当前位置:网站首页>BeautifulSoup4的介绍与使用
BeautifulSoup4的介绍与使用
2022-08-09 06:21:00 【嘿嘿潶黑黑】
BeautifulSoup4 的使用
python环境
Python 3.7.1
BeautifulSoup的简介
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库。
它通过转换器实现文档导航,查找,修改文档的方式。
BeautifulSoup4的安装
安装
若使用的是新版的ubuntu,可以通过系统的软件包管理来安装:
$ apt-get install Python-bs4
若无法使用系统包管理安装,那么也可以通过 easy_install 或 pip 来安装.包的名字是 beautifulsoup4 ,这个包兼容Python2和Python3.
$ easy_install beautifulsoup4
$ pip install beautifulsoup4
若没有安装 easy_install 或 pip ,那你也可以 下载BS4的源码 解压后,进入到beautifulsoup目录下,然后通过setup.py来安装.(Windows下的beautifulsoup安装过程和此方法一样)
$ Python setup.py install
出现的问题
如果此时代码抛出了异常,可能是因为你在Python2版本中执行Python3版本的代码或你在Python3版本中执行Python2的代码.最好的解决方法是重新安装BeautifulSoup4.
假设需要将把BS4的Python代码版本从Python2转换到Python3. 可以重新安装BS4:
$ Python3 setup.py install
或在bs4的目录中执行Python代码版本转换脚本
$ 2to3-3.2 -w bs4
安装解析器
BeautifulSoup本身支持Python标准库中的HTML解析器
但若想使BeautifulSoup使用html5lib解析器,可以使用下面方法安装:
$ pip install html5lib
若想使BeautifulSoup使用lxml 解析器,可以使用下面方法安装:
$ pip install lxml
BeautifulSoup4的使用
使用
from bs4 import BeautifulSoup #导入BeautifulSoup4库
soup = BeautifulSoup("<html>hello python</html>") #得到文档的对象
print(soup)
''' 结果: <html><body><p>hello python</p></body></html> '''
对象的种类
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: Tag , NavigableString , BeautifulSoup, Comment .
Tag
from bs4 import BeautifulSoup
soup = BeautifulSoup('<a href="www.baidu.com">baidu</a>')
tag = soup.a
print(tag)
print(type(tag))
''' result: <a href="www.baidu.com">baidu</a> <class 'bs4.element.Tag'> '''
print('tag.name:',tag.name)
tag.name = 'b'
print(tag)
''' result: tag.name: a <b href="www.baidu.com">baidu</b> '''
print(tag.attrs)
print(tag['href'])
tag['href'] = 'www.163.com'
print(tag['href'])
del tag
print(tag)
''' result: {'href': 'www.baidu.com'} www.baidu.com www.163.com Traceback (most recent call last): File "UseBeautifulSoup4.py", line 21, in <module> print(tag) NameError: name 'tag' is not defined '''
#若含有多个值的属性也可以进行操作
soup = BeautifulSoup('<p class="t1 t2"></p>')
print(soup.p['class'])
soup.p['class'] = ['t3','s1']
print(soup.p['class'])
''' result: ['t1', 't2'] ['t3', 's1'] '''
NavigableString
用来包装tag中的字符串
soup = BeautifulSoup('<p class="t1">testong</p>')
tag = soup.p
print(tag.string)
''' result: testong '''
#用来替换字符串
print(tag.string)
tag.string.replace_with(" one two three")
print(tag.string)
''' result: testong one two three '''
BeautifulSoup
BeautifulSoup对象表示的是一个文档的全部内容,它包含了一个值为’[document]'的属性
soup = BeautifulSoup('<p class="t1">testong</p>')
print(soup.name)
''' result: [document] '''
Comment
Comment对象用于操作文档的注释部分
soup = BeautifulSoup('<p class="t1"><!-- when where who --></p>')
print(soup.p.string)
print('string type ',type(soup.p.string))
print(soup.p.prettify())
''' result: when where who string type <class 'bs4.element.Comment'> <p class="t1"> <!-- when where who --> </p> '''
遍历文档树
使用例子:
from bs4 import BeautifulSoup
soup = BeautifulSoup(''' <!DOCTYPE HTML> <html lang="zh-CN"> <head itemprop="video" itemscope itemtype="//schema.org/VideoObject"> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>王牌对王牌4之姚晨沙溢再聚同福客栈</title> </head> <body> <div is="i71-header" page-name="" class="qy-header" id="block-A" v-bind:non-index='true'> <[email protected]<template slot="header" slot-scope="props">@--> <div id="nav_logo" class="qy-logo" style="display: none;" :style="{ display: 'block'}"> <i class="logo-dot"></i> <a class="logo-channel" title="综艺" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6"><h2>综艺</h2></a> </div> <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div> </div> </body></html> ''')
子节点
tagName
#通过tag.name可以获取标签
print(soup.head)
print()
print(soup.div)
''' result: <head itemprop="video" itemscope="" itemtype="//schema.org/VideoObject"> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <title>王牌对王牌4之姚晨沙溢再聚同福客栈</title> </head> <div class="qy-header" id="block-A" is="i71-header" page-name="" v-bind:non-index="true"> <[email protected]<template slot="header" slot-scope="props">@--> <div :style="{ display: 'block'}" class="qy-logo" id="nav_logo" style="display: none;"> <i class="logo-dot"></i> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> </div> <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div> </div> '''
