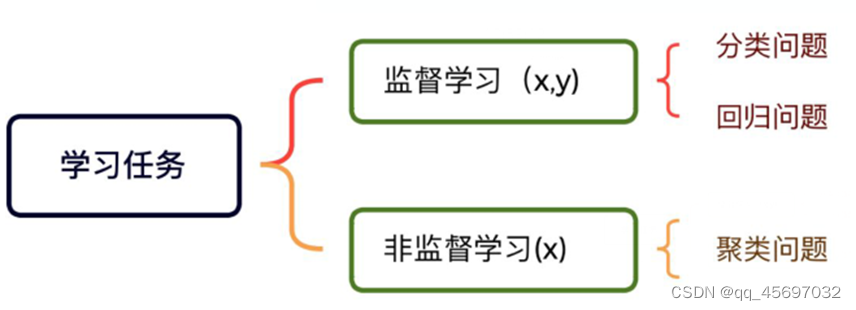
在机器学习领域,学习任务可大致划分为两类,一种是监督学习,另一种是非监督学习。通常,两者都需要从包含大量训练样本的训练数据集中学习预测模型,每个训练样本对应于事件/对象。
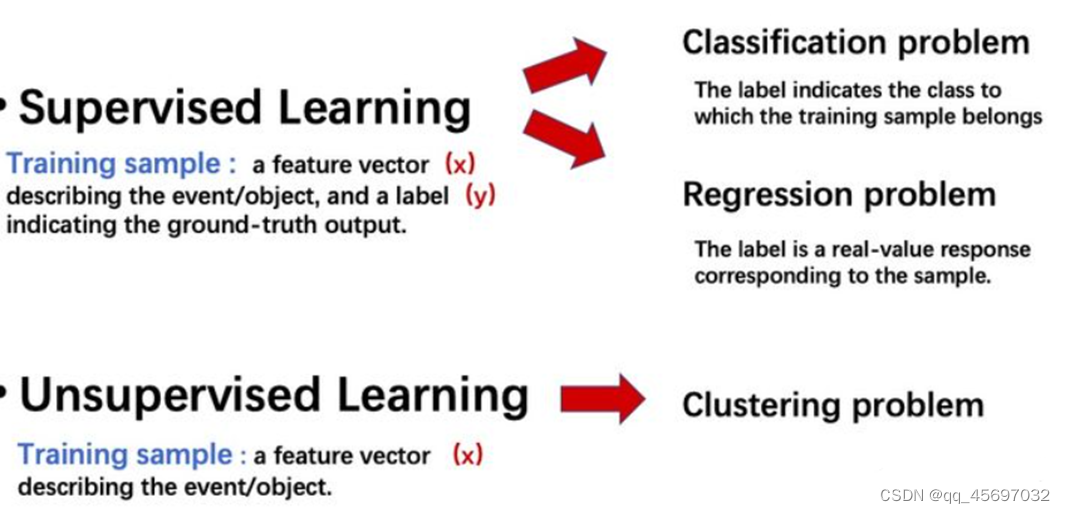
监督学习的训练数据由两部分组成:描述事件/对象的特征向量(x),以及 ground-truth 的标签(y)。而非监督学习的训练数据只有一个部分:描述事件/对象的特征向量(x),但是没有标签(y)。分类问题和回归问题是监督学习的代表,聚类学习是非监督学习的代表。
南京大学周志华教授在2018年1月发表的论文《A Brief Introduction to Weakly Supervised Learning》中,将弱监督详细分为不完全监督(Incomplete supervision)、不确切监督(Inexact supervision)、不准确监督(Inaccurate supervision)。
- incomplete supervision:只有一部分子集给出标签;
- inexact supervision:训练集样本只给出大概的标签;
- inaccurate supervision:训练集样本不一定可信。

对于这三种典型的弱监督学习,我们可以考虑使用不同的技术去进行改善和解决。
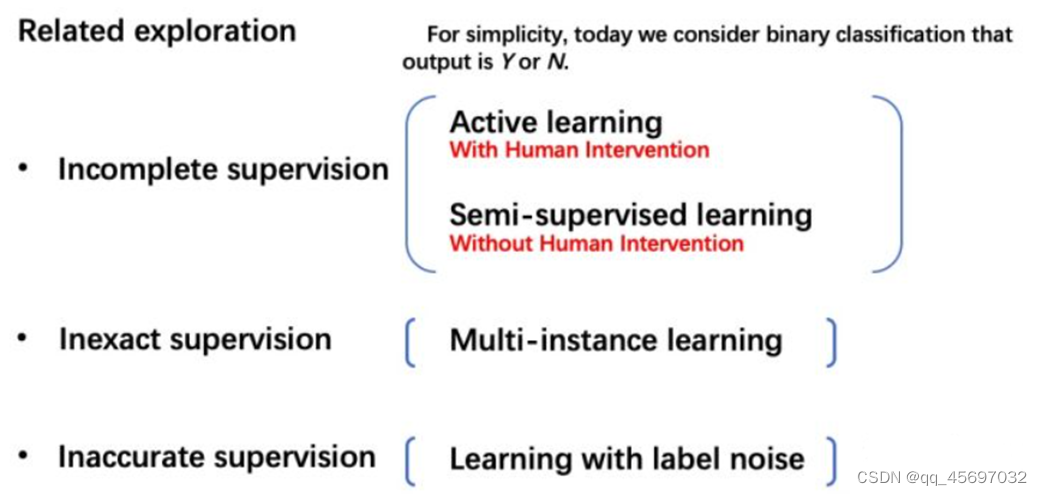
为了解决不完全监督,我们可以考虑两种主要技术,主动学习和半监督学习。前者是有人类干预的,后者是没有人类干预的。
为了解决不确切监督,我们可以考虑多实例学习。
为了解决不精确监督,我们考虑带噪学习。
下面对以上进行介绍。
主动学习
