当前位置:网站首页>计算神经网络推理时间的正确方法
计算神经网络推理时间的正确方法
2022-04-23 08:37:00 【a little cabbage】
前言
在网络部署这一块中,计算网络的推理时间是至关重要的一方面,但是,正确而有意义地测量神经网络的推理时间或延迟的任务,需要深刻的理解。即使是有经验的程序员也经常会犯一些常见的错误,这些错误会导致不准确的延迟度量。
在这篇文章中,我们回顾了一些应该解决的主要问题,以便正确地测量延迟时间。我们回顾了使GPU执行独特的主要过程,包括异步执行和GPU预热。然后我们共享代码样本,以便在GPU上正确地测量时间。最后,我们回顾了在gpu上量化推理时间时人们常犯的一些错误。
参考:The Correct Way to Measure Inference Time of Deep Neural Networks
异步执行
我们从讨论GPU的执行机制开始。在多线程或多设备编程中,两个独立的代码块可以并行执行;这意味着第二个代码块可能比第一个代码块先执行完成。这个过程称为异步执行。在深度学习环境中,我们经常使用这种执行,因为默认情况下GPU操作是异步的。

异步执行为深度学习提供了巨大的优势,比如可以大幅减少运行时间。例如,在多批推理时,可以在CPU上对第二个batches进行预处理,而第一个batches在GPU上forward。显然,在推理时尽可能使用异步将是有益的。
异步执行的效果对用户是不可见的,但是,当涉及到时间测量时,它可能是许多头痛的原因。当您使用Python中的“time”库计算时间时,测量将在CPU设备上执行。由于GPU的异步特性,停止计时的代码会在GPU进程完成之前执行。结果,计算的时间并不是正确的推理时间。请记住,我们想要使用异步,在这篇文章的后面,我们将解释如何正确地度量时间,尽管有异步进程。
GPU warm-up
现代GPU设备可以存在于几种不同的电源状态之一。当GPU不被用于任何目的,并且持久化模式(即保持GPU打开)不被启用时,GPU会自动将其电源状态降低到非常低的水平,有时甚至完全关闭。在低功耗状态下,GPU会关闭不同的硬件,包括内存子系统、内部子系统,甚至是计算核心和缓存。
任何试图与GPU交互的程序的调用都会导致驱动加载和/或初始化GPU。这个驱动程序加载行为是值得注意的。触发GPU初始化的应用程序可能会产生高达3秒的延迟,这是由于错误纠正代码的擦洗行为。例如,如果我们测量网络推理时间,推理一个例子需要10毫秒,推理1000个例子可能会导致我们的大部分运行时间浪费在初始化GPU上。当然,我们不想测量这些影响因素,因为测量的时间并不准确。这不能反映GPU已经初始化或工作在持久化模式下的生产环境。
下面,让我们看看如何在测量时间时克服GPU的初始化。
正确测量推理时间的方法
下面时pytorch正确测量推理时间的代码块。这里我使用Efficient-net-b0网络,也可以使用其它任何网络。在代码中,我们处理上面描述的两个注意事项。在我们进行任何时间测量之前,我们通过网络运行一些虚拟的例子来做一个“GPU warm-up”。这将自动初始化GPU,并防止它进入节电模式时,当我们测量时间时。接下来,我们使用tr.cuda.event在GPU上测量时间,这里我们使用torch.cuda.synchronize()是至关重要的。这行代码执行主机和设备(即GPU和CPU)之间的同步,因此,只有在GPU上运行完进程后,才会进行时间记录。这克服了不同步执行的问题。
model = EfficientNet.from_pretrained(‘efficientnet-b0’)
device = torch.device(“cuda”)
model.to(device)
dummy_input = torch.randn(1, 3,224,224,dtype=torch.float).to(device)
starter, ender = torch.cuda.Event(enable_timing=True), torch.cuda.Event(enable_timing=True)
repetitions = 300
timings=np.zeros((repetitions,1))
#GPU-WARM-UP
for _ in range(10):
_ = model(dummy_input)
# MEASURE PERFORMANCE
with torch.no_grad():
for rep in range(repetitions):
starter.record()
_ = model(dummy_input)
ender.record()
# WAIT FOR GPU SYNC
torch.cuda.synchronize()
curr_time = starter.elapsed_time(ender)
timings[rep] = curr_time
mean_syn = np.sum(timings) / repetitions
std_syn = np.std(timings)
print(mean_syn)
测量时间时常见的错误
当我们计算网络的推理时间是,我们的目标是只计算前向推理的时间。通常,即使是专家,也会在他们的测量中犯某些常见的错误。下面是常见错误的举例:
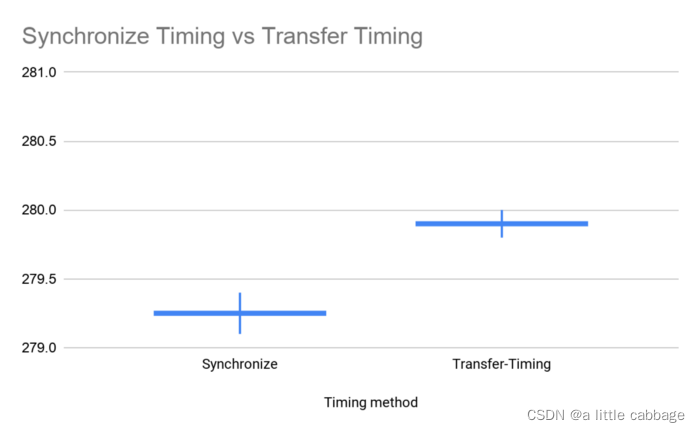
- 测量包括了CPU和GPU之间的数据传输。这通常是在CPU上创建一个张量,然后在GPU上执行推理时无意中完成的。这个内存分配需要相当长的时间。这个错误对测量的平均值和方差的影响如下:
- 没有使用GPU warm-up。如上所述,第一次在GPU上运行是会初始化。GPU初始化需要3秒。
- 使用标准的CPU计时。最常见的错误是在没有同步的情况下测量时间。甚至有经验的程序员也会使用下面的代码。当然,这完全忽略了前面提到的异步执行,因此输出了错误的时间。此错误对测量值均值和方差的影响如下:

