当前位置:网站首页>浅谈 Redis 的底层数据结构
浅谈 Redis 的底层数据结构
2022-08-08 13:56:00 【daydreamed】
浅谈 Redis 的底层数据结构
1、简介
Redis 的底层数据结构 主要包括以下六种:
- 简单动态字符串
- 双向链表
- 压缩列表
- 字典
- 跳跃表
- 整数集合
补充:
Redis 五大基本类型所使用的底层数据结构:
- string(简单动态字符串)
- list(双向链表、压缩列表)
- 当 list 保存的元素数量不超过 128 个,且元素长度都小于 64 字节 采用 压缩列表 作为底层实现,否则 采用 双向链表 作为底层实现
- hash(压缩列表、字典)
- 当 hash 保存的键值对数量小于 512个,且键和值的字符串长度都小于 64 字节 采用 压缩列表 作为 底层实现,否则 采用 字典 作为底层实现
- set(整数集合)
- zset(压缩列表、字典、跳跃表)
- 当 zset 保存的元素数量不超过 128 个,且元素长度都小于 64 字节 采用 压缩列表 作为底层实现,否则 采用 字典、跳跃表 作为底层实现
扩展:
redisObject 的数据结构如下:
typedef struct redisObject {
// 数据类型 (基本数据结构: string、list、hash等等)
unsigned [type] 4;
// 内部编码 (底层数据结构: 简单动态字符串、双向链表、字典等等)
unsigned [encoding] 4;
// 当前对象可以保留的时长
unsigned [lur] REDIS_LRU_BITS;
// 对象引用计数,用于 GC
int refcount;
// 对象实际地址指针
void *ptr;
}robj;
2、简单动态字符串(Simple Dynamic String,简称 SDS)
Redis 没有直接使用 C语言 传统的字符串,而是自己构建了一种名为 简单动态字符串(Simple Dynamic String)的抽象类型,并将 SDS 作为 Redis 的默认字符串表示。
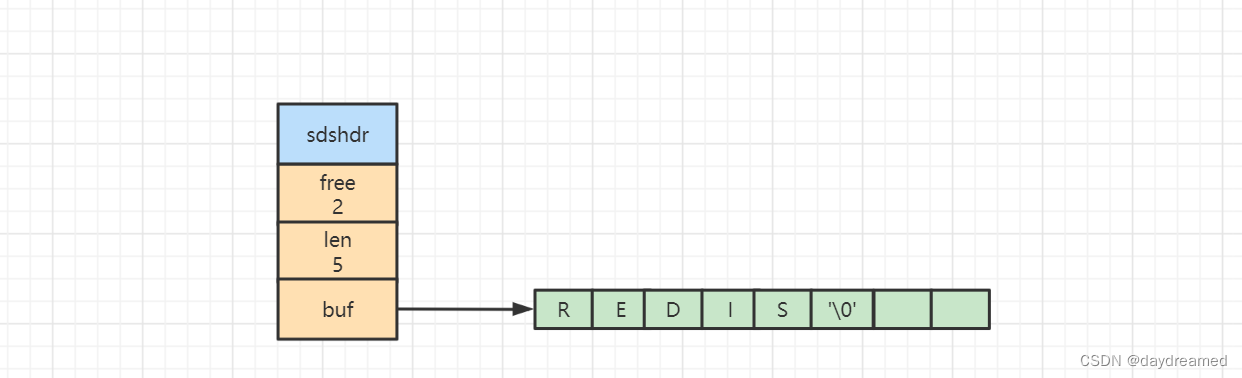
SDS 的数据结构如下:
struct sdshdr{
// 记录 buf 数组中已使用字节的数量
// 等于 SDS 所保存字符串的长度
int len;
// 记录 buf 数组中未使用字节的数量
int free;
// 字节数组,用于保存字符串
char buf[];
}
那为什么要使用 SDS 作为 字符串的默认实现呢?
