当前位置:网站首页>Paper sharing: "FED BN" uses the LOCAL BATCH NORMALIZATION method to solve the Non-iid problem
Paper sharing: "FED BN" uses the LOCAL BATCH NORMALIZATION method to solve the Non-iid problem
2022-08-09 21:04:00 【InfoQ】

更多干货内容,请关注公众号:隐语的小剧场
This sharing is based onICLR 2021收录的一篇文章:
《FED BN: FEDERATED LEARNING ON NON-IID FEATURES VIA LOCAL BATCH NORMALIZATION》
,This paper mainly discusses the use ofLOCAL BATCH NORMALIZATION方法解决Non-iid问题.The sharing around this paper will be divided into4个部分:
1、BATCH NORMALIZATION及其解决Non-iid问题的方法;
2、Non-iidProblems and commonly usedsota解决方法;
3、FED BN及其解决Non-iid问题的方法;
4、Experiment analysis around the paperFED BNeffect and value.
话题一、BATCH NORMALIZATION及其解决Non-iid问题的方法
1. BATCH NORMALIZATION
BATCH NORMALIZATION是在
A commonly used and effective method in plaintext machine learning,
it can be solved very wellfeature scaling的问题,Including between layersinternal Covariate Shift 的问题.
那么什么是feature shift呢,我们来举个例子

As shown in the figure, the task is to identify whether the content of the picture is a rose,The small green circle on the right is a rose,red is not,The blue is the classification boundary.Although up and down2This Mosaic at the same task,However, it can be seen that the distribution of characteristics is significantly different to the naked eye..
This distribution state can cause convergence difficulties during training.,More steps are needed to offsetscaleThe influence of different can finally converge.
这种feature scaleDifferences when matrix-multiplied with weights,will produce some large deviations,This difference value affects later layers in the network,And the greater the deviation, the more obvious the impact.BNThe role is to normalize the input,缩小 scale 的范围.The result is that can improve the convergence of the gradient,并提升训练速度.
那么BN是怎么来的呢?
在早些时期,There is a way when network is relatively flatWhiten(白化):Transform the input data to a normal distribution with unit variance,可以加速网络收敛.In deep networks, with increasing network depth,每层特征值分布会逐渐的向激活函数的输出区间的上下两端(激活函数饱和区间)靠近,Continuing like this will cause the gradient to disappear,Affects training convergence.一些工作包括Relu, Resnet和BNwait is just trying to fix this.
既然whiten可以加速收敛,So whether to do each layer in the deep networkwhitento speed up the convergence?
From this idea came theBN,Its role is to ensure that machine learningiid假设,Ensure that the activation input distribution of each hidden layer node is fixed,降低feature shiftImpact on model training.
那BN怎么做?
训练阶段

1、取batchCalculate the mean of the data
2、取batchData calculation variance
3、做normalize
4、通过训练得到scale 和shift参数
这里normalizeIn the latter process, two parameters are also involved
:γ及β,一个对应scale,一个对应shift
,is the parameter to perform a translation operation on it.Why are these two parameters needed?我们以sigmoidActivation function for example;By default, the author of the paper willBNadd before activation function,If you getnormalize No linear changes are added after,will cause most of the input results to stay in linear space.But the multi-layer superposition of linear space is invalid.,There is no difference compared to a one-layer linear network,that weakens the expressiveness of the entire network
.Therefore it is necessary to addγ及β参数进行转换,make it find a balance between linearity and nonlinearity,In this way, you can enjoy the benefits of non-linear expression,It can also prevent it from falling on both ends and affecting the convergence speed.