s = time.time()
_ = model(dummy_input)
curr_time = (time.time()-s )*1000
- 只进行一次推理。与计算机科学中的许多过程一样,神经网络的前馈具有(小)随机成分。运行时的差异可能非常大,尤其是在测量低延迟网络时。为此,必须在多个示例中运行网络(即多进行基础推理)然后计算平均的结果。
版权声明
本文为[a little cabbage]所创,转载请带上原文链接,感谢
https://blog.csdn.net/weixin_43937959/article/details/124301298
边栏推荐
- 什么是RPC
- PDF with watermark
- After a circle, I sorted out this set of interview questions..
- Failed to convert a NumPy array to a Tensor(Unsupported Object type int)
- Notes on 30 steps of introduction to Internet of things of yangtao electronics STM32 III. Explanation of new cubeide project and setting
- 面了一圈,整理了这套面试题。。
- JSP page coding
- okcc呼叫中心外呼系统智能系统需要用多大的盘存录音?
- Excle plus watermark
- DOM 学习之—添加+-按钮
猜你喜欢

Failed to convert a NumPy array to a Tensor(Unsupported Object type int)

增强现实技术是什么?能用在哪些地方?

flask项目跨域拦截处理以及dbm数据库学习【包头文创网站开发】

数据可视化:使用Excel制作雷达图
项目上传部分

STM32使用HAL库,整体结构和函数原理介绍

idea配置连接远程数据库MySQL,或者是Navicat连接远程数据库失败问题(已解决)

'恶霸' Oracle 又放大招,各大企业连夜删除 JDK。。。

Yangtao electronic STM32 Internet of things introduction 30 steps notes 1. The difference between Hal library and standard library

测试你的机器学习流水线
随机推荐
How to encrypt devices under the interconnection of all things
Notes on 30 steps of introduction to Internet of things of yangtao electronics STM32 III. Explanation of new cubeide project and setting
Add listening event to input element
Navicat远程连接mysql
Input / output system
What is RPC
bashdb下载安装
洋桃电子STM32物联网入门30步笔记二、CubeIDE下载、安装、汉化、设置
vmware 搭建ES8的常见错误
Notes on English class (4)
《深度学习》学习笔记(八)
测试你的机器学习流水线
SYS_CONNECT_BY_PATH(column,'char') 结合 start with ... connect by prior
Flash project cross domain interception and DBM database learning [Baotou cultural and creative website development]
【精品】利用动态代理实现事务统一管理 二
2022-04-22 OpenEBS云原生存储
Swagger document export custom V2 / API docs interception
第一性原理 思维导图
STM32F103ZET6【标准库函数开发】----库函数介绍
应纳税所得额