SDS 获取 字符串长度 的 时间复杂度为 常数
由于 C语言 字符串 并不记录 自身的长度信息,所以 要想获取 字符串的长度 则必须 遍历整个字符串,时间复杂度为 O(N);
而 SDS 只需要获取 len 属性的值 就可以得到 字符串的长度,时间复杂度为 O(1)。
SDS 杜绝了 缓存区溢出
在对 C语言 字符串 进行修改时,如果没有事先手动 重新分配空间 的话,可能会造成数据溢出。
当 SDS API 需要对 SDS 进行修改时,API 会先检查 SDS 的空间是否满足修改所需的要求,如果不满足,API 会自动将 SDS 的空间扩展至所需大小,然后才执行实际的修改操作。
减少内存重分配次数
SDS 通过 空间预分配 和 惰性空间释放 两种优化策略 来减少内存重分配次数:
空间预分配
当进行 字符串扩容操作 时,Redis 会同时分配 必要空间 和 额外未使用空间(长度 存储在 free 属性),减少了连续执行字符串扩展操作所需的内存分配次数。
惰性空间释放
当进行 字符串缩容操作 时,Redis 不会立即回收 缩短后多余的空间,而是 使用 free 属性 记录起来,等待将来使用。
二进制安全
SDS API 会以处理二进制的方式来处理 SDS 存放在 buf 数组中的数据,Redis 不会对其中的数据做任何的限制、过滤或者假设(如:使用 len 属性的值 而不是 空字符 来判断字符串是否结束),所以 SDS 的 API 都是 二进制安全的。
兼容部分 C语言 字符串函数
SDS 在 字符串末尾 添加一个空字符(‘\0’)是为了 兼容 一些 C语言 字符串函数库(如:字符串对比函数 <string.h>/strcasecmp() )。
3、双向链表
双向链表数据结构如下:
typedef struct list {
// 表头节点
listNode *head;
// 表尾节点
listNode *tail;
// 链表所包含的节点数量
unsigned long len;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void *(*free)(void *ptr);
// 节点值对比函数
int *(*match)(void *ptr,void *key);
} list;
链表节点数据结构如下:
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value
}listNode;
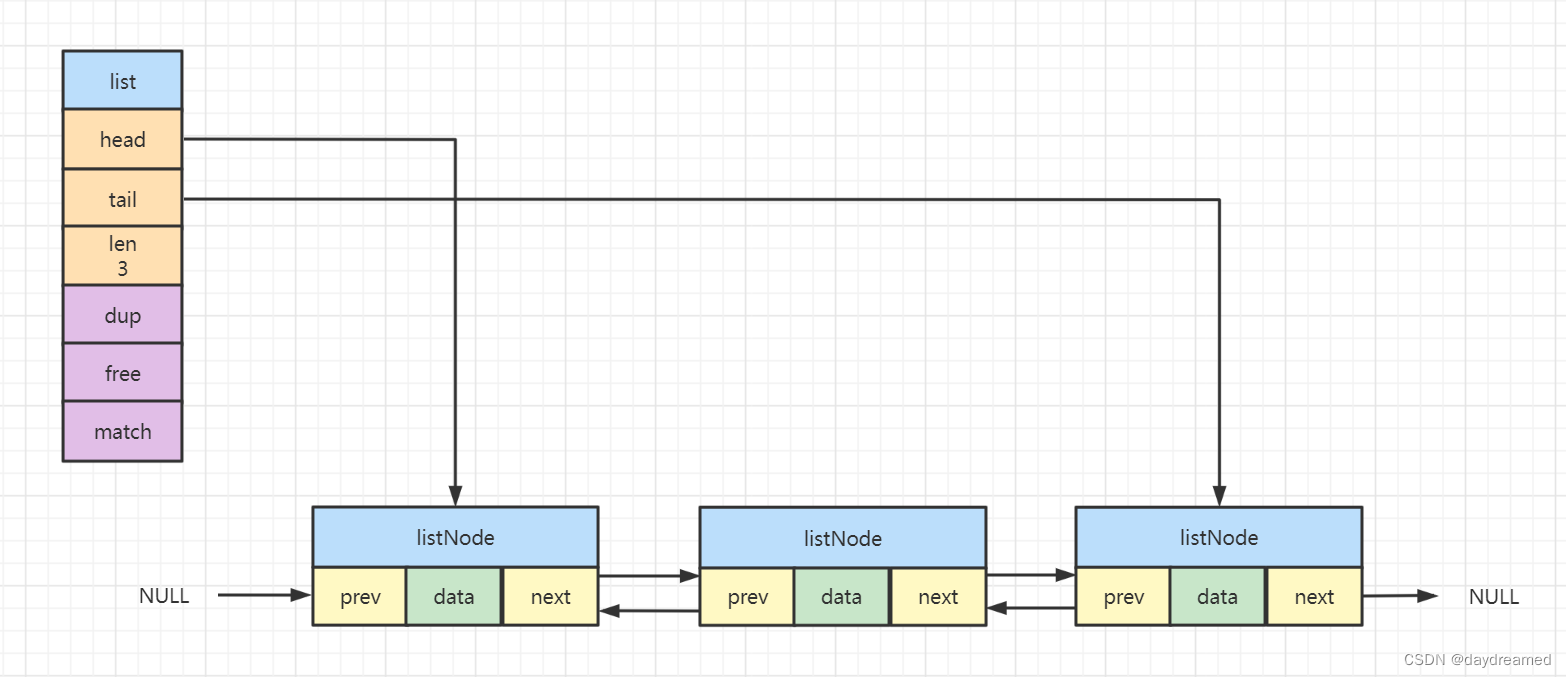
Redis 链表实现的特性:
双端
链表节点带有 prev 和 next 指针,获取 某个节点的 前置节点 和 后置节点 的 时间复杂度 都是 O(1)。
无环
表头节点的 prev 指针 和 表尾节点的 next 指针 都指向 NULL,对链表的访问以 NULL 为终点。
带表头指针和表尾指针
通过 list 结构的 head 指针 和 tail 指针,程序获取 链表 的 表头节点 和 表尾节点 的 时间复杂度 为 O(1)。
带链表长度计数器
程序使用 list 结构的 len 属性来对 list 持有的 链表节点 进行计数,程序获取 链表中节点数量 的 时间复杂度为 O(1)。
