当前位置:网站首页>Flink DataStream 类型系统 TypeInformation
Flink DataStream 类型系统 TypeInformation
2022-04-23 14:51:00 【smartsi】
Flink DataStream 应用程序所处理的事件以数据对象的形式存在。函数调用时会传入数据对象,同时也可以输出数据对象。因此,Flink 在内部需要能够处理这些对象。当通过网络传输或者读写状态后端、检查点以及保存点时,需要对它们进行序列化和反序列化。为了能够更高效的做到这一点,Flink 需要详细了解应用程序处理的数据类型。Flink 使用类型信息的概念来表示数据类型,并为每种数据类型生成特定的序列化器、反序列化器以及比较器。
此外,Flink 还有一个类型提取系统,可以分析函数的输入和返回类型来自动获取类型信息,进而获得序列化器和反序列化器。但是,在某些情况下,例如使用了 Lambda 函数或者泛型类型,必须显式提供类型信息才能使应用程序正常工作或者提高其性能。
在本文中,我们会讨论 Flink 支持的数据类型,如何为数据类型创建类型信息,以及如何在 Flink 的类型系统无法自动推断函数的返回类型时提供提示,最后简单说明一下显示指定类型信息的两个场景。
1. 数据类型
Flink 支持 Java 和 Scala 所有常见的数据类型,也不需要像 Hadoop 一样去实现一个特定的接口(org.apache.hadoop.io.Writable),能够自动识别数据类型。使用最多的可以分为如下几类,如下图所示:
从图中可以看到 Flink 类型可以分为基本类型、数组类型、复合类型、辅助类型以及泛型。
1.1 基本类型
Flink 能够支持所有 Java 和 Scala 原生基本类型(包装类型)以及 Void、String、Date、BigDecimal、BigInteger 等类型。例如通过从给定的元素集中创建 DataStream 数据集:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 创建 Integer 类型的数据集
DataStream<Integer> integerElements = env.fromElements(1, 2, 3);
// 创建 String 类型的数据集
DataStream<String> stringElements = env.fromElements("1", "2", "3");1.2 数组类型
数组类型包含两种类型:
- 基本类型数组:基本类型的 Java 数组,支持 boolean、byte、short、int、long、float 等
- 对象数组:Object 类型的 Java 数组,支持 String 以及其他对象
例如通过从给定的元素集中创建 DataStream 数据集:
int[] a = {1, 2};
int[] b = {3, 4};
DataStream<int[]> arrayElements = env.fromElements(a, b);1.3 复合数据类型
1.3.1 Java Tuples 类型
Flink 在 Java 接口中定义了元组类(Tuple)供用户使用。元组是由固定数量的强类型字段组成的复合数据类型。如下代码所示,创建 Tuple 数据类型数据集:
DataStream<Tuple2> tupleElements = env.fromElements(new Tuple2(1, "a"), new Tuple2(2, "b"));Flink 提供了 Java 元组的高效实现,最多包含 25 个字段,每个字段长度都对应一个单独的实现,即 Tuple0 到 Tuple25。如果字段数量超过上限,可以通过继承 Tuple 类的方式进行拓展。
1.3.2 Scala Case Class 与 Tuple 类型
Flink 支持任意的 Scala Case Class 以及 Scala tuples 类型,支持的字段数量上限为 22,支持通过字段名称和位置索引获取指标,不支持存储空值。如下代码实例所示,定义 WordCount Case Class 数据类型,然后通过 fromElements 方法创建 input 数据集,调用 keyBy() 方法对数据集根据 word 字段重新分区。
// 定义WordCount Case Class数据结构
case class WordCount(word: String, count: Int)
// 通过fromElements方法创建数据集
val input = env.fromElements(WordCount("hello", 1), WordCount("world", 2))
val keyStream1 = input.keyBy("word") // 根据word字段为分区字段,
val keyStream2 = input.keyBy(0) //也可以通过指定position分区通过使用 Scala Tuple 创建 DataStream 数据集,其他的使用方式和 Case Class 相似。需要注意的是,如果根据名称获取字段,可以使用 Tuple 中的默认字段名称:
// 通过 scala Tuple 创建具有两个元素的数据集
val tupleStream: DataStream[Tuple2[String, Int]] = env.fromElements(("a", 1),("c", 2))
// 使用默认字段名称获取字段,其中 _1 表示 tuple 的第一个字段
tupleStream.keyBy("_1")1.3.3 ROW 类型
Row 是一种固定长度、可识别空值的复合类型,以确定的字段顺序存储多个值。每个字段的类型都可以不一样并且每个字段都可以为空。由于无法自动推断行字段的类型,因此在生成 Row 时都需要提供类型信息。如下代码所示,创建 Row 数据类型数据集:
DataStream<Row> rowElements = env.fromElements(Row.of(0, "a", 3.14));1.3.4 POJO 类型
Flink 会分析那些不属于任何一类的数据类型,尝试将它们作为 POJO 类型进行处理。如果一个类型满足如下条件,Flink 就会将它们作为 POJO 数据类型:
- POJOs 类必须是一个公有类,Public 修饰且独立定义,不能是内部类;
- POJOs 类中必须包含一个 Public 修饰的无参构造器;
- POJOs 类中所有的字段必须是 Public 或者具有 Public 修饰的 getter 和 setter 方法;
- POJOs 类中的字段类型必须是 Flink 支持的。
例如,如下 Java 类就会被 Flink 识别为 POJO:
// (1) 必须是 Public 修饰且必须独立定义,不能是内部类
public class Person {
// (4) 字段类型必须是 Flink 支持的
private String name;
private int age;
// (2) 必须包含一个 Public 修饰的无参构造器
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
// (3) 所有的字段必须是 Public 或者具有 Public 修饰的 getter 和 setter 方法
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}定义好 POJOs Class 后,就可以在 Flink 环境中使用了,如下代码所示,使用 fromElements 接口构建 Person 类的数据集:
env.fromElements(new Person("Lucy", 18), new Person("Tom", 12))1.4 辅助类型
在 Flink 中也支持一些比较特殊的数据数据类型,例如 Scala 中的 List、Map、Either、Option、Try 数据类型,以及 Java 中 Either 数据类型,还有 Hadoop 的 Writable 数据类型。如下代码所示,创建 List 类型数据集:
DataStream<ArrayList<Integer>> listElements = env.fromElements(
Lists.newArrayList(1, 2), Lists.newArrayList(3, 4)
);这种数据类型使用场景不是特别广泛,主要原因是数据中的操作相对不像 POJOs 类那样方便和透明,用户无法根据字段位置或者名称获取字段信息,同时要借助 Types Hint 帮助 Flink 推断数据类型信息。
1.5 泛型类型
那些无法特别处理的类型会被当做泛型类型处理并交给 Kryo 序列化框架进行序列化。如果可能的话,尽可能的避免使用 Kryo。Kryo 作为一个通用的序列化框架,通常效率不高。
2. TypeInformation
那这么多的数据类型,在 Flink 内部又是如何表示的呢?在 Flink 中每一个具体的类型都对应了一个具体的 TypeInformation 实现类。例如,BasicTypeInformation 中的 IntegerTypeInformation 对应了 Integer 数据类型。数据类型的描述信息都是由 TypeInformation 定义,比较常用的 TypeInformation 有 BasicTypeInfo、TupleTypeInfo、CaseClassTypeInfo、PojoTypeInfo 类等,如下图所示:
TypeInformation 为系统提供生成序列化器和比较器提供必要的信息。当应用程序提交执行时,Flink 的类型系统会尝试为处理的每种数据类型自动推断 TypeInformation。类型提取器会分析函数的泛型类型以及返回类型,来获取相应的 TypeInformation 对象。但是,有时类型提取器会失灵,或者你可能想定义自己的类型并告诉 Flink 如何有效地处理它们。在这种情况下,你需要为特定数据类型生成 TypeInformation。
除了对类型地描述之外,TypeInformation 还提供了序列化的支撑。每一个 TypeInformation 都会为对应的具体数据类型提供一个专属的序列化器。TypeInformation 会提供一个 createSerialize() 方法,通过这个方法就可以得到该类型进行数据序列化操作与反序列化操作的序列化器 TypeSerializer:
public TypeSerializer<T> createSerializer(ExecutionConfig executionConfig) {
return this.serializer;
}对于大多数数据类型 Flink 可以自动生成对应的序列化器,能非常高效地对数据集进行序列化和反序列化,比如,BasicTypeInfo、WritableTypeIno 等,但针对 GenericTypeInfo 类型,Flink 会使用 Kyro 进行序列化和反序列化。其中,Tuple、Pojo 和 CaseClass 类型是复合类型,它们可能嵌套一个或者多个数据类型。在这种情况下,它们的序列化器同样是复合的。它们会将内嵌类型的序列化委托给对应类型的序列化器。
3. 显示指定 TypeInformation
大多数情况下,Flink 可以自动推断类型生成正确的 TypeInformation,并选择合适的序列化器和比较器。Flink 的类型提取器利用反射分析函数签名以及子类信息,生成函数的正确输出类型。但是有时无法提取必要的信息,例如定义函数时如果使用到了泛型,JVM 就会出现类型擦除的问题,使得 Flink 并不能很容易地获取到数据集中的数据类型信息。这时候可能会抛出如下类似的异常:
Exception in thread "main" org.apache.flink.api.common.functions.InvalidTypesException: The return type of function 'main(ReturnsExample.java:21)' could not be determined automatically, due to type erasure. You can give type information hints by using the returns(...) method on the result of the transformation call, or by letting your function implement the 'ResultTypeQueryable' interface.
