当前位置:网站首页>Introduction and use of BeautifulSoup4
Introduction and use of BeautifulSoup4
2022-08-09 06:28:00 【hey hei hei hei】
BeautifulSoup4 的使用
python环境
Python 3.7.1
BeautifulSoup的简介
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.
它通过转换器实现文档导航,查找,修改文档的方式.
BeautifulSoup4的安装
安装
If you are using a newer versionubuntu,可以通过系统的软件包管理来安装:
$ apt-get install Python-bs4
If it cannot be installed using system package management,那么也可以通过 easy_install 或 pip 来安装.包的名字是 beautifulsoup4 ,这个包兼容Python2和Python3.
$ easy_install beautifulsoup4
$ pip install beautifulsoup4
若没有安装 easy_install 或 pip ,那你也可以 下载BS4的源码 解压后,进入到beautifulsoup目录下,然后通过setup.py来安装.(Windows下的beautifulsoupThe installation process is the same as this method)
$ Python setup.py install
出现的问题
If the code throws an exception at this point,可能是因为你在Python2版本中执行Python3version of the code or you are inPython3版本中执行Python2的代码.The best solution is to reinstallBeautifulSoup4.
Suppose you need to putBS4的PythonCode version fromPython2转换到Python3. 可以重新安装BS4:
$ Python3 setup.py install
或在bs4的目录中执行PythonCode version conversion script
$ 2to3-3.2 -w bs4
安装解析器
BeautifulSoup本身支持Python标准库中的HTML解析器
But if you want to makeBeautifulSoup使用html5lib解析器,It can be installed using the following method:
$ pip install html5lib
若想使BeautifulSoup使用lxml 解析器,It can be installed using the following method:
$ pip install lxml
BeautifulSoup4的使用
使用
from bs4 import BeautifulSoup #导入BeautifulSoup4库
soup = BeautifulSoup("<html>hello python</html>") #Get the document object
print(soup)
''' 结果: <html><body><p>hello python</p></body></html> '''
对象的种类
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: Tag , NavigableString , BeautifulSoup, Comment .
Tag
from bs4 import BeautifulSoup
soup = BeautifulSoup('<a href="www.baidu.com">baidu</a>')
tag = soup.a
print(tag)
print(type(tag))
''' result: <a href="www.baidu.com">baidu</a> <class 'bs4.element.Tag'> '''
print('tag.name:',tag.name)
tag.name = 'b'
print(tag)
''' result: tag.name: a <b href="www.baidu.com">baidu</b> '''
print(tag.attrs)
print(tag['href'])
tag['href'] = 'www.163.com'
print(tag['href'])
del tag
print(tag)
''' result: {'href': 'www.baidu.com'} www.baidu.com www.163.com Traceback (most recent call last): File "UseBeautifulSoup4.py", line 21, in <module> print(tag) NameError: name 'tag' is not defined '''
#It is also possible to operate on properties with multiple values
soup = BeautifulSoup('<p class="t1 t2"></p>')
print(soup.p['class'])
soup.p['class'] = ['t3','s1']
print(soup.p['class'])
''' result: ['t1', 't2'] ['t3', 's1'] '''
NavigableString
用来包装tag中的字符串
soup = BeautifulSoup('<p class="t1">testong</p>')
tag = soup.p
print(tag.string)
''' result: testong '''
#用来替换字符串
print(tag.string)
tag.string.replace_with(" one two three")
print(tag.string)
''' result: testong one two three '''
BeautifulSoup
BeautifulSoup对象表示的是一个文档的全部内容,It contains a value’[document]'的属性
soup = BeautifulSoup('<p class="t1">testong</p>')
print(soup.name)
''' result: [document] '''
Comment
CommentObjects are used to manipulate the comment section of the document
soup = BeautifulSoup('<p class="t1"><!-- when where who --></p>')
print(soup.p.string)
print('string type ',type(soup.p.string))
print(soup.p.prettify())
''' result: when where who string type <class 'bs4.element.Comment'> <p class="t1"> <!-- when where who --> </p> '''
