当前位置:网站首页>Task02:PyTorch进阶训练技巧
Task02:PyTorch进阶训练技巧
2022-08-08 06:29:00 【Never give up】
文章目录
前言
本篇内容主要是有关PyTorch进阶训练技巧方面的内容,其中包括了自定义损失函数、动态调整学习率、模型微调、半精度训练。
一、自定义损失函数
PyTorch在torch.nn模块为我们提供了许多常用的损失函数,比如:MSELoss,L1Loss,BCELoss… 但是随着深度学习的发展,出现了越来越多的非官方提供的Loss,比如DiceLoss,HuberLoss,SobolevLoss… 这些Loss Function专门针对一些非通用的模型,PyTorch不能将他们全部添加到库中去,因此这些损失函数的实现则需要我们通过自定义损失函数来实现。另外,在科学研究中,我们往往会提出全新的损失函数来提升模型的表现,这时我们既无法使用PyTorch自带的损失函数,也没有相关的博客供参考,此时自己实现损失函数就显得尤为重要了。
6.1.1 以函数方式定义
损失函数仅仅是一个函数而已,因此我们可以通过直接以函数定义的方式定义一个自己的函数,如下所示:
def my_loss(output, target):
loss = torch.mean((output - target)**2)
return loss
6.1.2 以类方式定义
虽然以函数定义的方式很简单,但是以类方式定义更加常用,在以类方式定义损失函数时,我们发现Loss函数部分继承自_loss, 部分继承自_WeightedLoss, 而_WeightedLoss继承自_loss,_loss继承自 nn.Module。我们可以将其当作神经网络的一层来对待,同样地,我们的损失函数类就需要继承自nn.Module类,在下面的例子中我们以DiceLoss为例向大家讲述。
Dice Loss是一种在分割领域常见的损失函数,定义如下:
D S C = 2 ∣ X ∩ Y ∣ ∣ X ∣ + ∣ Y ∣ DSC = \frac{2|X∩Y|}{|X|+|Y|} DSC=∣X∣+∣Y∣2∣X∩Y∣
实现代码如下:
class DiceLoss(nn.Module):
def __init__(self,weight=None,size_average=True):
super(DiceLoss,self).__init__()
def forward(self,inputs,targets,smooth=1):
inputs = F.sigmoid(inputs)
inputs = inputs.view(-1)
targets = targets.view(-1)
intersection = (inputs * targets).sum()
dice = (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth)
return 1 - dice
# 使用方法
criterion = DiceLoss()
loss = criterion(input,targets)
除此之外,常见的损失函数还有BCE-Dice Loss,Jaccard/Intersection over Union (IoU) Loss,Focal Loss…
class DiceBCELoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(DiceBCELoss, self).__init__()
def forward(self, inputs, targets, smooth=1):
inputs = F.sigmoid(inputs)
inputs = inputs.view(-1)
targets = targets.view(-1)
intersection = (inputs * targets).sum()
dice_loss = 1 - (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth)
BCE = F.binary_cross_entropy(inputs, targets, reduction='mean')
Dice_BCE = BCE + dice_loss
return Dice_BCE
--------------------------------------------------------------------
class IoULoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(IoULoss, self).__init__()
def forward(self, inputs, targets, smooth=1):
inputs = F.sigmoid(inputs)
inputs = inputs.view(-1)
targets = targets.view(-1)
intersection = (inputs * targets).sum()
total = (inputs + targets).sum()
union = total - intersection
IoU = (intersection + smooth)/(union + smooth)
return 1 - IoU
--------------------------------------------------------------------
ALPHA = 0.8
GAMMA = 2
class FocalLoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(FocalLoss, self).__init__()
def forward(self, inputs, targets, alpha=ALPHA, gamma=GAMMA, smooth=1):
inputs = F.sigmoid(inputs)
inputs = inputs.view(-1)
targets = targets.view(-1)
BCE = F.binary_cross_entropy(inputs, targets, reduction='mean')
BCE_EXP = torch.exp(-BCE)
focal_loss = alpha * (1-BCE_EXP)**gamma * BCE
return focal_loss
注:在自定义损失函数涉及到数学运算时,我们最好全程使用PyTorch提供的张量计算接口,这样就不需要我们实现自动求导功能并且我们可以直接调用cuda。
二、动态调整学习率
学习率的选择是深度学习中一个困扰人们许久的问题,学习率设置过小,会极大降低收敛速度,增加训练时间;学习率太大,可能导致参数在最优解两侧来回振荡。但是当我们选定了一个合适的学习率,经过多轮训练后,可能会出现准确率震荡或loss不再下降等情况,说明当前学习率已不能满足模型调优的需求。此时我们就可以通过适当的学习率衰减策略来改善这种现象,提高精度。这种设置方式在PyTorch中被称为scheduler。
6.2.1 使用官方scheduler
了解官方提供的API
在训练神经网络的过程中,学习率是最重要的超参数之一,作为当前较为流行的深度学习框架,PyTorch已经在torch.optim.lr_scheduler为我们封装好了一些动态调整学习率的方法供我们使用,如下面列出的这些scheduler。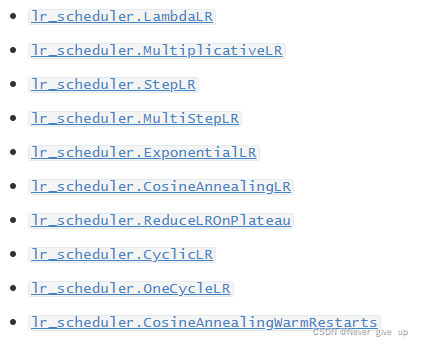
使用官方API
# 选择一种优化器
optimizer = torch.optim.Adam(...)
