当前位置:网站首页>【Robustness of VQA-1】——2019-EMNLP-Don’t Take the Easy Way Out
【Robustness of VQA-1】——2019-EMNLP-Don’t Take the Easy Way Out
2022-08-09 11:15:00 【临淮郡人】
2019-EMNLP-Don’t Take the Easy Way Out: Ensemble Based Methods for Avoiding Known Dataset Biases
1.文章提出背景
即使是一些SOTA模型,在一些问题中也很容易仅仅捕捉到表面的数据关联(superficial patterns),而因此在OOD的测试集 (out-of-domain)或者有对抗样本的测试集上 (adversarial settings)的泛化能力不强。
例如:
在文本蕴含问题中,模型常常学到个别key words就暗示了蕴含现象,而并没有考虑文本内容(irrespective of context);
在VQA问题中,模型学会用<q,a>pair中的固有模式回答问题(learn to predict prototypical answers,),而并没有去真正关注图文信息。
2.解决的问题
这样的bias造成的问题,就是模型的不鲁棒。因此本文提出一种基于模型集成的方法,去增强模型的鲁棒性,来应对domain shift。
虽然种种数据集中确实都有所谓的bias现象存在,但是我们可以让模型变得鲁棒,避免在有bias的数据集上,学到bias,继而我们一方面继续可以在数据集上研究,同时也可以增强我们对于bias是什么的研究。(我个人也是这样觉得的)
(While reducing bias is important, developing ways to prevent models from using known biases will allow us to continue to leverage existing datasets, and update our methods as our understanding of what biases we want to avoid evolve)
- 所谓的捕捉到superficial patterns,也就是所谓的bias,造成模型仅仅依赖于bias的信息在in-domain问题上表现不错,这就造成,模型是脆弱的(brittle and easy to fool)
- OOD和adversarial settings都是domain shift的一种表现形式吧?能够正确应对domain shift,体现了模型的鲁棒性。
- 而bias的问题,造成模型的不鲁棒;
3.主要的工作、模型
本文整体包括一个language-only的模型;首先训练一个学到bias的不鲁棒模型,再学习一个鲁棒模型作为集成的一部分,in order to encourage it to focus on other patterns in the data that are more likely to generalize。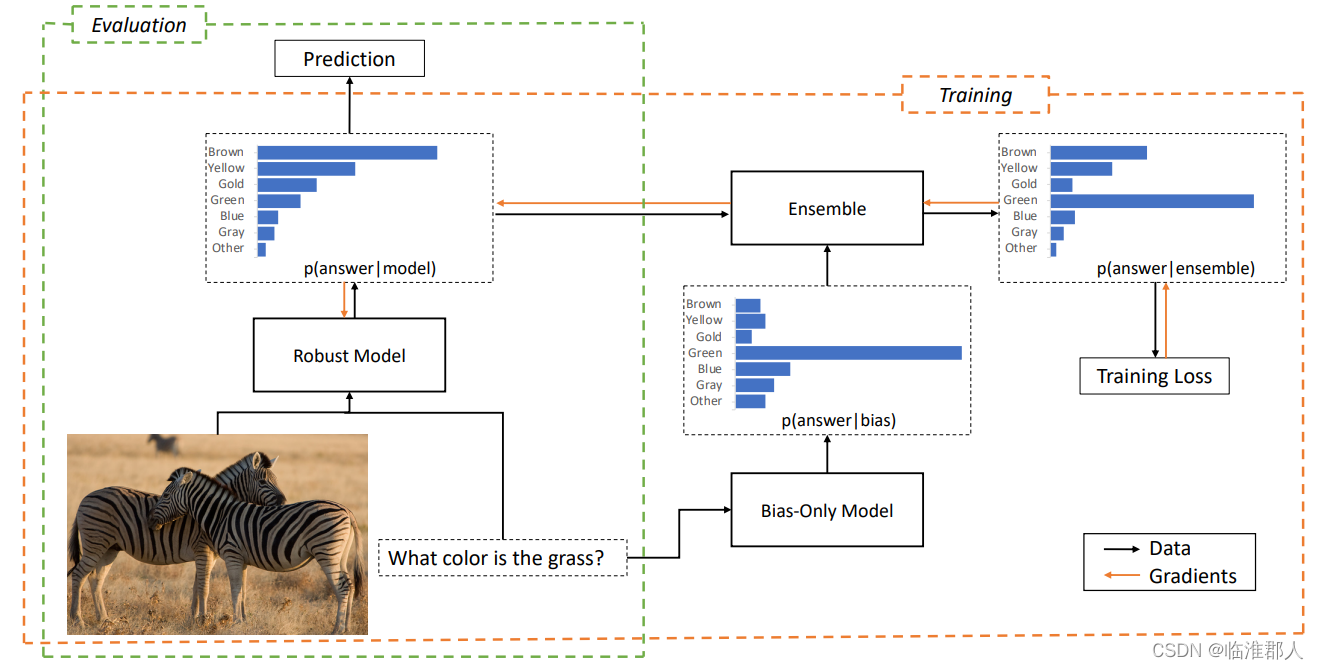
In this paper, we build on these works by showing that, once a dataset bias has been identified,we can improve the out-of-domain performance of
models by preventing them from making use of that bias. 意思是,我们发现了bias就可以设计方法去对抗、避免它。当然问题也在这,得人为事先知到这个问题。