遍历文档树
使用例子:
from bs4 import BeautifulSoup
soup = BeautifulSoup(''' <!DOCTYPE HTML> <html lang="zh-CN"> <head itemprop="video" itemscope itemtype="//schema.org/VideoObject"> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>王牌对王牌4Yao Chensha Yi reunited at Tongfu Inn</title> </head> <body> <div is="i71-header" page-name="" class="qy-header" id="block-A" v-bind:non-index='true'> <[email protected]<template slot="header" slot-scope="props">@--> <div id="nav_logo" class="qy-logo" style="display: none;" :style="{ display: 'block'}"> <i class="logo-dot"></i> <a class="logo-channel" title="综艺" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6"><h2>综艺</h2></a> </div> <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div> </div> </body></html> ''')
子节点
tagName
#通过tag.name可以获取标签
print(soup.head)
print()
print(soup.div)
''' result: <head itemprop="video" itemscope="" itemtype="//schema.org/VideoObject"> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <title>王牌对王牌4Yao Chensha Yi reunited at Tongfu Inn</title> </head> <div class="qy-header" id="block-A" is="i71-header" page-name="" v-bind:non-index="true"> <[email protected]<template slot="header" slot-scope="props">@--> <div :style="{ display: 'block'}" class="qy-logo" id="nav_logo" style="display: none;"> <i class="logo-dot"></i> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> </div> <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div> </div> '''
#使用find_all()method to find all tags
print(soup.find_all('div'))
''' result: [<div class="qy-header" id="block-A" is="i71-header" page-name="" v-bind:non-index="true"> <[email protected]<template slot="header" slot-scope="props">@--> <div :style="{ display: 'block'}" class="qy-logo" id="nav_logo" style="display: none;"> <i class="logo-dot"></i> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> </div> <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div> </div>, <div :style="{ display: 'block'}" class="qy-logo" id="nav_logo" style="display: none;"> <i class="logo-dot"></i> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> </div>, <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div>] '''
.contents和.children
.contents
tag的.contents属性会将tagThe child nodes of are output as a list
tag = soup.head
print(tag)
print()
print(tag.contents)
''' result: <head itemprop="video" itemscope="" itemtype="//schema.org/VideoObject"> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <title>王牌对王牌4Yao Chensha Yi reunited at Tongfu Inn</title> </head> ['\n', <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/>, '\n', <title>王牌对王牌4Yao Chensha Yi reunited with the same blessing 客栈</title>, '\n'] '''
.children
tag的.children属性可以对tag的子节点进行循环
for t in tag.children:
print(t)
''' result: <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <title>王牌对王牌4Yao Chensha Yi reunited at Tongfu Inn</title> '''
.descendants
tag的.children和.contents只包含tag的直接子节点,.descendantsA recursive loop can be performed directly on all descendant nodes
for t in tag.descendants:
print(t)
''' result: <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <title>王牌对王牌4Yao Chensha Yi reunited at Tongfu Inn</title> 王牌对王牌4Yao Chensha Yi reunited at Tongfu Inn '''
.string
如果tag只有一个NavgableString类型的子节点,可以使用.string得到子节点
tag = soup.head
print(tag.string)