in the forecasting process,则没有batch 的概念,We need to use all the data to be predicted to find the mean,Then find the sampling variance,Finally use these two parameters,Convert it and use it in predictions.
Summary of advantages:
1、Can greatly improve the training speed and convergence speed,可以使用较大的学习率
2、can enhance learning
3、The parameter adjustment process will become easier,因为BNThe use of sensitivity to the initial value of the reduced
Summary of shortcomings:
1、There is a slight inconsistency between the training and prediction results
2、单个batchThe calculation requires an increase in the amount of calculation
话题二、iid
iid,即独立同分布,Assume that the training data and test data satisfy the same distribution,It is the basic premise guarantee that the model obtained through training data can obtain better results on the test set.But in some federal scenarios,Different data sources make this assumption difficult to satisfy.关于iidThe classification reference of related papers can be divided into five cases:
1、Feature distribution skew,
feature distribution shift
(Take the recognition of roses in the previous article as an example,x characteristics are inconsistent,但label 分布一致);
2、Label distribution skew,
That is, the characteristic distribution is consistent,but each party'slabelare not the same
(As different people recognize different sets of words);
3、Quantity skew,
That is, the amount of data is different
;
4、Same label but different feature,the vertical scene as we know it
,Each party has some data,These data share alabel;
5、Same feature but different label,
same features butlabel不同,即多任务学习.

如上图(Figure quoted from)所示,Divide data and common methods into corresponding solvable problems,FED BNIt solves the problem of feature distribution shift.
解决iidThe classical federated algorithm for the problem
1. Fed-AVG
Fed-AVGIt is one of the classic algorithms in federated learning,主要解决两个问题:
communication problems andClient数量问题.
通信问题,即相较于SGDThe method requires the gradient to be(gradient)或权重(weight)Sent to the server for aggregation,Requires a lot of additional communication and computation.Fed-AVGthen allows some to be done locally on the clientstepThen go to the server for aggregation,Reduce overall communication by increasing client-side computation,并且Fed-AVGAll don't need every timeClient都参加,Further reduces the communication and computation.This work theoretically provesFed-avg的收敛性.
FedavgThe convergence path is shown in the following figure:


Fed-AVG的流程为:
1、server Distribute the global model to eachclient
2、各个client 使用localThe data is iterated through other optimization methods such as,得到gradient或weight,并加密发送给server
3、Server对收到的gradient和weightto aggregateglobal g/w,发送给各个clients
4、Client收到global g/w update its local model
2. FedProx
FedProx是在Fed-AVGBased on some evolution,作者引入了proximal term the concept of constraints,set learning objectives byF(x) 变为了H(x),The purpose is to make local update don't be too far away from the initial global model,Reduced while tolerant of system heterogeneity Non-IID 的影响.用γas a local iterable proxy,The smaller the value, the higher the update accuracy.

FedProxThe overall process is basicallyfed-avg是一样的,
差异在于loss函数做了修改,Added constraints
.

So the gradient of each round of descent becomes

3. Scaffold
Scaffold也是从fed-avgevolved on the basis ofnon-iid策略,through a random processcontrol variates(guess)来克服client driftfor federated learning.scaffoldWant to can see their own data,又能看到server 的数据啊,In this way, the direction of your own learning can be as far as possible.globalhere,Avoid Divergence Not Convergence.但是serverdata is not visible,So just guess,to guessserver的梯度方向,作者给了C和Ci的概念,Ci是梯度, CIs the conjunction gradient,Here it is assumed that the coincidence gradient isserverdirection to optimize,Take the conjunct gradient and the gradient calculated this time to find a difference,You can get optimization should go in the direction of the.So for this algorithm,not only update parameters,Also update the guess.
算法流程如下:

可以看到和fed-avg的区别在于多了ci和c,每一个client计算的ciSeveral rounds of iteration is to his sidegradient进行平均得到的,server的Cis obtained from all aspectsci进行平均得到.

