当前位置:网站首页>Redis源码分析之HSET流程与ziplist
Redis源码分析之HSET流程与ziplist
2022-04-23 14:11:00 【Mrpre】
本篇分析Redis 如何处理hset指令
数据结构
首先,hset不同于set,set是存储在dict,即redis字典里面,毕竟set只是简单的kv类型数据。 hset存储的是复杂的数据结构,使用了压缩表ziplist(超大数据使用hashmap,本篇不涉及),例如
hset mykey name abc id 123
其中 mykey 为 key,abc为field,123为 value 。首先,需要说明的是,如果想了解ziplist内存的布局,完全可以看ziplist.c 文件开头的那些注释,这个是非常官方的解释,也非常详细。
- ziplist 其实挺坑的,其查找时间复杂度是O(n),如果是hmget n个field,那么复杂度就是O(n^2)
- hash_max_ziplist_entries 可以控制超过多少个field或者value后,转换成hashtable。hash_max_ziplist_value 可以控制 field或者value超过多大后,转换成hashtable
- 但是,设置 通过congfig set 来设置hash_max_ziplist_entries/hash_max_ziplist_value 不能立刻生效!!!!,除非 设置这些配置过后,key被hset了一下,那么才尝试去转换成hashtable,或者 通过redis.conf 里面配死,然后 bgsave/save生成rdb文件后,重新启动解析rdb时,会将之前的ziplist转换为hashtable。如果你的业务在设置过后一直是hget,那么一直都在O(n)
- 对于少量field后者value,使用 ziplist是有意义的;对于巨长field或者value,ziplist也节省不了空间。
- 不要尝试改动这2个值,如果你对自己存储业的数据没有百分之百了解的情况下,改动这2个参数,意味着潜在的雪崩。
使用场景:存储序列化的kv。比如,一个人叫张三,他属性有年龄、性别、职业等,使用者往往使用struct/class 存储这些属性:
struct people {
int 年龄
string 性别
} 张三
那么有几种方法存储这些信息到kv里面
(1)自己序列化,例如key为 张三,value为年龄+性别等信息,然后set到redis;取出来时自己反序列化。
(2)不同属性设置不同key,例如(张三_年龄,18),(张三_性别,男)。。。这么一堆key,分别set,然后使用时分别get。
(3)使用hset,这就体现hset的优势了。
名为mykey的key,里面有2个条目,分别是 name 以及 id。如果让你设计如何存储这些数据,怎么设计?最简单的就是将key和filed合并,即 {mykey_name, abc}, {mykey_id, 123} 2个kv,然后分别set。当然redis并不是这么存储的,我们先来看下redis怎么存储的,最后再来对比和set指令的区别。
hset对应的server的执行函数是hsetCommand
void hsetCommand(client *c) {
int i, created = 0;
robj *o;
/*hset 指令 都是 field value 对,故正确指令的参数是2的倍数*/
if ((c->argc % 2) == 1) {
addReplyError(c,"wrong number of arguments for HMSET");
return;
}
/*找到 key 对应 的object,没找到就 创建 * 假设命令是 hset mykey name abc id 123,则 查找 mykey * */
if ((o = hashTypeLookupWriteOrCreate(c,c->argv[1])) == NULL) return;
/*后面再说*/
hashTypeTryConversion(o,c->argv,2,c->argc-1);
/*保存 field value*/
for (i = 2; i < c->argc; i += 2)
created += !hashTypeSet(o,c->argv[i]->ptr,c->argv[i+1]->ptr,HASH_SET_COPY);
/* HMSET (deprecated) and HSET return value is different. */
char *cmdname = c->argv[0]->ptr;
if (cmdname[1] == 's' || cmdname[1] == 'S') {
/* HSET */
addReplyLongLong(c, created);
} else {
/* HMSET */
addReply(c, shared.ok);
}
signalModifiedKey(c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_HASH,"hset",c->argv[1],c->db->id);
server.dirty++;
}
所以保存 field value的核心函数是 hashTypeSet。在看 hashTypeSet先看看hashTypeLookupWriteOrCreate函数,这个毕竟,知道如何创建ziplist就大致了解如何存储数据到ziplist。
hashTypeLookupWriteOrCreate调用了createHashObject创建obj,然后调用ziplistNew创建ziplist挂在obj上。
/* Create a new empty ziplist. */