To do this, we use the fact that these biases can often be explicitly modelled with simple,constrained baseline methods to factor them out of(将他们分解出)a final model through ensemble-based training.(就像因式分解一般,我们尝试把他们从问题之中解耦出来)
总体来说模型有两步:
- 第一步:只根据bias学习一个模型,专门捕捉bias信息,这里的bias是使得数据在train-test集合上,出现重大差异的输入信息。
- 第二部,通过建模,loss构造,利用这个有偏见的模型,训练一个“无偏”的模型。注意,在测试时,仅仅使用无偏见的模型,这里的两个模型使用
product-of-expert style学习。
其实是很有道理的,首先我们需要知到“什么因素”造成了偏置。我们在stage1学习一个,仅仅由偏见得到的模型,然后在stage2学习一个真实数据下学习的模型。我们在学习真实数据的情况下,需要两个模型一起学,但是在测试的时候,我们应该拿掉stage1的模型:
- 但是问题就在于,这种bias是否真的能被学到,并且模型的结构和训练方式的合理性。
3.1 模型建立
这里由浅入深,我们将问题形式化:
- 问题:我们已知样本 x x x,其中由bias的因素 x − b x^{-b} x−b和除了bias的因素 x b x^b xb共同组成 x x x,我们对于分类任务,是要预测 p ( c ∣ x ) p(c|x) p(c∣x)。
- 假设:这里,我们做一个条件比较强的假设,在给定 c c c的时候, x − b x^{-b} x−b和 x b x^b xb是条件独立的,也就是说 p ( x b , x − b ∣ c ) = p ( x b ∣ c ) p ( x − b ∣ c ) p(x^b,x^{-b}|c)=p(x^{b}|c)p(x^{-b}|c) p(xb,x−b∣c)=p(xb∣c)p(x−b∣c)或者说 p ( x b ∣ c , x − b ) = p ( x b ∣ c ) p(x^b|c,x^{-b})=p(x^b|c) p(xb∣c,x−b)=p(xb∣c)
那么我们可以对概率进行转化,如下建模:
P ( c ∣ x ) = p ( c ∣ x − b , x b ) ∝ p ( c ∣ x − b ) p ( x b ∣ c , x b ) = p ( c ∣ x − b ) p ( x b ∣ c ) = p ( c ∣ x − b ) p ( c ∣ x b ) p ( x b ) p ( c ) ∝ p ( c ∣ x − b ) p ( c ∣ x b ) p ( c ) \begin{aligned} P(c|x) &= p(c|x^{-b},x^{b})\\ & \propto p(c|x^{-b})p(x^b|c,x^{_b}) \\ & = p(c|x^{-b})p(x^b|c) \\ & = p(c|x^{-b}) {p(c|x^b)p(x^b) \over p(c)}\\ & \propto p(c|x^{-b}) {p(c|x^b) \over p(c)} \end{aligned} P(c∣x)=p(c∣x−b,xb)∝p(c∣x−b)p(xb∣c,xb)=p(c∣x−b)p(xb∣c)=p(c∣x−b)p(c)p(c∣xb)p(xb)∝p(c∣x−b)p(c)p(c∣xb)
其中,当我们知到样本的时候,那么 p ( x b ) p(x^b) p(xb)和 p ( x − b ) p(x^{-b}) p(x−b)以及 p ( x b ) p ( x − b ) p(x^b)p(x^{-b}) p(xb)p(x−b)都是常量了,因此第一个正比于可以通过全概率公式得到,如下:
p ( x b , x − b , c ) = p ( c ∣ x − b , x b ) p ( x − b , x b ) = p ( c ∣ x − b ) p ( x b ∣ c , x b ) p ( x − b ) \begin{aligned} p(x^b,x^{-b},c) & = p(c|x^{-b},x^{b}) p(x^{-b},x^{b}) \\ & = p(c|x^{-b})p(x^b|c,x^{_b})p(x^{-b}) \end{aligned} p(xb,x−b,c)=p(c∣x−b,xb)p(x−b,xb)=p(c∣x−b)p(xb∣c,xb)p(x−b)
可见
p ( c ∣ x − b , x b ) = p ( c ∣ x − b ) p ( x b ∣ c , x b ) p ( x − b ) p ( x − b , x b ) \begin{aligned} p(c|x^{-b},x^{b}) &=p(c|x^{-b})p(x^b|c,x^{_b}) {p(x^{-b}) \over p(x^{-b},x^{b})} \end{aligned} p(c∣x−b,xb)=p(c∣x−b)p(xb∣c,xb)p(x−b,xb)p(x−b)
其它也是由独立性,和贝叶斯可以得到的。
值得注意的是,我们事实上希望模型能对 p ( c ∣ x − b ) p(c|x^{-b}) p(c∣x−b)建模,因此我们对有偏置模型的建模,实际上是考虑 p ( c ∣ x b ) p ( c ) p(c|x^{b}) \over p(c) p(c)p(c∣xb),个人觉得这算是把类别的先验也给学了吧。
如果我们认为,使用有偏置的模型建模 p ( c ∣ x − b ) p(c|x^{-b}) p(c∣x−b),用无偏置的模型建模 p ( c ∣ x b ) p(c|x^{b}) p(c∣xb),那么我们的目标就可以看作两个概率之乘积。对应的概率,可以写作:
p i ^ = s o f t m a x ( l o g ( p i ) + l o g ( q i ) ) \begin{aligned} \widehat{p_i}= softmax(log(p_i)+log(q_i)) \end{aligned} pi=softmax(log(pi)+log(qi))
这里的意思是, p i = ( p 1 , p 2 , . . . , p n ) p_i=(p_1,p_2,...,p_n) pi=(p1,p2,...,pn),然后 l o g ( p i ) + l o g ( q i ) log(p_i)+log(q_i) log(pi)+log(qi)得到 l o g ( p 1 q 1 ) , l o g ( p 2 q 2 ) , . . . , l o g ( p n q n ) log(p_1q_1),log(p_2q_2),...,log(p_nq_n) log(p1q1),log(p2q2),...,log(pnqn),再做softmax,分子和 p i q i p_iq_i piqi相关,分母就是两个向量的内积,再元素求和。
3.2 反思假设
由于这里的“条件独立假设”实际上可能比较强,因此我们引入一个因子 g ( x i ) g(x_i) g(xi),体现二者的相关性。
p i ^ = s o f t m a x ( l o g ( p i ) + g ( x i ) l o g ( q i ) ) \begin{aligned} \widehat{p_i}= softmax(log(p_i)+g(x_i)log(q_i)) \end{aligned} pi=softmax(log(pi)+g(xi)log(qi))
具体的,作者采用的 g ( ) g() g()函数是:
s o f t p l u s ( w ∗ h i ) , 其 中 s o f t p l u s ( x ) = l o g ( 1 + e x ) softplus(w*h_i),其中softplus(x)=log(1+e^x) softplus(w∗hi),其中softplus(x)=log(1+ex)
其中, h i h_i hi是 x i x_i xi的最后一层隐藏层的输出, w w w是参数。
