当前位置:网站首页>实操|风控模型中常用的这三种预测方法与多分类场景的实现
实操|风控模型中常用的这三种预测方法与多分类场景的实现
2022-08-10 01:16:00 【番茄风控】
在信贷风控场景中,存在很多分类模型的应用,例如申请信用、欺诈识别、客户流失等属于二分类模型,信用评价、价值分层、额度定价等属于多分类模型,因此分类模型在信贷风控体系的架构中占据着非常重要的位置。对于分类有监督模型场景,无论是二分类还是多分类,当我们完成模型的拟合训练之后,必然会对模型的结果进行预测,这样才能进一步对模型的效果进行综合评价。例如分类模型指标AUC、KS、accuracy、Recall等指标,都依赖于模型真实标签true_Y与预测标签pred_Y的数据分布结果。其中,真实标签true_Y在样本数据中始终存在,无需额外处理,而对于预测标签pred_Y则需要采用相关方法进行直接输出或适当转换,在Python语言环境中最常用的莫过于函数predict()与predict_proba(),这是我们经常采用的方式,不仅实现方便而且易于理解。
为了全面熟悉分类模型预测标签的获取过程,本文将系统性介绍在实际场景中模型预测各种方法的原理逻辑与实现方式,除了以上predict()与predict_proba()常用的两种途径之外,还要重点分析另外一种比较好用的方法,即采用decision_function()函数来实现模型的预测标签,便于大家在实际建模场景中对模型预测有更多元化的对比与分析。在具体内容介绍之前,我们先简单描述下以上三种预测方法的原理逻辑:
(1)predict():输出模型预测的标签类型;
(2)predict_proba():输出模型预测各种标签类型的概率值;
(3)decision_function():输出模型预测属于正样本标签的可信度。
1、案例场景介绍
本文结合信贷客户价值评级场景来展开分析,为了验证各种模型预测方法针对二分类与多分类标签的输出效果,这里采用的样本数据包括两个目标变量,分别用于不同的分类情形。现有一份信贷客户价值评级场景的建模样本,数据宽表包含10000条样本和10个特征,部分样例如图1所示,其中ID为样本主键,X1~X8为特征变量;Y1为二分类变量,取值1和0,分别代表客户价值的高与低;Y2为多分类变量,取值包含1、2、3、4,代表客户价值等级,数值越大代表客户价值越高;目标变量Y1与Y2的取值分布情况如图2所示。

图1 样本数据

图2 目标分布
根据以上样本数据,我们采用传统机器学习模型逻辑回归来构建本案例的客户价值评级模型,由于目标变量Y1与Y2的取值类型不同,这里先后实现二分类模型与多分类模型,从而在两种场景下分析模型预测的重点内容。
2、客户价值二分类模型
客户价值二分类模型的建立,是通过特征变量池X1~X8来训练拟合目标变量Y1,具体实现过程如图2所示,其中模型算法LogisticRegression的输入参数采用默认组合(随机种子random_state除外)。

图3 二分类模型拟合训练
当模型训练完成后,便可以进行模型预测得到pred_Y(预测标签),下面我们采用前边所述的三种预测方法来实现(predict、predict_proba、decision_function),具体过程如图4所述。同时,我们将各预测方法下前5条样本的预测结果取出进行对比,具体数据如图5所示。