话题三:FedBN
FedBNThe greatest contribution of this work is that he proposed
How to use under federal study scenebatch normalization策略,来解决feature shift问题,同时可以利用BN来加速训练.
•The article by adding a batch normalization layer to the local model(BN)Heterogeneity of federal study datafeature shift这种情况
•Feature shift:
•y为标签,x为特征,文章将feature shiftDefined as:

•例如:Medical imaging in different scanners/传感器,Different environment distributions in autonomous driving(highway and city),Make the sample distribution of local clients different from other clients.
•与FedAvg类似,FedBNLocal updates and model aggregation are also performed,不同的是,FedBNSuppose the local model has a batch normalization layer(BN),且BNThe parameters do not participate in aggregation.

收敛性分析:
作者用NTKDo a series of formal proofs,得出的结论是:
在feature shift场景下,FedBN的收敛比FedAvgfaster and smoother
Experiment:
The experiment was chosen
5from different domains withfeature shiftdataset of properties
(Data from different domains has heterogeneity and the same label distribution),具体包括
SVHN、USPS、 MNIST-M、MNIST、SynthDigits
.The article preprocesses these five datasets in advance,Control for irrelevant factors,For example, the problem of unbalanced sample size among customers,使BNThe effect is easier to observe in the experiment.

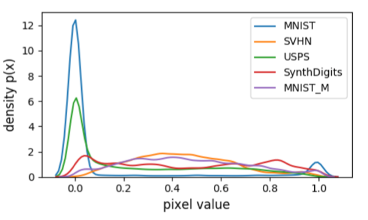
Difference plot of distributions between individual datasets
模型提供了一个简单的CNN网络,Each layer is added a backBN ReLU
实验一
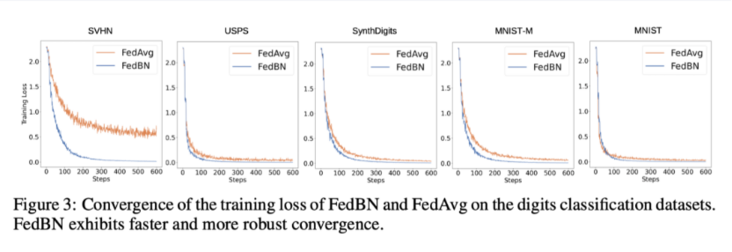
从上面5A data set and modelssetting 可以看出,
Whether in terms of convergence quality or convergence speed,都是要比FedBN以及FedAVG要好.
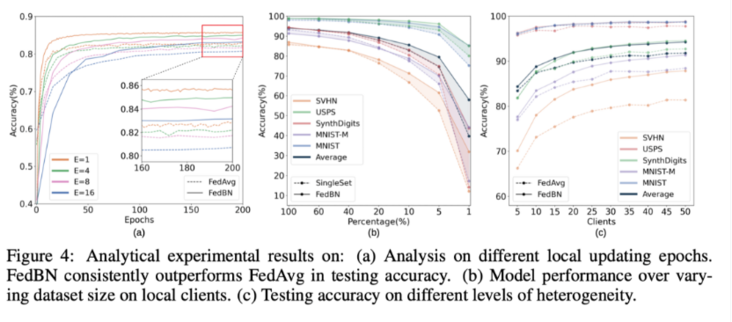
上图是3个实验:
aThe figure shows the differentlocal update step 对收敛性的影响.
横轴是Epochs 其实是local update step 的概念.纵轴是test accuracy.
1、可以看出local update step和testing\_acc负相关
2、fedBnOverall ratiofed-avg表现优异
3、Especially when we look at the final convergence results,fedbnmore stable performance
图bis the effect of different local dataset sizes on convergence
,横轴 percentage,That is, what percentage of the data is taken out locally for training,纵轴是testing accuracy.我们可以看出,The accuracy of the test islocal clientonly contribute20%Significant drop in data,but corresponds tosinglesetThe boost is reversed,The smaller the amount of data, the greater the performance improvement,所以表明fedbnSuitable for use in joint training where one party does not hold a large amount of data.
图cis the effect of different heterogeneity on convergence,
The author here attempts to answer the question to what extent is heterogeneityFedBN会比FedAVG位置好.The experiments here put each1The square data is divided into10份,一共有5个数据,总共50份数据,So the total number of abscissas is50.
1、开始时每个datasetChoose a dataset to participate in training
2、然后逐渐的增加clients,要保持n倍clients数量
3、More clients -> less heterogeneity
Assume that more data sets,Client more,his heterogeneity will be lower.得出结论是,
at any setting,FedBN都比FedAVG效果要更好一点.
接下来是和SOTA的比较,The method of comparison isFed Prox,Fed Avg,还有Single set(Pull the data to a party for training,仍有non-iid特性).因为FedBNadded to the modelBN,So the result compared toSingleset要更好一点,因为BN把一些“data shift”做了处理,降低了non-iid数据的影响.FedBNcompared to others,indicators are better,尤其是在svhn 这个数据上,The increase is the most obvious,将近有10%.The characteristic of this data is that the characteristic is very high,差异很大.Therefore, this method is more effective for data with large differences in characteristics..同时FedBNwhen running multiple times,error的方差最小,The trained model is more stable.
最后我们FedBNTake a look at the performance on the real dataset:This article selects a natural image datasetOffice-Caltech10,它有4个数据源Office-31(3个数据源)、Caltech256,每个clients分配了4one of the data sources,所以数据在clients之间是Non-iid的.
The second data source isDomainNet,包含了从6The natural image datasets from these data sources are:(Clipart,Infograph,Painting,Quickdraw,Real,Sketch),Classification method and the aboveCal10是一样的.
The third dataset fromABIDE I数据集选取,包含了4个医学数据集
(NYU,USM,UM,UCLA)
Each party is considered to be aclient.