# 选择上面提到的一种或多种动态调整学习率的方法
scheduler1 = torch.optim.lr_scheduler....
scheduler2 = torch.optim.lr_scheduler....
...
schedulern = torch.optim.lr_scheduler....
# 进行训练
for epoch in range(100):
train(...)
validate(...)
optimizer.step()
# 需要在优化器参数更新之后再动态调整学习率
scheduler1.step()
...
schedulern.step()
注:我们在使用官方给出的torch.optim.lr_scheduler时,需要将scheduler.step()放在optimizer.step()后面进行使用。
6.2.2 自定义scheduler
虽然PyTorch官方给我们提供了许多的API,但是在实验中也有可能碰到需要我们自己定义学习率调整策略的情况,而我们的方法是自定义函数adjust_learning_rate来改变param_group中lr的值。
假设我们现在正在做实验,需要学习率每30轮下降为原来的1/10,假设已有的官方API中没有符合我们需求的,那就需要自定义函数来实现学习率的改变。
def adjust_learning_rate(optimizer, epoch):
lr = args.lr * (0.1 ** (epoch // 30))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
有了adjust_learning_rate函数的定义,在训练的过程就可以调用我们的函数来实现学习率的动态变化。
def adjust_learning_rate(optimizer,...):
...
optimizer = torch.optim.SGD(model.parameters(),lr = args.lr,momentum = 0.9)
for epoch in range(10):
train(...)
validate(...)
adjust_learning_rate(optimizer,epoch)
三、模型微调
随着深度学习的发展,模型的参数越来越大,许多开源模型都是在较大数据集上进行训练的,比如Imagenet-1k,Imagenet-11k,甚至是ImageNet-21k等。但在实际应用中,我们的数据集可能只有几千条,这时从头开始训练具有几千万参数的大型神经网络是不现实的,因为越大的模型对数据量的要求越大,过拟合无法避免。
假设我们想从图像中识别出不同种类的椅⼦,然后将购买链接推荐给用户。一种可能的方法是先找出100种常见的椅子,为每种椅子拍摄1000张不同⻆度的图像,然后在收集到的图像数据集上训练一个分类模型。这个椅子数据集虽然可能比Fashion-MNIST数据集要庞⼤,但样本数仍然不及ImageNet数据集中样本数的十分之⼀。这可能会导致适用于ImageNet数据集的复杂模型在这个椅⼦数据集上过拟合。同时,因为数据量有限,最终训练得到的模型的精度也可能达不到实用的要求。
为了应对上述问题,一个显⽽易⻅的解决办法是收集更多的数据。然而,收集和标注数据会花费大量的时间和资金。例如,为了收集ImageNet数据集,研究人员花费了数百万美元的研究经费。虽然目前的数据采集成本已降低了不少,但其成本仍然不可忽略。
另外一种解决办法是应用迁移学习(transfer learning),将从源数据集学到的知识迁移到目标数据集上。例如,虽然ImageNet数据集的图像大多跟椅子无关,但在该数据集上训练的模型可以抽取较通用的图像特征,从而能够帮助识别边缘、纹理、形状和物体组成等。这些类似的特征对于识别椅子也可能同样有效。
迁移学习的一大应用场景是模型微调(finetune)。简单来说,就是我们先找到一个同类的别人训练好的模型,把别人现成的训练好了的模型拿过来,换成自己的数据,通过训练调整一下参数。 在PyTorch中提供了许多预训练好的网络模型(VGG,ResNet系列,mobilenet系列…),这些模型都是PyTorch官方在相应的大型数据集训练好的。学习如何进行模型微调,可以方便我们快速使用预训练模型完成自己的任务。
6.3.1 模型微调的流程
- 在源数据集(如ImageNet数据集)上预训练一个神经网络模型,即源模型。
- 创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。我们还假设源模型的输出层跟源数据集的标签紧密相关,因此在目标模型中不予采用。
- 为目标模型添加一个输出⼤小为⽬标数据集类别个数的输出层,并随机初始化该层的模型参数。
- 在目标数据集上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。

6.3.2 使用已有模型结构
这里我们以torchvision中的常见模型为例,列出了如何在图像分类任务中使用PyTorch提供的常见模型结构和参数。对于其他任务和网络结构,使用方式是类似的:
实例化网络
import torchvision.models as models
resnet18 = models.resnet18()
# resnet18 = models.resnet18(pretrained=False) 等价于与上面的表达式
alexnet = models.alexnet()
vgg16 = models.vgg16()
squeezenet = models.squeezenet1_0()
densenet = models.densenet161()
inception = models.inception_v3()
googlenet = models.googlenet()
shufflenet = models.shufflenet_v2_x1_0()
mobilenet_v2 = models.mobilenet_v2()
mobilenet_v3_large = models.mobilenet_v3_large()
mobilenet_v3_small = models.mobilenet_v3_small()
resnext50_32x4d = models.resnext50_32x4d()