title_tag = tag.title
print(title_tag.string)
''' result: None 王牌对王牌4Yao Chensha Yi reunited at Tongfu Inn '''
.strings
如果tagThere are multiple strings,可以使用.strings来循环获取
for str in soup.strings:
print(repr(str))
''' '\n' '\n' '\n' '王牌对王牌4Yao Chensha Yi reunited at Tongfu Inn' '\n' '\n' '\n' '\n' '\n' '\n' '\n' '综艺' '\n' '\n' '\n' '\n' '\n' '''
.stripped_strings
使用.stripped_strings可以去除多余空白内容
for str in soup.stripped_strings:
print(repr(str))
''' '王牌对王牌4Yao Chensha Yi reunited at Tongfu Inn' '综艺' '''
父节点
.parent
可以通过.parent属性来获取某个元素的父节点
tag = soup.title
print(tag.parent)
''' <head itemprop="video" itemscope="" itemtype="//schema.org/VideoObject"> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <title>王牌对王牌4Yao Chensha Yi reunited at Tongfu Inn</title> </head> '''
.parents
可以通过.parentsThe attribute recursively gets all the parent nodes of the element
tag = soup.title
for p in tag.parents:
if p is None:
print(p)
else:
print(p.name)
''' head html [document] '''
兄弟节点
.next_sibling和.previous_sibling
通过.next_sibling和.previous_siblingproperties to manipulate sibling nodes
#.previous_sibling的使用
tag = soup.a
previous_tag = tag.previous_sibling
print(previous_tag)
print(previous_tag.previous_sibling)
''' result: Here is an output,A space also counts as a node <i class="logo-dot"></i> '''
#.next_sibling的使用
tag = soup.i
next_tag = tag.next_sibling
print(next_tag)
print(next_tag.next_sibling)
''' result: <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> '''
.next_siblings和.previous_siblings
通过.next_siblings和.previous_siblingsProperties can iterate over all sibling nodes
#.previous_siblings的使用
tag = soup.a
for previous in tag.previous_siblings:
print(repr(previous))
''' result: '\n' <i class="logo-dot"></i> '\n' '''
#.next_siblings的使用
tag = soup.i
for next in tag.next_siblings:
print(repr(next))
''' result: '\n' <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> '\n' '''
前进和回退
.next_element 和 .previous_element
通过.next_element和.previous_elementThe next or previous object can be resolved
tag = soup.a
#previous_element
print(tag.next_element)
print(tag.next_element.next_element)
''' result: 该tagThe previous object is\n <i class="logo-dot"></i> '''
#.next_element
print(tag.next_element)
''' result: <h2>综艺</h2> '''
.next_elements 和 .previous_elements
通过.next_elements和.previous_elementsThe next or previous object can be resolved iteratively
#.previous_element
tag = soup.head
for e in tag.previous_elements:
print(e)
''' result: <html lang="zh-CN"> <head itemprop="video" itemscope="" itemtype="//schema.org/VideoObject"> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <title>王牌对王牌4Yao Chensha Yi reunited at Tongfu Inn</title> </head> <body> <div class="qy-header" id="block-A" is="i71-header" page-name="" v-bind:non-index="true"> <[email protected]<template slot="header" slot-scope="props">@--> <div :style="{ display: 'block'}" class="qy-logo" id="nav_logo" style="display: none;"> <i class="logo-dot"></i> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> </div> <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div> </div> </body></html> HTML '''
#next_element
tag = soup.h2
for e in tag.next_elements:
print(e)
''' result: 综艺 <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div> '''
搜索文档树
使用例子:
from bs4 import BeautifulSoup