图4 二分类模型预测过程

图5 二分类模型预测结果
对于图5的预测结果,pred_Y、pred_Y_proba、pred_Y_reliabe分别代表在三种不同预测方法下的输出数据,我们选取部分客户样本的结果来依次分析:
(1)pred_Y:在第1种方式predict()下,预测结果只有1列,直接反映用户所属标签类型,例如第1个用户的预测结果为0,说明此客户的价值度低,而第3个用户的预测结果为1,代表客户的价值度高。
(2)pred_Y_proba:在第2种方式predict_proba()下,预测结果会有2列,分别代表预测为0和1的概率,二者之和为1,概率高者则属于对应标签类型。例如第1个用户预测为0的概率是0.851206,而预测为1的概率值是0.148794,前者大于后者,说明此客户预测结果为0,也就是客户的价值度低;同理可知第3个用户预测为1的概率(0.666312)大于预测为0的概率(0.333688),说明客户预测结果为1,代表客户的价值度高。
(3)pred_Y_reliabe:在第3种方式decision_function()下,预测结果只有1列,代表客户属于positive正样本的可信度,取值范围没有限制,当取值大于0时,说明预测为正样本的可能性更大,当取值小于0时,说明预测为负样本的可能性更大,当取值等于0时,说明预测为正样本与负样本的可能性相当,这里的正/负样本在本案例中分别代表1/0。例如第1个用户预测为正样本的可信度为-1.74409,说明属于0的可能性更大,预测结果为0,代表客户的价值度低;第3个用户预测为正样本的可信度为0.691553,说明属于1的可能性更大,预测结果为1,代表客户的价值度高。
通过以上三种维度的预测结果分析可知,其模型最终的预测结果都是一致的,只是从业务解释方法上有一定区别,具体应用可以结合场景需求而定,当然为了保证模型预测结果的合理性,可以尝试采用以上三种方法来对比分析,以保证模型结果的准确性。
3、客户价值多分类模型
以上内容是在二分类模型场景下实现了客户价值的评估,接下来我们采用同一种机器学习模型算法(逻辑回归LR)来构建多分类模型,主要区别点在于模型的目标变量不同,这里是通过特征变量X1~X8对目标变量Y2进行拟合训练,具体实现过程如图6所示,其中参数multi_class指定“ovr”便可以完成多分类模型的训练,此外还可以指定“multinomial”也可以实现多分类,二者的区别在于分类过程中“一对多”与“一对一”的差别,这里采用前者来实现。

图6 多分类模型拟合训练
模型拟合完成后,可以采用与上文二分类模型同样的预测方法来获取模型的预测结果,实现结果与图4一致,最终输出数据的部分样本结果汇总如图7、图8所示,具体包括三种预测方法下的预测值。

图7 多分类模型预测结果1

图8 多分类模型预测结果2
根据以上多分类模型的预测结果,分别代表分类模型三种预测方式(predict、predict_proba、decision_function)的模型预测值,我们分别对其进行解读:
(1)pred_Y:在第1种方式predict()下,预测结果直接反映用户所属标签类型,例如第1个用户的预测结果为2,说明此客户的价值度一般,而第3个用户的预测结果为1,代表客户的价值度较低。
(2)pred_Y_proba:在第2种方式predict_proba()下,预测结果会有n列,n取决于目标变量的取值类型数量,由于本案例多分类模型标签Y2有4个取值(14),因此这里的预测结果会展示4列,分别代表预测为1、2、3、4的概率,取值之和为1,概率高者则属于对应标签类型。例如第1个用户预测为14各类型标签的概率依次为0.0923001、0.767376、0.0739988、0.0663248,由于第2个概率值(0.767376)最大,对应标签为2,则说明此客户预测结果为2,说明客户的价值度一般;同理可知第3个用户预测为1的概率(0.418385)相比其他标签较大,说明客户预测结果为1,代表客户的价值度较低。
(3)pred_Y_reliabe:在第3种方式decision_function()下,预测结果也有4列,具体列数与前一种方式的逻辑相同,由目标变量取值分布决定。在前边二分类模型预测过程已介绍,这种预测方式下输出的结果值代表客户属于positive正样本的可信度,取值正负分别代表属于正样本的可能性大小。在二分类模型中,正样本是固定的,只有取值为1的情况,而对于多分类模型,每个取值类型会分别作为正样本来评价,对应到本例输出的4个可信度值,依次将1、2、3、4作为正样本,而在每种情况下,其他取值统一作为负样本。因此,对于图8输出的预测结果,以第1列数据为例,指的是预测为正样本的可信度,其中正样本为标签1,负样本为标签2、3、4。例如第1个用户在4种假设正样本的情况下,其可信度分别为:
-2.29453、1.16019、-2.53531、-2.65298,从数值的正负大小关系可以很直观了解到,此客户属于标签2的可信度更高,也就是预测结果为2,代表客户的价值度低;第3个用户预测为各标签类型的可信度虽然都为负值,但从数值大小比较之下可知预测标签1为负样本的可能性相对较低(-0.0104212),因此预测结果为1,代表客户的价值度较低。
通过以上三种维度的预测结果分析可知,多分类模型无论采取哪种方法来进行预测,其最终结果也是一致的。虽然多分类模型相比二分类模型的分析思路相对较稍显复杂,但其核心逻辑是一样的,因此在实际应用中掌握好分析方法,可以为模型预测带来很多便利,从而为数据建模任务的模型预测与评估引入更科学的系统方法,这在实际场景中是非常有价值的。
综合以上内容,我们围绕信贷客户价值评级的风控场景,通过逻辑回归算法分别建立了二分类模型与多分类模型,实现了客户价值等级的有效评估。同时,重点介绍了采用predict、predict_proba、decision_function三种方法实现了模型预测,并对预测方法的原理逻辑进行解读,以及预测结果的业务解释,可以帮助大家引入多种模型预测方法,提升对模型预测的可靠性评价。
为了便于大家对模型预测及其分析内容的进一步熟悉和理解,本文额外附带了与以上内容同步的样本数据与python代码,供大家参考学习,详情请移至知识星球查看相关内容。