wide_resnet50_2 = models.wide_resnet50_2()
mnasnet = models.mnasnet1_0()
传递pretrained参数
通过True或者False来决定是否使用预训练好的权重,在默认状态下pretrained = False,意味着我们不使用预训练得到的权重,当pretrained = True,意味着我们将使用在一些数据集上预训练得到的权重。
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True)
alexnet = models.alexnet(pretrained=True)
squeezenet = models.squeezenet1_0(pretrained=True)
vgg16 = models.vgg16(pretrained=True)
densenet = models.densenet161(pretrained=True)
inception = models.inception_v3(pretrained=True)
googlenet = models.googlenet(pretrained=True)
shufflenet = models.shufflenet_v2_x1_0(pretrained=True)
mobilenet_v2 = models.mobilenet_v2(pretrained=True)
mobilenet_v3_large = models.mobilenet_v3_large(pretrained=True)
mobilenet_v3_small = models.mobilenet_v3_small(pretrained=True)
resnext50_32x4d = models.resnext50_32x4d(pretrained=True)
wide_resnet50_2 = models.wide_resnet50_2(pretrained=True)
mnasnet = models.mnasnet1_0(pretrained=True)
注意事项:
通常PyTorch模型的扩展为
.pt或.pth,程序运行时会首先检查默认路径中是否有已经下载的模型权重,一旦权重被下载,下次加载就不需要下载了。一般情况下预训练模型的下载会比较慢,我们可以直接通过迅雷或者其他方式去 这里 查看自己的模型里面
model_urls,然后手动下载,预训练模型的权重在Linux和Mac的默认下载路径是用户根目录下的.cache文件夹。在Windows下就是C:\Users\<username>\.cache\torch\hub\checkpoint。我们可以通过使用torch.utils.model_zoo.load_url()设置权重的下载地址。如果觉得麻烦,还可以将自己的权重下载下来放到同文件夹下,然后再将参数加载网络。
self.model = models.resnet50(pretrained=False)
self.model.load_state_dict(torch.load('./model/resnet50-19c8e357.pth'))
- 如果中途强行停止下载的话,一定要去对应路径下将权重文件删除干净,要不然可能会报错。
6.3.3 训练特定层
在默认情况下,参数的属性.requires_grad = True,如果我们从头开始训练或微调不需要注意这里。但如果我们正在提取特征并且只想为新初始化的层计算梯度,其他参数不进行改变。那我们就需要通过设置requires_grad = False来冻结部分层。在PyTorch官方中提供了这样一个例程。
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
在下面我们仍旧使用resnet18为例的将1000类改为4类,但是仅改变最后一层的模型参数,不改变特征提取的模型参数;注意我们先冻结模型参数的梯度,再对模型输出部分的全连接层进行修改,这样修改后的全连接层的参数就是可计算梯度的。
import torchvision.models as models
# 冻结参数的梯度
feature_extract = True
model = models.resnet18(pretrained=True)
set_parameter_requires_grad(model, feature_extract)
# 修改模型
num_ftrs = model.fc.in_features
model.fc = nn.Linear(in_features=512, out_features=4, bias=True)
之后在训练过程中,model仍会进行梯度回传,但是参数更新则只会发生在fc层。通过设定参数的requires_grad属性,我们完成了指定训练模型的特定层的目标,这对实现模型微调非常重要。
四、半精度训练
我们提到PyTorch时,总会想到要用硬件设备GPU的支持,也就是“卡”。GPU的性能主要分为两部分:算力和显存,前者决定了显卡计算的速度,后者则决定了显卡可以同时放入多少数据用于计算。在可以使用的显存数量一定的情况下,每次训练能够加载的数据更多(也就是batch size更大),则也可以提高训练效率。另外,有时候数据本身也比较大(比如3D图像、视频等),显存较小的情况下可能甚至batch size为1的情况都无法实现。因此,合理使用显存也就显得十分重要。
我们观察PyTorch默认的浮点数存储方式用的是torch.float32,小数点后位数更多固然能保证数据的精确性,但绝大多数场景其实并不需要这么精确,只保留一半的信息也不会影响结果,也就是使用torch.float16格式。由于数位减了一半,因此被称为“半精度”,具体如下图:
半精度能够减少显存占用,使得显卡可以同时加载更多数据进行计算。
6.4.1 半精度训练的设置
在PyTorch中使用autocast配置半精度训练,同时需要在下面三处加以设置:
import autocast
from torch.cuda.amp import autocast
模型设置
在模型定义中,使用python的装饰器方法,用autocast装饰模型中的forward函数。
@autocast()
def forward(self, x):
...