soup = BeautifulSoup(''' <!DOCTYPE HTML> <html lang="zh-CN"> <head itemprop="video" itemscope itemtype="//schema.org/VideoObject"> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>王牌对王牌4Yao Chensha Yi reunited at Tongfu Inn</title> </head> <body> <div is="i71-header" page-name="" class="qy-header" id="block-A" v-bind:non-index='true'> <[email protected]<template slot="header" slot-scope="props">@--> <div id="nav_logo" class="qy-logo" style="display: none;" :style="{ display: 'block'}"> <i class="logo-dot"></i> <a class="logo-channel" title="综艺" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6"><h2>综艺</h2></a> </div> <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div> </div> </body></html> ''')
find_all()
find_all(name,attrs,recursive,string,**kwargs)
#name参数
#查找所有名字为name的tag
print(soup.find_all("a"))
''' result: [<a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a>] '''
#keyword参数
#将属性作为key值来查找
import re
print(soup.find_all(id='nav_logo'))
print(soup.find_all(href=re.compile("zongyi/")))
#有些tagNot available in search,但可以使用attrsparameters to define parameters
#print(soup.find_all(class="qy-logo")) The result here will be an error SyntaxError: invalid syntax
print(soup.find_all(attrs=["class","qy-logo"]))
''' result: [<div :style="{ display: 'block'}" class="qy-logo" id="nav_logo" style="display: none;"> <i class="logo-dot"></i> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> </div>] [<a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a>] [<div :style="{ display: 'block'}" class="qy-logo" id="nav_logo" style="display: none;"> <i class="logo-dot"></i> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> </div>] '''
#css参数
#class在Python是保留字,使用classAn error will be reported as a parameter,但BeautifulSoup4.1.1版本之后,可以通过class_参数搜索
print(soup.find_all('i',class_='logo-dot'))
''' result: [<i class="logo-dot"></i>] '''
#text参数
#通过textThe parameter can search the contents of the string in the document,textParameters can also be regular、列表等
print(soup.find_all(text="综艺"))
''' result: ['综艺'] '''
#limit参数
#使用limitproperty to limit the number of returned values
print(soup.find_all("div",limit=1))
''' result: [<div class="qy-header" id="block-A" is="i71-header" page-name="" v-bind:non-index="true"> <[email protected]<template slot="header" slot-scope="props">@--> <div :style="{ display: 'block'}" class="qy-logo" id="nav_logo" style="display: none;"> <i class="logo-dot"></i> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> </div> <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div> </div>] '''
#recursive参数
#find_all()The method defaults to searching for the current onetag的所有子孙节点,If you only want to search direct child nodes,将recursive参数设为False即可
print(soup.find_all("div",id='nav_logo',recursive=True))
print(soup.find_all("div",id='nav_logo',recursive=False))
''' result: [<div :style="{ display: 'block'}" class="qy-logo" id="nav_logo" style="display: none;"> <i class="logo-dot"></i> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> </div>] [] '''
find()
If you only want to get one result,可以使用find()方法
print(soup.find("title"))
''' result: <title>王牌对王牌4Yao Chensha Yi reunited at Tongfu Inn</title> '''
#soup.find("title") 等价于soup.find_all('title',limit=1)
过滤器
字符串
在find_all()The method passes a string as a parameter
print(soup.find_all('a'))