unsigned char *ziplistNew(void) {
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
zl[bytes-1] = ZIP_END;
return zl;
}
ziplistNew顾名思义,创建空的ziplist,空的ziplist,初始大小是ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE
/* The size of a ziplist header: two 32 bit integers for the total * bytes count and last item offset. One 16 bit integer for the number * of items field. */
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
/* Size of the "end of ziplist" entry. Just one byte. */
#define ZIPLIST_END_SIZE (sizeof(uint8_t))
显然,初始化的字段,都是一些头部字段以及边界字段
| total bytes(32bit) | last item offset(32bit) | number of items (16bit) | end (8bit)|
ZIPLIST_BYTES宏是用来取当前ziplist总长度的,包括头部长度以及entry的总长度,也就是 第一个32bit的 total bytes。
ZIPLIST_TAIL_OFFSET是用来取最后一个entry位置的,也就是last item offset所保存的值。
但是这是空的ziplist,如果保存field value那么数据结构又是怎么样的,这里先展示entry在整个ziplist中的布局:
| total bytes | last item offset | number of items | entry1 | entry2 | end |
entry 放置在 number of items之后,end之前。
下面我们看看如何存储数据到 ziplist,然后怎么创建entry的。
#define HASH_SET_TAKE_FIELD (1<<0)
#define HASH_SET_TAKE_VALUE (1<<1)
#define HASH_SET_COPY 0
int hashTypeSet(robj *o, sds field, sds value, int flags) {
int update = 0;
/*默认就是 OBJ_ENCODING_ZIPLIST ,所以进这个if*/
if (o->encoding == OBJ_ENCODING_ZIPLIST) {
unsigned char *zl, *fptr, *vptr;
/*zl 是在 hashTypeLookupWriteOrCreate时,通过 ziplistNew 创建*/
zl = o->ptr;
/*ziplistIndex 获取 第ZIPLIST_HEAD个entry *显然如果之前没有hset过,那么 fptr返回是null */
fptr = ziplistIndex(zl, ZIPLIST_HEAD);
if (fptr != NULL) {
/*从fptr所指的entry开始找,找到 field一样的entry *由于 fptr是 第 ZIPLIST_HEAD 个节点,即第0个节点 *这就是相当于从第0个entry开始找,时间复杂度是O(n) */
fptr = ziplistFind(fptr, (unsigned char*)field, sdslen(field), 1);
if (fptr != NULL) {
/*表示找到了,那么就覆盖 value*/
/* Grab pointer to the value (fptr points to the field) */
vptr = ziplistNext(zl, fptr);
serverAssert(vptr != NULL);
update = 1;
/* Delete value */
zl = ziplistDelete(zl, &vptr);
/* Insert new value */
zl = ziplistInsert(zl, vptr, (unsigned char*)value,
sdslen(value));
}
}
if (!update) {
/* Push new field/value pair onto the tail of the ziplist */
/*没找到field对应的entry,那么就插入一个 *但是我们看到 要插入2次,field和value分别作为一个entry插入 * */
zl = ziplistPush(zl, (unsigned char*)field, sdslen(field),
ZIPLIST_TAIL);
zl = ziplistPush(zl, (unsigned char*)value, sdslen(value),
ZIPLIST_TAIL);
}
o->ptr = zl;
/* Check if the ziplist needs to be converted to a hash table */
if (hashTypeLength(o) > server.hash_max_ziplist_entries)
hashTypeConvert(o, OBJ_ENCODING_HT);
} else if (o->encoding == OBJ_ENCODING_HT) {
......
} else {
......