at org.apache.flink.api.dag.Transformation.getOutputType(Transformation.java:479)
at org.apache.flink.streaming.api.datastream.DataStream.addSink(DataStream.java:1236)
at org.apache.flink.streaming.api.datastream.DataStream.print(DataStream.java:937)
...
Caused by: org.apache.flink.api.common.functions.InvalidTypesException: The generic type parameters of 'Tuple2' are missing. In many cases lambda methods don't provide enough information for automatic type extraction when Java generics are involved. An easy workaround is to use an (anonymous) class instead that implements the 'org.apache.flink.api.common.functions.MapFunction' interface. Otherwise the type has to be specified explicitly using type information.
...此外,在某些情况下,Flink 选择的 TypeInformation 可能无法生成最有效的序列化器和反序列化器。因此,你可能需要为你使用的数据类型显式地提供 TypeInformation。我们首先看一下如何创建 TypeInformation,然后再看一下如何为函数指定 TypeInformation。
3.1 创建 TypeInformation
3.1.1 of 方法
对于非泛型的类型,可以使用 TypeInformation 的 of(Class typeClass) 函数直接传入 Class 就可以创建 TypeInformation:
// 示例1 非泛型类型 直接传入 Class 对象
DataStream<WordCount> result1 = env.fromElements("a b a")
.flatMap((String value, Collector<WordCount> out) -> {
for(String word : value.split("\\s")) {
out.collect(new WordCount(word, 1));
}
})
.returns(TypeInformation.of(WordCount.class));
result1.print("R1");上述方法仅适用于非泛型类型。如果是泛型类型,可以借助 TypeHint 为泛型类型创建 TypeInformation:
// 示例2 泛型类型 需要借助 TypeHint
DataStream<Tuple2<String, Integer>> result2 = env.fromElements("a", "b", "a")
.map(value -> Tuple2.of(value, 1))
.returns(TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {}));
result2.print("R2");3.1.2 TypeHint
对于泛型类型,上面是通过 TypeInformation.of + TypeHint 来创建 TypeInformation,也可以单独使用 TypeHint 来创建 TypeInformation:
DataStream<Tuple2<String, Integer>> result2 = env.fromElements("a", "b", "a")
.map(value -> Tuple2.of(value, 1))
.returns(new TypeHint<Tuple2<String, Integer>>() {}.getTypeInfo());
result2.print("R2");TypeHint 的原理是在内部创建匿名子类,捕获泛型信息并会将其保留到运行时。运行时 TypeExtractor 可以获取保存的实际类型。
3.1.3 预定义的快捷方式
例如 BasicTypeInfo 类定义了一系列常用类型的快捷方式,对于 String、Boolean、Byte、Short、Integer、Long、Float、Double、Char 等基本类型的类型声明,可以直接使用:
当然,如果觉得 BasicTypeInfo 还是太长,Flink 还提供了完全等价的 Types 类(org.apache.flink.api.common.typeinfo.Types):
Types 为常见数据类型提供 TypeInformation,使用起来非常方便,如下示例:
// 示例1 Types.TUPLE
DataStream<Tuple2<String, Integer>> result1 = env.fromElements("a", "b", "a")
.map(value -> Tuple2.of(value, 1))
.returns(Types.TUPLE(Types.STRING, Types.INT));
result1.print("R1");
// 示例2 Types.POJO