#使用find_all()方法查找所有的标签
print(soup.find_all('div'))
''' result: [<div class="qy-header" id="block-A" is="i71-header" page-name="" v-bind:non-index="true"> <[email protected]<template slot="header" slot-scope="props">@--> <div :style="{ display: 'block'}" class="qy-logo" id="nav_logo" style="display: none;"> <i class="logo-dot"></i> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> </div> <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div> </div>, <div :style="{ display: 'block'}" class="qy-logo" id="nav_logo" style="display: none;"> <i class="logo-dot"></i> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> </div>, <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div>] '''
.contents和.children
.contents
tag的.contents属性会将tag的子节点以列表形式输出
tag = soup.head
print(tag)
print()
print(tag.contents)
''' result: <head itemprop="video" itemscope="" itemtype="//schema.org/VideoObject"> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <title>王牌对王牌4之姚晨沙溢再聚同福客栈</title> </head> ['\n', <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/>, '\n', <title>王牌对王牌4之姚晨沙溢再聚同福 客栈</title>, '\n'] '''
.children
tag的.children属性可以对tag的子节点进行循环
for t in tag.children:
print(t)
''' result: <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <title>王牌对王牌4之姚晨沙溢再聚同福客栈</title> '''
.descendants
tag的.children和.contents只包含tag的直接子节点,.descendants可以直接对所有的子孙节点进行递归循环
for t in tag.descendants:
print(t)
''' result: <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <title>王牌对王牌4之姚晨沙溢再聚同福客栈</title> 王牌对王牌4之姚晨沙溢再聚同福客栈 '''
.string
如果tag只有一个NavgableString类型的子节点,可以使用.string得到子节点
tag = soup.head
print(tag.string)
title_tag = tag.title
print(title_tag.string)
''' result: None 王牌对王牌4之姚晨沙溢再聚同福客栈 '''
.strings
如果tag中有多个字符串,可以使用.strings来循环获取
for str in soup.strings:
print(repr(str))
''' '\n' '\n' '\n' '王牌对王牌4之姚晨沙溢再聚同福客栈' '\n' '\n' '\n' '\n' '\n' '\n' '\n' '综艺' '\n' '\n' '\n' '\n' '\n' '''
.stripped_strings
使用.stripped_strings可以去除多余空白内容
for str in soup.stripped_strings:
print(repr(str))
''' '王牌对王牌4之姚晨沙溢再聚同福客栈' '综艺' '''
父节点
.parent
可以通过.parent属性来获取某个元素的父节点
tag = soup.title
print(tag.parent)
''' <head itemprop="video" itemscope="" itemtype="//schema.org/VideoObject"> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <title>王牌对王牌4之姚晨沙溢再聚同福客栈</title> </head> '''
.parents
可以通过.parents属性递归得到元素的所有父节点
tag = soup.title
for p in tag.parents:
if p is None:
print(p)
else:
print(p.name)
''' head html [document] '''
兄弟节点
.next_sibling和.previous_sibling
通过.next_sibling和.previous_sibling属性来操作兄弟节点
#.previous_sibling的使用
tag = soup.a
previous_tag = tag.previous_sibling
print(previous_tag)
print(previous_tag.previous_sibling)
''' result: 这里是一个输出,空格也算一个节点 <i class="logo-dot"></i> '''
#.next_sibling的使用
tag = soup.i
next_tag = tag.next_sibling
print(next_tag)
print(next_tag.next_sibling)
''' result: <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> '''
.next_siblings和.previous_siblings
通过.next_siblings和.previous_siblings属性可以迭代输出所有的兄弟节点
#.previous_siblings的使用
tag = soup.a
for previous in tag.previous_siblings:
print(repr(previous))
''' result: '\n' <i class="logo-dot"></i> '\n' '''
#.next_siblings的使用
tag = soup.i
for next in tag.next_siblings:
print(repr(next))
''' result: '\n' <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> '\n' '''
前进和回退
.next_element 和 .previous_element
通过.next_element和.previous_element可以解析下一个或上一个对象
tag = soup.a
#previous_element
print(tag.next_element)
print(tag.next_element.next_element)
''' result: 该tag上一个对象是\n <i class="logo-dot"></i> '''
#.next_element
print(tag.next_element)
''' result: <h2>综艺</h2> '''
.next_elements 和 .previous_elements
通过.next_elements和.previous_elements可以迭代解析下一个或上一个对象
#.previous_element
