当前位置:网站首页>PyTorch官方文档学习笔记(备忘)
PyTorch官方文档学习笔记(备忘)
2022-08-10 22:52:00 【吃吃今天努力学习了吗】
以前学习过一些pytorch教程,平时也会应用到,但发现技术文档才是最好最系统最全面的教材,现在从头学习梳理一遍,本文记录一下平时记不住的内容。
Tensors
In-place operations
就地操作,将结果存储到操作数中。用 _ 结尾,比如 x.copy_(),x.t_(),x.add_(),都会改变x。
in-place 操作节省了一些内存,但是也会丢失历史记录,所以不建议使用。
Tensor to NumPy array
CPU 上的张量和 NumPy 数组可以共享它们的底层内存位置,改变其中一个将会改变另一个。
Tensor to NumPy array:
t = torch.ones(5)
n = t.numpy()
NumPy array to Tensor:
n = np.ones(5)
t = torch.from_numpy(n)
这时改变其中一个的值,另一个随之改变。
Datasets & Dataloaders
处理数据样本的代码容易混乱,难以维护;理想情况下,我们希望数据集代码与模型训练代码分离,以获得更好的可读性和模块化。
PyTorch 提供了两个工具:torch.utils.data.Dataset, torch.utils.data.DataLoader。Dataset 存储样本和它们对应的标签,DataLoader 在 Dataset 周围包装一个可迭代对象,以便方便地访问样本。
Createing a Custom Dataset for your files
必须实现三个函数:__init__ , __len__, __getitem__
初始化时包含图像、标签和两者的transform等。
Preparing your data for training with DataLoaders
Dataset 每次检索我们数据集的特征并标记一个样本。在训练模型时,我们通常希望小批量地通过样本,在每个epoch重新打乱数据以减少模型过拟合,并使用python的multiprocessing来加速数据检索。DataLoader 是一个可迭代对象,为我们做了上面这些复杂的事。
from torch.utils.data import DataLoader
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(testing_data, batch_size=64, shuffle=True)
每次迭代都返回一批 train_features 和 train_labels(分别包含 64 个特征和标签),指定 shuffle=True,在遍历所有 batches 后数据被打乱。对于更细粒度的数据加载顺序控制,查看 Samplers 的用法。
# Display image and label.
train_features, train_labels = next(iter(train_dataloader))
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img, cmap='gray')
plt.show()
Transforms
使用转换对数据进行一些操作使其适合训练。
所有的T哦日出Vision数据集都有两个参数:transform, target_transform。torchvision.transforms 模块可以方便的使用转换。
ToTensor()
converts a PIL image or NumPy ndarray into a FloatTensor. and scales the image’s pixel intensity values in the range [0., 1.].
Lambda Transforms
用户可以自己定义 Lambda 函数。
例如,这里定义了一个函数将整数转换成一个 one-hot 编码张量。先创建一个大小为10的零张量,调用scatter_在标签y给出的索引上赋值为1。
target_transform = Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(dim=0, index=torch.tensor(y), value=1))
Build Model
torch.nn 提供了构建神经网络所需的构建模块。神经网络本身是由其他模块(layers)组成的模块。这种嵌套结构允许轻松地构建和管理复杂的体系结构。
Get Device for Training
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {
device} device")
Define the Class
__init__初始化神经网络层,forward方法实现对输入数据的操作。
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28,512),
nn.ReLU(),
nn.Linear(512,512),
nn.ReLU(),
nn.Linear(512,10),
)
def forward(self,x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
使用时先创建实例,然后转移到device上。
model = NeuralNetwork().to(device)
使用模型,传入数据:
logits = model(X)
pred_probab = nn.Softmax(dim=1)(logits)
y_pred = pred_probab.argmax(1)
Model Parameters