…
~原创文章
边栏推荐
- C语言头文件组织与包含原则
- 你有对象类,我有结构体,Go lang1.18入门精炼教程,由白丁入鸿儒,go lang结构体(struct)的使用EP06
- 用于X射线光学器件的哈特曼波前传感器
- OOD论文:Revisit Overconfidence for OOD Detection
- 【wpf】自定义事件总结(Action, EventHandler)
- XSS详解及复现gallerycms字符长度限制短域名绕过
- web开发概述
- el-input保留一位小数点
- [转] Typora_Markdown_图片标题(题注)
- In the 2022 gold, nine, silver and ten work tide, how can I successfully change jobs and get a high salary?
猜你喜欢
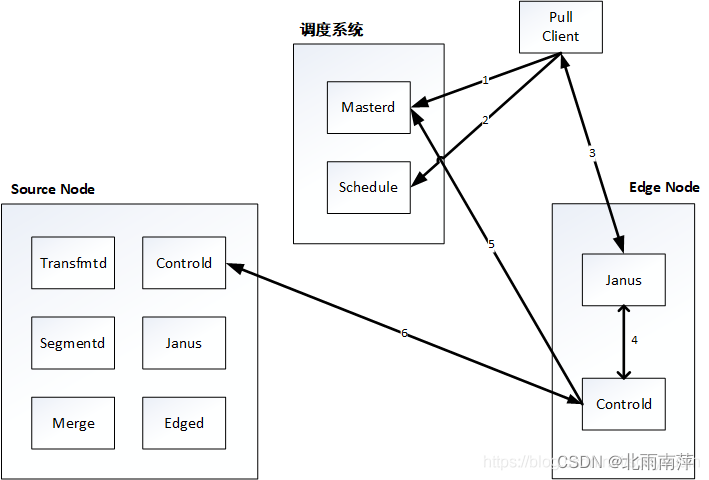
Janus实际生产案例
Unity editor extension interface uses List
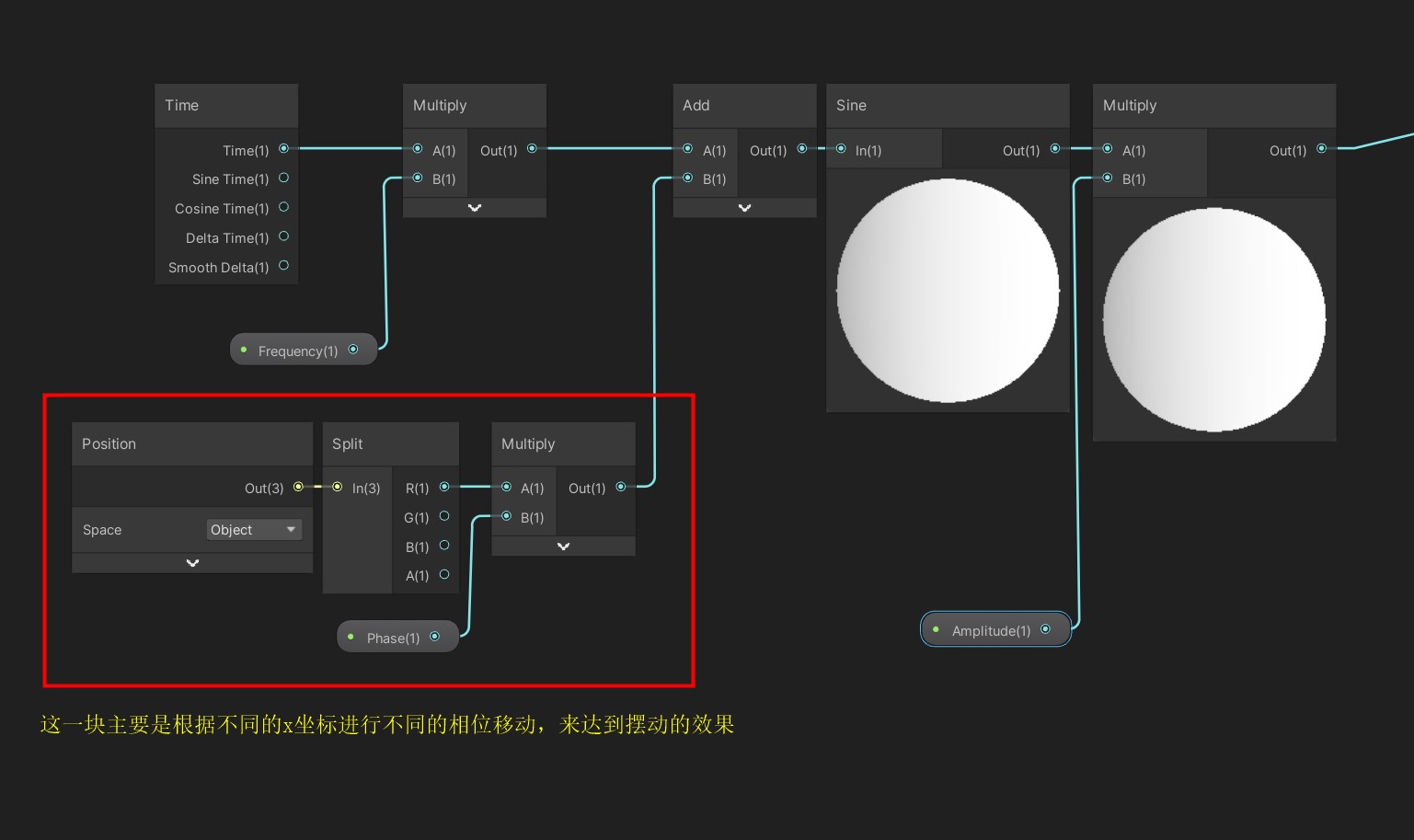
Unity顶点动画

