当前位置:网站首页>Basic regular expression
Basic regular expression
2022-04-23 14:21:00 【Small ash pier】
Basic regular expressions
One 、 Metacharacters
.: Match any single character , But it can't match the newline \n*: Match the previous character 0 Times or times?: Match the previous character 0 Once or once+: Match the previous character 1 More than once{M,N}: Match the previous character at least M, most N Time{M,}: Match the previous character at most N Time ( At least, of course 0 Time ){M}: Match the previous character exactly M Time
Anchoring : Anchoring means to match the position , Instead of matching character entities
^: Match the beginning of the line , Note that the match is the location , It's not a character$: Match end of line position , Note that the match is the location , It's not a character
Special and common combinations of regular expressions :
^$: It means matching blank lines.*: Matches any character of any length , But it can't match the newline .
Two 、 brackets
Square brackets indicate matching any , Generally, it is related to the sorting rules of character sets , Different tools may adopt different sorting rules .
[abcd...]: Match any character in brackets[^abcd...]: Refuse to match any character in brackets[a-z]: Match the letter a To z[A-Z]: Match the letter A To Z[0-9]: matching 0-9, That is, matching numbers
About the sorting of letters :
- perl in ,A-Z be ranked at a In front of , therefore [A-z] Represents all uppercase and lowercase letters
- grep in ,A-Z be ranked at z Behind , therefore [a-Z] Represents all uppercase and lowercase letters
- There are also tools , The case sorting rule is aAbBcC…zZ, therefore [a-C] Express aAbBcC common 6 Letters
3、 ... and 、 Character class
Is a specially named sequence of brackets ; Except for character classes , And equivalence classes 、 Sorting class , But it's basically useless , Only character classes .
[:alpha:]: Match the letter , Equivalent to[a-zA-Z][:digit:]: Match the Numbers , Equivalent to[0-9][:xdigit:]: Matching hexadecimal numbers , Equivalent to[0-9a-fA-F][:upper:]: Match capital letters , Equivalent to[A-Z][:lower:]: Match lowercase letters , Equivalent to[a-z][:alnum:]: Match numbers or letters , Equivalent to[0-9a-zA-Z][:blank:]: Match blanks , Include spaces and tabs[:space:]: Match spaces , Including Spaces 、 tabs 、 A newline 、 Various types of whitespace such as carriage return[:punct:]: Match punctuation . Include :! ' "# $ % & ( ) * + , . - _ / : ; < = > ? @ [ \ ] ^ { | } ~`[:graph:]: Drawing class . Include : Case letters 、 Numbers and punctuation . Equivalent to[:alnum:]+[:punct:][:print:]: Print character class . Include : Case letters 、 Numbers 、 Punctuation and spaces . Equivalent to[:alnum:]+[:punct:]+space[:cntrl:]: Control character class . stay ASCII in , The octal code of these characters starts from 000 To 037, It also includes 177(DEL)
It should be noted that , Usually, character classes are in real use , A square bracket will be added , for example [[:alpha:]]. That's why , Because these character classes are just a named character set . for example [:lower:] The corresponding character set is a-z, instead of [a-z], So you want it to represent any of these named character classes , You need to add a layer of parentheses [[:lower:]], It is equivalent to [a-z]. It may be more helpful to understand why two brackets should be added when using character classes [^[:lower:]], It means that it does not contain any lowercase letters .
Four 、 Backslash sequence
Different tools , Different versions of the same tool , Different backslash sequence capabilities are supported . Common sequences are listed below .
The following words , Generally speaking, it only contains numbers 、 Letters and underscores , namely [_0-9a-zA-Z].
The following backslash sequences , Basically all tools support :
\b: Match empty characters at word boundaries\B: Matches empty characters at non word boundaries\<: Match the empty character at the beginning of the word\>: Match the empty character at the end of the word\w: Match word components , Equivalent to[_[:alnum:]]\W: Match non word components , Equivalent to[^_[:alnum:]]
Here are a few , Some tools do not support , but perl All support :
\s: Matching blank character , Equivalent to[[:space:]]\S: Match non white space characters , Equivalent to[^[:space:]]\d: Match the Numbers , Equivalent to[0-9]\D: Match non numeric , Equivalent to[^0-9]
Due to the metacharacter . Default cannot match newline , So when you need to match the newline character , Special combinations can be used [\d\D] To replace ., let me put it another way , If you want to match any character of any length , Can be replaced by [\d\D]*, Of course , The premise is that we must support \d and \D Two backslash sequences .
5、 ... and 、 Group capture and back reference
In basic regularity , Use parentheses to group matches and save them temporarily , After grouping, there will be a grouping number , You can use backslashes to add numbers \N Back reference these groups .
The way of grouping numbering is to calculate the number of parentheses from left to right , No matter what , The group corresponding to the first left bracket must be number 1, use \1 To quote , The group corresponding to the second left bracket must be number 2, use \2 To quote , And so on .
for example grep Packet capture : Match two consecutive identical letters .
echo "abcddefg" | grep -E "(.)\1"
It can be considered that grouping is the process of variable assignment . for example , The matching process of the above example is as follows :
1. Match the first letter a, Put into group , That is, assign a value to a variable ( Suppose the variable is named $1), namely $1="a", Then continue to perform the reverse reference of the regular expression matching process , It quotes $1, So it means the first letter a And after the letter a, So the match failed .
2. Match the second letter b, Put into group , namely $1="b", Then match the last letter , So the match failed .
3. Letter c The same is true of .
4. Match the letter d, Put into group , namely $1="d", Then match the last letter , The match was found to be successful , therefore $1 To be preserved .
5. Has been matched successfully , Then the end .
For tools that use only basic regularity , Generally, you can only quote \1 To \9 common 9 A back reference , At most, you can provide an additional back reference to all the matching contents ( for example sed Provided &). For exceeding 10 Groups of , Using basic regular tools is generally powerless .
also , Basic regularization simply captures the content that the group matches , Lost after the regular operation . But for a complete programming language , It's not enough , Almost all programming languages ( Such as perl/java/python etc. ) Will save the regular grouping matching content as a variable , They can be modified again even after the regular reference . For example, the letters captured by grouping in the above example d, If replaced perl, Even after this matching process , You can still refer to this group .
6、 ... and 、 A choice
pattern1 | pattern2: Match the left side of the vertical line , Or match the right side of the vertical line
About the structure of one out of two , Several points need to be explained :
- Because the vertical bar metacharacter has low priority , therefore
ab|cdThe match is "ab" or "cd", instead of abd or acd. - Successfully matched the left , You won't match the right again .
- Back reference failure problem : A vertical bar separates the groups on both sides , The group on the right can never refer back to the group on the left
Choose one of the two structures , Two typical examples of back reference problems :
for example a(.)|b\1 Will not match "ba", Because if you evaluate the left, you won't evaluate the right .
for example ([ac])e\1|b([xyz])\2t The left side of the can match aea or cec, But can't match cea or aec, The right side can match bxxt or byyt or bzzt. But if it will \2 Switch to \1, namely ([ac])e\1|b([xyz])\1t, Will not match b[xyz]at or b[xyz]ct, Because the first grouping bracket is on the left , Unable to participate in the regular evaluation on the right .
Reprint :https://www.cnblogs.com/f-ck-need-u/p/9621130.html
版权声明
本文为[Small ash pier]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231409158988.html
边栏推荐
- Logback logger and root
- 修改Firebase Emulators的默认侦听IP
- 返回数组排序后下标
- TLS/SSL 协议详解 (28) TLS 1.0、TLS 1.1、TLS 1.2之间的区别
- Get the thread return value. Introduction to the use of future interface and futuretask class
- 如何轻松做好一个项目
- C语言知识点精细详解——数据类型和变量【2】——整型变量与常量【1】
- Nacos作为配置中心(四) 使用Demo
- 逻辑卷创建与扩容
- 统信UOS卸载php7.2.24,安装php7.4.27 ;卸载再安装为PHP 7.2.34
猜你喜欢
循环队列的基本操作(实验)
Pass in external parameters to the main function in clion
Storage path of mod subscribed by starbound Creative Workshop at Star boundary