return x
训练过程
在训练过程中,只需在数据输入模型之后的部分放入“with autocast():”即可:
for x in train_loader:
x = x.cuda()
with autocast():
output = model(x)
...
注:半精度训练主要适用于数据本身的size比较大(比如说3D图像、视频等)。当数据本身的size并不大时(比如手写数字MNIST数据集的图片尺寸只有28*28),使用半精度训练则可能不会带来显著的提升。
总结
通过本次学习,我们可以收获:
- 掌握如何自定义损失函数
- 如何根据需要选取已有的学习率调整策略
- 如何自定义设置学习率调整策略并实现
- 掌握模型微调的流程
- 了解PyTorch提供的常用model
- 掌握如何指定训练模型的部分层
- 如何在PyTorch中设置半精度训练
- 使用半精度训练的注意事项
参考资料
[1]https://www.kaggle.com/bigironsphere/loss-function-library-keras-pytorch/notebook
[2]https://blog.csdn.net/qq_27825451/article/details/95165265
[3]https://pytorch.org/docs/stable/optim.html
[4]https://www.cnblogs.com/jfdwd/p/11253925.html
[5]https://blog.csdn.net/jdzwanghao/article/details/90402577
边栏推荐
猜你喜欢
C language judges the problem of big and small endian storage

Day39------网络相关
![[Unity] 状态机事件流程框架 (一)(C#事件系统,Trigger与Action)](/img/a7/bb79f2bd8c063e483e31892df24287.png)
[Unity] 状态机事件流程框架 (一)(C#事件系统,Trigger与Action)
论文解读:iDRNA-ITF:基于诱导和转移框架识别蛋白质中的DNA和RNA结合残基

使用websocket实现服务端主动发送消息到客户端
![计算机网络 | 03.[HTTP篇] HTTP缓存技术](/img/ff/c8c6f044ccb5bdff76b7849537d396.png)
计算机网络 | 03.[HTTP篇] HTTP缓存技术

Unity_条形图(柱状图)+ UI动画
Folder permission configuration for Unity local IIS service construction

Background Suppression Network for Weakly-supervised Temporal Action Localization

List、Set、Map、Queue、Deque、Stack遍历方式总结
随机推荐
论文解读:《Mouse4mC-BGRU:用于预测小鼠基因组中DNA N4-甲基胞嘧啶位点的深度学习》
用栈模拟队列
Unity_圆环滑动条(圆形、弧形滑动条)
jupyter notebook处理文件导致IOPub data rate exceeded
如何把项目部署到云服务器
背包问题小结
什么是类与对象?
minikube与kubectl版本不一致问题
排序,欸嘿,排序
[Unity] 状态机事件流程框架 (一)(C#事件系统,Trigger与Action)
List、Set、Map、Queue、Deque、Stack遍历方式总结
数据分表小结
网络开发相关
[总结]Unity Console面板的问题汇总
Solved the problem that when VRTK transmission under Unity HDRP, the screen fades in and out, and the visual occlusion cannot be displayed correctly when passing through the wall
每日一题Day5
多数之和小结
Unity object color gradient effect (judgment logic implementation)
websocket结合消息队列完成多台服务器下的订单服务主动通知
1.4.2seata-serverAT模式,数据库里insert没有回滚是什么原因呀?