Solidity最强对手:MOVE语言及新公链崛起

OSS-访问oss生成的url无法访问,直接下载问题

sql实战积累
XSS详解及复现gallerycms字符长度限制短域名绕过
Experimental support for decorators may change in future releases.Set the "experimentalDecorators" option in "tsconfig" or "jsconfig" to remove this warning

UI遍历的初步尝试

改变社交与工作状态的即时通讯是什么呢?
随机推荐
ABAP 里文件操作涉及到中文字符集的问题和解决方案
人际关系不仅要“存”,更要“激活”!
罗彻斯特大学 | 现在是什么序列?蛋白质序列的贝叶斯优化的预训练集成
浏览器中location详解
【内存管理概述 Objective-C语言】
OpenSSF的开源软件风险评估工具:Scorecards
Solidity最强对手:MOVE语言及新公链崛起
防勒索病毒现状分析
数据建模已死,真的吗?
芯片资讯|半导体收入增长预计将放缓至 7%,蓝牙芯片需求依然稳步增长
具有多孔光纤的偏振分束器
2022金九银十工作潮,怎么样才能成功跳槽面试拿到高薪呢?
【wpf】自定义事件总结(Action, EventHandler)
UI遍历的初步尝试
首次在我们的centos上安装MySQL
微信小程序tab切换时保存checkbox状态
Teach you how to write performance test cases
UI遍历的初步尝试
组件的使用
不是吧,连公司里的卷王写代码都复制粘贴,这合理?