多态
链表节点 使用 void* 指针 来保存节点值,并且可以通过 list 结构 的 dup、free、match 三个属性为节点值 设置 类型特定函数,所以链表可以用于保存各种不同类型的值。
4、压缩列表
压缩列表(ziplist),是 Redis 为了 节约内存 而设计的一种 线性数据结构,它是由 一系列 具有特殊编码的连续内存块 构成的。一个压缩列表 可以包含 任意多个节点,每个节点 可以保存 一个字节数组 或 一个整数值。
压缩列表的数据结构如下:

该结构当中的字段含义如下表所示:
| 属性 | 类型 | 长度 | 说明 |
|---|---|---|---|
| zlbytes | uint32_t | 4字节 | 压缩列表占用的内存字节数 |
| zltail | uint32_t | 4字节 | 压缩列表表尾节点距离列表起始地址的偏移量(单位字节) |
| zllen | uint16_t | 2字节 | 压缩列表包含的节点数量,等于UINT16_MAX时,需遍历列表计算真实数量 |
| entryX | 列表节点 | 不固定 | 压缩列表包含的节点,节点的长度由节点所保存的内容决定 |
| zlend | uint8_t | 1字节 | 压缩列表的结尾标识,是一个固定值 0xFF |
压缩列表节点的数据结构如下:
previous_entry_length(pel)属性 以字节为单位,记录当前节点的前一节点的长度,其自身占据 1 字节或 5 字节:
- 如果前一节点的长度小于 254 字节,则 “pel” 属性的长度为 1 字节,前一节点的长度就保存在这一个字节内;
- 如果前一节点的长度达到 254 字节,则 “pel” 属性的长度为 5 字节,其中第一个字节被设置为 0xFE,之后的四个字节用来保存前一节点的长度;
基于 “pel” 属性,程序便可以通过指针运算,根据当前节点的起始地址计算出前一节点的起始地址,从而实现从表尾向表头的遍历操作。
content 属性 负责保存节点的值(字节数组或整数),其类型和长度则由 encoding 属性决定,它们的关系如下:
| encoding | 长度 | content |
|---|---|---|
| 00 xxxxxx | 1字节 | 最大长度为 2^6 -1 的字节数组 |
| 01 xxxxxx bbbbbbbb | 2字节 | 最大长度为 2^14-1 的字节数组 |
| 10 __ bbbbbbbb … … … | 5字节 | 最大长度为 2^32-1 的字节数组 |
| 11 000000 | 1字节 | int16_t 类型的整数 |
| 11 010000 | 1字节 | int32_t 类型的整数 |
| 11 100000 | 1字节 | int64_t 类型的整数 |
| 11 110000 | 1字节 | 24位 有符号整数 |
| 11 111110 | 1字节 | 8位 有符号整数 |
| 11 11xxxx | 1字节 | 没有 content 属性,xxxx 直接存 [0,12] 范围的整数值 |
5、字典
字典(dict)又称为散列表,是一种用来存储键值对的数据结构。C语言 没有内置这种数据结构,所以Redis构建了自己的字典实现。
字典的数据结构如下:
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *data;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int trehashidx; /*rehashing not in progree if rehashidx == -1*/
} dict;
哈希表的数据结构如下:
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;
哈希表节点的数据结构如下:
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_tu64;
int64_ts64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
字典 主要由三个结构体:字典(dict)、哈希表(dictht)、哈希表节点(dictEntry)进行实现。
一个字典 由 两个哈希表 构成
一个哈希表 由 多个哈希表节点 构成
一个哈希表节点 保存 一个键值对
这三个结构体的关系如下图所示:

补充:dict 有 两个 dictht,一个用于存储数据,一个用于重新散列(rehash)
当哈希表保存的键值对 数量过多或过少 时,需要对 哈希表的大小 进行 扩展或收缩 操作,在 Redis 中,扩展和收缩 哈希表 是通过 rehash 实现的,执行 rehash 的大致步骤如下:
为 字典的 ht[1] 哈希表 分配内存空间
如果执行的是 扩展操作,则 ht[1] 的大小为 第1个大于等于 ht[0].used*2 的 2n;如果执行的是 收缩操作,则 ht[1] 的大小为 第1个大于等于 ht[0].used 的 2n。
将存储在 ht[0] 中的数据迁移到 ht[1] 上
重新计算 键的 哈希值 和 索引值,然后将 键值对 放置到 ht[1] 哈希表 的指定位置上。
将 字典的 ht[1] 哈希表 晋升为 默认哈希表
迁移完成后,清空 ht[0],再交换 ht[0] 和 ht[1] 的值,为下一次 rehash 做准备。
补充:
当满足以下任何一个条件时,程序会自动开始对哈希表执行扩展操作:
- 服务器目前 没有执行 bgsave 或 bgrewriteof 命令,并且 哈希表的负载因子 大于等于 1
- 服务器目前 正在执行 bgsave 或 bgrewriteof 命令,并且 哈希表的负载因子 大于等于 5
为了避免 rehash 对服务器性能造成影响,rehash 操作不是一次性地完成的,而是分多次、渐进式地完成的,渐进式 rehash 的详细过程如下:
为 ht[1] 分配空间,让 字典 同时持有 ht[0] 和 ht[1] 两个哈希表
在 字典 中的 索引计数器 rehashidx 设置为 0,表示 rehash 操作正式开始
在 rehash 期间,每次对字典执行 添加、删除、修改、查找操作 时,程序除了执行指定的操作外,还会顺带将 ht[0] 中位于 rehashidx 上的所有键值对迁移到 ht[1] 中,再将 rehashidx 的值加 1