但是根据作者所说,模型有时会会学出 g ( x i ) = 0 g(x_i)=0 g(xi)=0,这一点比较匪夷所思,因为这意味着 w ∗ h i = − i n f w*h_i=-inf w∗hi=−inf,或者说很小的数。
至于为什么用softplu,作者说是prevent the model reversing the bias by multiplying it by a negative weight.稍微有点没看懂哦? w w w is trained with the rest of the model parameters. This reduces to bias product when g(xi) = 1。
3.3 正则化方案:
我们需要避免上面的 g ( x i ) = 0 g(x_i)=0 g(xi)=0,因为不可能说真的是完全没关系的。对原本的loss加一定限制,这里采用信息熵的思路,要求 g ( x i ) l o g ( q i ) ) g(x_i)log(q_i)) g(xi)log(qi))具备较好的信息量,于是加上一项正则化项:
R = w ∗ H ( s o f t m a x ( g ( x i ) l o g ( b i ) ) , 其 中 H ( Z ) = E n t r o p y ( Z ) R=w * H(softmax(g(x_i)log(b_i)),其中H(Z)=Entropy(Z) R=w∗H(softmax(g(xi)log(bi)),其中H(Z)=Entropy(Z)
其中还带有一个可学习参数w。
- 我的想法:对熵的惩罚,其实是要求该项不要使平均分布,但是这个好像并不是说避免 g ( x i ) = 0 g(x_i)=0 g(xi)=0,这个就有点点奇怪了。
4.主要的创新
引入人对先验理解的知识,在明确知到什么问题会造成先验误差,进而去通过概率建模去消解他,思路简单,但行之有效。同时注意到了模型中概率独立性的缺陷和一些训练上的问题,工作比较完整。可以说,是因果推断的简单版本。
同时,不仅仅在VQA任务上做了实验,还在其它任务、数据集上做了坚实的验证工作。虽然我不是很能看懂。
5.实验
在多个任务上都进行了实验,概要如下: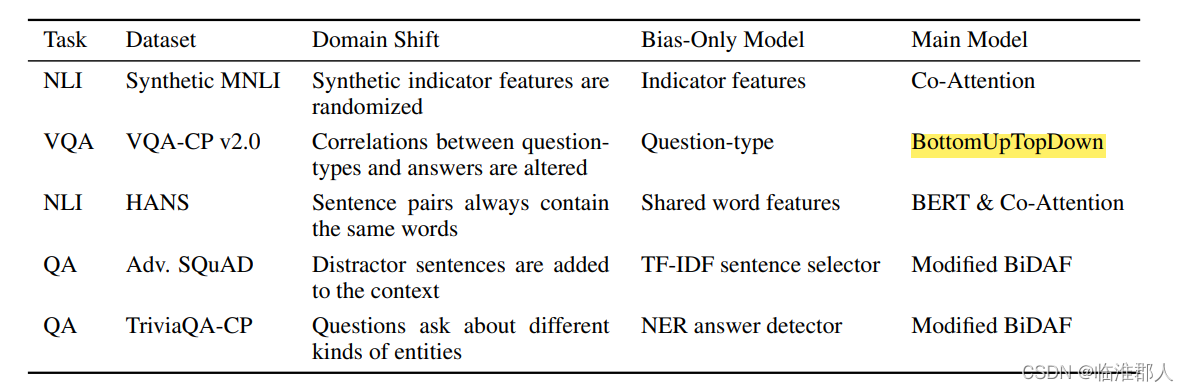
其中有的数据集似乎有所增改:
- textual entailment:MNLI(在其上增加了一些其它信息)
- QA:construct a new QA challenge dataset, TriviaQA-CP,类似于VQA-CP的构造方法;
- 本文还提出一个reweighted baseline,就是将
main model训练时的权重进行简单修改,而不加上述技巧: x i x_i xi的样本,他的权重为 1 − b i y i 1-b_{iyi} 1−biyi,其中 b i y i b_{iyi} biyi是bias-only model对第 i i i个样本的正确标签 y i y_i yi分类的的预测,这使得main模型更关注bias-only预测错误的样本。
在VQA的实验中,bias-only model仅仅输入“问题”种类+图片进行训练。
最终结果总体评价是:
our method works well on two adversarial datasets, and two changing-prior datasets。
Experiments on five datasets with out-of-domain test sets show significantly improved robustness in all settings, including a 12 point gain on a changing priors visual question answering dataset and a 9 point gain on an adversarial question answering test set.