}
/* Free SDS strings we did not referenced elsewhere if the flags * want this function to be responsible. */
if (flags & HASH_SET_TAKE_FIELD && field) sdsfree(field);
if (flags & HASH_SET_TAKE_VALUE && value) sdsfree(value);
return update;
}
梳理下流程:
(1)找到第一个entry,然后从第一个entry开始找和filed相同的entry
(2)若(1)没找到,则创建2个entry,若(1)找到了则更新value
这里就要讲下 entry 的内存分布了
| pre_len | encoding | content |
pre_len:记录了前一个entry的长度,因为 entry 是线性布局的,所以当我们知道前一个entry的长度时,我们就能在当前entry起始地址减去这个长度,就能寻址到前一个entry,达到反向遍历的效果。 pre_len本身的存储是被编码的,而不是简单的x字节。
pre_len的表示长度,要么1字节要么5字节,既简单也暴力。pre_len存储的值小于254,就用1字节表示,大于等于254就用5字节。当pre_len的msb为0x00时,当前字节就表示了长度,如果是0xfe时,那么其后4个字节,就是表示了长度。
encode:记录了content的类型和长度,他本身也是被编码的,而不是简单的x字节。 encode的编码就复杂了点。这里就直接贴出 源码中的注释,核心就是不同的msb (2bit)表示不同长度的数据。最高如果是11,那么他更特殊,因为后面保存的是数字。
* |00pppppp| - 1 byte
* String value with length less than or equal to 63 bytes (6 bits).
* "pppppp" represents the unsigned 6 bit length.
* |01pppppp|qqqqqqqq| - 2 bytes
* String value with length less than or equal to 16383 bytes (14 bits).
* IMPORTANT: The 14 bit number is stored in big endian.
* |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 bytes
* String value with length greater than or equal to 16384 bytes.
* Only the 4 bytes following the first byte represents the length
* up to 32^2-1. The 6 lower bits of the first byte are not used and
* are set to zero.
* IMPORTANT: The 32 bit number is stored in big endian.
* |11000000| - 3 bytes
* Integer encoded as int16_t (2 bytes).
* |11010000| - 5 bytes
* Integer encoded as int32_t (4 bytes).
* |11100000| - 9 bytes
* Integer encoded as int64_t (8 bytes).
* |11110000| - 4 bytes
* Integer encoded as 24 bit signed (3 bytes).
* |11111110| - 2 bytes
* Integer encoded as 8 bit signed (1 byte).
* |1111xxxx| - (with xxxx between 0000 and 1101) immediate 4 bit integer.
* Unsigned integer from 0 to 12. The encoded value is actually from
* 1 to 13 because 0000 and 1111 can not be used, so 1 should be
* subtracted from the encoded 4 bit value to obtain the right value.
* |11111111| - End of ziplist special entry.
content:就是实际的内容了。
此时不得不重提ziplist内存布局了,entry位于number of items之后,end
之前,ziplist作为一个线性空间,插入filed会必然导致频繁的realloc,即当频繁对一个key增加成千上百个field value时,就存在大量realloc以及内存拷贝
| total bytes(32bit) | last item offset(32bit) | number of items (16bit) | end (8bit)|
我们来看看一个entry如何表示field的,插入函数是ziplistPush。
ziplistPush->__ziplistInsert,下面代码中的注释就是我们关心的细节。
/* Insert item at "p". */
unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen;