随着 字典 不断被访问,最终在某个时刻,ht[0] 上的所有键值对都被迁移到 ht[1] 上,此时程序将 rehashidx 属性值设置为 -1,标识 rehash 操作完成
补充:
rehash 期间,字典同时持有两个哈希表,此时的访问将按照如下原则处理:
新添加的键值对,一律被保存到 ht[1] 中
删除、修改、查找等其他操作,会在两个哈希表上进行,即程序先尝试去 ht[0] 中访问要操作的数据,若不存在则到 ht[1] 中访问,再对访问到的数据做相应的处理
6、跳跃表
跳跃表 是一种 有序 数据结构,它通过在 每个节点 中维持 多个指向其他节点的指针,从而达到快速访问节点的目的,跳跃表 的 查找复杂度为 平均 O(logN),最坏 O(N)。
补充:
有序链表 插入、删除的复杂度为 O(1),而查找的复杂度为 O(N)。例:若要查找值为60的元素,需要从第 1 个元素依次向后比较,共需比较 6 次才行,如下图:

跳跃表 是从 有序链表 中选取部分节点,组成一个新链表,并以此作为 原始链表 的 一级索引,再从 一级索引 中选取部分节点,组成一个新链表,并以此作为 原始链表 的 二级索引。以此类推,可以有多级索引,如下图:
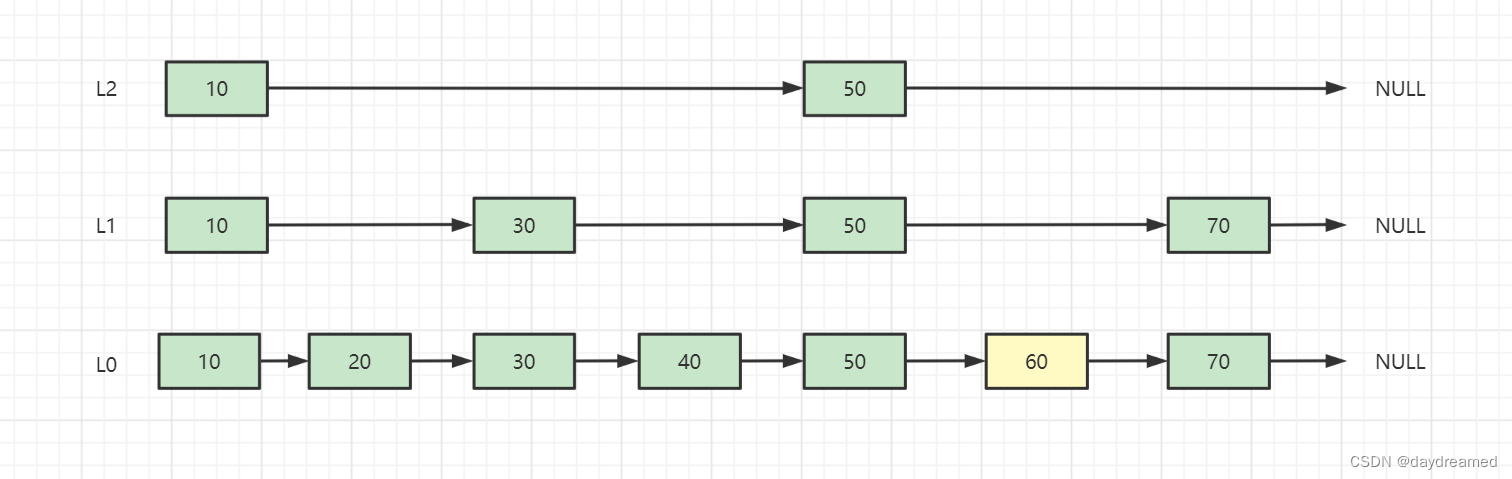
跳跃表 在查找时,优先从 高层 开始查找,若 next 节点值大于目标值,或 next 指针 指向 NULL,则从当前节点 下降一层 继续向后查找,这样便可以提高查找的效率了。
跳跃表的数据结构如下:
typedef struct zskiplist {
// 表头节点和表尾节点
struct skiplistNode *head, *tail;
// 表中节点的数量
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist;
跳跃表节点的数据结构如下:
typedef struct zskiplistNode {
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度,记录两个节点之间的距离
unsigned int span;
} level[];
// 后退指针
struct zskiplistNode *backward;
// 分值
double score;
// 成员对象
robj *obj;
} zskiplistNode;
跳跃表 主要由两个结构体:zskiplist、zskiplistNode 进行实现。

补充:
- 节点层高的范围是 [1,ZSKIP_MAXLEVEL],在 Redis 6 中层高的最大值为 32
- 头节点是特殊节点,它的层高为 32,不存储数据和分值,也不计入跳跃表的总长度和高度
- 创建节点时,程序会生成一个 [1,32] 之间的随机值作为该节点的层高,并且生成算法符合幂次定律(越大的数出现的概率越小)
7、整数集合
整数集合是 Redis 用于保存 整数值 的 集合抽象 数据结构,它可以保存类型为 int16_t 、int32_t 或者 int64_t 的整数值,并且保证集合中不出现重复值。
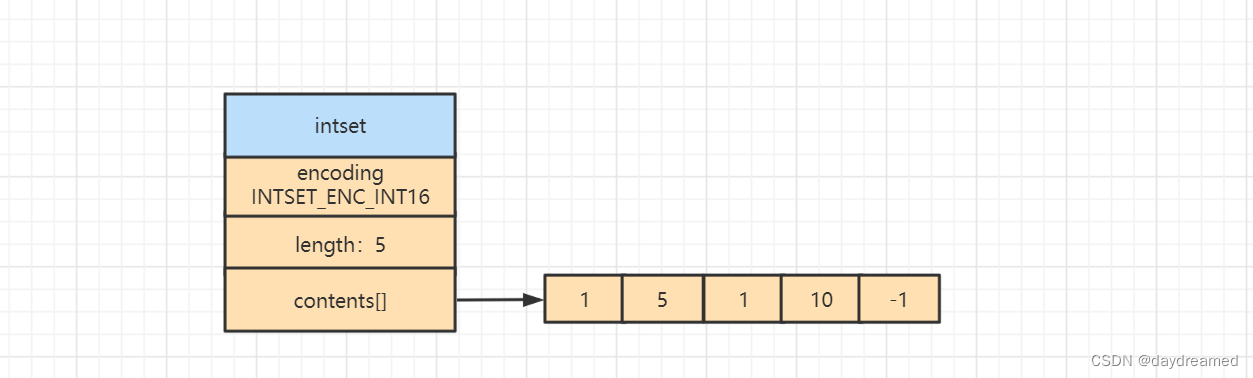
整数集合的数据结构如下:
typedef struct intset {