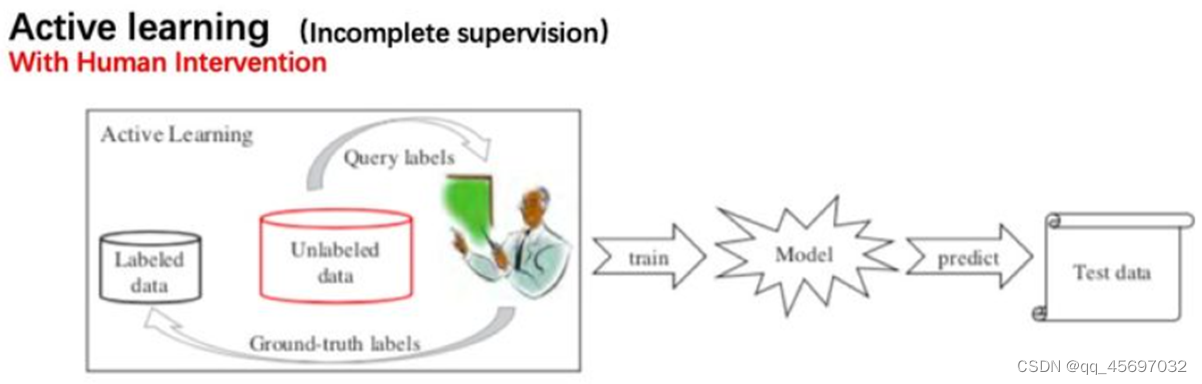
首先为了解决不完全监督,我们考虑主动学习(Active learning),这个方法是训练过程中有人工干预的。由以上图,输入的是一些标注过的数据和没有标注过的数据,首先,我们先训练这些标注过的数据,然后根据得到的经验对这些没有标注过的数据进行聚类。在这些未标记数据中,主动学习尝试选择最有价值的未标记实例进行查询。主动学习的目标是最小化查询的数量。
2019年CVPR有一篇主动学习的相关论文,叫《Large-scale interactive object segmentation with human annotators》(如下图)。
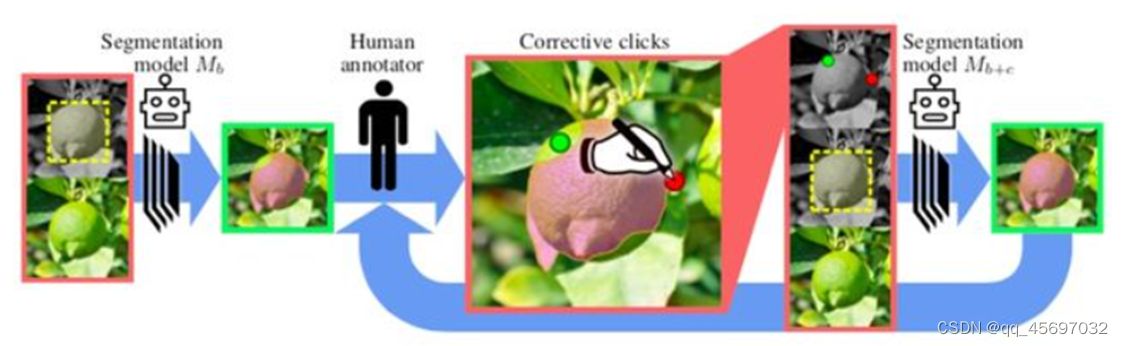
由于手动注释对象分割掩码非常耗时,所以这篇论文考虑交互式对象分割方法,其中人类注释器和机器分割模型协作完成分割任务。
半监督学习
接下来我们看看解决不完全监督的第二种技术,半监督学习(Semi-supervised learning),这种方法没有人类干预。
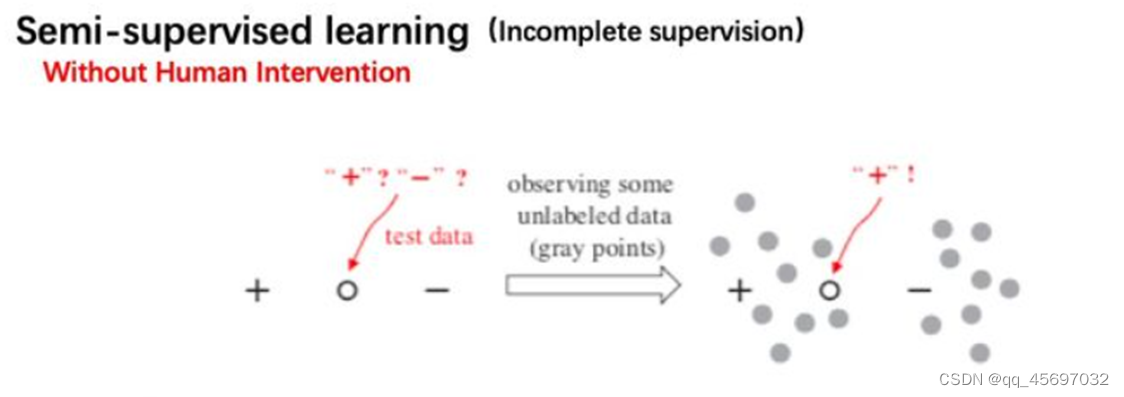
以上图举例,如果我们已知一个数据是positive,另一个数据是negative,在两个数据点正中间有一个test data,此时我们是很难去判断这个test data到底是positive 还是negative的。但是如果我们被允许去观察一些未被标注的数据分布(右边部分的灰点),这时我们还是可以较肯定的认为test data是positive。
多实例学习
为了解决不确切监督,我们可以考虑多实例学习(Multi-instance learning)。

实际上,几乎所有监督学习算法都有其多实例对等体。