unsigned int prevlensize, prevlen = 0;
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789; /* initialized to avoid warning. Using a value that is easy to see if for some reason we use it uninitialized. */
zlentry tail;
/*入参p是ZIPLIST_ENTRY_END(zl),即最后一个entry的结尾,所以p[0]在当前这种情况,必然是 ZIP_END *只有当 p 是 ZIPLIST_ENTRY_HEAD时p[0]才不会为ZIP_END */
/* Find out prevlen for the entry that is inserted. */
if (p[0] != ZIP_END) {
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
} else {
/*到这里,p[0] == ZIP_END, 说明p指向末尾了,那么只能取最后一个entry*/
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
if (ptail[0] != ZIP_END) {
/*到这里,说明当前有entry,那么就取最后一个entry*/
prevlen = zipRawEntryLength(ptail);
}/*else 说明这个zl 压根就是空的*/
}
/* See if the entry can be encoded */
/*编码,看看字符串的值是不是数字,是数字就存储为数字,这样省内存 *编码成功,reqlen 就能设置为 具体的长度了,否则设置为原始长度slen */
if (zipTryEncoding(s,slen,&value,&encoding)) {
/* 'encoding' is set to the appropriate integer encoding */
reqlen = zipIntSize(encoding);
} else {
/* 'encoding' is untouched, however zipStoreEntryEncoding will use the * string length to figure out how to encode it. */
reqlen = slen;
}
/* We need space for both the length of the previous entry and * the length of the payload. */
reqlen += zipStorePrevEntryLength(NULL,prevlen);
reqlen += zipStoreEntryEncoding(NULL,encoding,slen);
/*到这里,reqlen就是实际entry的长度,具体 编码 看上面2个函数*/
/* When the insert position is not equal to the tail, we need to * make sure that the next entry can hold this entry's length in * its prevlen field. */
int forcelarge = 0;
/*上面注释写的很清楚了,由于下一个entry存折当前entry的长度,而长度本身又是编码的不定长字节,如果当前entry改变了长度,导致下一个entry保存pre_len字节数有变化,就是nextdiff*/
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
if (nextdiff == -4 && reqlen < 4) {
nextdiff = 0;
forcelarge = 1;
}
/* Store offset because a realloc may change the address of zl. */
offset = p-zl;
zl = ziplistResize(zl,curlen+reqlen+nextdiff);
p = zl+offset;
/* Apply memory move when necessary and update tail offset. */
/*上面对ziplist realloc,即ziplist后面多了一堆空内存,这里如果p不是插入在最后而是插入在中间,那么需要把p对应的地方的数据,往后面挪,然后空出空间来保存当前的entry*/
if (p[0] != ZIP_END) {
/* Subtract one because of the ZIP_END bytes */
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
/* Encode this entry's raw length in the next entry. */
if (forcelarge)
zipStorePrevEntryLengthLarge(p+reqlen,reqlen);
else
zipStorePrevEntryLength(p+reqlen,reqlen);
/* Update offset for tail */
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