''' result: [<a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a>] '''
正则表达式
在find_all()The method passes a regular expression as a parameter
import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
''' result: body '''
列表
在find_all()The method passes in a list as a parameter
print(soup.find_all(["i","a"]))
''' result: [<i class="logo-dot"></i>, <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a>] '''
True
True可以匹配任何值
for tag in soup.find_all(True):
print(tag.name)
''' result: html head meta title body div div i a h2 div '''
方法
在find_all()A method is passed in as a parameter
def method1(tag):
return tag.has_attr('class') and not tag.has_attr('id')
print(soup.find_all(method1))
''' result: [<i class="logo-dot"></i>, <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a>, <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div>] '''
find_parents()和find_parent()
用来搜索当前节点的父辈节点
a_string = soup.find(text="综艺")
print(a_string)
print(a_string.find_parents("a"))
print(a_string.find_parent("a"))
''' result: 综艺 [<a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a>] <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> '''
find_next_siblings()和find_next_sibling()
Used to find sibling nodes,find_next_siblings()All sibling nodes can be found iteratively,find_next_sibling()Only the first sibling node that meets the conditions can be found
print(soup.i.find_next_siblings("a"))
print(soup.i.find_next_sibling("a"))
''' result: [<a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a>] <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> '''
find_all_next() 和 find_next()
Used to find nodes behind the current node
print(soup.i.find_all_next())
print(soup.i.find_next())
''' result: [<a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a>, <h2>综 艺</h2>, <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div>] <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> '''
find_all_previous() 和 find_previous()
Find the node preceding the current node
print(soup.title.find_all_previous())
print(soup.title.find_previous())
''' result: [<meta content="text/html; charset=utf-8" http-equiv="Content-Type"/>, <head itemprop="video" itemscope="" itemtype="//schema.org/VideoObject"> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <title>王牌对王牌4Yao Chensha Yi reunited at Tongfu Inn</title> </head>, <html lang="zh-CN"> <head itemprop="video" itemscope="" itemtype="//schema.org/VideoObject"> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <title>王牌对王牌4Yao Chensha Yi reunited at Tongfu Inn</title> </head> <body> <div class="qy-header" id="block-A" is="i71-header" page-name="" v-bind:non-index="true"> <[email protected]<template slot="header" slot-scope="props">@--> <div :style="{ display: 'block'}" class="qy-logo" id="nav_logo" style="display: none;"> <i class="logo-dot"></i> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> </div> <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div> </div> </body></html>] <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> '''
CSS选择器
使用 .select() The method can be searched by passing in a string parameter
#通过tag来查找
print(soup.select('a'))
''' result: [<a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a>] '''
#通过id来查找
print(soup.select('#nav_logo'))