使用模型的parameters()named_parameters() 方法可以访问模型的所有参数。
for name, param in model.named_parameters():
print(f"Layer: {
name} | Size: {
param.size()} | Values: {
param[:2]}\n")
Autograd
Automitic differentiation with torch.autograd,支持自动计算梯度的任何计算图。
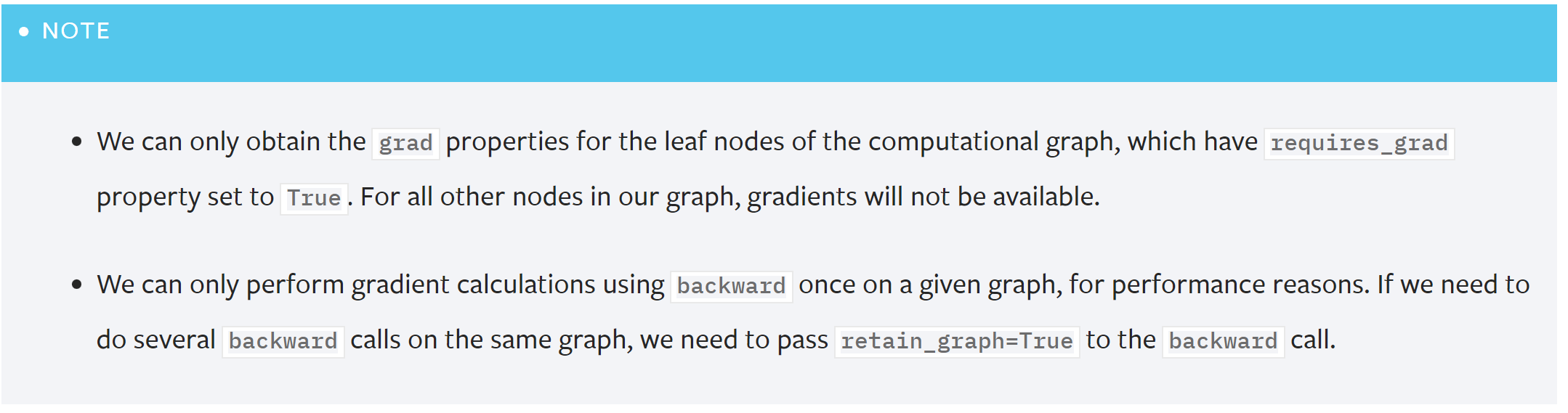
设置张量的requires_grad 属性。反向传播函数的引用存储在一个张量的grad_fn属性中。
Computing Gradients
loss.backward()
Disabling Gradient Tracking
当已经训练了模型,只是想应用到一些输入数据上,只想通过网络进行正向计算时,可以通过torch.no_grad()来停止追踪计算。或者使用detach()
禁用梯度追踪的原因:
- 将神经网络中的一些参数标记为
frozen parameters。这是对预训练网络进行微调的常见场景。 - 只做前向传播时为了加速计算,不跟踪梯度的张量的计算更有效率。
从概念上讲,autograd 在一个由 Function 对象组成的有向无环图(DAG)中保存数据(张量)和所有执行操作(以及产生的新张量)的记录。在这个 DAG 中,叶是输入张量,根是输出张量。通过跟踪这个从根到叶的图,可以使用链式法则自动计算梯度。
在向前传递中,autograd 同时做两件事:
- 运行请求的操作来计算结果张量
- 在 DAG 中维护操作的梯度函数 (gradient function)
当在 DAG 根上调用.backward()时,向后传递开始。然后 autograd:
- 计算每个
.grad_fn, - 将它们累积到各自张量的
. grad属性中, - 使用链式法则,一直传播到叶张量。
Note: DAGs are dynamic in PyTorch. 每次backward()后,会填充一个新图。如果需要,可以在每次迭代中更改形状、大小和操作。
Optimization
超参数 Hyperparameters 是可调参数,控制模型优化过程。
然后定义 loss function 和 optimizer。
def train_loop(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
for batch, (X, y) in enumerate(dataloader):
# Compute prediction and loss
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {
loss:>7f} [{
current:>5d}/{
size:>5d}]")
def test_loop(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {
(100*correct):>0.1f}%, Avg loss: {
test_loss:>8f} \n")
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
epochs = 10
for t in range(epochs):
print(f"Epoch {
t+1}\n-------------------------------")
train_loop(train_dataloader, model, loss_fn, optimizer)
test_loop(test_dataloader, model, loss_fn)
print("Done!")
Save & Load Model
torch.save(model.state_dict(), 'model_weights.pth')
model.load_state_dict(torch.load('model_weights.pth'))
torch.save(model, 'model.pth')
model = torch.load('model.pth')
(待补充)
Reference:
官方教程指路
A u t h o r : C h i e r Author: Chier Author:Chier
边栏推荐
猜你喜欢






随机推荐
VulnHub之DC靶场下载与DC靶场全系列渗透实战详细过程
Splunk中解决数据质量问题常见日期格式化
canvas
Btree索引和Hash索引
国内vr虚拟全景技术领先的公司
Configuring vim(7) from scratch - autocommands
Redis
产品web3d效果动态展示更生动形象
PlaidCTF 2022 Amongst Ourselves: Shipmate writeup
腾讯云轻量应用服务器配置及建网站教程
HGAME 2022 Final writeup
fme csmapreprojector转换器使用高程异常模型进行高程基准转换
OneNote tutorial, how to organize notebooks in OneNote?
y93.第六章 微服务、服务网格及Envoy实战 -- Envoy配置(四)
leetcode:357. 统计各位数字都不同的数字个数
JS学习 2022080
MySQL学习笔记(2)——简单操作
"DevOps Night Talk" - Pilot - Introduction to CNCF Open Source DevOps Project DevStream - feat. PMC member Hu Tao
pytorch tear CNN
N1BOOK writeup