tag = soup.head
for e in tag.previous_elements:
print(e)
''' result: <html lang="zh-CN"> <head itemprop="video" itemscope="" itemtype="//schema.org/VideoObject"> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <title>王牌对王牌4之姚晨沙溢再聚同福客栈</title> </head> <body> <div class="qy-header" id="block-A" is="i71-header" page-name="" v-bind:non-index="true"> <[email protected]<template slot="header" slot-scope="props">@--> <div :style="{ display: 'block'}" class="qy-logo" id="nav_logo" style="display: none;"> <i class="logo-dot"></i> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> </div> <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div> </div> </body></html> HTML '''
#next_element
tag = soup.h2
for e in tag.next_elements:
print(e)
''' result: 综艺 <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div> '''
搜索文档树
使用例子:
from bs4 import BeautifulSoup
soup = BeautifulSoup(''' <!DOCTYPE HTML> <html lang="zh-CN"> <head itemprop="video" itemscope itemtype="//schema.org/VideoObject"> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>王牌对王牌4之姚晨沙溢再聚同福客栈</title> </head> <body> <div is="i71-header" page-name="" class="qy-header" id="block-A" v-bind:non-index='true'> <[email protected]<template slot="header" slot-scope="props">@--> <div id="nav_logo" class="qy-logo" style="display: none;" :style="{ display: 'block'}"> <i class="logo-dot"></i> <a class="logo-channel" title="综艺" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6"><h2>综艺</h2></a> </div> <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div> </div> </body></html> ''')
find_all()
find_all(name,attrs,recursive,string,**kwargs)
#name参数
#查找所有名字为name的tag
print(soup.find_all("a"))
''' result: [<a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a>] '''
#keyword参数
#将属性作为key值来查找
import re
print(soup.find_all(id='nav_logo'))
print(soup.find_all(href=re.compile("zongyi/")))
#有些tag在搜索中不能使用,但可以使用attrs参数来定义参数
#print(soup.find_all(class="qy-logo")) 此处结果会报错 SyntaxError: invalid syntax
print(soup.find_all(attrs=["class","qy-logo"]))
''' result: [<div :style="{ display: 'block'}" class="qy-logo" id="nav_logo" style="display: none;"> <i class="logo-dot"></i> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> </div>] [<a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a>] [<div :style="{ display: 'block'}" class="qy-logo" id="nav_logo" style="display: none;"> <i class="logo-dot"></i> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> </div>] '''
#css参数
#class在Python是保留字,使用class作为参数将会报错,但BeautifulSoup4.1.1版本之后,可以通过class_参数搜索
print(soup.find_all('i',class_='logo-dot'))
''' result: [<i class="logo-dot"></i>] '''
#text参数
#通过text参数可以搜索文档中的字符串的内容,text参数也可以是正则、列表等
print(soup.find_all(text="综艺"))
''' result: ['综艺'] '''
#limit参数
#使用limit属性来限制返回值的数量
print(soup.find_all("div",limit=1))
''' result: [<div class="qy-header" id="block-A" is="i71-header" page-name="" v-bind:non-index="true"> <[email protected]<template slot="header" slot-scope="props">@--> <div :style="{ display: 'block'}" class="qy-logo" id="nav_logo" style="display: none;"> <i class="logo-dot"></i> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> </div> <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div> </div>] '''
#recursive参数
#find_all()方法默认会搜索当前tag的所有子孙节点,若只想搜索直接子节点,将recursive参数设为False即可
print(soup.find_all("div",id='nav_logo',recursive=True))
print(soup.find_all("div",id='nav_logo',recursive=False))
''' result: [<div :style="{ display: 'block'}" class="qy-logo" id="nav_logo" style="display: none;"> <i class="logo-dot"></i> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> </div>] [] '''
find()
若只想得到一个结果,可以使用find()方法
print(soup.find("title"))
''' result: <title>王牌对王牌4之姚晨沙溢再聚同福客栈</title> '''
#soup.find("title") 等价于soup.find_all('title',limit=1)
过滤器
字符串
在find_all()方法中传一个字符串作为参数
print(soup.find_all('a'))
''' result: [<a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a>] '''
正则表达式
在find_all()方法中传一个正则表达式作为参数