DataStream<WordCount> result2 = env.fromElements("a b a")
.flatMap((String value, Collector<WordCount> out) -> {
for(String word : value.split("\\s")) {
out.collect(new WordCount(word, 1));
}
})
.returns(Types.POJO(WordCount.class));
result2.print("R2");3.2 显示提供类型信息
当 Flink 无法自动推断函数的生成类型是什么的时候,就需要我们显示提供类型信息提示。从上面示例中我们知道可以通过 returns 显示提供类型信息,除此之外还可以实现 ResultTypeQueryable 接口显示提供。
3.2.1 returns
第一种方法是使用 returns 为算子添加返回类型的类型信息提示。对于非泛型类型,可以直接传入 Class 即可;对于泛型类型需要借助 TypeHint 提供类型信息提示,如下所示:
// 示例1 非泛型类型 直接传入 Class
DataStream<WordCount> result1 = env.fromElements("a b a")
.flatMap((String value, Collector<WordCount> out) -> {
for(String word : value.split("\\s")) {
out.collect(new WordCount(word, 1));
}
})
.returns(WordCount.class);
result1.print("R1");
// 示例2 泛型类型 优先推荐借助 TypeHint
DataStream<Tuple2<String, Integer>> result2 = env.fromElements("a", "b", "a")
.map(value -> Tuple2.of(value, 1))
.returns(new TypeHint<Tuple2<String, Integer>>() {});
result2.print("R2");
// 示例3 TypeInformation.of + TypeHint
DataStream<Tuple2<String, Integer>> result3 = env.fromElements("a", "b", "a")
.map(value -> Tuple2.of(value, 1))
.returns(TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {}));
result3.print("R3");
// 示例4 Types 快捷方式
DataStream<Tuple2<String, Integer>> result4 = env.fromElements("a", "b", "a")
.map(value -> Tuple2.of(value, 1))
.returns(Types.TUPLE(Types.STRING, Types.INT));
result4.print("R4");3.2.2 ResultTypeQueryable
第二种方法是通过实现 ResultTypeQueryable 接口来扩展函数以显式提供返回类型的 TypeInformation。如下示例是一个显式提供返回类型的 MapFunction:
public static class ResultTypeMapFunction implements MapFunction<String, Stu>, ResultTypeQueryable {
@Override
public Stu map(String value) throws Exception {
String[] params = value.split(",");
String name = params[0];
int age = Integer.parseInt(params[1]);
return new Stu(name, age);
}
@Override
public TypeInformation getProducedType() {
return Types.POJO(Stu.class);
}
}4. 使用场景
4.1 Table 转 DataStream
Table 转 DataStream 的时候,Table 并清楚 DataStream 的数据结构,因此需要给当前转换出来的 DataStream 显性的指定数据类型:
// 转化为 Pojo 类型
DataStream<WordCount> stream1 = tEnv.toAppendStream(table, Types.POJO(WordCount.class));
// 转换为 Row 类型
DataStream<Row> stream2 = tEnv.toAppendStream(table, Types.ROW(Types.STRING, Types.LONG));4.2 Lambda 表达式与泛型
由于 Java 泛型会出现类型擦除问题,因此 Flink 通过 Java 反射机制尽可能重构类型信息,例如使用函数签名以及子类的信息等。对于函数的返回类型取决于输入类型的情况时,会包含一些简单的类型推断。但如果无法重构所有的泛型类型信息时,需要借助于类型提示来告诉系统函数中传入的参数类型信息和输出参数信息。如下所示使用 returns 语句指定生成的类型:
env.fromElements(1, 2, 3)