/* When the tail contains more than one entry, we need to take * "nextdiff" in account as well. Otherwise, a change in the * size of prevlen doesn't have an effect on the *tail* offset. */
zipEntry(p+reqlen, &tail);
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else {
/* This element will be the new tail. */
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
/* When nextdiff != 0, the raw length of the next entry has changed, so * we need to cascade the update throughout the ziplist */
if (nextdiff != 0) {
/*这就是所谓的连锁更新,碰到这种情况就糟糕的很*/
offset = p-zl;
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
/* Write the entry */
p += zipStorePrevEntryLength(p,prevlen);
p += zipStoreEntryEncoding(p,encoding,slen);
if (ZIP_IS_STR(encoding)) {
memcpy(p,s,slen);
} else {
zipSaveInteger(p,value,encoding);
}
ZIPLIST_INCR_LENGTH(zl,1);
return zl;
}
版权声明
本文为[Mrpre]所创,转载请带上原文链接,感谢
https://wonderful.blog.csdn.net/article/details/106824764
边栏推荐
- mysql 5.1升级到5.68
- TLS/SSL 协议详解 (30) SSL中的RSA、DHE、ECDHE、ECDH流程与区别
- Thread group ThreadGroup uses introduction + custom thread factory class to implement threadfactory interface
- JDBC details
- 一些小小小小记录~
- Notes on Visio drawing topology
- VMware 15pro mounts the hard disk of the real computer in the deepin system
- MYSQL一种分表实现方案及InnoDB、MyISAM、MRG_MYISAM等各种引擎应用场景介绍
- 线程间控制之Semaphore使用介绍
- JS progress bar, displaying the loading progress
猜你喜欢
Recyclerview advanced use (I) - simple implementation of sideslip deletion

About the configuration and use of json5 in nodejs
Operation instructions of star boundary text automatic translator
Research on recyclerview details - Discussion and repair of recyclerview click dislocation
API Gateway/API 网关(四) - Kong的使用 - 集成Jwt和熔断插件
云迁移的六大场景
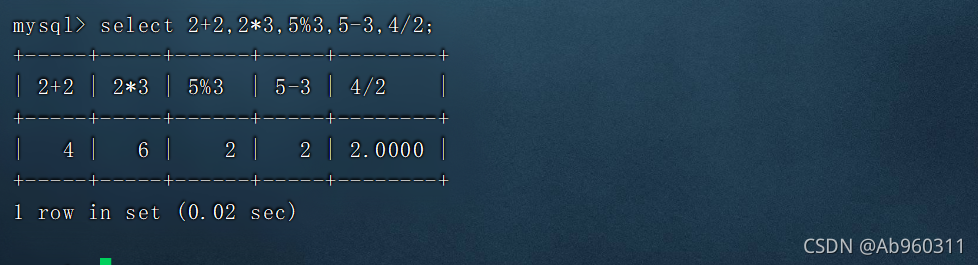
MySQL数据库讲解(八)

HyperBDR云容灾V3.2.1版本发布|支持更多云平台,新增监控告警功能
Tongxin UOS uninstall php7 2.24, install php7 4.27 ; Uninstall and then install PHP 7.2.34

多云数据流转?云上容灾?年前最后的价值内容分享
随机推荐
mysql 5.1升级到5.66
01-nio basic ByteBuffer and filechannel
在Clion中给主函数传入外部参数
Pass in external parameters to the main function in clion
js 格式化时间
grep无法重定向到文件的问题
redis数据库讲解(四)主从复制、哨兵、Cluster群集
百度笔试2022.4.12+编程题目:简单整数问题
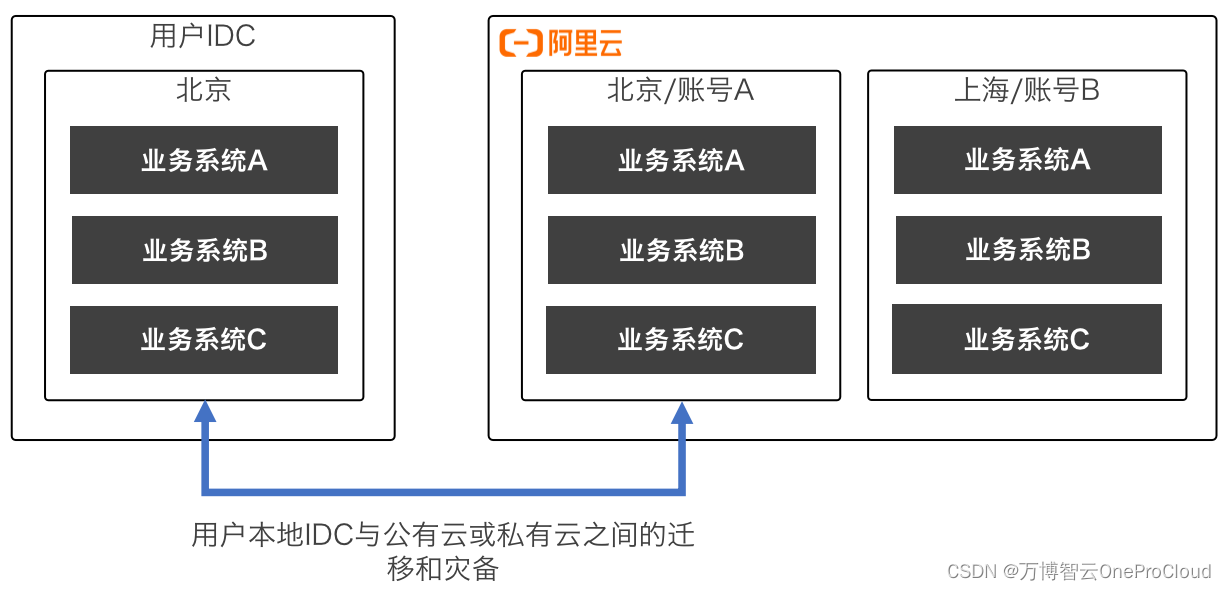
云迁移的六大场景
线程间控制之CountDownLatch和CyclicBarrier使用介绍
Uni app message push
Quickly understand the three ways of thread implementation
TLS/SSL 协议详解 (30) SSL中的RSA、DHE、ECDHE、ECDH流程与区别
使用开源调研工具Prophet是一种什么体验?
Storage path of mod subscribed by starbound Creative Workshop at Star boundary
关于云容灾,你需要知道这些
Notes on Visio drawing topology
mysql 5.1升级到5.69
mysql 5.1升级到5.68
Arrays类的使用案例