import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
''' result: body '''
列表
在find_all()方法中传入一个列表作为参数
print(soup.find_all(["i","a"]))
''' result: [<i class="logo-dot"></i>, <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a>] '''
True
True可以匹配任何值
for tag in soup.find_all(True):
print(tag.name)
''' result: html head meta title body div div i a h2 div '''
方法
在find_all()方法中传入一个方法作为参数
def method1(tag):
return tag.has_attr('class') and not tag.has_attr('id')
print(soup.find_all(method1))
''' result: [<i class="logo-dot"></i>, <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a>, <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div>] '''
find_parents()和find_parent()
用来搜索当前节点的父辈节点
a_string = soup.find(text="综艺")
print(a_string)
print(a_string.find_parents("a"))
print(a_string.find_parent("a"))
''' result: 综艺 [<a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a>] <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> '''
find_next_siblings()和find_next_sibling()
用来查找兄弟节点,find_next_siblings()可以迭代查出所有的兄弟节点,find_next_sibling()只能查出符合条件的第一个兄弟节点
print(soup.i.find_next_siblings("a"))
print(soup.i.find_next_sibling("a"))
''' result: [<a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a>] <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> '''
find_all_next() 和 find_next()
用来查找当前节点后面的节点
print(soup.i.find_all_next())
print(soup.i.find_next())
''' result: [<a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a>, <h2>综 艺</h2>, <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div>] <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> '''
find_all_previous() 和 find_previous()
查找当前节点前面的节点
print(soup.title.find_all_previous())
print(soup.title.find_previous())
''' result: [<meta content="text/html; charset=utf-8" http-equiv="Content-Type"/>, <head itemprop="video" itemscope="" itemtype="//schema.org/VideoObject"> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <title>王牌对王牌4之姚晨沙溢再聚同福客栈</title> </head>, <html lang="zh-CN"> <head itemprop="video" itemscope="" itemtype="//schema.org/VideoObject"> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <title>王牌对王牌4之姚晨沙溢再聚同福客栈</title> </head> <body> <div class="qy-header" id="block-A" is="i71-header" page-name="" v-bind:non-index="true"> <[email protected]<template slot="header" slot-scope="props">@--> <div :style="{ display: 'block'}" class="qy-logo" id="nav_logo" style="display: none;"> <i class="logo-dot"></i> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> </div> <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div> </div> </body></html>] <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> '''
CSS选择器
使用 .select() 方法传入字符串参数即可查找
#通过tag来查找
print(soup.select('a'))
''' result: [<a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a>] '''
#通过id来查找
print(soup.select('#nav_logo'))
''' result: [<div :style="{ display: 'block'}" class="qy-logo" id="nav_logo" style="display: none;"> <i class="logo-dot"></i> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> </div>] '''
#通过class来查找
print(soup.select('.qy-logo'))
''' result: [<div :style="{ display: 'block'}" class="qy-logo" id="nav_logo" style="display: none;"> <i class="logo-dot"></i> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> </div>] '''
#通过属性的值来查找
print(soup.select('div[style="display:none;"]'))
''' result: [<div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div>] '''
修改文档树
使用例子:
from bs4 import BeautifulSoup
soup = BeautifulSoup(''' <!DOCTYPE HTML> <html lang="zh-CN"> <head itemprop="video" itemscope itemtype="//schema.org/VideoObject"> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>王牌对王牌4之姚晨沙溢再聚同福客栈</title> </head> <body> <div is="i71-header" page-name="" class="qy-header" id="block-A" v-bind:non-index='true'> <[email protected]<template slot="header" slot-scope="props">@--> <div id="nav_logo" class="qy-logo" style="display: none;" :style="{ display: 'block'}"> <i class="logo-dot"></i> <a class="logo-channel" title="综艺" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6"><h2>综艺</h2></a> </div> <div class="qy-player-head-list" is="i71-playpage-source-video-floater" style="display:none;"></div> </div> </body></html> ''')