// 编码方式:NTSET_ENC_INT16、INTSET_ENC_INT32、INTSET_ENC_INT64
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
当 新添加的元素的类型 比 整数集合 现有的元素类型大(如:新元素 – int32,整数集合元素 – int16)时,这时 整数集合 就需要进行升级。(Redis 的整数集合 不支持 降级。)
整数集合的升级步骤:
- 根据新元素的类型,扩展 整数集合数组 的空间,并为新元素分配空间
- 将 数组的所有元素 都转换成 与新元素相同的类型
- 将 新元素 添加到 数组中
边栏推荐
猜你喜欢

HackTheBox | Horizontall
华为云云数据库RDS MySQL 版初试探【华为云至简致远】
Implement a customized pin code input control
QtWebassembly遇到的一些报错问题及解决方案
看到这个应用上下线方式,不禁感叹:优雅,太优雅了!

Tsinghua | GLM-130B: An Open Bilingual Pre-training Model

如果Controller里有私有的方法,能成功访问吗?

代码随想录笔记_动态规划_322零钱兑换

活动报名| StreamNative 受邀参与 ITPUB 在线技术沙龙
清华|GLM-130B:一个开放的双语预训练模型
随机推荐
【小码匠自习室】ABC258-A 代码写的啰嗦了
serialize serialize native method
R语言使用位置索引筛选dataframe的数据列:筛选单个数据列、筛选多个数据列、列表表达式方法、矩阵式下标方法
Thesis understanding: "Self-adaptive loss balanced Physics-informed neural networks"
idea 好工具
R语言ggplot2可视化:基于aes函数中的fill参数和shape参数自定义绘制分组折线图并添加数据点(散点)、设置可视化图像的主题为theme_gray
【第2天】SQL快速入门-条件查询(SQL 小虚竹)
qtwebapp库的编译及简单使用
全网最全的PADS 9.5安装教程与资源包
什么样的程序员在35岁依然被公司抢着要?打破程序员“中年危机”
LeetCode简单题之统计星号
R语言ggpubr包的ggsummarystats函数可视化分面箱图(通过ggfunc参数和facet.by参数设置)、添加描述性统计结果表格、palette参数配置不同水平可视化图像和统计值的颜色
变量和函数的声明提前
leetcode 155. Min Stack最小栈(中等)
又一个千亿市场,冰淇淋也成了创新试验田
【SWT】创建自己的SWT组件
Implement a customized pin code input control
论文理解:“Self-adaptive loss balanced Physics-informed neural networks“
兔起鹘落全端涵盖,Go lang1.18入门精炼教程,由白丁入鸿儒,全平台(Sublime 4)Go lang开发环境搭建EP00
机器学习+深度学习笔记(持续更新~)