训练数据集中每一个数据看做一个包(Bag),每个包由多个实例(Instance)构成,每个包有一个可见的标签,在上图例子中,假设这个包大小为8*8,如果我们用size为2*2的图片包生成器(Image bag generators)去获得实例,那么我们可以得到16个实例(Instance)。显而易见,我们这个包是有标签的(左图),老虎,而包中的每个实例是没有标签的(右图)。
多实例学习假设每一个正包必须存在至少一个关键实例。这意味着,假设这个例子中关键实例是示例9,那么这个包的标签为正(positive)。多实例学习的过程就是通过模型对包及其包含的多个实例进行分析预测得出包的标签。
带噪学习
最后,解决不精确监督,我们可以考虑带噪学习(Learning with label noise)。
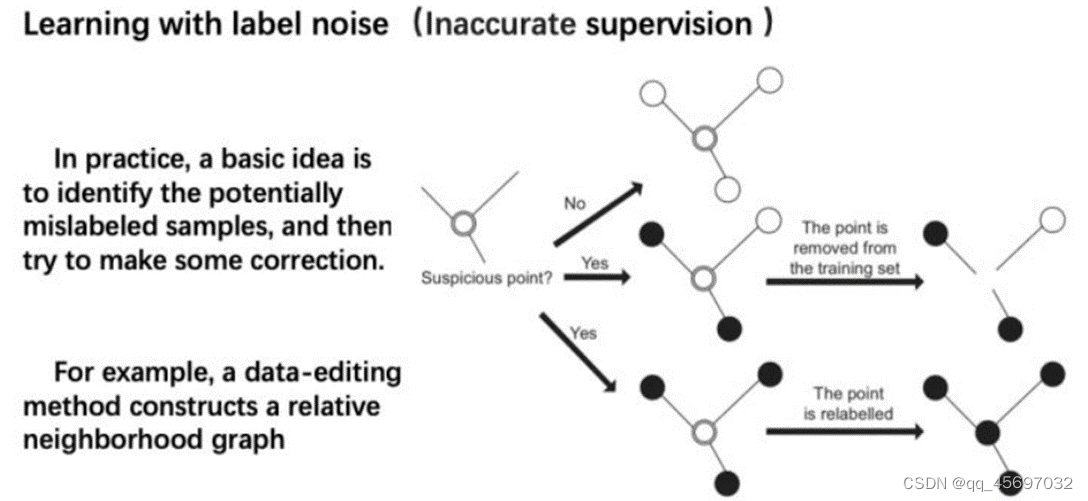
在实践中,基本的思想是识别潜在的误分类样本,然后尝试进行修正。例如,我们用数据编辑的方法去构建一个关系相邻表。然后我们判断一个点是否为可疑点。我们判断这个点和相邻的点是否一样。如果一样,那这个点就不是可疑的,将保持原样。如果这个点和相邻的点不一样,那么这个点是可疑的,这个点将被删除或者被重新标记。
Snorkel 框架介绍
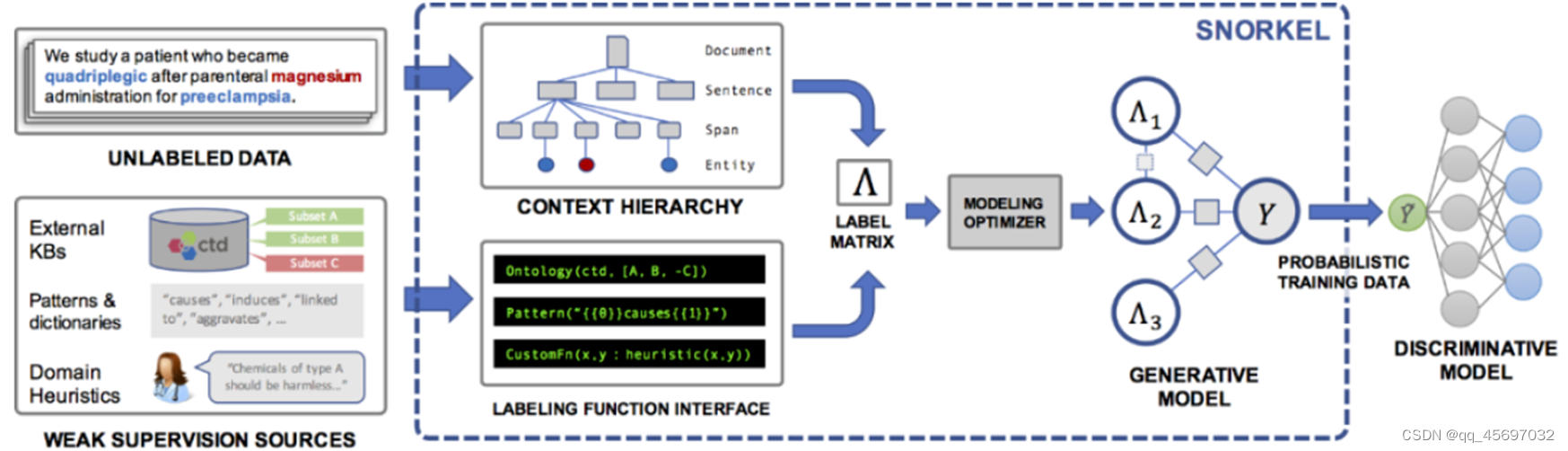
Snorkel 是一种快速产出训练数据的弱监督系统,利用标签函数,可以快速产生、管理、建模训练数据。在Snorkel中,不需要使用手工标记的训练数据,而是要求用户编写标记函数 ( LF ),即用于标记未标记数据子集的黑盒代码片段。
研究人员可以使用一组这样的标注函数来为机器学习模型标注训练数据。由于标记函数只是任意的代码片段,所以它们可以对任意信号进行编码:模式、启发式、外部数据资源、来自众包人员的带噪声的标签、弱分类器等等。还可以获得标注函数作为代码所特有的优点,比如模块化、可重用性和可调试性。例如,如果建模目标发生了变化,可以调整标注函数来快速适应这种变化。