6.评价
思想很重要,其实就是基于“解耦”的思想,利用概率论进行简单的转化建模;并采用最为直接粗暴的特征提取方法,针对问题进行解决,也比较用心地选择对相关性、信息熵的正则化项目与考量,使得模型能够正常训练。
缺点,需要人为的知到测试集信息,知到什么因素导致了模型的OOD性能不佳
实际上就是说,应该把问题解耦,分开来讨论。或者说把问题看作是“矛盾”部分的合体,或者说问题是“特殊性与一般性”的合一,既有一般性的“先验部分”,更是有特殊性的“非先验部分”
个人意见:有的就是好的bias,因为比如我问你what color,你不需要理解,因为答案就是color之中的结果。但是有的不是好的bias,因为模型也就仅仅是捕捉到了所谓的表面联系。应该仔细地探究,扬长避短。
其实我觉得,现在的统计模型,基本只能解决“先验部分”,或者大力出奇迹,直接把见过的数据都“隐式的记住了”。即便是这样,对few-shot 和zero-shot能力还是有所欠缺。
此外我认为,要使得模型具备更强的OOD泛化能力,可以考虑一下,
合理利用语言先验,就是说,能够学到what color是在问“颜色”,然后我们不要用hard的分类去看,我们不妨直接输出向量,看看软标签,比如借助于预训练的word-to-vector,将标签变为软的。或者说把标签空间变为一个“层次聚类”,充分体现语义信息,然后按照层次信息重新进行编码,使得模型“多次预测”。然后对于OOD问题应该有更好地解决。可以考察一下,模型有没有这种能力?针对于上一点,是不是可以,让模型更细化的认识到,有用的先验,和没有用的先验知识。因为我们学习就是要学会一些先验,既有bottom-up,也有top-down的推理,并不是一味的摈弃所谓的先验。这个我觉得可以继续研究一下,虽然其中第二部有引入一个 g ( x i ) g(x_i) g(xi)因子,似乎体现了这个,但是其实是来解释它的
条件概率独立问题,并不是利用先验问题。而且是否真正学到了所谓的相关性,还需要好好探讨一下。进一步的,本文对于先验的定义,我觉得还是过于粗放,可以对文字信息进一步探讨。不过好像也差不多了,意义不大。
其它一些遗留问题:
- 如本文的4.2所说,这里的参数调整还是很需要水平的,因为不知道test-集合数据分布,因此在train 集合上很可能会过拟合之类的。原文中的意思是,在test集合上做模型的选择了,这是个
caveat(警告) - 另外对于什么是先验,能否自动发现先验还是个值得研究的点,不知道作者有没有继续深入下去了。
7.其它知识:
7.1 related works
首先是对数据集的建设,有了各种建议。
其次是对模型本身的设计上,有各种见解:
然后是特意设置的任务,也有相关内容。
最近在VQA方面,主要关注到的biases来自于,忽视多模态输入中的某些部分(e.g., guessing the answer to a question before seeing the evidence)。
其它一些解决方案:
- generative objectives to force models to understand all the input
- carefully designed model architecture (Agrawal et al., 2018; Zhang et al., 2016),
- adversarial removal of class-indicative features
from model’s internal representations
在任务的设计上:
A related task is preventing models from using particular problematic dataset features, which is often studied from the perspective of fairnes。
Evaluating models on out-of-domain examples built by applying minor perturbations to existing examples has also been the subject of recent study.
边栏推荐
猜你喜欢
x86 Exception Handling and Interrupt Mechanism (1) Overview of the source and handling of interrupts
bat文件(批处理文件)运行时一闪而过解决方法

wait系统调用

x86 Exception Handling and Interrupt Mechanism (3) Interrupt Handling Process
程序员的专属浪漫——用3D Engine 5分钟实现烟花绽放效果
无刷无霍尔BLCD电机控制
美的数字化平台 iBUILDING 背后的技术选型
基于STM32F103移植FreeRTOS

matlab图像分割,从基因芯片荧光图像中提取阴性点(弱)和阳性点(强)

去除蜂窝状的噪声(matlab实现)
随机推荐
C语言中信号函数(signal)的使用
x86异常处理与中断机制(2)中断向量表
STM32使用静态队列保存数据
【精华文】C语言结构体特殊情况分析:结构体指针 / 基本数据类型指针,指向其他结构体
使用gdb调试多进程程序、同时调试父进程和子进程
redis内存的淘汰机制
Cesium加载三维模型数据
电磁场与电磁波-场论基础
激光条纹中心提取——灰度重心法
PAT1008
通关SQLilab靶场——Less-1思路步骤
Julia常见符号意思
People | How did I grow quickly from programmer to architect?
PAT1010
PAT1006
VS Code有趣插件
Redis的常用数据结构和底层实现方式
【C language】typedef的使用:结构体、基本数据类型、数组
PTA 找出不是两个数组共有的元素
学长告诉我,大厂MySQL都是通过SSH连接的