''' result: [<div :style="{ display: 'block'}" class="qy-logo" id="nav_logo" style="display: none;"> <i class="logo-dot"></i> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> </div>] '''
#通过class来查找
print(soup.select('.qy-logo'))
''' result: [<div :style="{ display: 'block'}" class="qy-logo" id="nav_logo" style="display: none;"> <i class="logo-dot"></i> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> </div>] '''
#通过属性的值来查找
print(soup.select('div[style="display:none;"]'))
''' result: [<div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div>] '''
修改文档树
使用例子:
from bs4 import BeautifulSoup
soup = BeautifulSoup(''' <!DOCTYPE HTML> <html lang="zh-CN"> <head itemprop="video" itemscope itemtype="//schema.org/VideoObject"> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>王牌对王牌4Yao Chensha Yi reunited at Tongfu Inn</title> </head> <body> <div is="i71-header" page-name="" class="qy-header" id="block-A" v-bind:non-index='true'> <[email protected]<template slot="header" slot-scope="props">@--> <div id="nav_logo" class="qy-logo" style="display: none;" :style="{ display: 'block'}"> <i class="logo-dot"></i> <a class="logo-channel" title="综艺" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6"><h2>综艺</h2></a> </div> <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div> </div> </body></html> ''')
修改tag的名称和属性
tag = soup.i
print(tag)
tag.name = "a"
print(tag)
tag['class']='logo'
print(tag)
del tag['class']
print(tag)
''' result: <i class="logo-dot"></i> <a class="logo-dot"></a> <a class="logo"></a> <a></a> '''
修改 .string
tag = soup.h2
print(tag)
tag.string = "zongyi"
print(tag)
''' result: <h2>综艺</h2> <h2>zongyi</h2> '''
append()
Used to append content to a string
tag = soup.h2
print(tag)
tag.append(" hhhh ")
print(tag)
''' result: <h2>综艺</h2> <h2>综艺 hhhh </h2> '''
BeautifulSoup.new_string() 和 .new_tag()
#new_string()方法是BeautifulSoup对象的,不是tag的
s1 = BeautifulSoup("<b></b>")
tag = s1.b
print(tag)
tag.append(s1.new_string(" test "))
print(tag)
''' result: s1 = BeautifulSoup("<b></b>") <b></b> <b> test </b> '''
#添加注释
s1 = BeautifulSoup("<b></b>")
tag = s1.b
print(tag)
from bs4 import Comment
comment = s1.new_string("1 2 3",Comment)
tag.append(comment)
print(tag)
''' result: s1 = BeautifulSoup("<b></b>") <b></b> <b><!--1 2 3--></b> '''
#添加新的节点
s1 = BeautifulSoup("<b></b>")
tag = s1.b
print(tag)
new_tag = s1.new_tag("a",href="http://www.baidu.com")
tag.append(new_tag)
print(tag)
''' result: s1 = BeautifulSoup("<b></b>") <b></b> <b><a href="http://www.baidu.com"></a></b> '''
插入
# insert()
tag = soup.a
tag.insert(0," hello ")
print(tag)
tag.insert(2," world ")
print(tag)
''' result: <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"> hello <h2>综艺</h2></a> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"> hello <h2>综艺</h2> world </a> '''
# insert_before()
tag = soup.a
tag1 = soup.i
tag1.string = "hello"
tag.string.insert_before(tag1)
print(tag)
''' result: <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2><i class="logo-dot">hello</i>综艺</h2></a> '''
# insert_after()
tag = soup.a
tag1 = soup.i
tag1.string = "hello"
tag.string.insert_after(tag1)
print(tag)
''' result: <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺<i class="logo-dot">hello</i></h2></a> '''
clear()
Used to remove the content of the current node
tag = soup.a
print(tag)
tag.clear()
print(tag)