修改tag的名称和属性
tag = soup.i
print(tag)
tag.name = "a"
print(tag)
tag['class']='logo'
print(tag)
del tag['class']
print(tag)
''' result: <i class="logo-dot"></i> <a class="logo-dot"></a> <a class="logo"></a> <a></a> '''
修改 .string
tag = soup.h2
print(tag)
tag.string = "zongyi"
print(tag)
''' result: <h2>综艺</h2> <h2>zongyi</h2> '''
append()
用于往字符串中追加内容
tag = soup.h2
print(tag)
tag.append(" hhhh ")
print(tag)
''' result: <h2>综艺</h2> <h2>综艺 hhhh </h2> '''
BeautifulSoup.new_string() 和 .new_tag()
#new_string()方法是BeautifulSoup对象的,不是tag的
s1 = BeautifulSoup("<b></b>")
tag = s1.b
print(tag)
tag.append(s1.new_string(" test "))
print(tag)
''' result: s1 = BeautifulSoup("<b></b>") <b></b> <b> test </b> '''
#添加注释
s1 = BeautifulSoup("<b></b>")
tag = s1.b
print(tag)
from bs4 import Comment
comment = s1.new_string("1 2 3",Comment)
tag.append(comment)
print(tag)
''' result: s1 = BeautifulSoup("<b></b>") <b></b> <b><!--1 2 3--></b> '''
#添加新的节点
s1 = BeautifulSoup("<b></b>")
tag = s1.b
print(tag)
new_tag = s1.new_tag("a",href="http://www.baidu.com")
tag.append(new_tag)
print(tag)
''' result: s1 = BeautifulSoup("<b></b>") <b></b> <b><a href="http://www.baidu.com"></a></b> '''
插入
# insert()
tag = soup.a
tag.insert(0," hello ")
print(tag)
tag.insert(2," world ")
print(tag)
''' result: <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"> hello <h2>综艺</h2></a> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"> hello <h2>综艺</h2> world </a> '''
# insert_before()
tag = soup.a
tag1 = soup.i
tag1.string = "hello"
tag.string.insert_before(tag1)
print(tag)
''' result: <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2><i class="logo-dot">hello</i>综艺</h2></a> '''
# insert_after()
tag = soup.a
tag1 = soup.i
tag1.string = "hello"
tag.string.insert_after(tag1)
print(tag)
''' result: <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺<i class="logo-dot">hello</i></h2></a> '''
clear()
用于移除当前节点的内容
tag = soup.a
print(tag)
tag.clear()
print(tag)
''' result: <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"></a> '''
extract()
将当前节点移除文档树
tag = soup.a
print(tag)
h_tag = tag.h2.extract()
print(tag)
print(h_tag)
''' result: <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"></a> <h2>综艺</h2> '''
decompose()
将当前节点移除文档树并完全销毁
tag = soup.a
print(tag)
tag.h2.decompose()
print(tag)
''' result: <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"></a> '''
replace_with()
用新tag或文本节点替换文档树的部分内容
tag = soup.a
print(tag)
new_tag = soup.new_tag("b")
new_tag.string = "test"
tag.h2.replace_with(new_tag)
print(tag)
''' result: <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><h2>综艺</h2></a> <a class="logo-channel" href="//www.iqiyi.com/zongyi/" rseat="708151_channel_6" title="综艺"><b>test</b></a> '''
wrap() 和 unwrap()
对指定元素进行包装和解包
# wrap()
tag = BeautifulSoup("<p>I wish I was bold.</p>")
print(tag)
tag.string.wrap(tag.new_tag("b"))
print(tag)
''' result: tag = BeautifulSoup("<p>I wish I was bold.</p>") <html><body><p>I wish I was bold.</p></body></html> <html><body><p><b>I wish I was bold.</b></p></body></html> '''
#unwrap()
tag = BeautifulSoup("<p>I wish I was bold.</p>")
print(tag)
tag.string.wrap(tag.new_tag("b"))
print(tag)
tag.b.unwrap()
print(tag)
''' result: tag = BeautifulSoup("<p>I wish I was bold.</p>") <html><body><p>I wish I was bold.</p></body></html> <html><body><p><b>I wish I was bold.</b></p></body></html> <html><body><p>I wish I was bold.</p></body></html> '''
最后
以上是我通过BeautifulSoup4文档学习BeautifulSoup4的过程,可能有些地方写的不够详细,但仍希望对其他初学者有帮助,若想了解更多,请参考Beautiful Soup Documentation
边栏推荐
- 正则表达式-判断字符串是否匹配“AABB”模式
- Build a "firewall" for safety and carry out firefighting training in Fengzhuang Township, Tongxu County, Henan Province
- [GO], arrays and slices
- Word文件的只读模式没有密码怎么退出?