TLS/SSL 协议详解 (30) SSL中的RSA、DHE、ECDHE、ECDH流程与区别

字节面试编程题:最小的K个数
Nacos uses demo as configuration center (IV)
線程組ThreadGroup使用介紹+自定義線程工廠類實現ThreadFactory接口

Qt界面优化:Qt去边框与窗体圆角化
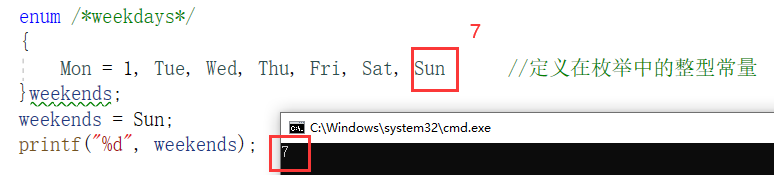
C语言知识点精细详解——数据类型和变量【2】——整型变量与常量【1】
API Gateway/API 网关(二) - Kong的使用 - 负载均衡Loadbalance
随机推荐
Man man notes and @ reboot usage of crontab
操作系统常见面试题目:
ActiveMQ Basics
进入新公司,运维工程师从下面这几项了解系统的部署
快速搞懂线程实现的三种方式
Storage path of mod subscribed by starbound Creative Workshop at Star boundary
TUN 设备原理
JS progress bar, displaying the loading progress
网页自适应,等比缩放
C语言知识点精细详解——初识C语言【1】——你不能不知的VS2022调试技巧及代码实操【1】
Introduction to the use of countdownlatch and cyclicbarrier for inter thread control
SSH 通过跳板机连接远程主机
MySQL-InnoDB-事务
LLVM - 生成 if-else 以及 PH
Docker (V) MySQL installation
Uni app message push
Gif to still image processing
微信小程序将原生请求通过es6的promise来进行优化
修改Firebase Emulators的默认侦听IP
sar命令详解