''' result: <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"></a> '''
extract()
Remove the current node from the document tree
tag = soup.a
print(tag)
h_tag = tag.h2.extract()
print(tag)
print(h_tag)
''' result: <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"></a> <h2>综艺</h2> '''
decompose()
Removes the current node from the document tree and destroys it completely
tag = soup.a
print(tag)
tag.h2.decompose()
print(tag)
''' result: <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"></a> '''
replace_with()
用新tagor text node to replace part of the document tree
tag = soup.a
print(tag)
new_tag = soup.new_tag("b")
new_tag.string = "test"
tag.h2.replace_with(new_tag)
print(tag)
''' result: <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><b>test</b></a> '''
wrap() 和 unwrap()
Wraps and unwraps the specified element
# wrap()
tag = BeautifulSoup("<p>I wish I was bold.</p>")
print(tag)
tag.string.wrap(tag.new_tag("b"))
print(tag)
''' result: tag = BeautifulSoup("<p>I wish I was bold.</p>") <html><body><p>I wish I was bold.</p></body></html> <html><body><p><b>I wish I was bold.</b></p></body></html> '''
#unwrap()
tag = BeautifulSoup("<p>I wish I was bold.</p>")
print(tag)
tag.string.wrap(tag.new_tag("b"))
print(tag)
tag.b.unwrap()
print(tag)
''' result: tag = BeautifulSoup("<p>I wish I was bold.</p>") <html><body><p>I wish I was bold.</p></body></html> <html><body><p><b>I wish I was bold.</b></p></body></html> <html><body><p>I wish I was bold.</p></body></html> '''
最后
以上是我通过BeautifulSoup4文档学习BeautifulSoup4的过程,There may not be enough detail in some places,But still hope it helps other beginners,若想了解更多,请参考Beautiful Soup Documentation
边栏推荐
猜你喜欢
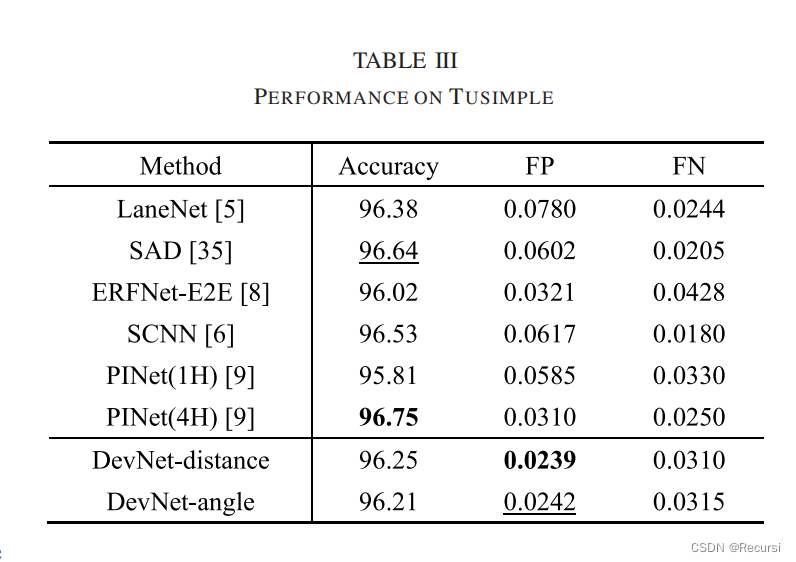
DevNet: Deviation Aware Networkfor Lane Detection

Deep Learning - Principles of Neural Networks 2

JMeter test - JMeter 】 【 upload multiple images/batch CSV file upload pictures interface parametric method

带头双向循环链表的增删查改(C语言实现)

缓存技术使用
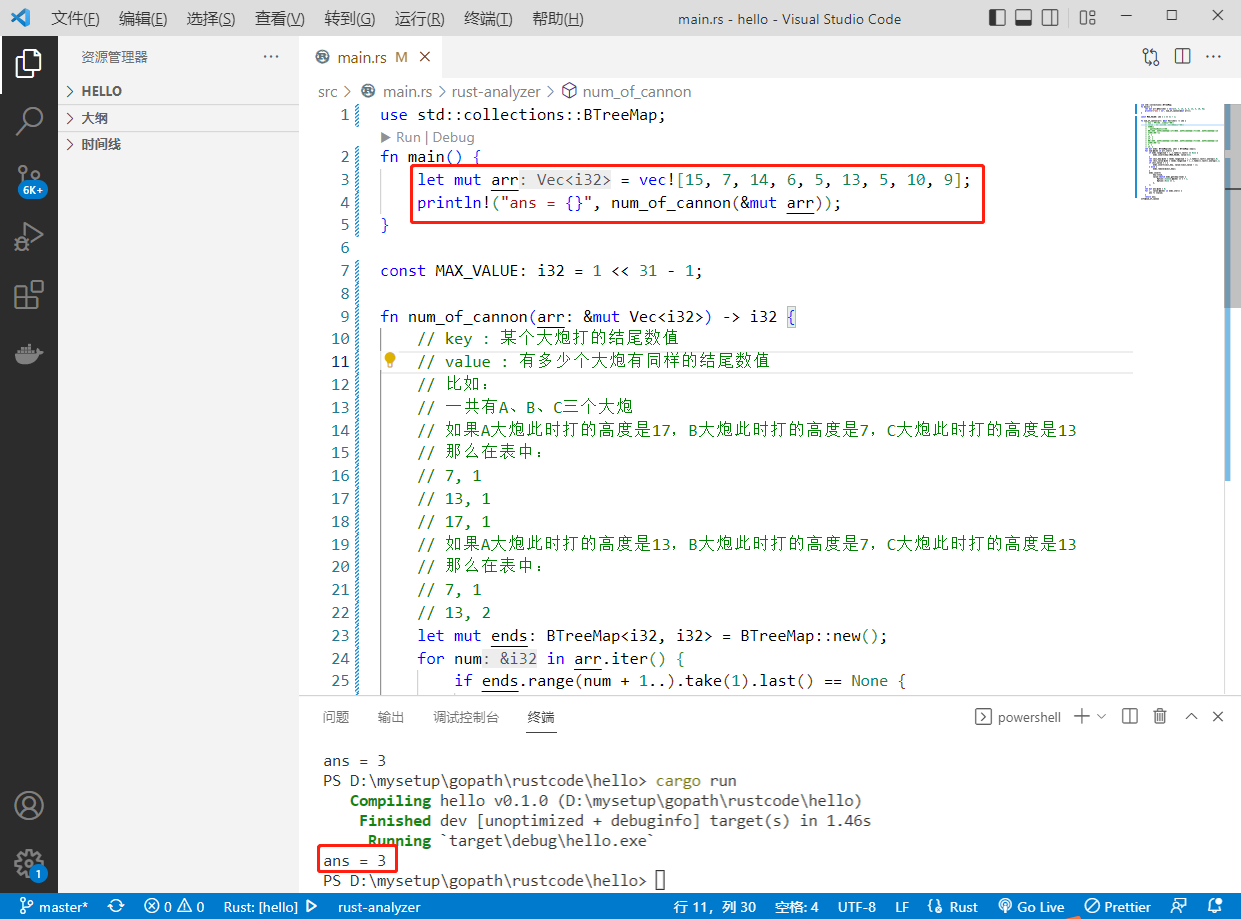
2022-08-08: Given an array arr, it represents the height of the missiles that will appear in order from morning to night.When the cannon shoots missiles, once the cannon is set to shoot at a certain h

mongo+ycsb性能测试及线程数分析
Adds, deletes, searches, and changes the leading doubly circular linked list (implemented in C language)

ZIP压缩包文件删除密码的方法
深度学习-神经网络原理2
随机推荐
Unity 五子棋游戏设计和简单AI(2)
缓存技术使用
代码目录结构
Cysteine/Galactose/Perylenediimide Functionalized Fe3O4 Fe3O4 Nanomaterials | Scientific Research Reagents
什么是excel文件保护
Initials-Letter Query Tool-Word Abbreviation Query Online Tool
Getting started with kubernetes apparmor
Fe3O4/SiO2 Composite Magnetic Nanoparticles Aminated on SiO2-NH2/Fe3O4 Surface (Qiyue Reagent)
[R language] Extract all files under a folder to a specific folder
中英文说明书丨CalBioreagents 山羊抗人白蛋白,IgG组分
APP商品详情源数据接口(淘宝/京东/拼多多/苏宁/抖音等平台详情数据分析接口)代码对接教程
After the VB.net program is closed, the background is still connected to SQL
Polyamide-amine (PAMAM) dendrimer-bismuth sulfide composite nanoparticles | bismuth sulfide modified Gd‑DTPA‑OA ligand | for scientific research
BeautifulSoup4的介绍与使用
VB.net程序关闭后后台还在与SQL连接
程序性能分析 —— 复杂度分析
常用Oracle命令
idea中PlantUML插件使用
Unity五子棋游戏设计 和简单AI实现(1)
Teach you how to make the Tanabata meteor shower in C language - elegant and timeless (detailed tutorial)