- Unity Gobang Game Design and Simple AI (2)
- el-table缓存数据
- IQ Products CMV Brite Turbo试剂盒的原理
- S7-200SMART PLC Modbus TCP通信
- Qt learning (3) - Qt module
- kubernetes apparmor 简介
猜你喜欢

51 serial communication (on)

Deep Learning - Principles of Neural Networks 2

Likou Brush Question 180
![[MySQL] Second, the relationship between processes, MySQL password cracking, table building and database building related commands](/img/20/a0fb44e9360837146d0ed696c9e992.png)
[MySQL] Second, the relationship between processes, MySQL password cracking, table building and database building related commands
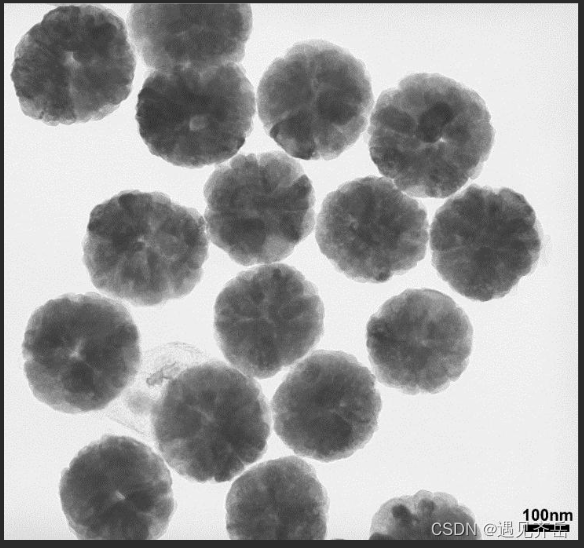 [email protected]@cadmium sulfide nanocore-shell structure material|Fe3O4 magnetic nanop"/>
[email protected]@cadmium sulfide nanocore-shell structure material|Fe3O4 magnetic nanop"/>Superparamagnetic iron [email protected]@cadmium sulfide nanocore-shell structure material|Fe3O4 magnetic nanop
vs番茄助手的方便功能和便捷快捷键介绍

Fe3O4/SiO2 Composite Magnetic Nanoparticles Aminated on SiO2-NH2/Fe3O4 Surface (Qiyue Reagent)

Used to import the data type

ZIP压缩包文件删除密码的方法

Gao Zelong, a famous digital collection expert and founder of the Digital Collection Conference, was interviewed by China Entrepreneur Magazine
随机推荐
Harbor Enterprise Mirror Warehouse Construction
弄潮 Web3 欧易OKX全球「抢人」
【JMeter】jmeter测试 - 上传多个图片/批量上传图片接口 CSV文件参数化方法
zip压缩包密码解密
直接用的zip包 缺少很多依赖,pip没有,感觉用anaconda create一个环境会方便点
Regular Expression - Determine if a string matches the "AABB" pattern
Text String Length Sorting - Online Tool
工控设备的系统如何进行加固
golang xml 处理动态属性
Kubernetes apparmor profile
Unity Gobang Game Design and Simple AI (2)
harbor企业级镜像仓库搭建
phpstudy install flarum forum
【R语言】把文件夹下的所有文件提取到特定文件夹
[MySQL]二、进程的关系、MySQL密码破解、建表和建库相关命令
MYSQLg高级------批量插入百万级数据量
Unity五子棋游戏设计 和简单AI实现(1)
qt发送邮件程序
Unity 五子棋游戏设计和简单AI(2)
声母-字母查询工具-词语缩写查询在线工具