参考
浅谈弱监督学习(Weakly Supervised Learning) - 知乎
干货 | 弱监督学习框架 Snorkel 在大规模文本数据集"自动标注"任务中的实践_携程技术的博客-CSDN博客
(1条消息) 弱监督学习——A brief introduction to weakly supervised learning_shaoyue1234的博客-CSDN博客_弱监督学习
边栏推荐
猜你喜欢



随机推荐
高精度减法
MySQL: MySQL Cluster - Principle and Configuration of Master-Slave Replication
李宏毅机器学习-- Backpropagation
Pengcheng Cup 2022 web/misc writeup
IFIT的架构与功能
MUI框架开发app中出现的问题
常见的加密方式有哪几种,各有哪些优缺点
响应式pbootcms模板运动健身类网站
性能不够,机器来凑;jvm调优实战操作详解
国内vr虚拟全景技术领先的公司
手机端出现Z-Fighting现象
HCTF 2018 WarmUP writeup
二叉树 | 对称二叉树、相同的树、子树相同 | leecode刷题笔记
PyQt5 窗口自适应大小
ArcGIS应用基础知识
How to bounce the shell
ACTF 2022 writeup
大厂面试热点:“热修复机制及常见的几个框架介绍”
蓝帽杯 2022 web/misc writeup
Android面试冲刺:2022全新面试题——剑指Offer(备战金九银十)