.map(i -> Tuple2.of(i, i*i))
// 如果不指定 returns 返回的 TypeInformation 会抛出异常
.returns(Types.TUPLE(Types.INT, Types.INT))
.print();参考:
版权声明
本文为[smartsi]所创,转载请带上原文链接,感谢
https://cloud.tencent.com/developer/article/1986110
边栏推荐
- When splicing HQL, the new field does not appear in the construction method
- 1N5408-ASEMI整流二极管1N5408
- do(Local scope)、初始化器、内存冲突、Swift指针、inout、unsafepointer、unsafeBitCast、successor、
- The art of automation
- QT Detailed explanation of pro file
- Arduino for esp8266串口功能简介
- OC to swift conditional compilation, marking, macro, log, version detection, expiration prompt
- go基础 反射
- LeetCode153-寻找旋转排序数组中的最小值-数组-二分查找
- LeetCode162-寻找峰值-二分-数组
猜你喜欢

I thought I could lie down and enter Huawei, but I was confused when I received JD / didi / iqiyi offers one after another
Provided by Chengdu control panel design_ It's detailed_ Introduction to the definition, compilation and quotation of single chip microcomputer program header file

Ali developed three sides, and the interviewer's set of combined punches made me confused on the spot

LeetCode 练习——396. 旋转函数
![[jz46 translate numbers into strings]](/img/e0/f32249d3d2e48110ed9ed9904367c6.png)
[jz46 translate numbers into strings]
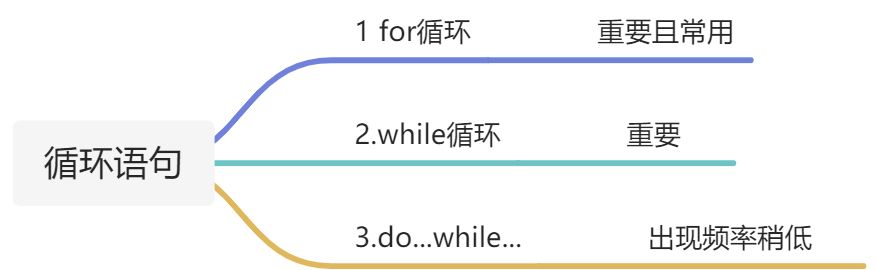
1 minute to understand the execution process and permanently master the for cycle (with for cycle cases)
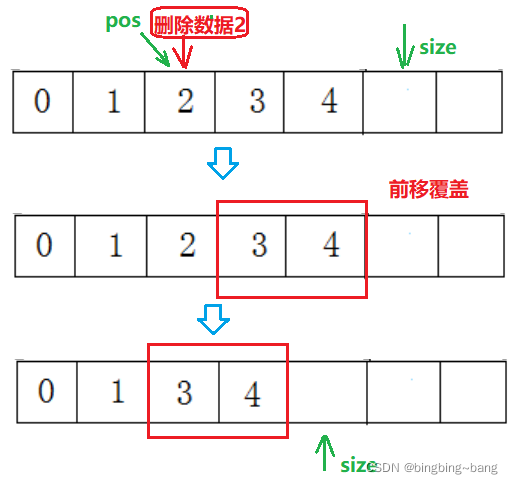
Bingbing learning notes: take you step by step to realize the sequence table
qt之.pro文件详解
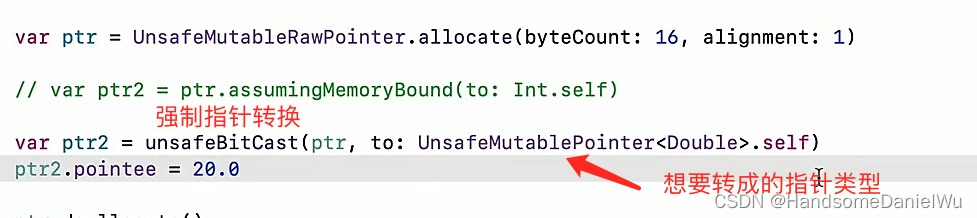
Do (local scope), initializer, memory conflict, swift pointer, inout, unsafepointer, unsafebitcast, success
《JVM系列》 第七章 -- 字节码执行引擎
随机推荐
Thread synchronization, life cycle
Advanced application of I / O multiplexing: Processing TCP and UDP services at the same time
I/O复用的高级应用之一:非阻塞 connect———使用 select 实现(也可以用 poll 实现)
qt之.pro文件详解
拼接hql时,新增字段没有出现在构造方法中
Select receives both normal data and out of band data
QT interface optimization: QT border removal and form rounding
想要成为架构师?夯实基础最重要
外包干了四年,废了...
LeetCode149-直线上最多的点数-数学-哈希表
MySQL报错packet out of order
UML项目实例——抖音的UML图描述
do(Local scope)、初始化器、内存冲突、Swift指针、inout、unsafepointer、unsafeBitCast、successor、
分享 20 个不容错过的 ES6 的技巧
1 minute to understand the execution process and permanently master the for cycle (with for cycle cases)
First acquaintance with STL
全连接层的作用是什么?
压缩映射定理
Outsourcing for four years, abandoned
Resolve the conflict between computed attribute and input blur event