结果和分析:
从结果可以看出,FedBNsurpasses the current SOTA工作.而且,我们可以看到FedBN除了QuickDraw数据集外,results in a comparative advantage,甚至优于SingleSet的结果,BN在解决feature shiftThere are significant advantages in improving the model effect.
The above results are also for us to use in the medical and health fieldFedBN提供了信心,Because the characteristics of data in medical scenarios are often limited in number,离散分布,而且是有feature shift的.
总结:
This work presentsFedBN,given for use in federated scenariosBN来缓解feature shift的方法,and proved its convergence and effectiveness.
FedBNmethods and communications、The optimizer method is orthogonal,Can be used in combination in actual use.FedBNthe algorithm is rightFedAvg只做了很小的改动,In practice, also with other federationsstrategy进行结合使用(Pysyft、TFFHave integrated).FedBNHas been in the medical health,Fields such as autonomous driving have proven to be effective strategies,The data for these scenarios are characterized by,Different local data due to existencefeature shift导致的non-iid.关于数据安全性,BNThe layer's data is invisible to the entire interaction and aggregation(Invasible),Therefore, to a certain extent, it increases the difficulty of attacking local data..
更多干货内容,请关注公众号:隐语的小剧场
边栏推荐
猜你喜欢




随机推荐
URLError: <urlopen error [Errno 11004] getaddrinfo failed>调用seaborn-data无法使用
字节二面,差点倒在了MySQL上面
单调栈
基于AWS构建云上数仓第一步:云平台的基础概念
Go-Excelize API源码阅读(五)—— Close()
怎样选择一个好的SaaS知识库工具?
LeetCode做题小结
golang单元测试:testing包的基本使用
使用.NET简单实现一个Redis的高性能克隆版(四、五)
HarmonyOS - 基于ArkUI (JS) 实现图片旋转验证
国产抗新冠口服药每瓶不超300元/ 我国IPv6网络全面建成/ 谷歌入局折叠屏手机...今日更多新鲜事在此...
InfluxDB语法
IDEA工具常用配置
哈希表
PHP 变量注释/**@var*/
shell脚本基础语句使用(一)
Simple prohibition of garbage collection in d
Cortex-A7 MPCore 架构
anno arm移植Qt环境后,编译正常,程序无法正常启动问题的记录
智驾科技完成C1轮融资,此前2轮已融4.5亿元